1. 获取目标页面的源码
以获取百度页面源码为例
#使用urllib获取百度首页的源码
import urllib.request
#1 定义一个url 作为需要访问的网址
url = 'http://www.baidu.com'
#2 模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
#3 获取响应中的页面源码
content = response.read()
print(content)
直接这样输出的结果会是一堆二进制文件,这是因为read返回的是字节形式的二进制数据,因此需要转换成字符串,也就是解码,具体方式是decode('编码的格式')
而编码的格式则需要在输出里找charset

content = response.read().decode('utf-8')解码之后再输出,就可以看到输出结果里会出现汉字了
#使用urllib获取百度首页的源码
import urllib.request
#1 定义一个url 作为需要访问的网址
url = 'http://www.baidu.com'
#2 模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
#3 获取响应中的页面源码
#read 返回的是字节形式的二进制数据 因此需要转换成字符串 也就是解码 decode('编码的格式')
#content = response.read() 在输出内容里看charset是utf-8
content = response.read().decode('utf-8')
print(content)

2. 一个类型和六个方法
一个类型指的是response是HTTPResponse的类型
六个方法是read() readline() readlines() getcode() geturl() getheaders()
import urllib.request
url = 'http://www.baidu.com'
#模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
#一个类型和六个方法
# response 是HTTPResponse的类型
print(type(response))
#按字节去读 返回多少个字节
content1 = response.read(5)
print(content1)
#按行读 只能读取一行
content2 = response.readline()
print(content2)
#按行读 能读所有
content3 = response.readlines()
print(content3)
#返回状态码,如果是200 就没错
content4 = response.getcode()
print(content4)
#返回url地址
content5 = response.geturl()
print(content5)
#获取状态信息
content6 = response.getheaders()
print(content6)
3. 进行下载
3.1 下载网页
import urllib.request
#下载网页
url_page = 'http://www.baidu.com'
#url表示下载路径 filename表示文件名字
#在python中,可以写变量名称,也可以直接写值
urllib.request.urlretrieve(url_page,'baidu.html')
执行这段逻辑后,就会在当前文件夹内多出来下载后的baidu.html文件,双击后就可以打开百度的网页

3.2 下载图片
在百度上随便找一张图片,右键复制图片地址https://img0.baidu.com/it/u=3159466223,684024309&fm=253&fmt=auto&app=138&f=JPEG?w=480&h=360
import urllib.request
#下载网页
