:详细介绍百度ERNIE:Enhanced Representation through Knowledge Integration
文章目录
- ERNIE 2.0简介
- 相关工作
- 语言表征的无监督学习
- 持续学习
- ERNIE2.0 框架
- 持续的预训练
- 预训练任务的构建
- 持续的多任务学习
- 针对应用任务的微调
- ERNIE 2.0模型
- 模型结构
- 预训练任务
- 1.词汇感知预训练任务
- 2.结构感知的预训练任务
- 3.语义感知的预训练任务
- 实验
- 预训练及其实现
- 微调任务
- 实验结果
- 结论
论文题目:ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding语言理解的持续预训练框架
为了从训练语料中提取词汇、句法和语义信息,我们提出了一个名为ERNIE 2.0的持续预训练框架,该框架逐步建立预训练任务,然后通过持续的多任务学习在这些构建的任务上学习预训练模型。基于这个框架,我们构建了几个任务,并训练ERNIE 2.0模型来捕捉训练数据中的词汇、句法和语义方面的信息。
实验结果表明,ERNIE 2.0模型在16个任务上的表现优于BERT和XLNet,包括GLUE基准的英语任务和几个类似的中文任务。
ERNIE 2.0简介
预训练的语言表征,如ELMo、OpenAI GPT、BERT、ERNIE 1.0和XLNet已被证明能有效提高各种自然语言理解任务的性能,包括情感分类、自然语言推理、命名实体识别等等。
目前模型的预训练往往是根据词和句子的共现性来通过几个简单的任务训练模型。而事实上,在训练语料中,除了共现之外,还有其他值得研究的词法、句法和语义信息。例如,像人名、地点名和组织名称这样的命名实体,可能包含概念性信息。像句子顺序和句子接近度这样的信息使模型能够学习结构感知的表示。而文档级别的语义相似性或句子之间的话语关系使模型能够学习语义感知的表述。
为了发现训练语料中所有有价值的信息,无论是词汇、句法还是语义表征,我们提出了一个名为ERNIE 2.0的持续预训练框架,它可以通过持续的多任务学习逐步建立并训练大量的预训练任务。
ERNIE框架支持不断引入各种定制的任务,这是通过持续的多任务学习实现的。当给定一个或多个新任务时,持续多任务学习方法以有效的方式同时训练新引入的任务和原来的任务,而不会忘记以前学到的知识。通过这种方式,我们的框架可以根据它所掌握的先前训练的参数来逐步训练分布式表征。此外,在这个框架中,所有的任务都共享相同的编码网络,从而使跨不同任务的词汇、句法和语义信息的编码成为可能。
