目录
1. 编程实现图6-1,并观察特征
2. 观察梯度方向
3. 编写代码实现算法,并可视化轨迹
4. 分析上图,说明原理(选做)
5. 总结SGD、Momentum、AdaGrad、Adam的优缺点(选做)
6. Adam这么好,SGD是不是就用不到了?(选做)
7. 增加RMSprop、Nesterov算法。(选做)
8. 基于MNIST数据集的更新方法的比较(选做)
参考:深度学习入门:基于Python的理论与实现 (ituring.com.cn)
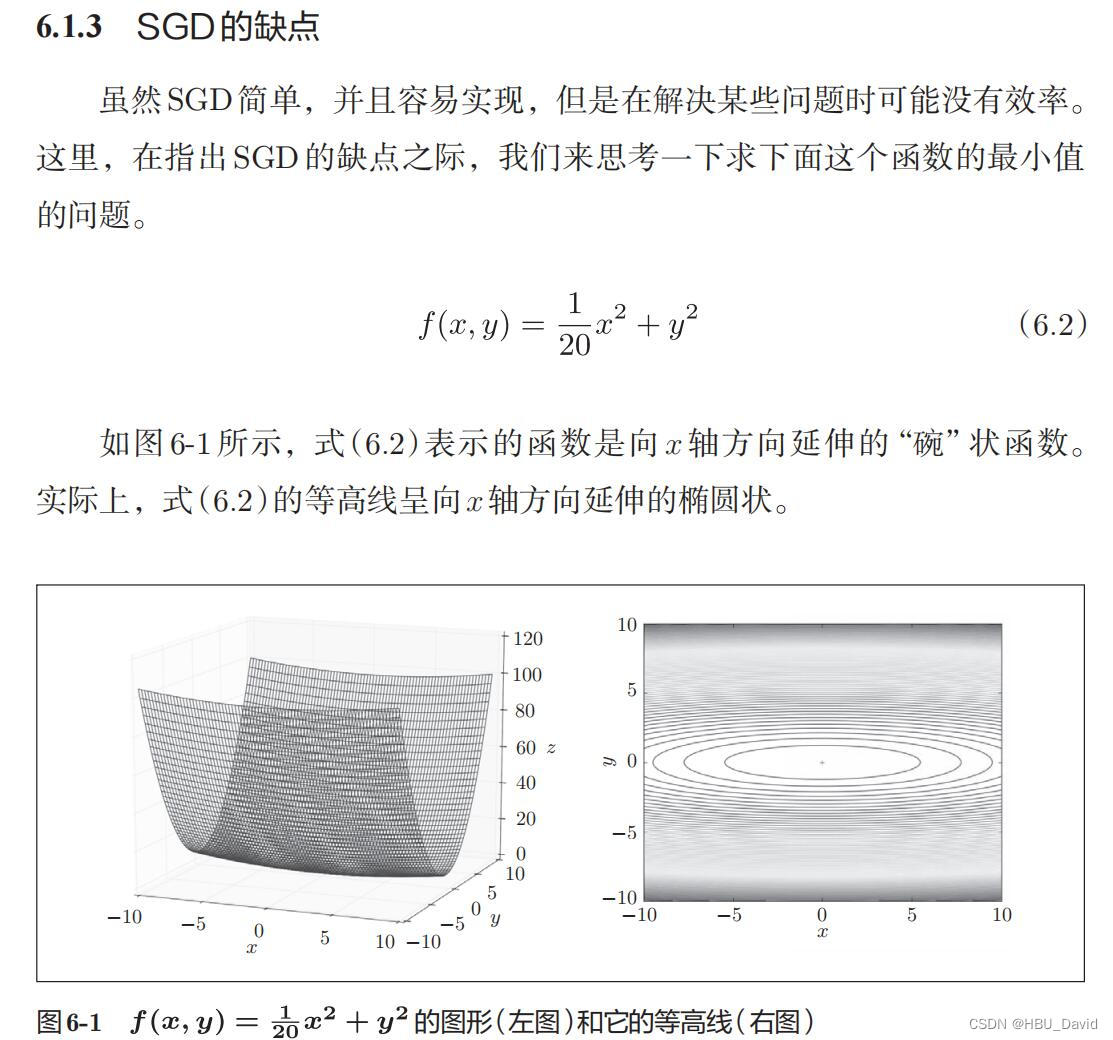
1. 编程实现图6-1,并观察特征

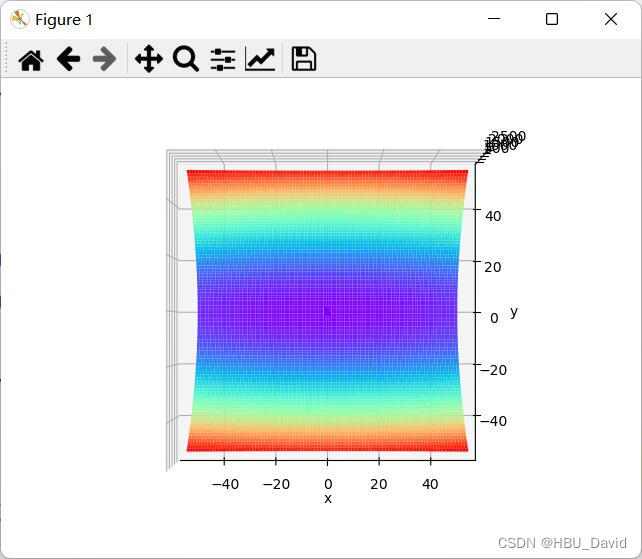
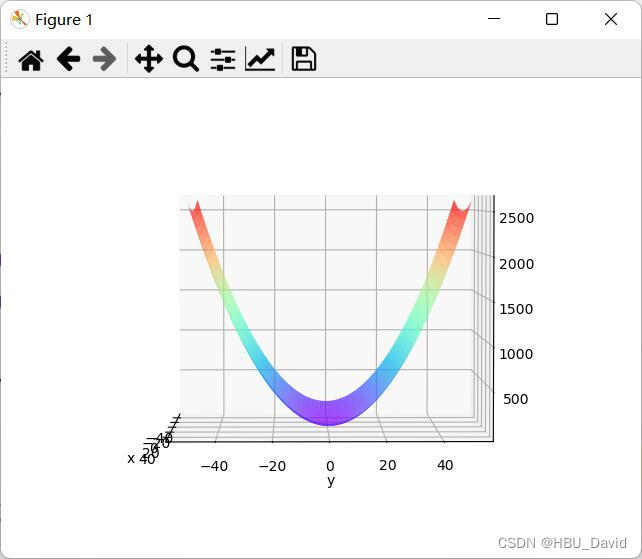
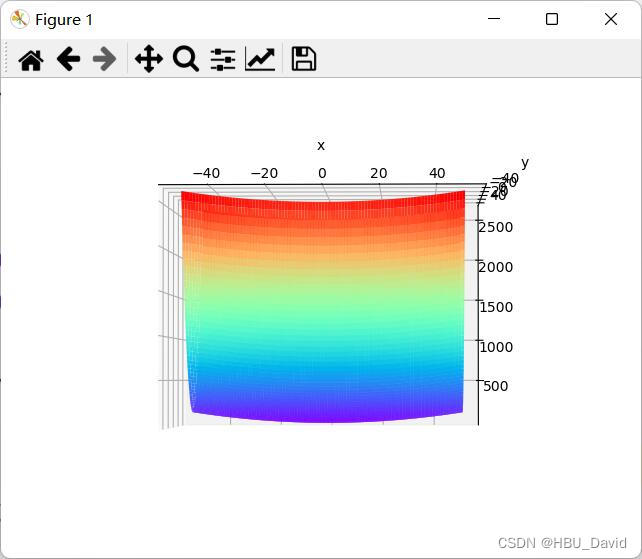
参考代码:
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# https://blog.csdn.net/weixin_39228381/article/details/108511882
def func(x, y):
return x * x / 20 + y * y
def paint_loss_func():
x = np.linspace(-50, 50, 100) # x的绘制范围是-50到50,从改区间均匀取100个数
y = np.linspace(-50, 50, 100) # y的绘制范围是-50到50,从改区间均匀取100个数
X, Y = np.meshgrid(x, y)
Z = func(X, Y)
fig = plt.figure() # figsize=(10, 10))
ax = Axes3D(fig)
plt.xlabel('x')
plt.ylabel('y')
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='rainbow')
plt.show()
paint_loss_func()
2. 观察梯度方向

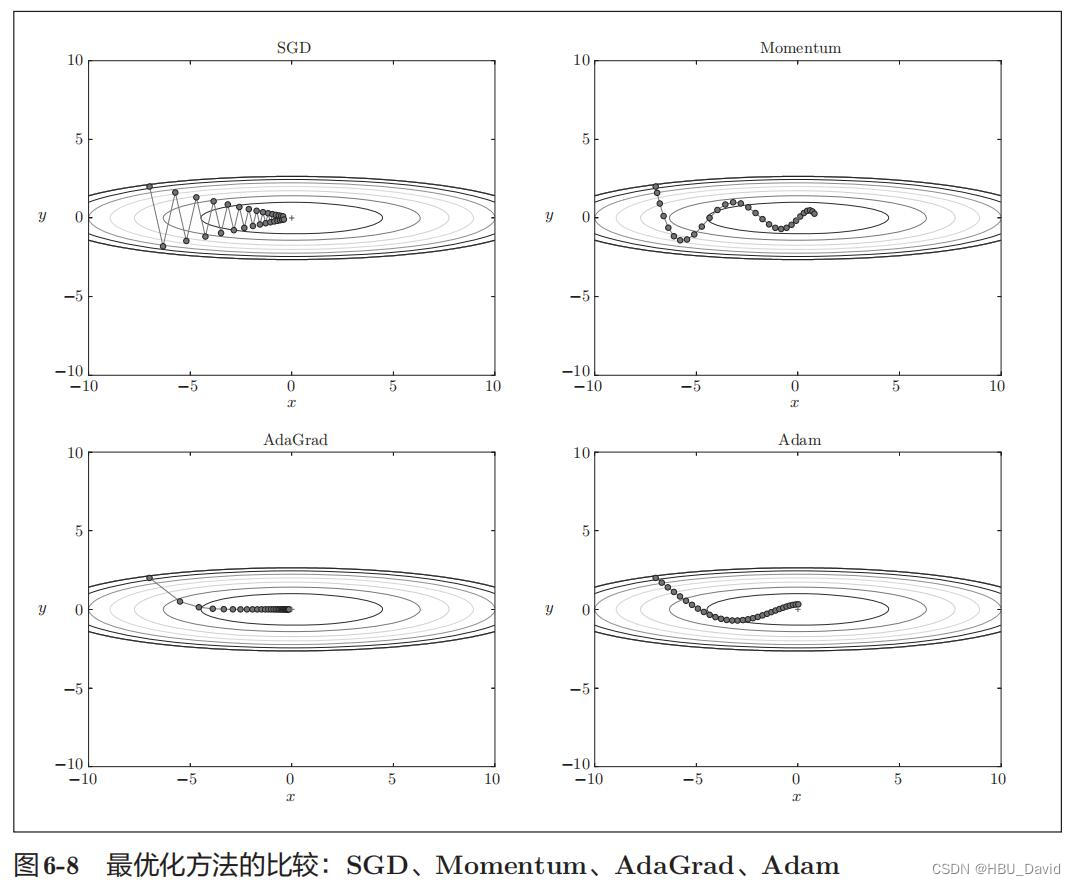
3. 编写代码实现算法,并可视化轨迹
SGD、Momentum、Adagrad、Adam
参考代码:
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)
idx = 1
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z) # 绘制等高线
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
plt.title(key)
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()
4. 分析上图,说明原理(选做)
- 为什么SGD会走“之字形”?其它算法为什么会比较平滑?
