【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
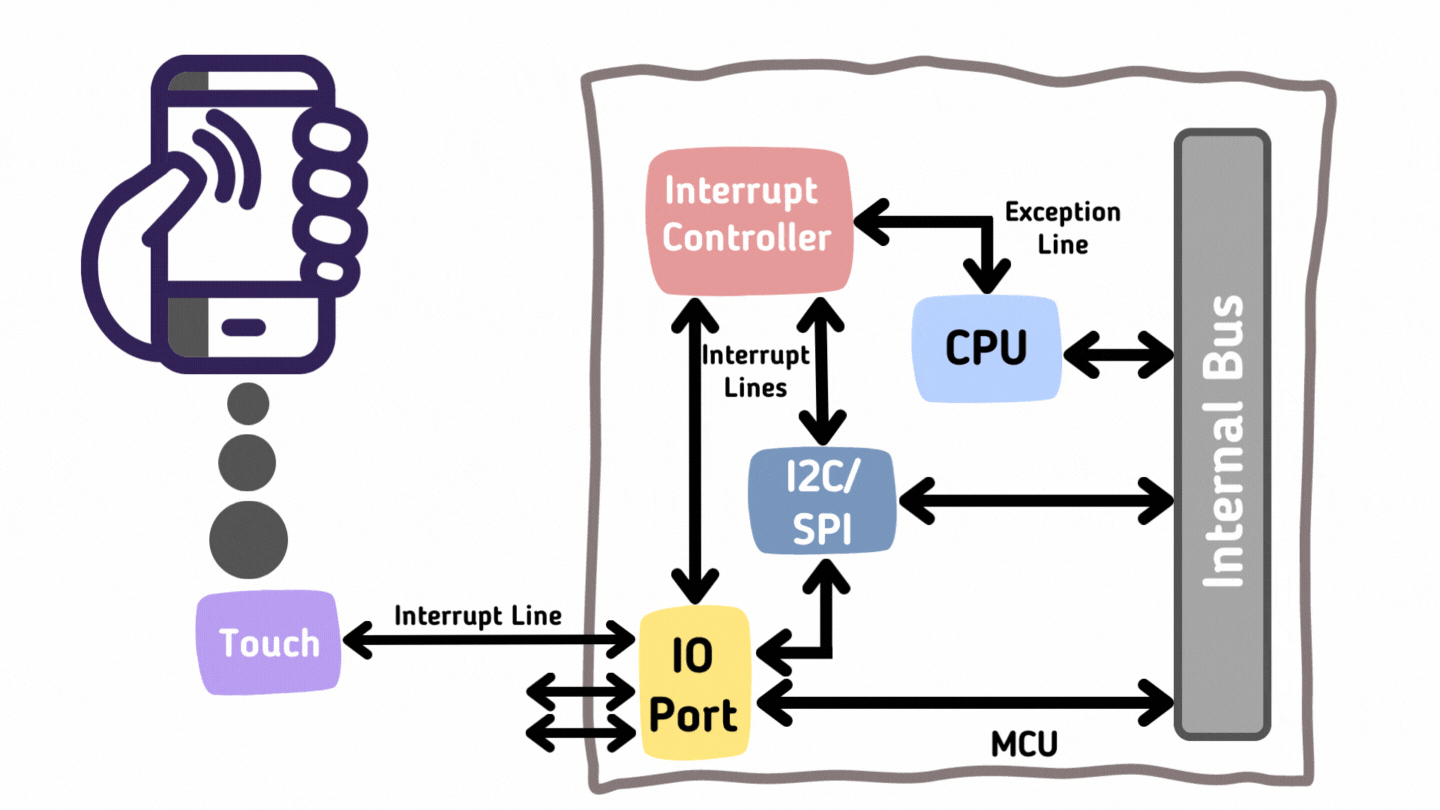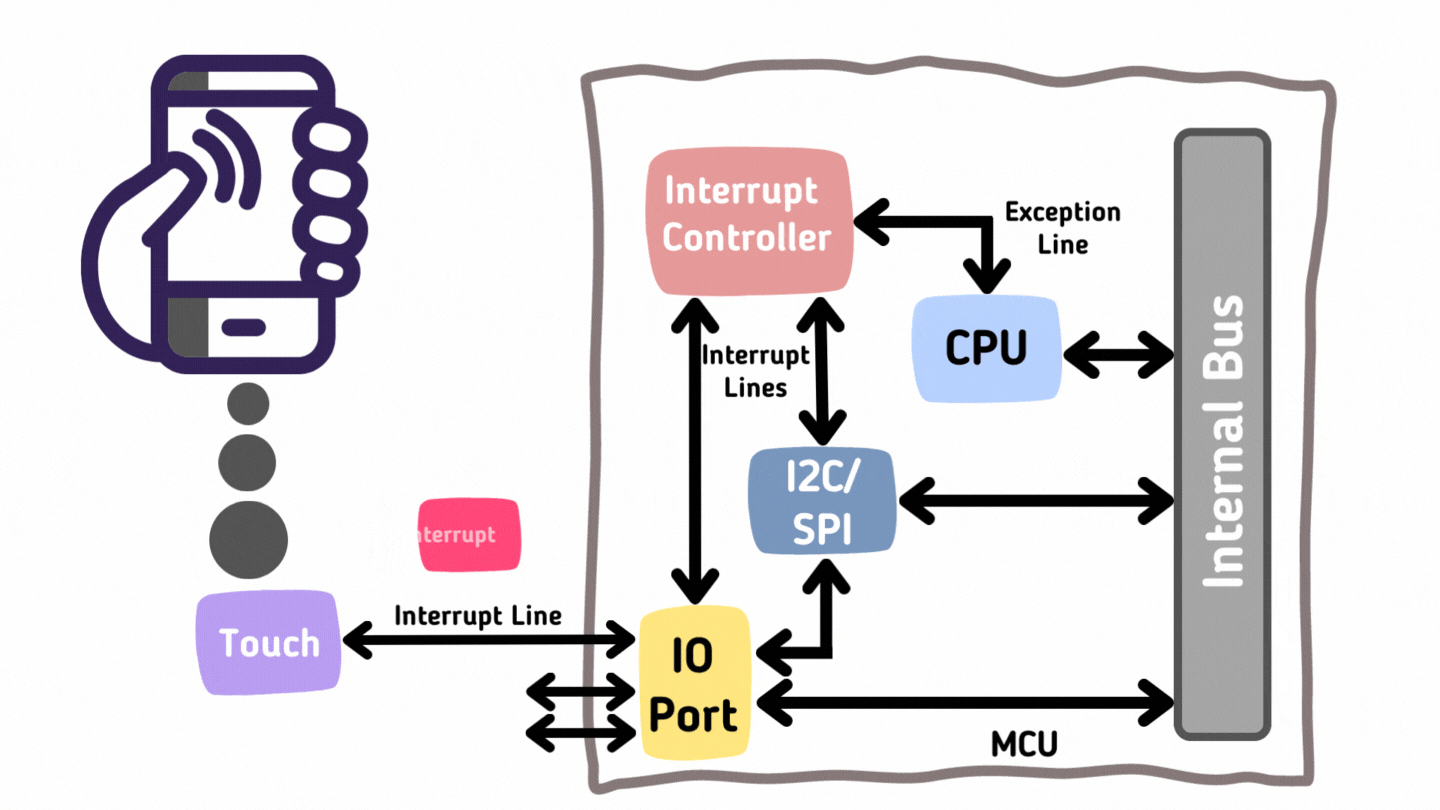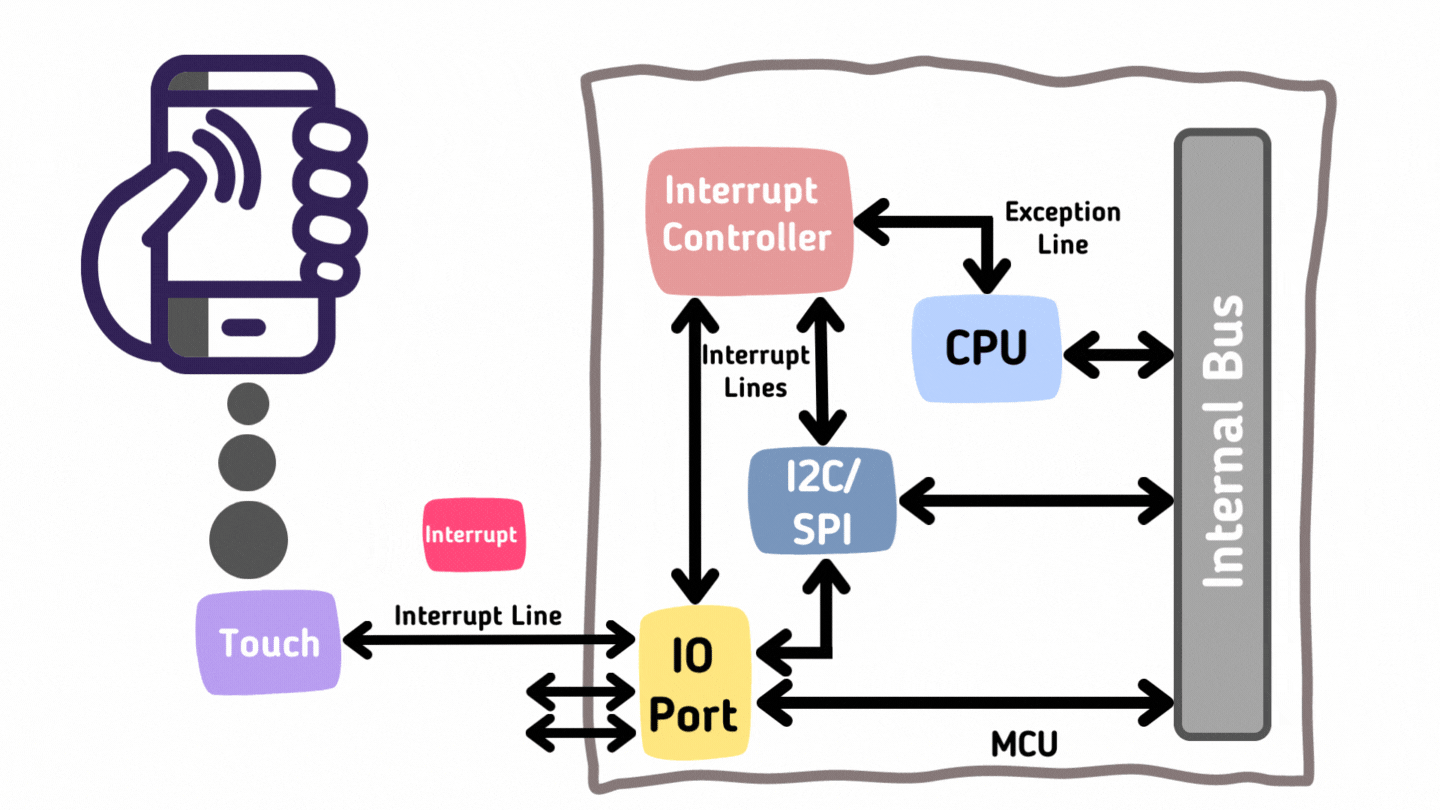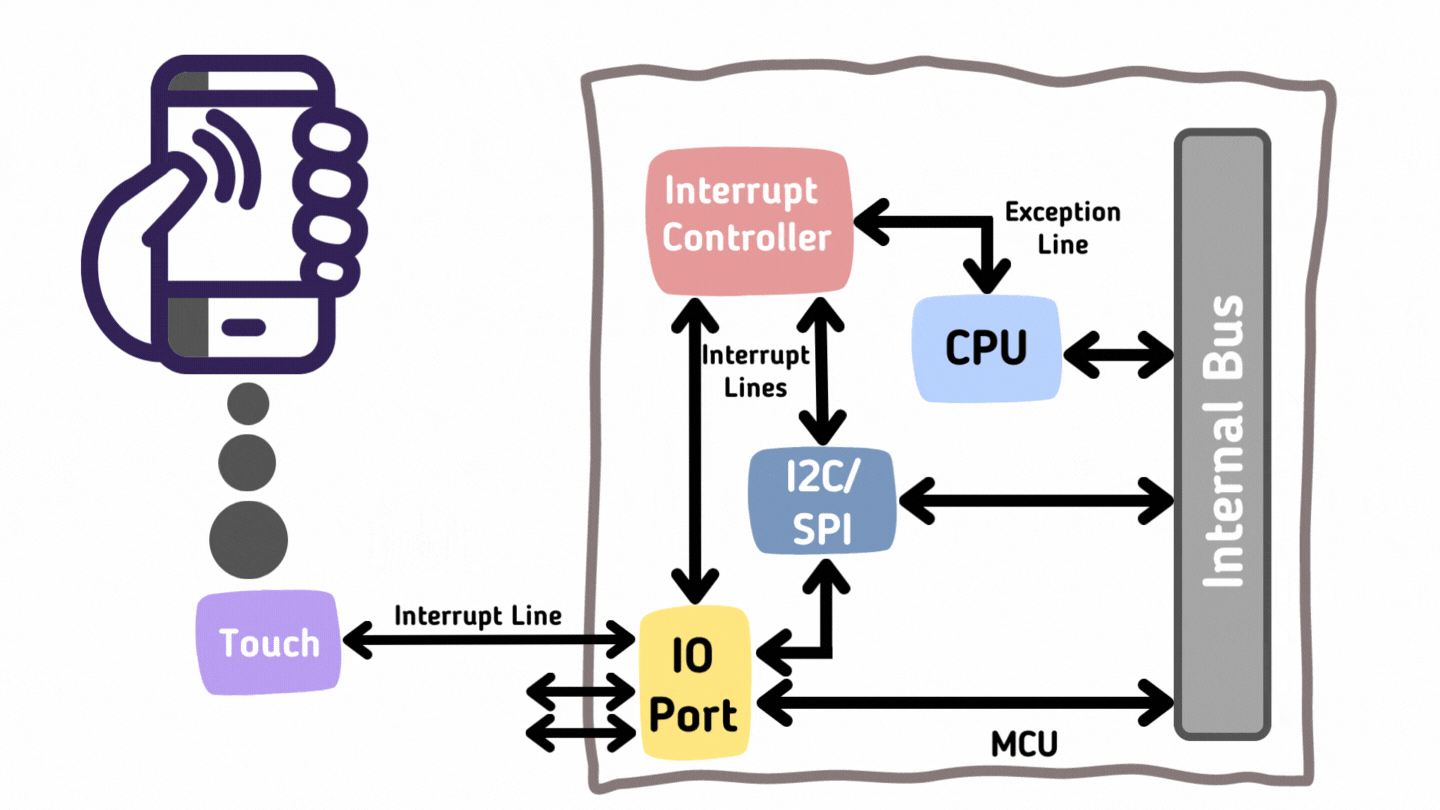
前面说过了一条指令经过cpu处理的时候需要经历几个阶段。通过实验,我们发现,哪怕是再简单的ori指令也要经历取指、译码、执行、访存和写回这五个阶段。这从之前的波形图上面可以看的很明显。
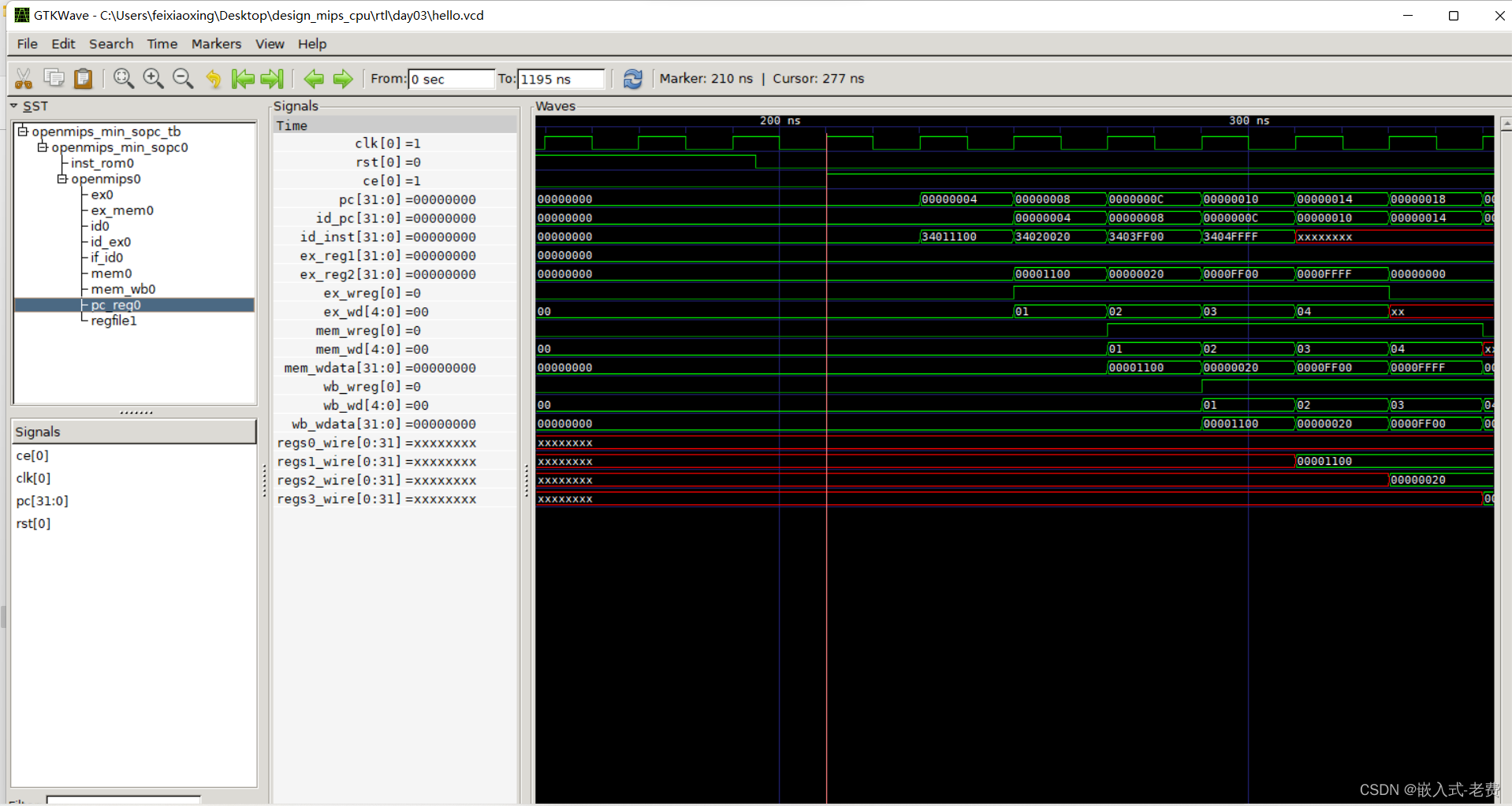
1、关于使用iverilog仿真
很多朋友也会使用《自己动手写cpu》这本书上的代码来仿真。这是完全可以的。目前来说,代码不太好找,我找了一个,上传到GitHub上面,有需要的朋友可以到这里来下载,https://github.com/feixiaoxing