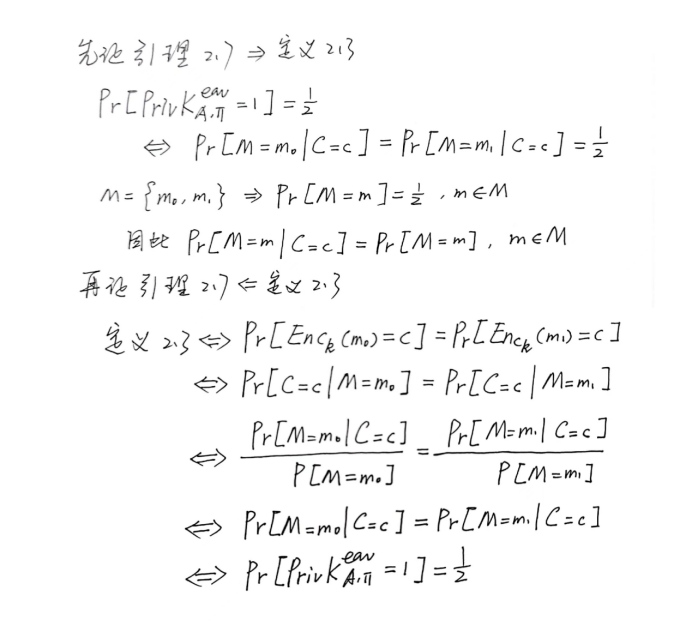目录
一.新征程开始 - 道阻且长
二.从源码入手 - 一探究竟
1.Tokenizer
2.UnaryTransformer
三.取源码精髓 - 照猫画虎
四.从实际出发 - 小试牛刀
五.扫重重障碍 - 补阙挂漏
1.Task not serializable
2.jsonEncode only supports string
3.Invisibility Error
4.Non-Writable stage
5.org.example.JiebaTokenizer.read()
六.慢慢人生路 - 学成归来
一.新征程开始 - 道阻且长

上文介绍豆瓣评论情感分析时,使用自定义 Transformer 实现了 JiebaTokenizer 完成了对 DataFrame 数据进行分词的需求,本文将基于 JiebaTokenizer 的实现细节详解如何自定义实现 Transformer 以及实战中可能遇到的坑。
二.从源码入手 - 一探究竟
自定义 Transformer 前,我们先看看 Spark ML 现有的 Transformer 是怎么实现的,正所谓俗话知己知彼百战不殆。

1.Tokenizer
Tokenizer 来自 org.apache.spark.ml.feature 官方库,负责根据空格将文本数据的分词:

可以看到 Tokenizer 继承 UnaryTransformer 实现了 Transform 方法,所以我们下面还得结合 UnaryTransformer 回看 Tokenizer 的方法。
2.UnaryTransformer

A.参数形式
![]()
这里和 Flink 的 ProcessFunction 很像,IN、OUT 代表输入输出类型, S <: T 代表 S必须是T的子类或者同类,这里实现时 extend UnaryTransformer,所以肯定满足第三个条件,我们只需定义输入输出类型即可:

Tokenizer 的开头我们便理解了,该函数接收 String 字符串,返回 Seq[String] 的分词。
B.SetInputCol、SetOutputCol