url_page = 'http://www.baidu.com'
#url表示下载路径 filename表示文件名字
#在python中,可以写变量名称,也可以直接写值
#urllib.request.urlretrieve(url_page,'baidu.html')
#下载图片
url_img = 'https://img0.baidu.com/it/u=3159466223,684024309&fm=253&fmt=auto&app=138&f=JPEG?w=480&h=360'
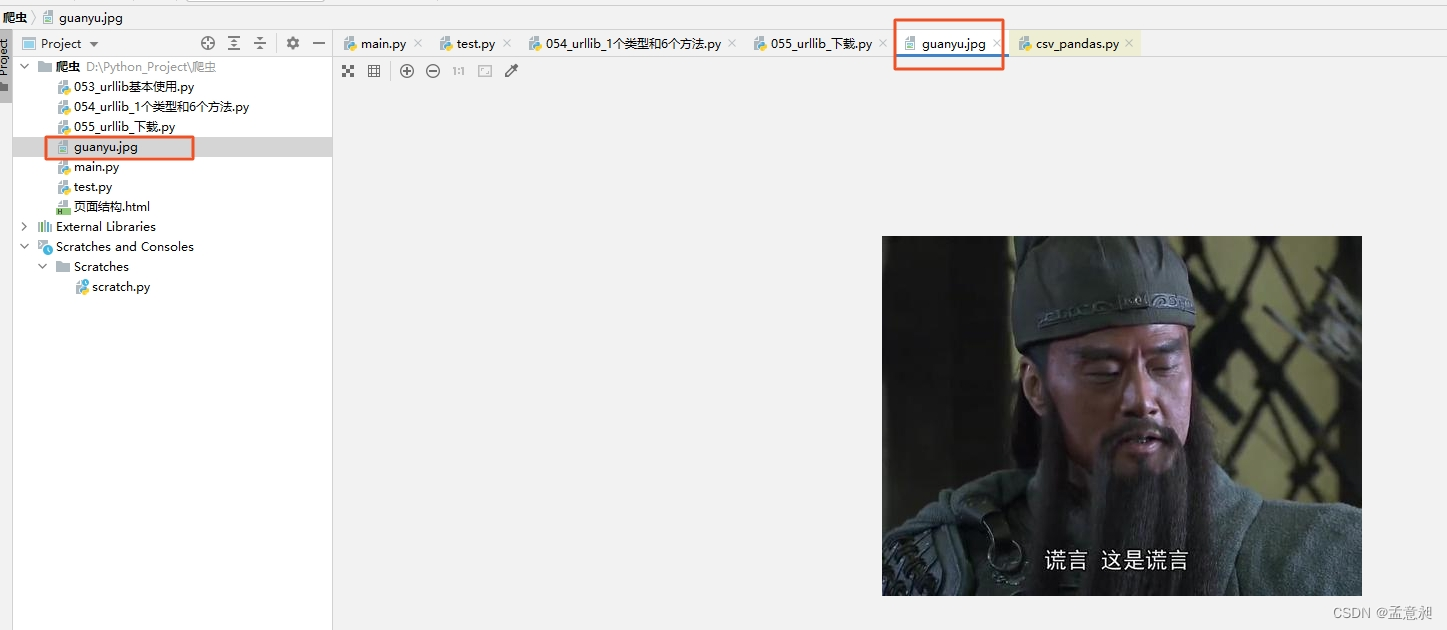
urllib.request.urlretrieve(url = url_img,filename='guanyu.jpg')
执行之后,就会发现下载到了当前文件夹下,并且可以直接双击打开
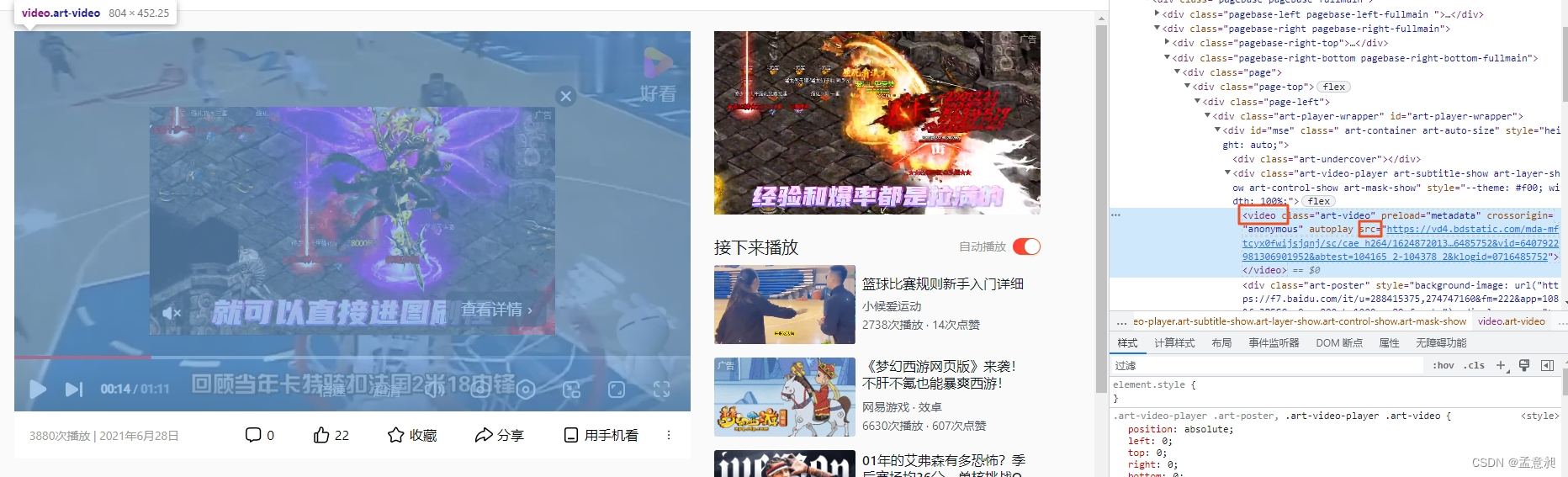
3.3 下载视频
个人感觉找视频的地址会麻烦一点,随便找一个视频,在控制台里找video模块下的src,后面跟的地址就是视频地址,这里似乎有个小技巧,当你把鼠标移到正在播放的视频界面上时,系统会自动帮你高亮对应的前端代码,我这里随便找了一段https://vd4.bdstatic.com/mda-mftcyx0fwijsjqnj/sc/cae_h264/1624872013701360043/mda-mftcyx0fwijsjqnj.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1662781316-0-0-0d102305b79f30b54f41e4213db3c308&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=0716485752&vid=6407922981306901952&abtest=104165_2-104378_2&klogid=0716485752
import urllib.request
#下载网页
url_page = 'http://www.baidu.com'
#url表示下载路径 filename表示文件名字
#在python中,可以写变量名称,也可以直接写值
#urllib.request.urlretrieve(url_page,'baidu.html')
#下载图片
url_img = 'https://img0.baidu.com/it/u=3159466223,684024309&fm=253&fmt=auto&app=138&f=JPEG?w=480&h=360'
#urllib.request.urlretrieve(url = url_img,filename='guanyu.jpg')
#下载视频
url_video = 'https://vd4.bdstatic.com/mda-mftcyx0fwijsjqnj/sc/cae_h264/1624872013701360043/mda-mftcyx0fwijsjqnj.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1662781316-0-0-0d102305b79f30b54f41e4213db3c308&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=0716485752&vid=6407922981306901952&abtest=104165_2-104378_2&klogid=0716485752'
urllib.request.urlretrieve(url_video,'video.mp4')
这段执行之后就会发现文件夹下多了一个视频文件,可以双击打开,只不过下载速度不太快
4. 定制请求对象
直接爬取https协议的网址,会遭遇反爬
import urllib.request
url = 'https://www.baidu.com'