相关工作
语言表征的无监督学习
通过用大量的未注释数据预训练语言模型来学习一般的语言表征是有效的。传统的方法通常专注于与语境无关的词嵌入。诸如Word2Vec和GloVe等方法基于大型语料库的词共现信息学习固定的词嵌入。
最近,一些以语境化语言表征为中心的研究被提出,语境相关的语言表征在各种自然语言处理任务中显示出最先进的成果。ELMo提出从语言模型中提取上下文敏感的特征。OpenAI GPT通过调整Transformer加强了上下文敏感的嵌入。BERT则采用了一个屏蔽的语言模型,同时在预训练中加入了一个下句预测任务。XLM整合了两种方法来学习跨语言的语言模型,即只依赖单语数据的无监督方法和利用平行双语数据的监督方法。MT-DNN通过在预训练模型的基础上一起学习GLUE中的几个监督任务,最终导致在多任务监督微调阶段没有学到的其他监督任务的改进,取得了更好的效果。XLNet使用Transformer-XL,并提出了一种广义自回归预训练方法,通过最大化因子化顺序的所有排列组合的预期可能性来学习双向语境。
持续学习
持续学习的目的是用几个任务依次训练模型,使其在学习新的任务时能记住以前学过的任务。这些方法受到人类学习过程的启发,因为人类能够不断积累通过学习或经验获得的信息,以充分发展新技能。通过不断的学习,模型应该能够在新的任务中表现良好,这要归功于之前训练中获得的知识。
ERNIE2.0 框架
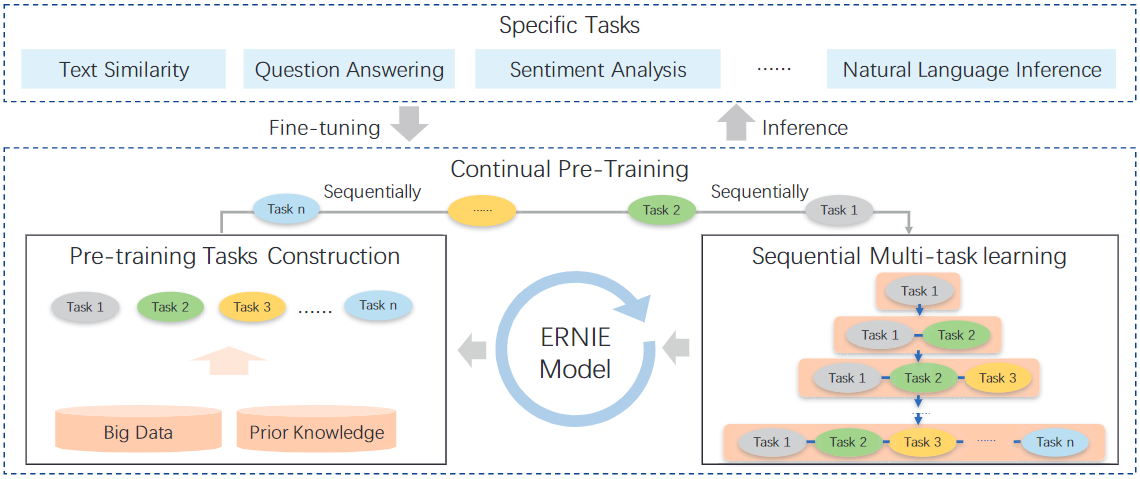
如图1所示,ERNIE 2.0框架是基于一个广泛使用的预训练和微调的架构建立的。ERNIE 2.0与以往的预训练不同的是,它不是用少量的预训练目标进行训练,而是可以不断引入大量的预训练任务,以帮助模型有效地学习词汇、句法和语义表征。
在此基础上,ERNIE 2.0框架通过持续的多任务学习不断更新预训练的模型。在微调过程中,ERNIE模型首先用预训练的参数进行初始化,然后用特定任务的数据进行微调。
图1:ERNIE 2.0的框架,其中预训练任务可以逐步构建,模型通过持续的多任务学习进行预训练,预训练的模型进行微调以适应各种语言理解任务。
持续的预训练