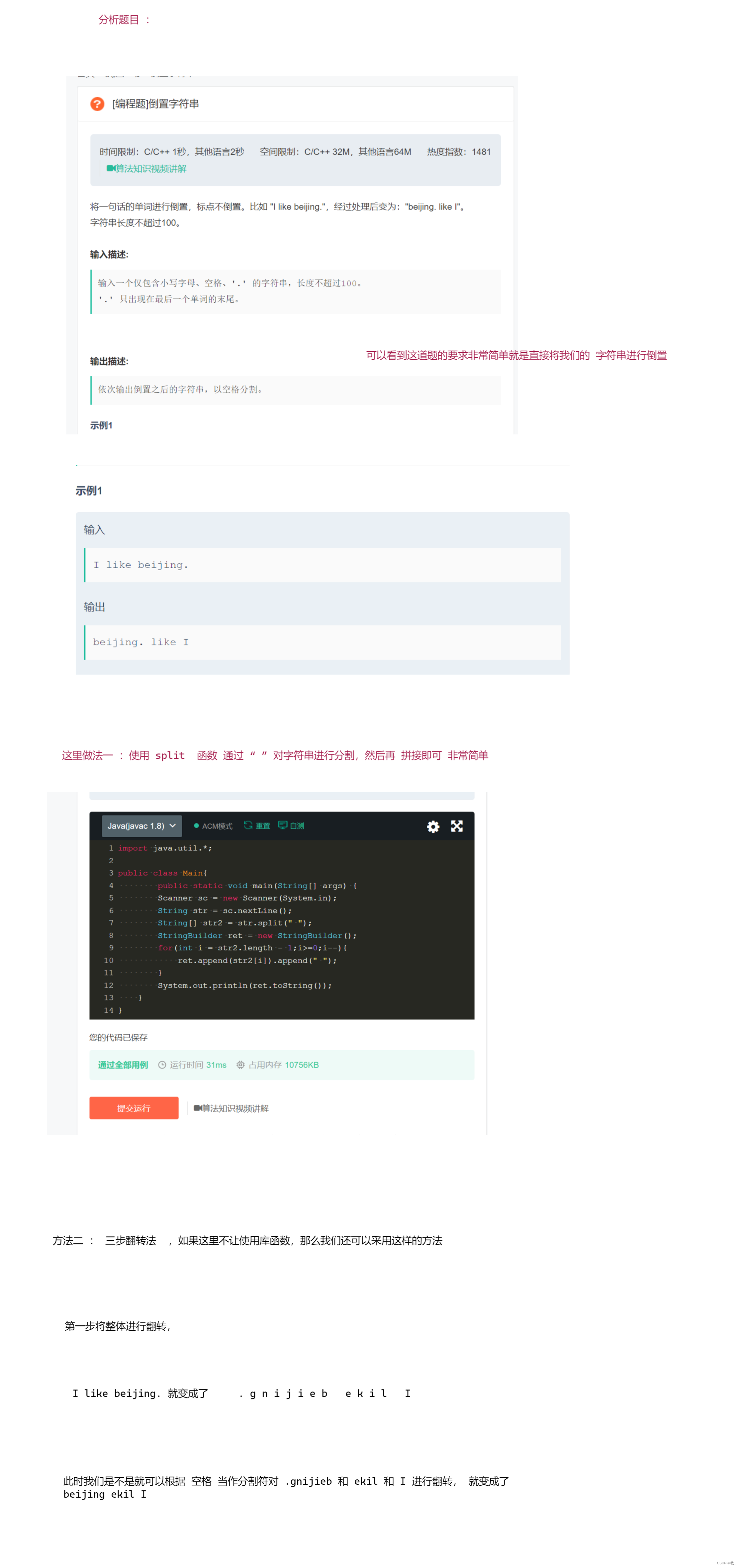
本质上,输入与输出的列名也是 Param 的一部分,因为 set 方法负责当前 Transformer 的所有参数配置,以上面 extends 的 HasInputCol 为例:
Transformer 内自定义参数需要使用 Param 类,定义参数所在类、名称与描述,但是该参数无法直接使用,其类型为 Param[T],如果想要在 transform 方法中使用,需要调用 $(Param[T]) 即可获取对应参数 T。以上文 JiebaTokenizer 为例,如果用户每次想要自定义 StopWords 并通过参数传入,只需在自定义函数内添加如下几行:
// 定义参数
final val stopwords = new Param[Set[String]](this, "StopWords", "停用词")
// 参数设置
def setStopWords(stopWords: Set[String]): this.type = set(stopwords, stopWords)
// 获取参数
def getStopWords: Set[String] = $(stopwords)添加后即可像官方 API 一样通过有回调的 Set 方法依次配置 Transformer 参数:

C.createTransformFunc

将输入转换为输出,说白了就是一个基本的 map 函数,就像 Hive UDF 一样,一进一出。该方法为整个代码类的核心所在,决定了 transform 如何转化数据。

Tokenizer 的实现即将输入字符 _ 先转小写再分割,我们自定义 \t 分词可以采用如下方式,更加清晰:
override protected def createTransformFunc: String => Array[String] = {
parseContent
}
/**
* \t 分词
*/
private def parseContent(text: String): Array[String] = {
text.split("\t")
}D.InputType 、OutputType
作用分别为验证输入类型与返回输出类型,前者主要用于输入数据的判断,如果数据类型不对则抛出异常警告⚠️开发者,后者返回输出类型主要用户后续 DataFrame Schem 类型判断。
override protected def validateInputType(inputType: DataType): Unit = {
require(inputType == StringType,
s"Input type must be ${StringType.catalogString} type but got ${inputType.catalogString}.")
}
override protected def outputDataType: DataType = new ArrayType(StringType, true)Tokenizer 中,输入类型为 String,所以需要见检查是否为 StringType,否则抛出异常,返回值类型为 Set[String],这里规范为统一数组类型 ArrayType(StringType)。
E.transformSchema

该函数官方 API 已帮我们实现,正常情况下无需复写,可以看到其中的逻辑,首先检查输入列对应 Schema,随后判断输出列是否存在,随后在原有 Schema 的基础上增加 output 列,这里通过 StructField 实现,指定该列的列名、类型与 nullable,如果你对输出类型的 Schema 有其他需求,也可以重写该函数,或者待返回后再修改 Schema。
F.transform
override def transform(dataset: Dataset[_]): DataFrame = {
val outputSchema = transformSchema(dataset.schema, logging = true)
val transformUDF = udf(this.createTransformFunc)
dataset.withColumn($(outputCol), transformUDF(dataset($(inputCol))),
outputSchema($(outputCol)).metadata)
}transform 方法逻辑,官方已实现,主要步骤为修改原始 Schema 【根据 OutputType 在 Schema 末尾新增一列 StructField】,UDF 转换并通过 DF 的 withColumn 方法将 inputCol 的内容转化至 OutputCol。
三.取源码精髓 - 照猫画虎
通过上面的源码分析,我们知道自定义 Transformer 拢共分三步:

第一步.定义输入输出类型
第二步.添加自定义参数,没有则忽略
第三步.添加自定义 UDF
下面基于上述步骤实现自定义 jieba 分词 Transformer:
import com.huaban.analysis.jieba.JiebaSegmenter
import org.apache.spark.annotation.Since
import org.apache.spark.ml.UnaryTransformer
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.param.Param
import org.apache.spark.ml.util.{DefaultParamsReadable, DefaultParamsWritable, Identifiable, MLReader, MLWriter}
import org.apache.spark.sql.types._
class JiebaTokenizer(override val uid: String)
extends UnaryTransformer[String, Array[String], JiebaTokenizer] with DefaultParamsWritable with java.io.Serializable {
lazy val jieba = new JiebaSegmenter()
def this() = this(Identifiable.randomUID("JiebaTokenizer"))
val inputPath = "./stopwords.txt"
val stopWords = scala.io.Source.fromFile(inputPath)
.getLines().toSet
override protected def outputDataType: DataType = new ArrayType(StringType, true)
override protected def validateInputType(inputType: DataType): Unit = {
require(inputType == DataTypes.StringType,
s"Input type must be string type but got $inputType."
)
}
override protected def createTransformFunc: String => Array[String] = {
parseContent
}
/**
* Jieba 分词
*/
private def parseContent(text: String): Array[String] = {
if (text == null || text.isEmpty) {
return Array.empty[String]
}
jieba.sentenceProcess(text).toArray().map(_.toString).filter(str => !stopWords.contains(str))
}
}
object JiebaTokenizer extends DefaultParamsReadable[JiebaTokenizer] {
override def load(path: String): JiebaTokenizer = {
super.load(path)
}
}
A.StopWords
分词一般需要初始化 StopWords,这里由于是本机,所以直接通过 io.source 读取,如果打包上集群,可以将 stopwords 放置在 resources 文件中并通过 Stream 读取。
B.JiebaSegmenter
初始化 JiebaSegmenter,后续 createTransformFunc 将基于该类进行语义分割,实现分词。