# url的组成
# http https www.baidu.com 80/443
# 协议 主机 端口号 路径 参数 锚点
# http 80
# https 443
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
print(content)
输出的结果很少
这时候就需要在逻辑里进行伪装,将代码模拟成浏览器进行网页访问,可以在浏览器内查看自己电脑的user-agent
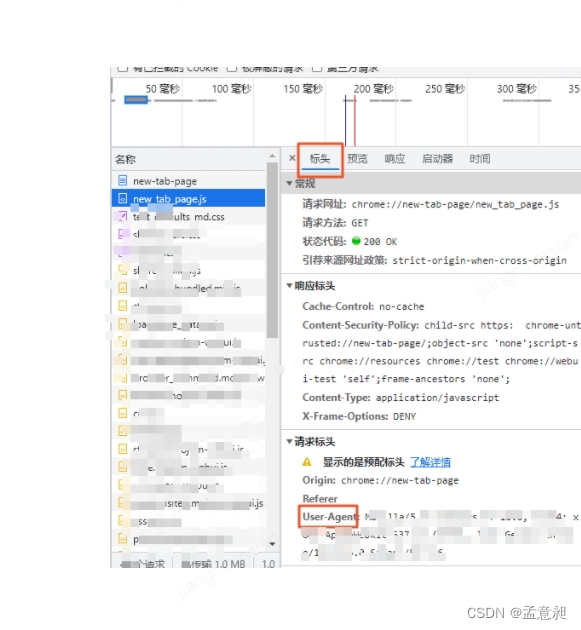
将user-agent放进代码里
import urllib.request
url = 'https://www.baidu.com'
# url的组成
# http https www.baidu.com 80/443
# 协议 主机 端口号 路径 参数 锚点
# http 80
# https 443
headers = {
'User-Agent' : '此处填写自己的user-agent'
}
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
就可以正常访问了
5. 编解码
5.1 get请求
5.1.1 get请求中的quote方法
如果直接执行这段逻辑会报错
#https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
import urllib.request
url = 'https://www.baidu.com/s?wd=周杰伦'
headers = {
'User-Agent' : '此处填写自己的user-agent'
}
# 定制请求对象
request = urllib.request.Request(url=url,headers=headers)
#模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
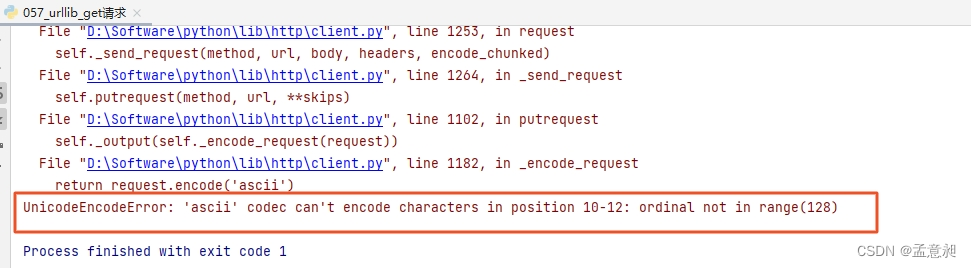
这是因为默认使用ASCII编码,而在这种编码里,不支持汉字,如果将逻辑中的url = 'https://www.baidu.com/s?wd=周杰伦'变成https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6,就可以正常输出结果,相当于是把周杰伦三个汉字改成Unicode编码,当然这种事情应该让脚本自己完成,只需要加上name = urllib.parse.quote('周杰伦')
#https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
headers = {
'User-Agent' : '此处填写自己的user-agent'
}
#将汉字转变为Unicode 需要依赖parse库
name = urllib.parse.quote('周杰伦')
#更新url变量
url = url + name
# 定制请求对象
request = urllib.request.Request(url=url,headers=headers)
#模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
运行上面这段逻辑,就可以正常访问了
5.1.2 get请求中的urlencode方法
当需要修改的值过多时,quote方法会很麻烦,这时候可以考虑使用urlencode
import urllib.parse
data = {
'wd':'周杰伦',
'sex':'男'
}
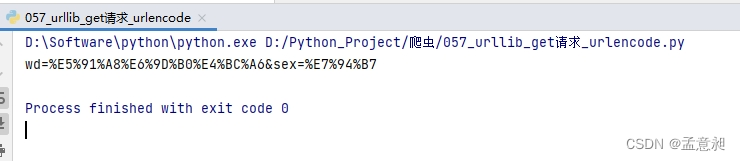
a = urllib.parse.urlencode(data)
print(a)
就会直接输出转码之后的结果
5.2 post请求
5.2.1 百度翻译