持续的预训练过程包含两个步骤。首先,我们不断地用大数据和先验知识构建无监督的预训练任务。其次,我们通过持续的多任务学习逐步更新ERNIE模型。
预训练任务的构建
我们可以在每个时间段构建不同类型的任务,包括单词感知任务、结构感知任务和语义感知任务。所有这些预训练任务都依赖于自监督或弱监督的信号,这些信号可以从没有人工标注的海量数据中获得。先验知识,如命名实体、短语和话语关系,被用来从大规模数据中生成标签。
持续的多任务学习
ERNIE 2.0框架旨在从一些不同的任务中学习词汇、句法和语义信息。因此,有两个主要挑战需要克服。第一个挑战是如何以持续的方式训练任务而不忘记之前学到的知识。第二是如何以一种有效的方式对这些任务进行预训练。
我们提出了一种持续的多任务学习方法来解决这两个问题。每当有新的任务出现时,持续多任务学习方法首先使用以前学过的参数来初始化模型,然后将新引入的任务与原有的任务同时训练。这将确保所学的参数能够编码先前所学的知识。剩下的一个问题是如何让它更有效地训练。我们通过给每个任务分配N次训练迭代来解决这个问题。我们的框架需要将每个任务的这N次迭代自动分配给不同的训练阶段。
图2:持续预训练的不同方法
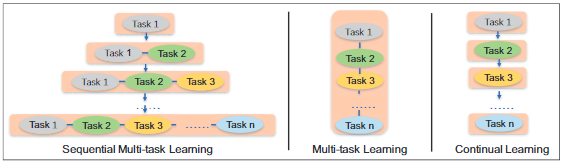
图2显示了我们的方法、从头开始的多任务学习和以前的持续学习之间的区别。
虽然从头开始的多任务学习(第二种)可以同时训练多个任务,但在训练进行之前,必须准备好所有定制的预训练任务,每当有新任务时,模型都需要从头学习。所以这种方法需要的时间和持续学习一样多,甚至更多。
传统的持续学习方法(第三种)在每个阶段只用一个任务来训练模型,其缺点是可能会忘记之前学到的知识。
图4:ERNIE 2.0框架中的多任务学习架构,其中编码器可以是循环神经网络或深度Transformer。
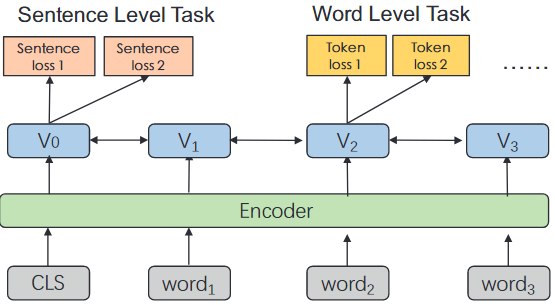
如图4所示,我们的持续多任务学习的架构在每个阶段都包含一系列共享文本编码层来编码上下文信息,可以通过使用递归神经网络或由堆叠的自我注意层组成的深度转化器来定制。
编码器的参数可以在所有学习任务中更新。在我们的框架中,有两种损失函数。一个是句子级损失,另一个是标记级损失,这与BERT的损失函数类似。每个预训练任务都有自己的损失函数。在预训练过程中,一个句子损失函数可以与多个标记级损失函数相结合,不断地更新模型。
