目录
磁盘的结构
磁盘的抽象(虚拟,逻辑)结构
分区
Block Group 块组:
分析:
文件名 vs inode编号
创建/删除/查看 一个文件,操作系统做了什么?
软硬链接
软连接
硬链接
对比:
硬链接数
文件,按照有没有被进程打开可以分为内存级文件和磁盘级文件。被某个进程打开的文件需要加载到内存,OS为了管理这些文件,会设立struct file结构体,还有进程PCB中的files指针指向结构体中的文件描述符表,存储进程打开的struct file的地址,这是之前所了解的内存级文件。
若一个文件没有被任何进程打开,则应该存储在磁盘中,我们接下来要了解的就是这部分磁盘级文件。
磁盘的结构

1. 内存:掉电易失存储介质 磁盘:永久性存储介质
2. 磁盘通过是否磁化来表示01,从而存储二进制数据,而磁化性是通过磁头改变的。向磁盘写入,本质就是改变盘面上的磁化性,即磁化或未磁化。
3. 如上图,磁盘存储数据的基本单位是扇区,一个扇区传统为512字节,即0.5KB。
4. CHS寻址:C表示磁道(柱面),H表示盘面,S表示扇区。也就是,通过盘片的旋转和磁头的左右摆动,确定哪一个磁道,哪一个盘面,哪一个扇区。即可找到磁盘中的任何一个扇区,即可通过磁头读写该扇区。这是磁盘物理上的的寻址方式。
磁盘的抽象(虚拟,逻辑)结构
操作系统为了更好地管理访问磁盘中的数据,将磁盘的这种物理上的圆形结构抽象为线性数组结构,数组的每个元素都是一个扇区,即sector disk[1024*1024*N],这样访问某一个扇区,只需要知道数组下标即可。这种称为LBA (Logical Block Addressing)逻辑块寻址模式。只需要将LBA转化为CHS,即可访问到磁盘的任何一个扇区。
分区
抽象为线性的数组结构之后,一个磁盘很大因此很难管理,所以操作系统将其进行分区操作。分为若干个区之后,对磁盘的管理->对一个小分区的管理。(每个分区的大小不一定相同)

对于每一个小分区,都有如上结构,一个Boot Block和若干个块组Block Group。
Boot Block称为启动块,存储了磁盘的分区信息和启动信息等...每个分区都存储一份是备份的作用
块组Block Group是磁盘分区后的基本单位。相当于对每个分区又进行了划分,下面主要了解块组的组成。
Block Group 块组:
前言:
1. 文件 = 内容 + 属性。Linux在磁盘上存储文件时,是将内容和属性分开存储。
2. inode是一个128字节的空间,保存的是对应文件的属性,属性中有一个inode编号字段。一般而言,一个文件,一个inode,一个inode编号。
3. 磁盘的存储基本单位是扇区,但是操作系统(文件系统)和磁盘进行IO时基本单位是4KB。而一个4KB空间称为一个块 block。故磁盘又称为块设备。
4. 文件的内容是存储在若干个block中的,一个块组内的block的集合就是Data blocks,它是多个4KB的集合。存储的是文件的内容
Super Block:
存储文件系统的属性信息。(简单了解)
GDT:块组描述符表,存储这个块组的各种属性信息,比如一共多大空间,已用多少,有多少个inode,多少个block,分别使用了多少....
inode Table:
这个块组内,所有文件的inode集合。可以理解为inode的数组。inode存储的是对应文件的属性,一个文件一个inode一个inode编号。
Data blocks:
Data blocks即多个4KB空间,也就是多个块的集合,这里保存的是文件的内容。
Block Bitmap:
一个块组内会有多个block,组成Data blocks。而这里的Block Bitmap是一个位图结构,用比特位和对应的block映射联系起来,用比特位的01表示对应block的占用情况! 没错,这里就是哈希思想的那个位图数据结构。
inode Bitmap:
一个块组内的所有inode组成inode Table,同理,这里是一个位图数据结构,用于表示对应inode空间的占用情况。假设有10000+个inode,则就有10000+个比特位。
分析:
综上,我们知道,一个文件的属性存储在一个对应的inode中,inode中有一个inode编号,具有唯一性,对应唯一一个文件。内容存储在若干个block中,每一个block4KB(文件占用block的个数取决于文件内容数据的大小)。
疑问1:一个文件的inode,如何和存储这个文件内容的若干个block对应起来?
inode中,保存对应文件的属性,比如文件大小,创建时间,拥有者,所属组等等... 其中还有一个字段,比如 int blocks[15]; 这里存储的是 和此inode同一个块组的保存对应文件内容的块的编号。这样,找到一个文件的inode,就能找到这个文件的属性+内容!