get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法
post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
#post请求
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent' : '此处填写自己的user-agent'
}
keyword = input('请输入您要查询的单词:')
data = {
'kw' : keyword
}
#post请求的参数 需要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
#post的参数 不会拼接在url后 需要放在请求对象定制的参数中
request = urllib.request.Request(url=url,data=data,headers=headers)
#模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
#字符串 》json对象
import json
obj = json.loads(content)
print(obj)
运行这段逻辑会要求输入需要翻译的单词,如果输入spider,就会得到返回结果

5.2.2 百度详细翻译
#post请求
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {'此处填写自己的header'}
data = {
'from':'en',
'to':'zh',
'query':'love',
'transtype':'realtime',
'simple_means_flag':'3',
'sign':'198772.518981',
'token':'填写自己的token',
'domain':'common'
}
#post请求的参数 需要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
#post的参数 不会拼接在url后 需要放在请求对象定制的参数中
request = urllib.request.Request(url=url,data=data,headers=headers)
#模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
#字符串 》json对象
import json
obj = json.loads(content)
print(obj)
6. ajax的get请求
6.1 ajax的get请求豆瓣电影第一页
#get请求 获取豆瓣电影的第一页数据 并保存
import urllib.request
import urllib.parse
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100:90&action=&start=0&limit=20'
headers = {'此处填写自己的header'}
# 定制请求对象
request = urllib.request.Request(url=url,headers=headers)
#模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
#print(content)
# 数据下载到本地
# 默认使用gbk 保存中文就需要改成utf-8
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
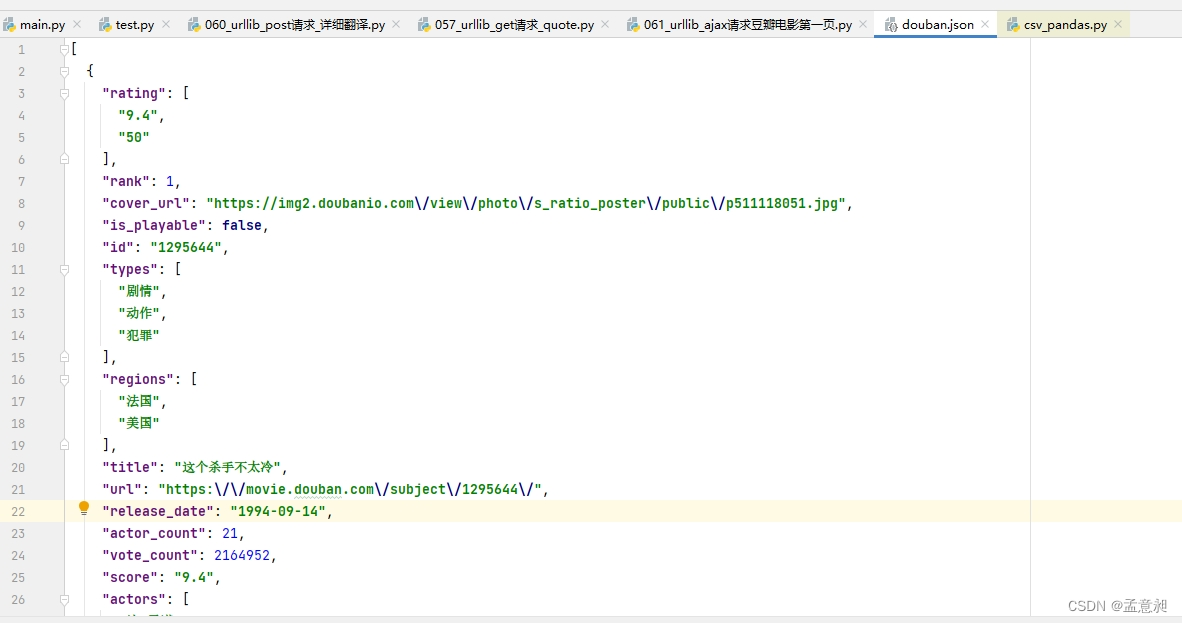
with open('douban.json','w',encoding='utf-8') as fp:
fp.write(content)
执行这段逻辑后就会得到douban.json文件,打开后会是一长行的文件,此时可以通过快捷方式ctrl + alt + l将其分行展示,就可以得到豆瓣电影的第一页
