🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
从模型中提取建议
没有模型我们能实现什么?
使用特征统计
提取全局特征重要性
使用模型的分数
提取局部特征重要性
比较模型
版本 1:成绩单
版本 2:更强大,更不清楚
版本 3:可理解的建议
生成编辑建议
结论
这在 ML 中取得进步的最佳方法是反复遵循图 7-1中描述的迭代循环,我们在第 III 部分的介绍中看到了这一点。首先建立一个建模假设,迭代建模管道,并执行详细的错误分析以告知您的下一个假设。

图 7-1。机器学习循环
前面的章节描述了这个循环中的多个步骤。在第 5 章中,我们介绍了如何训练和评分模型。在第 6 章中,我们分享了有关如何更快地构建模型和解决 ML 相关错误的建议。本章通过首先展示使用经过训练的分类器向用户提供建议的方法,然后选择用于 ML 编辑器的模型,最后将两者结合起来构建一个工作的 ML 编辑器来结束循环的迭代。
在“ML Editor Planning”中,我们概述了我们对 ML Editor 的计划,其中包括训练一个模型,将问题分为高分和低分类别,并使用这个经过训练的模型来指导用户写出更好的问题。让我们看看如何使用这样的模型为用户提供写作建议。
从模型中提取建议
这ML Editor 的目标是提供写作建议。将问题分类为好或坏是朝着这个方向迈出的第一步,因为它可以向用户显示问题的当前质量。我们想更进一步,通过向用户提供可操作的建议来帮助他们改进问题的表述。
本节介绍提供此类建议的方法。我们将从依赖聚合特征指标且不需要在推理时使用模型的简单方法开始。然后,我们将看到如何使用模型的分数及其对扰动的敏感性来生成更加个性化的推荐。您可以在本书的 GitHub 站点上的生成推荐笔记本中找到本章中展示的应用于 ML 编辑器的每种方法的示例。
没有模型我们能实现什么?
训练一个表现良好的模型是通过 ML 循环的多次迭代来实现的。每次迭代都有助于通过研究现有技术、迭代潜在数据集和检查模型结果来创建一组更好的特征。为了向用户提供建议,您可以利用此功能迭代工作。这种方法不一定需要针对用户提交的每个问题运行一个模型,而是专注于提出一般性建议。
您可以通过直接使用这些功能或通过结合经过训练的模型来帮助选择相关功能来做到这一点。
使用特征统计
一次预测特征已经确定,它们可以直接传达给用户而无需使用模型。如果每个类别的某个特征的平均值明显不同,您可以直接共享此信息以帮助用户将他们的示例推向目标类别的方向。
我们早期为 ML Editor 确定的功能之一是问号的存在。检查数据表明,得分高的问题往往有较少的问号。要使用此信息生成推荐,我们可以编写一条规则,如果用户问题中问号的比例比高评分问题中的比例大得多,则向用户发出警告。
可以使用 pandas 在几行代码中可视化每个标签的平均特征值。
class_feature_values = feats_labels.groupby("label").mean()
class_feature_values = class_feature_values.round(3)
class_feature_values.transpose()运行前面的代码会产生表 7-1中所示的结果。在这些结果中,我们可以看到我们生成的许多特征对于高分问题和低分问题具有明显不同的值,此处标记为 True 和 False。
| Label | False | True |
|---|---|---|
| num_questions | 0.432 | 0.409 |
| num_periods | 0.814 | 0.754 |
| num_commas | 0.673 | 0.728 |
| num_exclamation | 0.019 | 0.015 |
| num_quotes | 0.216 | 0.199 |