/design_mips_cpu/blob/master/Examples-in-book-write-your-own-cpu-master.zip。测试的时候,有几个地方需要注意下,
1)defines.v中指令的长度需要修改,比如修改成64,不然iverilog编译不过,之前作者可能使用的是modelsim软件,对于InstMemNum这一点可能不太那么讲究。
`define InstMemNum 642)在openmips_min_sopc_tb.v文件中添加生成波形文件的内容,不然无法显示波形,
initial
begin
$dumpfile("hello.vcd");
$dumpvars(0, openmips_min_sopc_tb);
end3)如果需要debug某一个module文件中的register内容,建议用wire拖出来一下即可
// wire[0:31] regs0_wire;
// wire[0:31] regs1_wire;
// wire[0:31] regs2_wire;
// wire[0:31] regs3_wire;
// wire[0:31] regs4_wire;
// assign regs0_wire = regs[0];
// assign regs1_wire = regs[1];
// assign regs2_wire = regs[2];
// assign regs3_wire = regs[3];
// assign regs4_wire = regs[4];平时测试的时候可以放开,后续编译烧入的时候可以重新注释上。
4)另外测试的过程中,可能把需要查看的信号先保存成gtkw文件。这样修改后,直接用gtkwave查看gtkw文件,所有的信号都可以快速看到。不需要再一条一条拖出来查看了,否则效率太低了。
5)对于不同模块之间的代码差异,建议直接用beyond compare查看代码差异,这样理解的更快一点。
2、继续分析流水线
流水线相比较单周期cpu有很多的优点,但是它的缺点也是很明显的。这些缺点就需要我们一个一个去处理和解决。数据依赖就是其中的一种,假设我们的指令是这样的,
ori $1, $0, 0x1100