6.2 ajax的get请求豆瓣电影前十页
#get请求 获取豆瓣电影的第十页数据 并保存
import urllib.request
import urllib.parse
def create_requests(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100:90&action=&'
#get请求格式
data = {'start':(page - 1) * 20,
'limit': 20}
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
'此处填写自己的header'}
# 定制请求对象
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return(content)
def down_load(page,content):
with open('douban_' + str(page) +'.json', 'w', encoding='utf-8') as fp:
fp.write(content)
#程序入口
if __name__ == '__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页码'))
for page in range(start_page,end_page + 1):
request = create_requests(page)
#获取响应的数据
content = get_content(request)
#下载
down_load(page,content)
执行完成后,会生成多个文件,打开之后就是豆瓣电影前十页的数据
6.3 ajax的post请求肯德基门店前十页
#post 请求 访问肯德基前10页
#查询网址 http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
def create_requests(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {'cname': '北京',
'pid':'',
'pageIndex': page,
'pageSize': '10'}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {'此处填写自己的header'}
# 定制请求对象
request = urllib.request.Request(url=base_url, headers=headers, data=data)
return request
def get_content(request):
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return(content)
def down_load(page,content):
with open('kfc' + str(page) +'.json', 'w', encoding='utf-8') as fp:
fp.write(content)
#程序入口
if __name__ == '__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页码'))
for page in range(start_page,end_page + 1):
request = create_requests(page)
#获取响应的数据
content = get_content(request)
#下载
down_load(page,content)
执行上面这段逻辑后,就会得到10个json文件





![[附源码]java毕业设计医院就诊流程管理系统](https://img-blog.csdnimg.cn/7064e12862744af0a499f555bacbf485.png)