| num_colon | 0.094 | 0.081 |
| num_stops | 10.537 | 10.610 |
| num_semicolon | 0.013 | 0.014 |
| num_words | 21.638 | 21.480 |
| num_chars | 822.104 | 967.032 |
使用特征统计是提供可靠推荐的简单方法。它在许多方面类似于我们在“最简单的方法:成为算法”中首次构建的启发式方法。
比较类之间的特征值时,可能很难确定哪些特征对以某种方式分类的问题贡献最大。为了更好地估计这一点,我们可以使用特征重要性。
提取全局特征重要性
我们首先在“评估特征重要性”中展示了在模型评估的背景下生成特征重要性的例子。特征重要性也可用于确定基于特征的推荐的优先级。在向用户显示建议时,应优先考虑对训练有素的分类器最具预测性的功能。
接下来,我展示了一个问题分类模型的特征重要性分析结果,该模型总共使用了 30 个特征。每个顶部特征的重要性都比底部特征大得多。引导用户首先基于这些顶级特征进行操作,将有助于他们根据模型更快地改进问题。
Top 5 importances:
num_chars: 0.053
num_questions: 0.051
num_periods: 0.051
ADV: 0.049
ADJ: 0.049
Bottom 5 importances:
X: 0.011
num_semicolon: 0.0076
num_exclam: 0.0072
CONJ: 0
SCONJ: 0结合特征统计和特征重要性可以使推荐更具可操作性和针对性。第一种方法为每个特征提供目标值,而后者优先显示最重要特征的较小子集。这些方法还可以快速提供建议,因为它们不需要在推理时运行模型,只需根据最重要的特征的特征统计检查输入。
正如我们在“评估特征重要性”中看到的那样,对于复杂模型而言,提取特征重要性可能更加困难。如果您使用的模型不公开特征重要性,则可以在大量示例样本上利用黑盒解释器来尝试推断它们的值。
特征重要性和特征统计有另一个缺点,即它们并不总是提供准确的推荐。由于建议是基于对整个数据集聚合的统计数据,因此它们不适用于每个单独的示例。特征统计仅提供一般性建议,例如“包含更多副词的问题往往会获得更高的评分”。然而,也有一些问题的例子,其中副词的比例低于平均水平,却获得了高分。这些建议对这些问题没有用。
在接下来的两节中,我们将介绍在单个示例级别提供更精细建议的方法。
使用模型的分数
要为 scikit-learn 模型显示分数而不是类,请使用该predict_proba函数并选择您要显示分数的类。
# probabilities is an array containing one probability per class
probabilities = clf.predict_proba(features)
# Positive probas contains only the score of the positive class
positive_probs = clf[:,1]如果校准得当,向用户显示分数可以让他们在按照建议修改问题时跟踪问题的改进,从而获得更高的分数。评分等快速反馈机制可帮助用户增强对模型提供的建议的信任感。
除了校准分数之外,经过训练的模型还可以用于提供改进特定示例的建议。
提取局部特征重要性
建议可以通过在训练模型之上使用黑盒解释器为单个示例生成。在“评估特征重要性”中,我们看到了如何黑盒解释器通过重复对输入特征应用轻微扰动并观察模型预测分数的变化来估计特征值对于特定示例的重要性。这使得此类解释器成为提供建议的绝佳工具。
from lime.lime_tabular import LimeTabularExplainer
explainer = LimeTabularExplainer(