ori $1, $1, 0x0020
ori $1, $1, 0x4400
ori $1, $1, 0x0044这是一个比较极端的例子,但是却是合理的,我们可以按照现在流水线的做法。$1寄存器的读取只能从regfile中来,但是实际cpu在处理的时候,这个寄存器的来源还有可能来自于写回、访存和执行。如果一味地认为寄存器只能来自于regfile,这其实是要出问题的,因为我们拿到的寄存器内容很有可能不是最新的内容。所以,在id译码的时候,要对原来的数据做一些调整,
always @(*) begin
if(rst == `RstEnable) begin
reg1_o <= `ZeroWord;
end else if((reg1_read_o == 1'b1) && (ex_wreg_i == 1'b1) && (ex_wd_i == reg1_addr_o)) begin
reg1_o <= ex_wdata_i;
end else if((reg1_read_o == 1'b1) && (mem_wreg_i == 1'b1) && (mem_wd_i == reg1_addr_o)) begin
reg1_o <= mem_wdata_i;
end else if(reg1_read_o == 1'b1) begin
reg1_o <= reg1_data_i;
end else if(reg1_read_o == 1'b0) begin
reg1_o <= imm;
end else begin
reg1_o <= `ZeroWord;
end
end
always @(*) begin
if(rst == `RstEnable) begin
reg2_o <= `ZeroWord;
end else if((reg2_read_o == 1'b1) && (ex_wreg_i == 1'b1) && (ex_wd_i == reg2_addr_o)) begin
reg2_o <= ex_wdata_i;
end else if((reg2_read_o == 1'b1) && (mem_wreg_i == 1'b1) && (mem_wd_i == reg2_addr_o)) begin