针对应用任务的微调
通过对特定任务的监督数据进行微调,预训练的模型可以适应不同的语言理解任务,如问题回答、自然语言推理和语义相似性。每个下游任务在经过微调后都有自己的微调模型。
ERNIE 2.0模型
为了验证该框架的有效性,我们构建了三种不同的无监督语言处理任务,并开发了一个预先训练好的模型,称为ERNIE 2.0模型。这一节将介绍该模型在提出的框架中的实现。
模型结构
Transformer编码器:该模型使用多层Transformer作为基本编码器,就像其他预训练模型,如GPT,BERT和XLM。Transformer可以通过自注意力来捕捉序列中每个标记的上下文信息,并生成一串上下文嵌入。
给定一个序列,特殊的分类嵌入[CLS]被添加到该序列的首位。此外,对于多输入段的任务,[SEP]的符号被添加到段的间隔中作为分隔符。
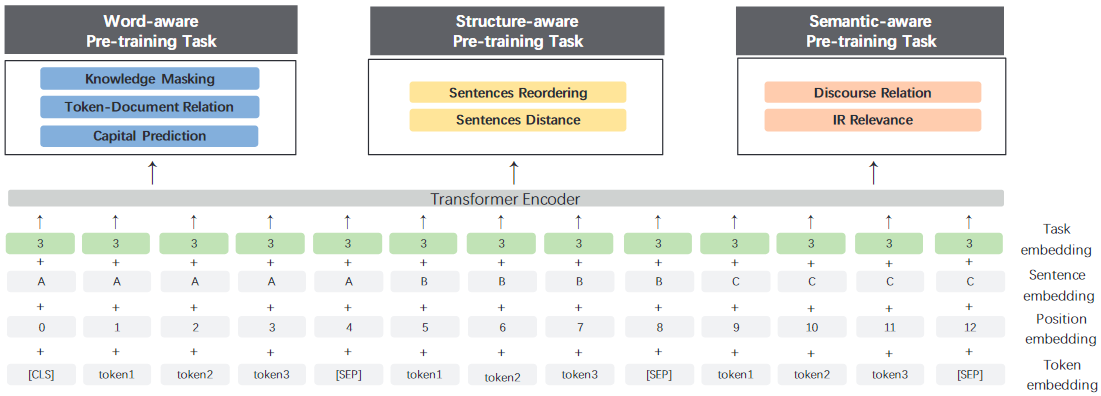
任务嵌入:该模型使用任务嵌入来表示不同任务的特征。我们用一个从0到N的id来表示不同的任务,每个任务id被分配到一个唯一的任务嵌入。相应的标记、片段、位置和任务嵌入被作为模型的输入。在微调过程中,我们可以使用任何任务ID来初始化我们的模型。该模型结构如图3所示。
图3:ERNIE 2.0模型的结构。输入嵌入包括标记嵌入、句子嵌入、位置嵌入和任务嵌入。ERNIE 2.0模型中构建了七个属于不同种类的预训练任务。
预训练任务
我们构建了三种不同类型的任务来捕捉训练语料中不同层面的信息。
词汇感知任务使模型能够捕获词汇信息,结构感知任务使模型能够捕获语料的句法信息,语义感知任务旨在学习语义信息。
1.词汇感知预训练任务
知识屏蔽任务:ERNIE 1.0提出了一个有效的策略,通过知识整合来增强表示。它引入了短语屏蔽和命名实体屏蔽,并预测整个被屏蔽的短语和命名实体,以帮助模型学习本地语境和全局语境中的依赖性信息。我们使用这个任务来训练模型的初始版本。
大写字母预测任务:与句子中的其他单词相比,大写字母通常具有某些特定的语义信息。大写字母模型在命名实体识别等任务中具有一些优势,而非大写字母模型则更适合于其他一些任务。为了结合两种模型的优势,我们增加了一个预测单词是否大写的任务。
标记-文档关系预测任务:这个任务预测一个片段中的标记是否出现在原始文档的其他片段中。根据经验,出现在文档许多部分的词通常是常用的词或与文档的主要主题有关。因此,通过识别出现在片段中的文档常见词,可以使模型在一定程度上捕捉到文档的关键词。