train_df[features].values,
feature_names=features,
class_names=["low", "high"],
discretize_continuous=True,
)
idx = 8
exp = explainer.explain_instance(
test_df[features].iloc[idx, :],
clf.predict_proba,
num_features=10,
labels=(1,),
)
print(exp_array)
exp.show_in_notebook(show_table=True, show_all=False)
exp_array = exp.as_list()运行前面的代码会生成图 7-2中所示的图以及以下代码中显示的特征重要性数组。模型的预测概率显示在图的左侧。在图的中间,特征值按它们对预测的贡献排序。

图 7-2。作为建议的解释
这些值与下面更具可读性的控制台输出中的值相同。此输出中的每一行代表一个特征值及其对模型得分的影响。例如,该特征num_diff_words的值低于 88.00 会使模型的得分降低约 0.038。根据这个模型,将输入问题的长度增加到超过这个数字会提高它的质量。
[('num_diff_words <= 88.00', -0.038175093133182826),
('num_questions > 0.57', 0.022220445063244717),
('num_periods <= 0.50', 0.018064270196074716),
('ADJ <= 0.01', -0.01753028452563776),
('408.00 < num_chars <= 655.00', -0.01573650444507041),
('num_commas <= 0.39', -0.015551364531963608),
('0.00 < PROPN <= 0.00', 0.011826217792851488),
('INTJ <= 0.00', 0.011302327527387477),
('CONJ <= 0.00', 0.0),
('SCONJ <= 0.00', 0.0)]更多使用示例请参考本书GitHub仓库中的生成推荐笔记本。
黑盒解释器可以为单个模型生成准确的建议,但它们也有一个缺点。这些解释器通过扰动输入特征并在每个扰动输入上运行模型来生成估计,因此使用它们生成推荐比讨论的方法慢。例如,LIME 用于评估特征重要性的默认扰动数是 500。这使得该方法比只需要运行一次模型的方法慢两个数量级,甚至比不需要运行模型的方法慢根本。在我的笔记本电脑上,在示例问题上运行 LIME 需要 2 秒多一点。这种延迟可能会阻止我们在用户打字时向他们提供建议,并要求他们手动提交问题。
就像许多 ML 模型一样,我们在这里看到的推荐方法在准确性和延迟之间进行了权衡。对产品的正确推荐取决于其要求。
我们介绍的每种推荐方法都依赖于模型迭代期间生成的特征,其中一些还利用了经过训练的模型。在下一节中,我们将比较 ML Editor 的不同模型选项,并决定哪一个最适合推荐。
比较模型
“衡量成功”涵盖判断产品成功与否的重要指标。“Judge Performance”描述了评估模型的方法。此类方法还可用于比较模型和特征的连续迭代,以确定性能最佳的模型和特征。
在在本节中,我们将选择关键指标的一个子集,并使用它们根据模型性能和建议的实用性来评估 ML Editor 的三个连续迭代。
这ML Editor 的目标是使用提到的技术提供建议。为了支持此类建议,模型应符合以下要求。它应该被很好地校准,以便它的预测概率代表对问题质量的有意义的估计。正如我们在“衡量成功”中所述,它应该具有高精度,以便它提出的建议是准确的。它使用的功能应该是用户可以理解的,因为它们将作为推荐的基础。最后,它应该足够快以允许我们使用黑盒解释器来提供建议。
