目录
一、查看数据
二、选择数据
1、选择单列
2、 用 [ ] 切片行:
3、标签选择
1、选择某列的某一行,如下是 A 列 第 5+1 行的值
2、B列与A列的数据相互替换
3、用标签选取多列
4、用标签切片,包含行与列结束点:
5、提取标量值:
6、布尔索引
6.1 用单列的值选择数据:
6.2 选择 DataFrame 里满足条件的值:
6.3 用 isin()筛选:
7 赋值
7.1 用索引自动对齐新增列的数据:
一、查看数据
import pandas as pd
import numpy as np生成数据 :
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))1、查看 DataFrame 头部和尾部数据:
df.head() A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401 df.tail(3) A B C D
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.5249882、显示索引与列名:
df.indexDatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D') df.columnsIndex(['A', 'B', 'C', 'D'], dtype='object')二、选择数据
1、选择单列
df['A']2013-01-01 0.469112
2013-01-02 1.212112
2013-01-03 -0.861849
2013-01-04 0.721555
2013-01-05 -0.424972
2013-01-06 -0.673690
Freq: D, Name: A, dtype: float642、 用 [ ] 切片行:
df[0:3] A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804df['20130102':'20130104'] A B C D
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.2718603、标签选择
dates = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.randn(8, 4),index=dates, columns=['A', 'B', 'C', 'D'])
1、选择某列的某一行,如下是 A 列 第 5+1 行的值
s = df['A']
s[dates[5]]-0.67368970808837062、B列与A列的数据相互替换
df[['B', 'A']] = df[['A', 'B']] A B C D
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
2000-01-04 -0.706771 0.721555 -1.039575 0.271860
2000-01-05 0.567020 -0.424972 0.276232 -1.087401
2000-01-06 0.113648 -0.673690 -1.478427 0.524988
2000-01-07 0.577046 0.404705 -1.715002 -1.039268
2000-01-08 -1.157892 -0.370647 -1.344312 0.8448853、用标签选取多列
df.loc[:, ['A', 'B']] A B
2022-01-01 -0.484042 0.071138
2022-01-02 -0.480833 0.706539
2022-01-03 2.071423 0.495800
2022-01-04 0.166673 0.390550
2022-01-05 -0.219285 -0.808867
2022-01-06 0.071547 -2.272539
2022-01-07 -0.701668 0.082397
2022-01-08 -1.551324 -0.3686164、用标签切片,包含行与列结束点:
df.loc['20220102':'20220104', ['A', 'B']] A B
2022-01-02 0.893689 -0.779383
2022-01-03 0.550630 -0.584050
2022-01-04 0.730872 -0.6256395、提取标量值:
df.loc[dates[0], 'A']2.24876015811127554、布尔索引
4.1 用单列的值选择数据:
df[df.A > 0] A B C D
2022-01-05 0.702815 0.239160 0.963091 -0.362987
2022-01-07 1.546928 -0.325164 -0.840244 -1.829160
2022-01-08 2.221970 -1.059052 -1.496134 -0.7013624.2 选择 DataFrame 里满足条件的值:
df[df > 0] A B C D
2022-01-01 NaN NaN 0.081784 0.456902
2022-01-02 NaN 0.753491 0.642349 0.525562
2022-01-03 NaN 2.173797 NaN NaN
2022-01-04 3.266260 NaN 0.146531 0.856028
2022-01-05 NaN NaN 0.717119 NaN
2022-01-06 0.889771 NaN NaN NaN
2022-01-07 NaN 0.194099 0.528841 1.283849
2022-01-08 0.957554 NaN 0.455982 0.2775924.3 用 isin()筛选:
import numpy as np
dates = pd.date_range('1/1/2022', periods=8)
df = pd.DataFrame(np.random.randn(8, 4),index=dates, columns=['A', 'B', 'C', 'D'])
df2 = df.copy()
print(df2)
df2['E'] = ['one', 'one', 'two', 'three', 'two', 'three','four', 'three']
print(df2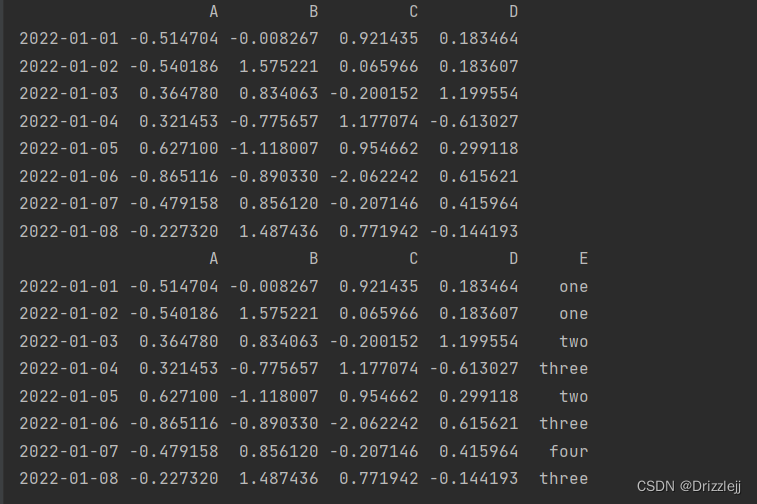
df2[df2['E'].isin(['two', 'four'])] 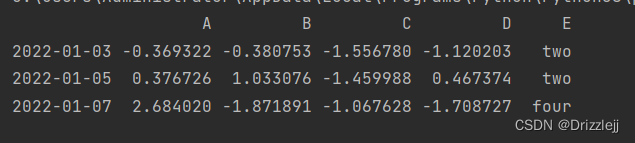
5 赋值
5.1 用索引自动对齐新增列的数据:
df2['F'] = pd.Series([1, 2, 3, 4, 5, 6,7,8], index=pd.date_range('20220102', periods=8))
print(df2) 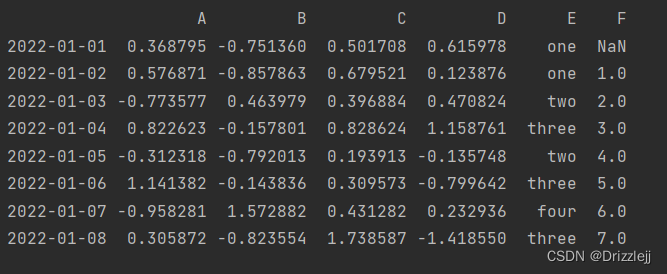
5.2 按标签赋值:
df2.at[dates[0], 'A'] = 0
print(df2)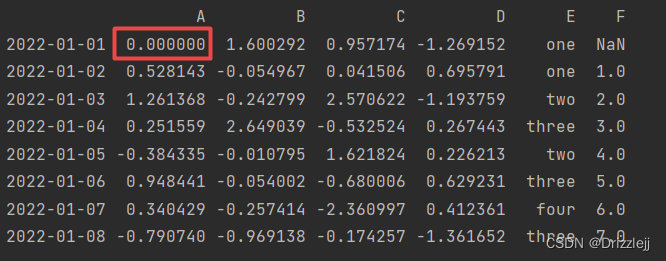
5.3 按位置赋值:
df2.iat[0, 1] = 0
print(df2)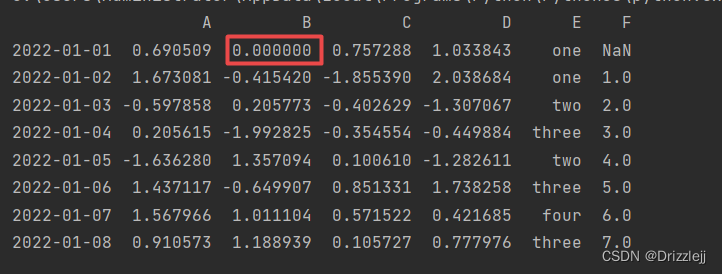
5.4 用 where 条件赋值:
dates = pd.date_range('1/1/2022', periods=8)
df = pd.DataFrame(np.random.randn(8, 4),index=dates, columns=['A', 'B', 'C', 'D'])
df2 = df.copy()
df2[df2 > 0] = -df2
print(df2)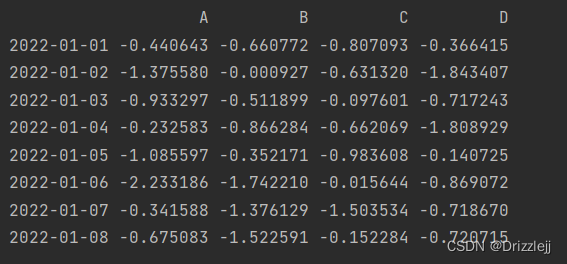
6、缺失值
Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值。
6.1 重建索引(reindex)可以更改、添加、删除指定轴的索引,并返回数据副本,即不更改原数据。
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])
df1.loc[dates[0]:dates[1], 'E'] = 1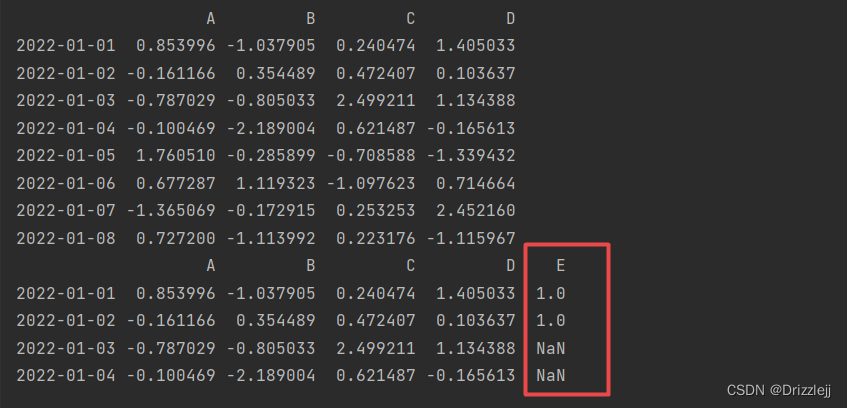
6.2 删除所有含缺失值的行:
df1.dropna(how='any')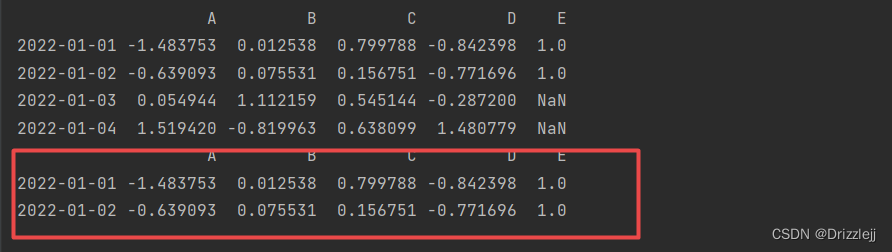
6.3 填充缺失值:
df1.fillna(value=5)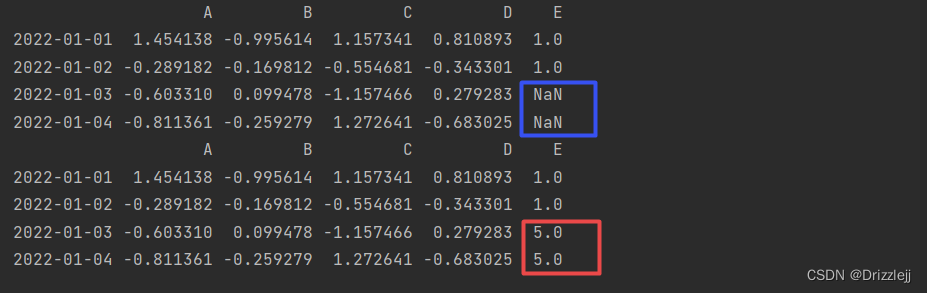
6.4 对于DataFrame,可以按列指定单个值替换:
df2.replace({"E": 'two','F':5}, 100)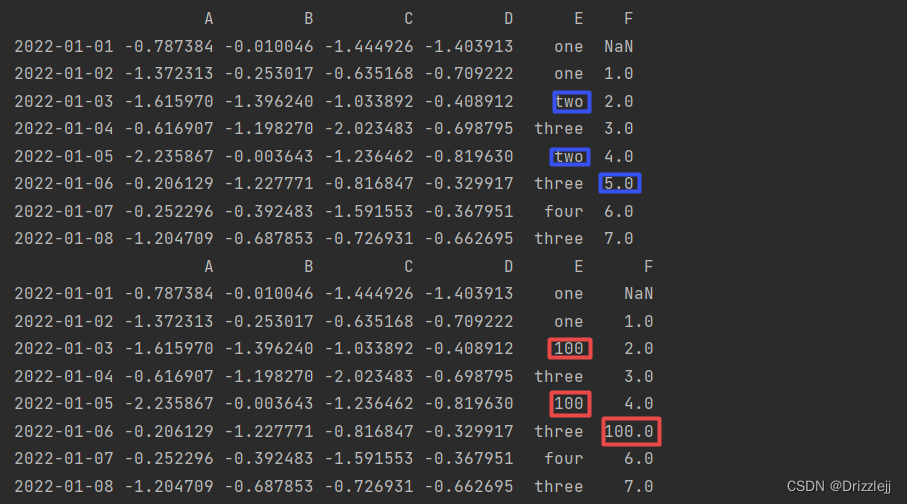
6.5 字符串/正则表达式替换
df2.replace("one", np.nan)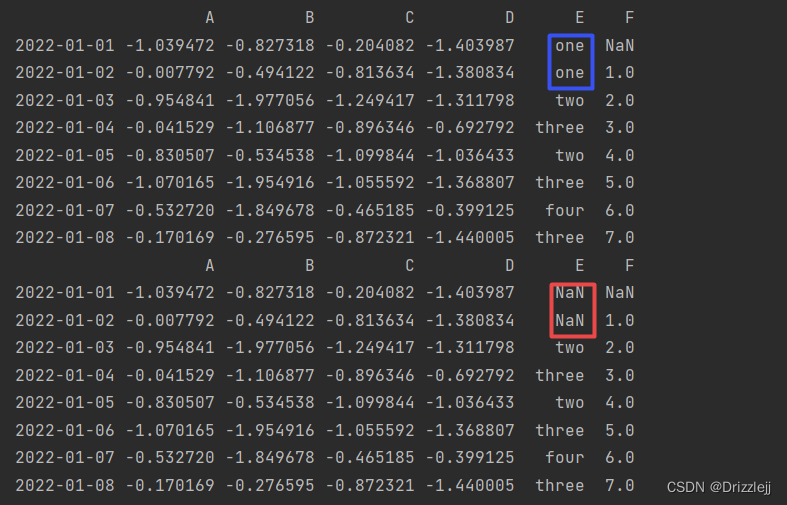
df2.replace(r"^o", '啊', regex=True)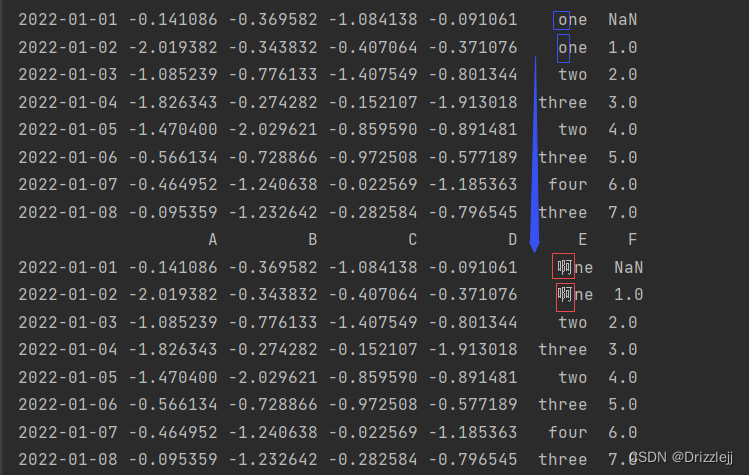
df2.replace([r"^f", r"(e)"], ["dot", r"\1stuff"], regex=True)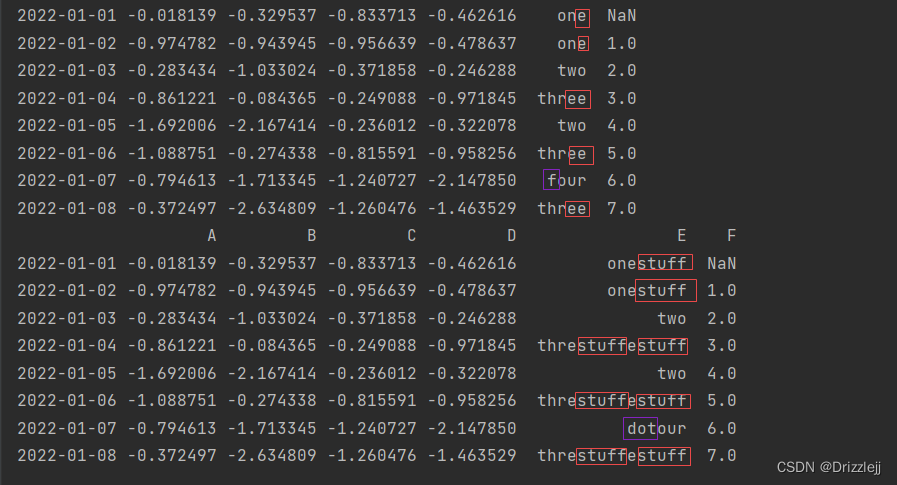
df2.replace({"E": "one"}, {"E": np.nan})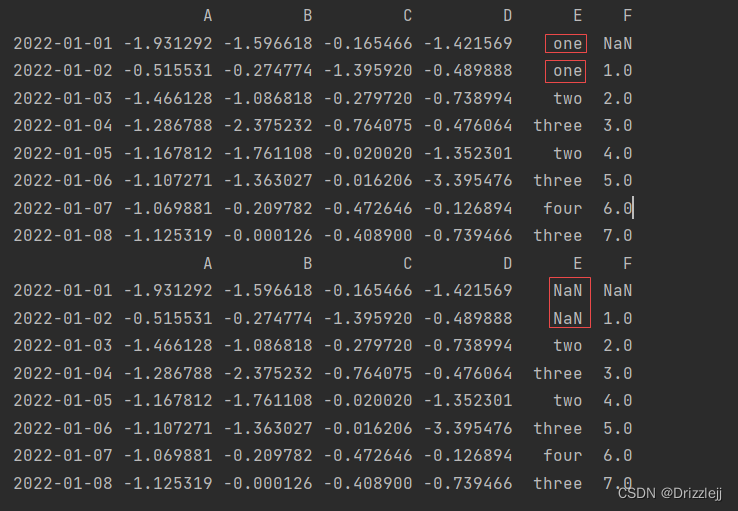
6.6 其他正则替换方法
df.replace({"b": r"\s*\.\s*"}, {"b": np.nan}, regex=True)
df.replace(regex=[r"\s*\.\s*", r"a|b"], value=np.nan)
df.replace({"b": r"\s*(\.)\s*"}, {"b": r"\1ty"}, regex=True)
df.replace(regex={"b": {r"\s*\.\s*": np.nan}})
df.replace({"b": {"b": r""}}, regex=True)
df.replace({"b": r"\s*\.\s*"}, {"b": np.nan}, regex=True)7、连接对象
7.1 pd.contact
pd.concat(objs,axis=0,join="outer",ignore_index=False,keys=None,levels=None,names=None,verify_integrity=False,copy=True)objs:
Series或 DataFrame 对象的序列或映射。如果dict被传递,排序的键将被用作keys参数,除非它被传递,在这种情况下,值将被选择。任何None对象都将被静默删除,除非它们都是None,在这种情况下将引发ValueError。