这里主要分析 UDF 函数,关于输入输出类型的函数,照搬源码并修改类型即可,非常方便。👍
四.从实际出发 - 小试牛刀
下面我们在实战中使用 JiebaTokenier Transform 看一下效果:

val jiebaTokenizer = new JiebaTokenizer()
.setInputCol("comment")
.setOutputCol("output")
jiebaTokenizer.transform(trainData)
jiebaTokenizer.transform(trainData).select("movie", "comment", "output").show(10)comment 为豆瓣影评,通过分词+停用词过滤得到输出分词数组。

五.扫重重障碍 - 补阙挂漏
上面的代码是博主经过一晚上测试得到的最终版本,下面罗列下使用期间可能遇到的坑。

1.Task not serializable
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
对于常规 UDF 逻辑,例如 string.split($sep) 这些不会出错,该错误原因是因为 Transformer 中引入的第三方类,例如 JiebaSegmenter,如果第三方类位继承序列化则会报错。

解决:

此时在自定义 Transformer 类后 extends java.io.Serializable 是没有用的,需要使用 lazy 关键字修饰对应类,使其延迟初始化,从而可以在 Spark 序列化时通过运行:
lazy val jieba = new JiebaSegmenter()
2.jsonEncode only supports string
ERROR Instrumentation: java.lang.UnsupportedOperationException: The default jsonEncode only supports string, vector and matrix. org.apache.spark.ml.param.Param must override jsonEncode for scala.collection.immutable.HashSet$HashTrieSet.
为了使用官方的 Api 设置参数,我们继承 Param 实现了 StopWords: Set[String] 的 set 方法:
final val stopwords = new Param[Set[String]](this, "StopWords", "停用词")
// /** @group setParam */
def setStopWords(stopWords: Set[String]): this.type = set(stopwords, stopWords)
def getStopWords: Set[String] = $(stopwords)通过官方 API 配置:
val jiebaTokenizer = new JiebaTokenizer()
.setInputCol("comment")
.setOutputCol("output")
.setStopWords(stopWords)这样的写法虽然比较优雅,但是 PipelineModel 或者 Model 在存储时,JsonENcode 要求 Param 类型必须为 String、vector 或者 matrix,这里我们的停用词为 Hashset 形式,故在保存模型时无法存储参数,导致 model.write.save 失败,所以这里建议使用 Param 参数传入常规的 String、Int 即可。

解决:
val inputPath = "./stopwords.txt"
val stopWords = scala.io.Source.fromFile(inputPath)
.getLines().toSet直接读取本地文件 [Local模式] 或者读取 resource 文件 [集群模式] 在类内初始化,参数尽量传 String、Int,最简单但也是最有效的办法。
3.Invisibility Error
博主还尝试了另外一种参数设置方法:
var stopWords = Set.empty[String]
def setStopWords(stopWords: Set[String]): this.type = {
this.stopWords = stopWords
this
}添加自定义回调函数,并覆盖 stopWords,如此修改后,模型保存无误。 但是存在一个可见性的问题,在模型 Pipeline-Transform 阶段,由于我们手动 setStopWords 所以该 stopwords 可以生效起到过滤作用,但是在 Pipeline-Estimator 阶段,由于 stopwords 不是内置 Param,所以 model.write.save 时无法保存该 stopwods,待预测时其不会自动调用 setStopWords 方法,所以预测阶段其实停用词一直为空 set,起不到过滤作用!!!大家可以打印验证,这个问题会导致预测期间出现数据干扰项影响模型结果。
val jiebaTokenizer = new JiebaTokenizer()
.setInputCol("comment")
.setOutputCol("output")
.setStopWords(stopWords)解决:
只在 Transform 阶段使用不保存模型的场景可以使用,或者使用上面的解决方案,在类内加载。
4.Non-Writable stage
Exception in thread "main" java.lang.UnsupportedOperationException: Pipeline write will fail on this Pipeline because it contains a stage which does not implement Writable. Non-Writable stage: JiebaTokenizer_216430a184a7 of type class org.example.JiebaTokenizer
模型参数存储异常,自定义 Transformer 类如果不支持 Writable 则该 Transform 只能应用于 Transform 阶段,如果在 Pipeline 中添加未支持 Writable 的自定义类,则 Pipeline 无法保存相关类参数,从而无法 save。