让我们描述 ML Editor 的几种连续建模方法并比较它们的性能。这些性能比较的代码可以在本书的 GitHub 存储库中的比较模型笔记本中找到。
版本 1:成绩单
在第 3 章中,我们构建了第一个完全基于启发式的编辑器版本。第一个版本使用硬编码规则来编码可读性并以结构化格式向用户显示结果。构建此管道使我们能够修改我们的方法并将 ML 工作集中在提供更清晰的建议上,而不是一组测量。
由于这个初始原型是为了培养对我们正在解决的问题的直觉而构建的,因此我们不会在这里将它与其他模型进行比较。
版本 2:更强大,更不清楚
后构建基于启发式的版本并探索 Stack Overflow 数据集,我们确定了初始建模方法。我们训练的简单模型可以在本书的GitHub仓库中的简单模型笔记本中找到。
该模型结合了使用“矢量化”中描述的方法对文本进行矢量化生成的特征,以及在数据探索期间出现的手动创建的特征。第一次探索数据集时,我注意到了一些模式:
-
更长的问题得到更高的分数。
-
专门针对英语语言使用的问题得分较低。
-
至少包含一个问号的问题得分较高。
我通过计算文本的长度、标点和缩写等词的出现以及问号的出现频率,创建了对这些假设进行编码的特征。
除了这些功能之外,我还使用 TF-IDF 对输入问题进行了矢量化处理。使用简单的矢量化方案可以让我将模型的特征重要性与单个词联系起来,这可以允许使用前面描述的方法进行词级推荐。
第一种方法显示出可接受的综合性能,精度为0.62. 然而,它的校准还有很多不足之处,如图 7-3 所示。

图 7-3。V2模型标定
检查该模型的特征重要性后,我意识到唯一可预测的手动创建特征是问题长度。其他生成的特征没有预测能力。再次探索数据集揭示了一些似乎具有预测性的特征:
-
限制使用标点符号似乎预示着高分。
-
情绪化程度更高的问题似乎得分较低。
-
描述性的和使用更多形容词的问题似乎得分更高。
为了对这些新假设进行编码,我生成了一组新的特征。我为每个可能的标点符号元素创建了计数。然后,我为每个词性类别(例如动词或形容词)创建了计数,测量问题中有多少词属于该类别。最后,我添加了一个特征来编码问题的情感情绪。有关这些功能的更多详细信息,请参阅本书 GitHub 存储库中的第二个模型笔记本。
这个更新版本的模型在总体上表现稍好,精度为0.63. 它的校准没有改进以前的模型。显示该模型的特征重要性表明该模型完全依赖于手动制作的特征,表明这些特征具有一定的预测能力。
与使用矢量化词级特征相比,让模型依赖于此类可理解的特征可以更容易地向用户解释推荐。例如,这个模型最重要的单词级特征是单词are和what。我们可以猜测为什么这些词可能与问题质量相关,但是向用户建议他们应该减少或增加问题中任意词的出现并不能提供明确的建议。
为了解决矢量化表示的这一局限性并认识到手动制作的特征具有预测性,我尝试构建一个不使用任何矢量化特征的更简单的模型。
版本 3:可理解的建议
这第三个模型只包含前面描述的特征(标点符号和词性、问题情绪和问题长度)。因此,该模型仅使用 30 个特征,而使用矢量化表示时则使用了 7,000 多个特征。有关详细信息,请参阅本书 GitHub 存储库中的第三个模型笔记本。删除矢量化特征并保留手动特征允许 ML Editor 仅利用可向用户解释的特征。但是,它可能会导致模型性能更差。
在综合性能方面,这个模型确实比以前的模型表现更差,精度为0.597. 但是,它的校准比以前的型号要好得多。在图 7-4中,您可以看到模型 3 针对大多数概率进行了很好的校准,即使是其他模型难以达到的 0.7 以上的概率。直方图显示这是由于该模型比其他模型更频繁地预测此类概率。