2.结构感知的预训练任务
句子重新排序任务:这个任务旨在学习句子之间的关系。在这个任务的预训练过程中,一个给定的段落被随机分割成1到m个片段,然后所有的组合被随机排列洗牌。我们让预训练模型来重组这些被打乱的段落,模型是一个k分类问题,其中k = ∑m n=1 n! 根据经验,句子重新排序的任务可以使预训练的模型学习文档中句子之间的关系。
句子距离任务:我们还构建了一个预训练任务,利用文档级信息学习句子距离。这个任务被建模为一个三类分类问题。"0 "代表两个句子在同一个文档中是相邻的,"1 "代表两个句子在同一个文档中,但不相邻,"2 "代表两个句子来自两个不同的文档。
3.语义感知的预训练任务
话语关系任务:除了上面提到的距离任务外,我们还引入了一个预测两个句子之间语义或修辞关系的任务。我们使用Sileo等人建立的数据来训练英语任务的预训练模型。按照Sileo et.al的方法,我们还自动构建了一个中文数据集进行预训练。
IR相关任务:我们建立了一个预训练任务来学习信息检索中的短文相关度。这是一个3类分类任务,预测查询和标题之间的关系。我们把查询作为第一句,把标题作为第二句。
来自商业搜索引擎的搜索日志数据被用作我们的预训练数据。这个任务有三种标签。被标记为 "0 "的查询和标题对代表强相关性,这意味着用户在输入查询后点击了标题。标为 "1 "的代表弱相关性,这意味着当用户输入查询后,这些标题出现在搜索结果中,但没有被用户点击。标记为 "2 "意味着查询和标题在语义信息方面是完全不相关和随机的。
实验
我们将ERNIE 2.0的性能与最先进的预训练模型进行比较。对于英语任务,我们将我们的结果与BERT和XLNet在GLUE上进行比较。对于中文任务,我们在几个中文数据集上与BERT和之前的ERNIE 1.0模型的结果进行比较。此外,我们将把我们的方法与多任务学习和传统的持续学习进行比较。
表1:预训练任务和预训练数据集之间的关系。我们使用不同的预训练数据集来构建不同的任务。一个类型的预训练数据集可以对应多个预训练任务。
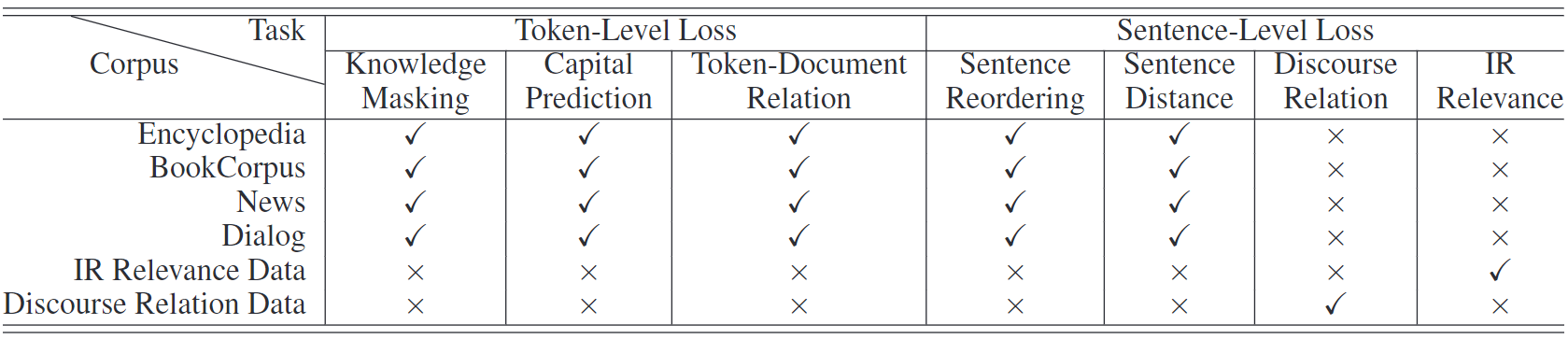
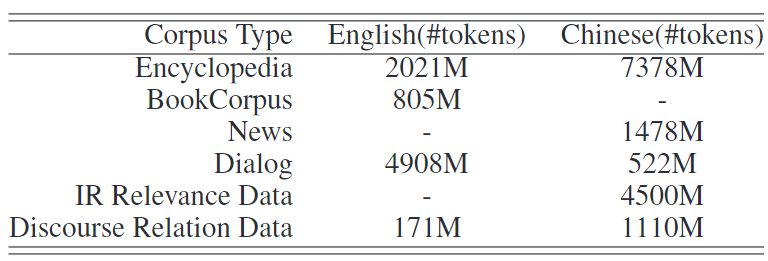
表2:预训练数据集的大小
预训练及其实现