axis:{0,1,…},默认为0。要连接的轴。
join:{'inner ',' outer'},默认为' outer '。如何处理其他轴上的索引。外部用于并集,内部用于交集。
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)
frames = [df1, df2, df3]
result = pd.concat(frames)
print(result)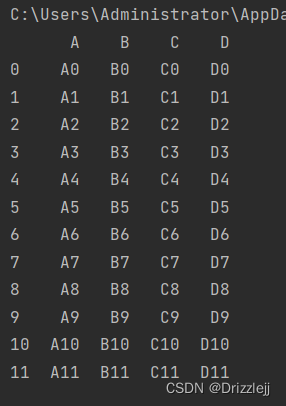
8、读取写入文件
1、读取csv
df.to_csv('foo.csv')2、读取excel
pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA'])读取某列
# 读取 name 列 和 content 列
df = pd.read_excel('Names4.xlsx',usecols=["name","content"])
print(df)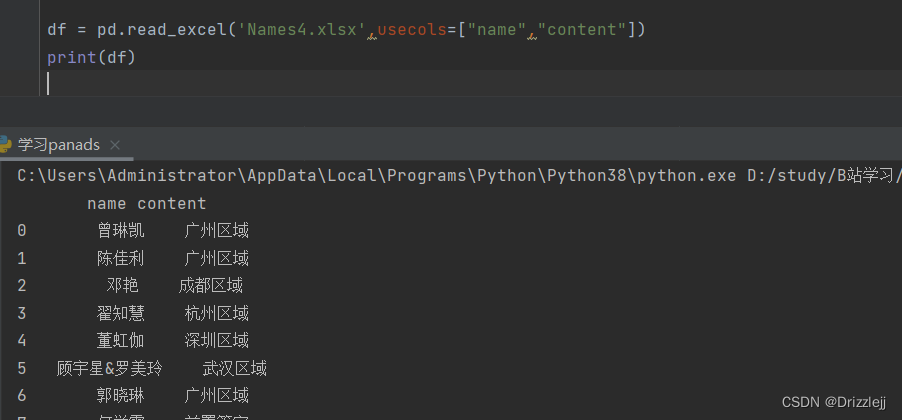
3、写入excel
df.to_excel('foo.xlsx', sheet_name='Sheet1')9、迭代
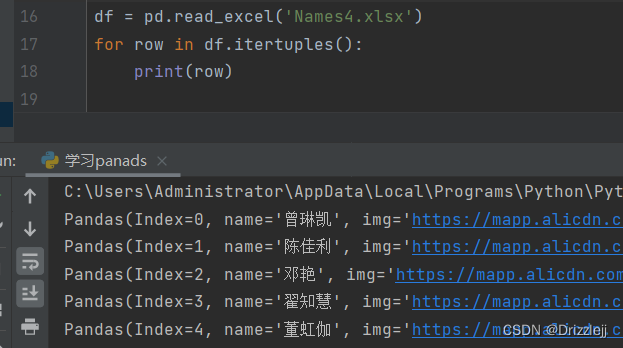
9.1 itertuples() 永远不要修改迭代的内容,这种方式不能确保所有操作都能正常运作。基于数据类型,迭代器返回的是复制(copy)的结果,不是视图(view),这种写入可能不会生效!
itertuples()迭代 DataFrame 或 Series 里的每一行数据。这个操作返回一个迭代器,生成索引值及包含每行数据的 Series:
panads 教程 文档 MultiIndex / advanced indexing — pandas 1.5.2 documentation








![[网络] https是什么?https是怎么保障我们信息传输的安全的?](https://img-blog.csdnimg.cn/a44836fc2d014f3aa8c9254392fcc05e.png)