由于它产生的分数范围增加并且分数校准得到改进,因此该模型是显示分数以引导用户的最佳选择。在提出明确的建议时,该模型也是最佳选择,因为它仅依赖于可解释的特征。最后,因为它比其他模型依赖更少的特征,所以它也是运行最快的。
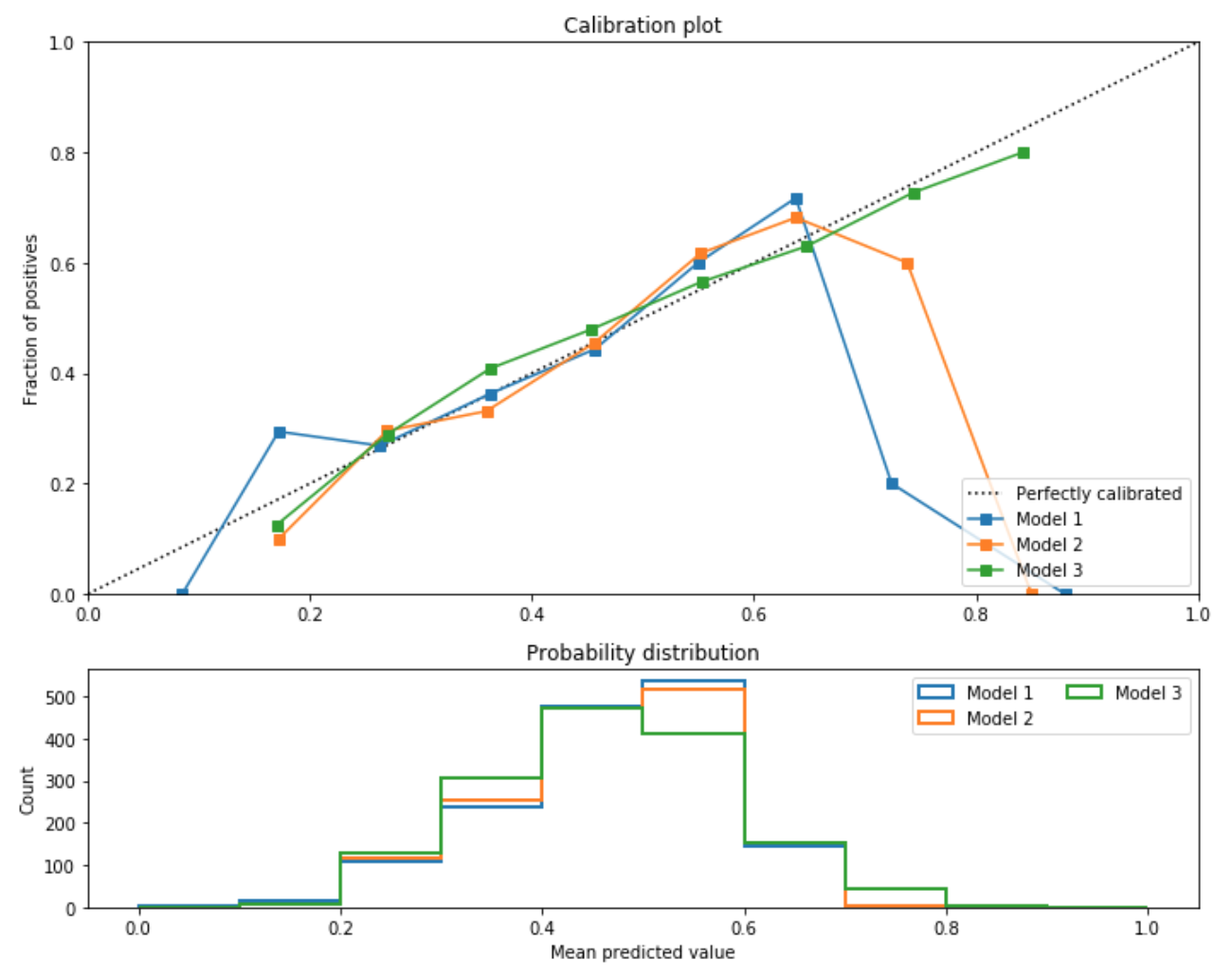
图 7-4。校准比较
Model 3 是 ML Editor 的最佳选择,因此是我们应该为初始版本部署的模型。在下一节中,我们将简要介绍如何使用此模型和推荐技术为用户提供编辑推荐。
生成编辑建议
这ML Editor 可以受益于我们描述的四种生成推荐的方法中的任何一种。事实上,所有这些方法都在本书的 GitHub 存储库中的生成推荐笔记本中进行了展示。因为我们使用的模型速度很快,所以我们将在这里说明最精细的方法,使用黑盒解释器。
让我们首先看一下接受问题并根据经过训练的模型提供编辑建议的整个推荐功能。这是这个函数的样子:
def get_recommendation_and_prediction_from_text(input_text, num_feats=10):
global clf, explainer
feats = get_features_from_input_text(input_text)
pos_score = clf.predict_proba([feats])[0][1]
exp = explainer.explain_instance(
feats, clf.predict_proba, num_features=num_feats, labels=(1,)
)
parsed_exps = parse_explanations(exp.as_list())
recs = get_recommendation_string_from_parsed_exps(parsed_exps)
return recs, pos_score在示例输入上调用此函数并漂亮地打印其结果会产生如下建议。然后我们可以向用户显示这些建议,让他们重复他们的问题。
recos, score = get_recommendation_and_prediction_from_text(example_question)
print("%s score" % score)
0.4 score
print(*recos, sep="\n")Increase question length
Increase vocabulary diversity
Increase frequency of question marks
No need to increase frequency of periods
Decrease question length
Decrease frequency of determiners
Increase frequency of commas
No need to decrease frequency of adverbs
Increase frequency of coordinating conjunctions
Increase frequency of subordinating conjunctions让我们分解这个功能。从它的签名开始,该函数将一个表示问题的输入字符串作为参数,以及一个可选参数,用于确定要推荐多少最重要的功能。它返回建议,以及代表问题当前质量的分数。
深入到问题的主体,第一行指的是两个全局定义的变量,训练模型和 LIME 解释器的实例,就像我们在“提取局部特征重要性”中定义的那样。接下来的两行从输入文本生成特征,并将这些特征传递给分类器进行预测。然后,exp通过使用 LIME 生成解释来定义。
最后两个函数调用将这些解释转化为人类可读的建议。让我们看看如何通过查看这些函数的定义,从parse_explanations.