预训练数据:与BERT类似,英语语料库中的一些数据是从Wikipedia和BookCorpus抓取的。此外,我们还从Reddit收集一些数据,并使用Discovery数据作为我们的话语关系数据。对于中文语料库,我们从搜索引擎中收集各种数据,如百科全书、新闻、对话、信息检索和对话关系数据。预训练数据的详情见表2。预训练任务和预训练数据集之间的关系如表1所示。
预训练设置:为了与BERT进行比较,我们使用了与BERT相同的模型设置的转化器。基础模型包含12层,12个自注意头和768维的隐藏大小,而大模型包含24层,16个自注意头和1024维的隐藏大小。XLNet的模型设置与BERT相同。
ERNIE 2.0在48块NVidia v100 GPU卡上训练基本模型,在64块NVidia v100 GPU卡上训练大模型的英文和中文。ERNIE 2.0框架是在PaddlePaddle上实现的,这是一个由百度开发的端到端的开源深度学习平台。我们使用Adam优化器,其参数固定为β1=0.9,β2=0.98,批量大小为393216个标记。英语模型的学习率被设定为5e-5,中文模型为1.28e-4。它由衰减方案noam设置,对每个预训练任务的前4000步进行热身。凭借float16操作,我们设法加速训练并减少我们模型的内存使用。每个预训练任务都被训练,直到预训练任务的指标收敛。
微调任务
英语任务:作为自然语言理解的多任务基准和分析平台,通用语言理解评估(GLUE)通常被用来评估模型的性能。我们也在GLUE上测试ERNIE 2.0的性能。具体来说,GLUE涵盖了多样化的NLP数据集。
中文任务:我们对9个中文NLP任务进行了广泛的实验,包括机器阅读理解、命名实体识别、自然语言推理、语义相似性、情感分析和问题回答。具体来说,我们选择了以下中文数据集来评估ERNIE 2.0在中文任务上的表现:
机器阅读理解(MRC):CMRC2018,DRCD,和DuReader。
命名实体识别(NER):MSRA-NER。
自然语言推理(NLI):XNLI。
情感分析(SA):ChnSentiCorp。
语义相似度(SS):LCQMC,BQ语料库。
问题回答(QA):NLPCC-DBQA。
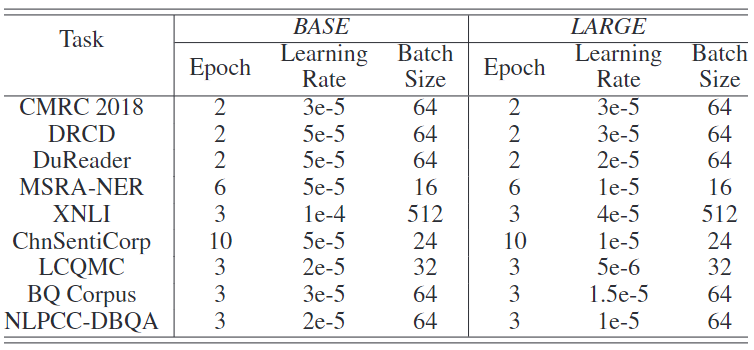
微调的实施细节:英语任务的详细微调实验设置见表3,中文任务的设置见表4。
表3:GLUE数据集的实验设置