- Momentum、AdaGrad对SGD的改进体现在哪里?速度?方向?在图上有哪些体现?
- 仅从轨迹来看,Adam似乎不如AdaGrad效果好,是这样么?
- 四种方法分别用了多长时间?是否符合预期?
- 调整学习率、动量等超参数,轨迹有哪些变化?
5. 总结SGD、Momentum、AdaGrad、Adam的优缺点(选做)
6. Adam这么好,SGD是不是就用不到了?(选做)
7. 增加RMSprop、Nesterov算法。(选做)
对比Momentum与Nesterov、AdaGrad与RMSprop。
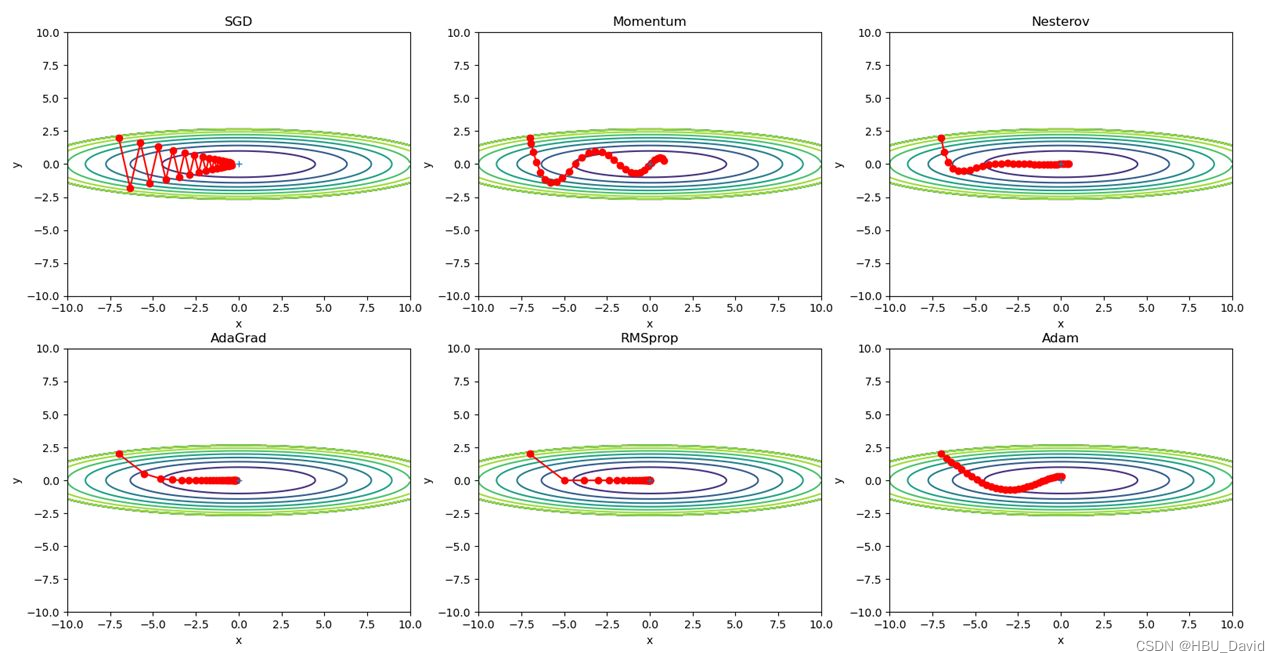
8. 基于MNIST数据集的更新方法的比较(选做)
在原图基础上,增加RMSprop、Nesterov算法。
编程实现,并谈谈自己的看法。
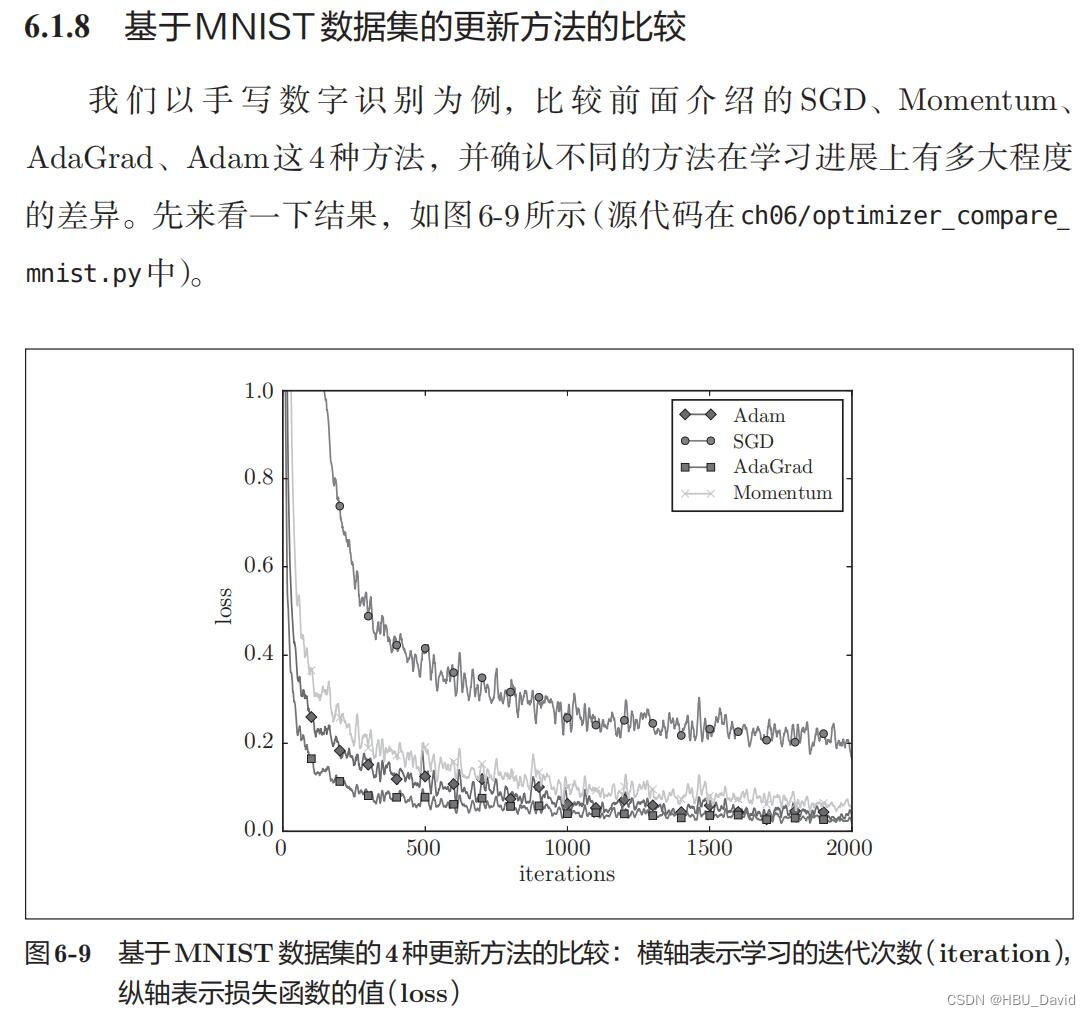
优化算法代码可参考前面的内容。
MNIST数据集的更新方法的比较:
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import *
# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1:进行实验的设置==========
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
#optimizers['RMSprop'] = RMSprop()
networks = {}
train_loss = {}
for key in optimizers.keys():
networks[key] = MultiLayerNet(
input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10)
train_loss[key] = []
# 2:开始训练==========
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizers[key].update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print( "===========" + "iteration:" + str(i) + "===========")
for key in optimizers.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
# 3.绘制图形==========
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D"}
x = np.arange(max_iterations)
for key in optimizers.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()






![[附源码]java毕业设计医院就诊流程管理系统](https://img-blog.csdnimg.cn/7064e12862744af0a499f555bacbf485.png)