def parse_explanations(exp_list):
global FEATURE_DISPLAY_NAMES
parsed_exps = []
for feat_bound, impact in exp_list:
conditions = feat_bound.split(" ")
# We ignore doubly bounded conditions , e.g. 1 <= a < 3 because
# they are harder to formulate as a recommendation
if len(conditions) == 3:
feat_name, order, threshold = conditions
simple_order = simplify_order_sign(order)
recommended_mod = get_recommended_modification(simple_order, impact)
parsed_exps.append(
{
"feature": feat_name,
"feature_display_name": FEATURE_DISPLAY_NAMES[feat_name],
"order": simple_order,
"threshold": threshold,
"impact": impact,
"recommendation": recommended_mod,
}
)
return parsed_exps这个函数很长,但是它完成了一个相对简单的目标。它采用 LIME 返回的特征重要性数组,并生成可用于推荐的结构化程度更高的字典。这是此转换的示例:
# exps is in the format of LIME explanations
>> exps = [('num_chars <= 408.00', -0.03908691525058592),
('DET > 0.03', -0.014685507408497802)]
>> parse_explanations(exps)
[{'feature': 'num_chars',
'feature_display_name': 'question length',
'order': '<',
'threshold': '408.00',
'impact': -0.03908691525058592,
'recommendation': 'Increase'},
{'feature': 'DET',
'feature_display_name': 'frequency of determiners',
'order': '>',
'threshold': '0.03',
'impact': -0.014685507408497802,
'recommendation': 'Decrease'}]请注意,函数调用将 LIME 显示的阈值转换为是否应增加或减少特征值的建议。这是使用get_recommended_modification此处显示的函数完成的:
def get_recommended_modification(simple_order, impact):
bigger_than_threshold = simple_order == ">"
has_positive_impact = impact > 0
if bigger_than_threshold and has_positive_impact:
return "No need to decrease"
if not bigger_than_threshold and not has_positive_impact:
return "Increase"
if bigger_than_threshold and not has_positive_impact:
return "Decrease"
if not bigger_than_threshold and has_positive_impact:
return "No need to increase"一旦解释被解析为建议,剩下的就是以适当的格式显示它们。这是由 中的最后一个函数调用完成的get_recommendation_and_prediction_from_text,如下所示:
def get_recommendation_string_from_parsed_exps(exp_list):
recommendations = []
for feature_exp in exp_list:
recommendation = "%s %s" % (
feature_exp["recommendation"],
feature_exp["feature_display_name"],
)
recommendations.append(recommendation)
return recommendations如果您想试用此编辑器并对其进行迭代,请随时参考本书 GitHub 存储库中的生成建议笔记本。在笔记本的末尾,我包含了一个使用模型建议多次改写问题并提高其分数的示例。我在这里复制这个例子来演示如何使用这些建议来指导用户编辑问题。
// First attempt at a question
>> get_recommendation_and_prediction_from_text(
"""
I want to learn how models are made
"""
)
0.39 score
Increase question length
Increase vocabulary diversity
Increase frequency of question marks
No need to increase frequency of periods
No need to decrease frequency of stop words
// Following the first three recommendations
>> get_recommendation_and_prediction_from_text(
"""
I'd like to learn about building machine learning products.
Are there any good product focused resources?
Would you be able to recommend educational books?
"""
)
0.48 score
Increase question length
Increase vocabulary diversity
Increase frequency of adverbs
No need to decrease frequency of question marks
Increase frequency of commas
// Following the recommendations once more
>> get_recommendation_and_prediction_from_text(
"""
I'd like to learn more about ML, specifically how to build ML products.
When I attempt to build such products, I always face the same challenge:
how do you go beyond a model?
What are the best practices to use a model in a concrete application?
Are there any good product focused resources?
Would you be able to recommend educational books?
"""
)
0.53 score瞧,我们现在有了一个可以接受问题并向用户提供可操作建议的管道。这个管道绝不是完美的,但我们现在有一个工作的端到端 ML 驱动的编辑器。如果您想尝试改进它,我鼓励您与当前版本进行交互并确定要解决的故障模式。有趣的是,虽然模型总是可以迭代的,但我认为这个编辑器最有希望改进的方面是生成用户更清楚的新功能。
结论
在本章中,我们介绍了从经过训练的分类模型生成建议的不同方法。考虑到这些方法,我们比较了 ML Editor 的不同建模方法,并选择了一种可以优化我们帮助用户提出更好问题的产品目标的方法。然后,我们为 ML Editor 构建了一个端到端的管道,并用它来提供建议。
我们确定的模型仍有很大的改进空间,可以从更多的迭代周期中受益。如果您想练习使用我们在第 III 部分中概述的概念,我鼓励您自己完成这些循环。总体而言,第 III 部分中的每一章都代表 ML 迭代循环的一个方面。要在 ML 项目上取得进展,请重复执行本节中概述的步骤,直到您估计模型已准备好部署。
在第 IV 部分中,我们将介绍部署模型所带来的风险、如何减轻这些风险,以及监控和应对模型性能可变性的方法。