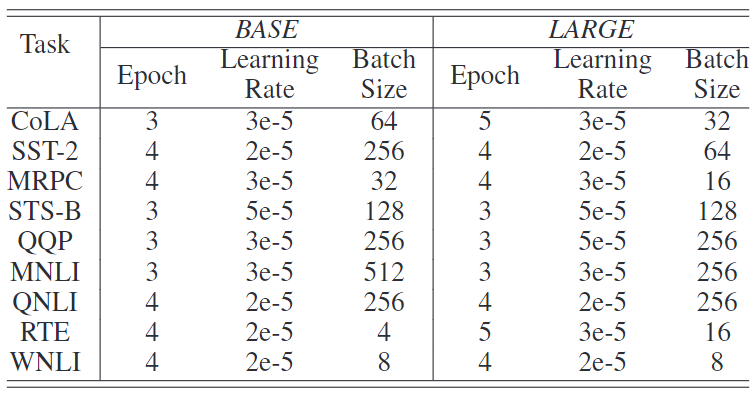
表4:中文数据集的实验设置
实验结果
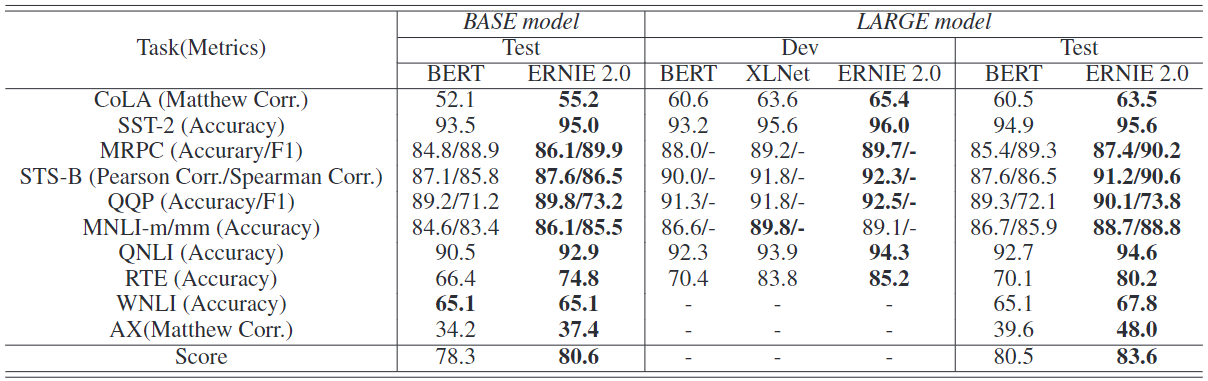
英语任务的结果:我们评估了基础模型和每种方法的大型模型在GLUE上的表现。考虑到只有单一模型XLNet在开发集上的结果被报告,我们也报告了每种方法在开发集上的结果。为了获得与BERT和XLNet的公平比较,我们在设计集上运行了单任务和单模型ERNIE 2.0。关于GLUE的详细结果在表5中描述。
如表5的BASE模型列所示,ERNIE 2.0BASE在所有10个任务上都优于BERTBASE,获得了80.6分。如表5中LARGE模型部分的dev列所示,ERNIE 2.0LARGE在除MNLI-m之外的大多数任务上始终优于BERTLARGE和XLNetLARGE。此外,如表5中LARGE模型部分所示,ERNIE 2.0LARGE在所有10个任务上都优于BERTLARGE,它在GLUE测试集上得到了83.6分,比之前的SOTA预训练模型BERTLARGE实现了3.1%的改进。
表5:GLUE基准测试的结果,其中设计集的结果是五次运行的中位数,测试集的结果由GLUE评估服务器打分,最先进的结果用粗体表示。所有AX的微调模型都是由MNLI的数据训练的。
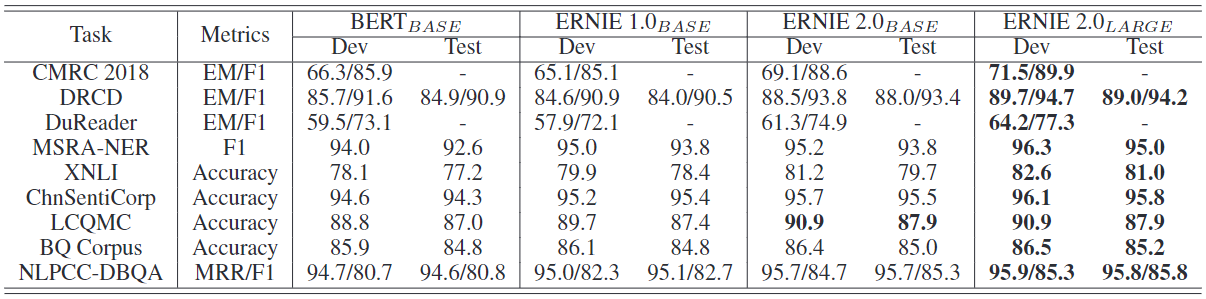
中文任务的结果:表6显示了在9个经典的中文NLP任务上的表现。可以看出,ERNIE 1.0BASE在XNLI、MSRA-NER、ChnSentiCorp、LCQMC和NLPCC-DBQA任务上的表现优于BERTBASE,但在其余任务上的表现却不太理想,这是由两种方法的预训练差异造成的。具体来说,ERNIE 1.0BASE的预训练数据不包含长度超过128的实例,但BERTBASE是用长度为512的实例预训练的。从结果中还可以看出,所提出的ERNIE 2.0取得了进一步的进展,它在所有九个任务上的表现都远远超过了BERTBASE。此外,我们还训练了一个大型版本的ERNIE 2.0。ERNIE 2.0LARGE在这些中文NLP任务上取得了最好的性能,并创造了新的最先进的结果。
表6:9个常见的中文NLP任务的结果。报告的结果是五个实验结果的平均值,最先进的结果用黑体字表示。