解决:

继承 org.apache.spark.ml.util.DefaultParamsWritable 类即可。
5.org.example.JiebaTokenizer.read()
ERROR Instrumentation: java.lang.NoSuchMethodException: org.example.JiebaTokenizer.read()
模型保存正常,但是 PipelineModel.load 时出错,这是因为没有在自定义 Class 内初始化对应 object 并添加 read 方法,导致 Pipeline 模型读取时无法读取该类。
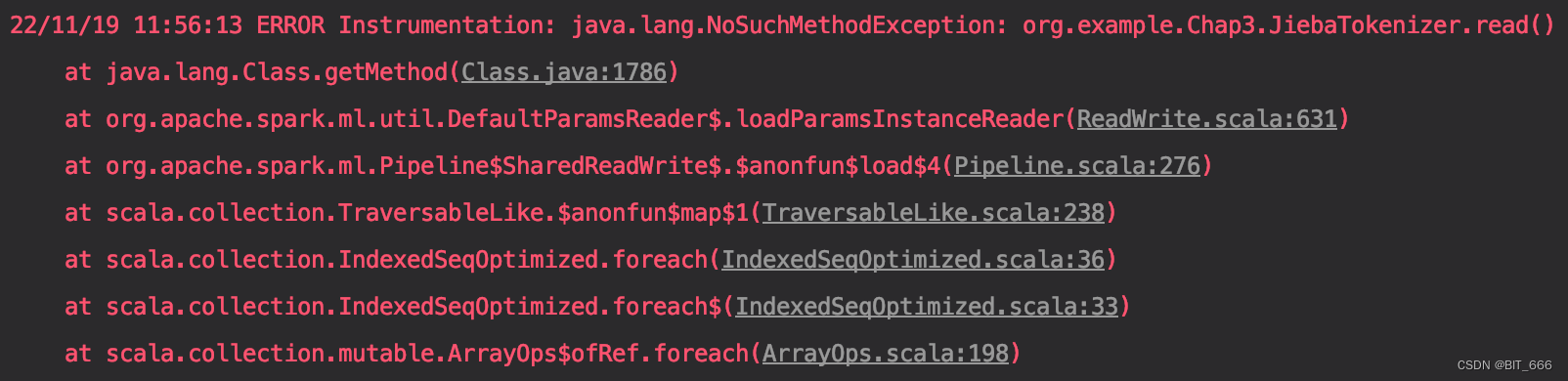
解决:
自定义类内增加 Object 并 override load 方法,方法内只需 super.load 即可。这样模型的存储和加载就都没有问题了。
object JiebaTokenizer extends DefaultParamsReadable[JiebaTokenizer] {
override def load(path: String): JiebaTokenizer = {
super.load(path)
}
}六.慢慢人生路 - 学成归来
自定义 Transformer 大致就这么多内容,大家需要注意:
- 自定义函数内是否有不可序列化的类
- 是否需要添加自定义参数并随模型保存
- Transfomrer 用于 Pipeline 哪个阶段