reg2_o <= mem_wdata_i;
end else if(reg2_read_o == 1'b1) begin
reg2_o <= reg2_data_i;
end else if(reg2_read_o == 1'b0) begin
reg2_o <= imm;
end else begin
reg2_o <= `ZeroWord;
end
end
因为写回的部分在regfile.v已经处理过了,所以这里reg1_o和reg2_o只多增加了两个部分内容。即,如果register发现在执行阶段有更新,那么优先从执行阶段获取数值;如果发现在访存阶段有更新,那么从访存阶段来获取数值。注意,这里处理的逻辑顺序,其实代表了数据优先级的获取顺序。
实验验证的方法也非常简单,我们可以看下ex_reg1每次的数值是不是最新的数值即可,
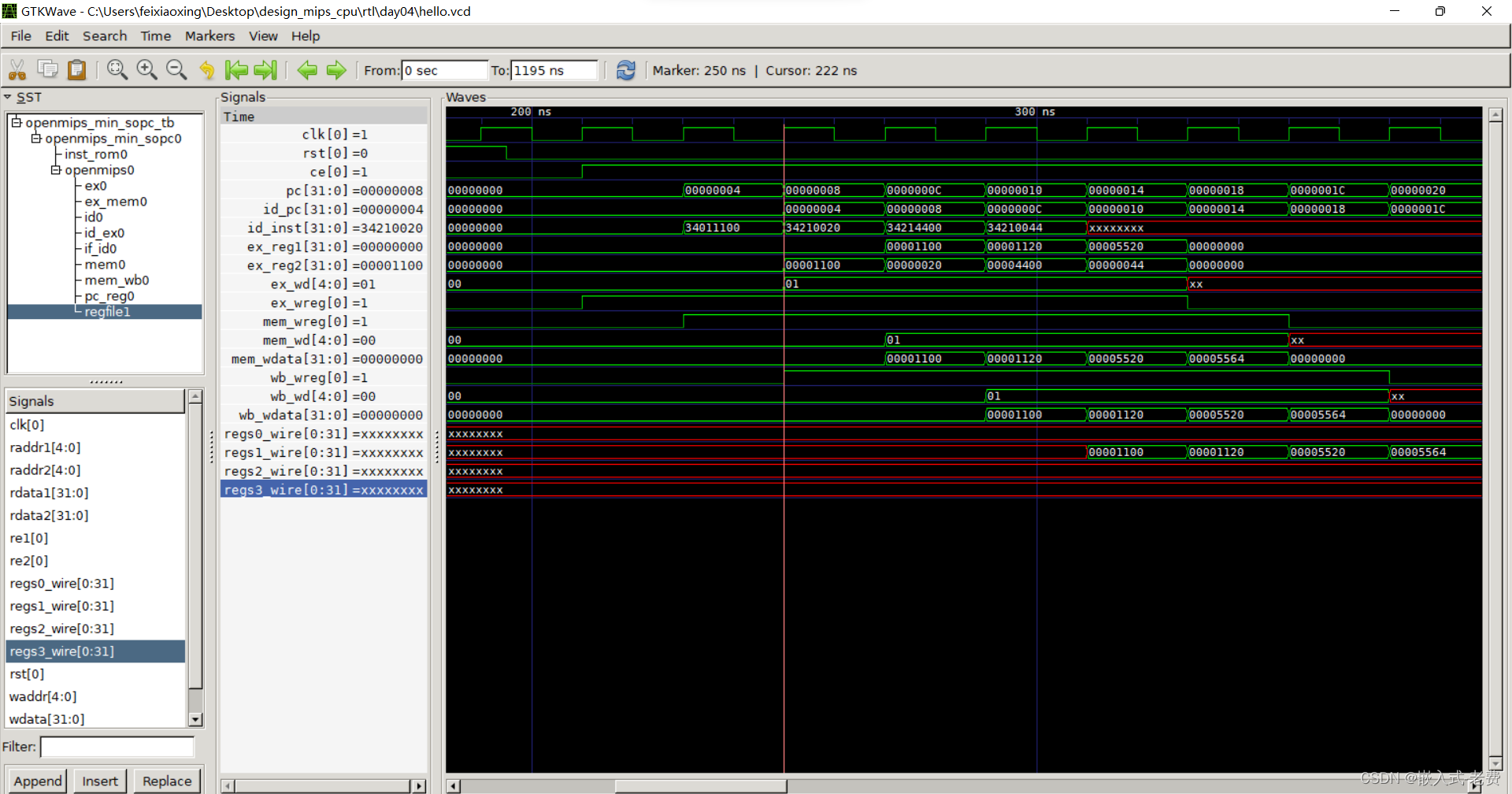
通过观察波形图,可以比较明显地发现,数据都是最新的数值。比如第一次是0x0,第二次是0x0010,这代表数值虽然还没有写回到寄存器,但是提前获取到了。第三次是0x1120,代表ex_reg1又被更新到了最新的数值,依次类推。这就是数据预取方法。在后续的多个场合,我们会看到这个方法的使用之处。
另外,有需要进行代码调试的朋友,也可以在这个地址直接获取测试代码,https://github.com/feixiaoxing/design_mips_cpu/tree/master/rtl/day04。有了这个代码,加上iverilog+gtkwave就可以在windows平台仿真测试了。

![[附源码]java毕业设计医院就诊流程管理系统](https://img-blog.csdnimg.cn/7064e12862744af0a499f555bacbf485.png)




![[短的文章] Spring Boot 日志创建使用、日志级别、@Slf4j、日志持久化——Spring Boot 系列](https://img-blog.csdnimg.cn/img_convert/13588e5daa7a7d802f61e1a700aaad3d.png)