不同学习方法的比较:为了分析我们框架中采用的持续多任务学习策略的有效性,我们将这种方法与其他两种方法进行了比较,如图2所示。表7描述了详细的信息。对于所有的方法,我们假设每个任务的训练迭代都是一样的。在我们的设置中,每个任务可以在50k次迭代中进行训练,所有任务的迭代次数为200k次。
表7:不同持续预训练方法的结果。我们使用知识遮蔽、大写字母预测、标记文档关系和句子重排序作为我们的预训练任务。我们从整个预训练语料库中抽取10%的训练数据。在多任务学习方法中,我们用4个任务来训练模型,在其他两种学习方法中,我们分4个阶段训练模型。我们在不同的阶段训练不同的任务。这些任务的学习顺序与上面列出的任务相同。为了公平地比较结果,这4个任务中的每一个都以50,000步进行更新。预训练模型的大小与ERNIEBASE相同。我们选择MNLI-m、SST-2和MRPC作为我们的微调数据集。微调结果是五个随机开始的平均数。微调实验集与表3相同。
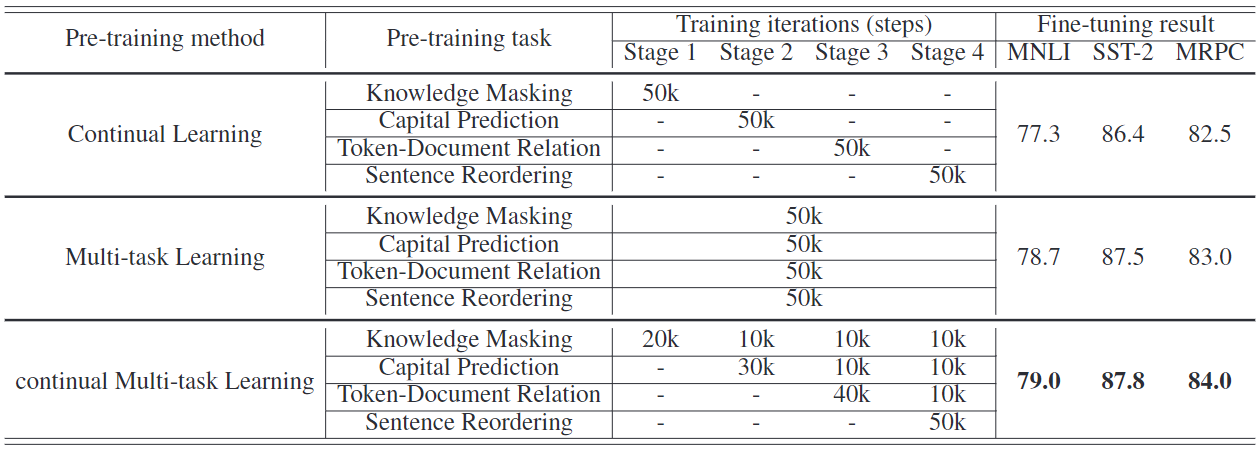
可以看出,多任务学习在一个阶段训练所有的任务,持续预训练逐个训练任务,而我们的持续多任务学习方法可以在不同的训练阶段给每个任务分配不同的迭代。实验结果表明,与另外两种方法相比,连续多任务学习在下游任务上获得了更好的表现,而且没有牺牲任何效率。实验结果还表明,我们的预训练方法能够以更有效的方式训练新任务。此外,持续多任务学习、多任务学习和传统的持续学习之间的比较表明,前两种方法优于第三种方法,这证实了我们的直觉,即当每次只涉及一个新任务时,传统的持续学习倾向于忘记它所学的知识。
结论
我们提出了一个名为ERNIE 2.0的持续预训练框架,其中预训练任务可以通过持续的多任务学习以持续的方式逐步建立和学习。基于该框架,我们构建了几个涵盖语言不同方面的预训练任务,并训练了一个名为ERNIE 2.0的新模型,该模型在语言表述方面更有能力。ERNIE 2.0在GLUE基准和各种中文任务上进行了测试。与BERT和XLNet相比,它获得了明显的改进。在未来,我们将为ERNIE 2.0框架引入更多的预训练任务,以进一步提高模型的性能。我们还将在我们的框架中研究其他复杂的持续学习方法。




![[网络] https是什么?https是怎么保障我们信息传输的安全的?](https://img-blog.csdnimg.cn/a44836fc2d014f3aa8c9254392fcc05e.png)