疑问2:如果一个文件的内容数据非常多,15个block不够怎么办?
解决方法:若15个不够,则将某几个block中不存储文件内容,而是存储其他block的编号,这些扩展block存储对应文件的内容,如果不够,还可以再扩展。(这里简单了解即可,总之是有方法的)
综上inode编号和文件一一对应。获得文件的inode编号 -> 特定分区的特定的块组 -> 找到inode -> 文件的内容 + 属性。
可是怎么获得文件的inode编号呢,我们在日常使用的文件名又是有什么用?
依托于目录结构!
文件名 vs inode编号
文件的属性存储在inode中,内容存储在若干block中。
=》 文件的inode中并没有文件名这种概念! 只有inode编号和其他文件属性。
=》 目录也是文件,目录也有inode和inode编号,内容存储在block中。
=》 目录的内容存储是该目录下保存的文件的文件名 和 对应的inode编号 的映射关系!可以理解为key value结构,且这里的文件名和 inode编号互为key,因为一个目录下文件名不能重复。
=》 因此,我们使用文件名,文件所属目录的内容中存储文件名及其对应的inode编号,找到inode编号 -> inode -> 属性+内容。 这些都依托于目录结构。
综上,我们再次理解,为什么,进入目录需要X执行权限,在目录中创建和删除文件需要目录的W写权限,显示目录中文件的文件名和属性需要R读权限。
因为在目录中创建文件,需要在所属目录的内容中写 文件名 和 inode编号的映射对,因此需要写权限。
显示目录中的文件名和属性需要读目录内容中的文件名和inode编号,通过inode编号找到对应文件的属性,再拼接打印出来,因此需要目录的读权限。
同理,之前一个经典问题是删除一个文件需要什么权限,结合这里,很合理地需要对目录的写权限。因为要删除目录内容中的文件名,inode编号映射对!
创建/删除/查看 一个文件,操作系统做了什么?
创建一个文件:
根据文件系统的信息,确定一个保存这个文件的分区和块组。在块组的inode bitmap中遍历找到比特位为0的位,将其置为1,再去inode table中找到对应的inode,将新建文件的所有属性写入这个inode中。因为是新建的,所以没有内容,因此inode中的块映射可以为空。等后面再写入文件内容时,可以去对应块组中的block bitmap中找为0的位,置为1,再去对应的块中写入数据。
同时,将用户输入的文件名和文件系统返回的inode编号的映射关系写入到文件所属目录的内容中。 (大致和关键步骤就是这些,或许有偏差,有遗漏)
删除一个文件:
找到这个文件所属目录的data block,根据用户输入的要删除的文件的文件名,作为key值,在目录的data blocks中找到inode编号,找到inode,将inode bitmap中该inode的比特位由1置为0,将此文件占用的data block的block bitmap中的对应比特位由1置为0。 最后将所属目录的内容中的文件名 inode编号映射关系删除掉。即可 (或许有偏差)
注意,删除文件不需要将inode清空,将data block内容清空,这不重要,也不影响。只需要将inode位图和block位图中的比特位置为0即可。(这也是为什么下载一个东西很慢,而删除只需要很短的时间的原因)基于上述删除文件的规则,其实删除一个文件之后,若文件占用的inode和block 没有被再次占用写入,则恢复文件是完全可以做到的!
写入一个文件:
结合前面基础IO的缓冲区的知识。当我们向文件中写入数据时,这个文件一定被某个进程打开了,操作系统在内存中创建对应的struct file,这个file结构体中有对应文件的内核级缓冲区,写入的数据会先保存在内存的缓冲区中,等待刷新条件达成,根据文件的inode编号(可以根据所属目录获取,或许也可以在file中找到),找到inode,在block bitmap中找比特位为0的block,将内存中的缓冲数据刷新到对应的block中,同时修改inode内存储的block映射关系。
(和上面的基本都是一个道理)
有没有可能,磁盘还有空间,但是新建文件失败,或者向文件写入数据失败?
因为inode和block的数量是有限的,且一定的。所以上方情况完全有可能发生。比如inode还有,但是block没有空余的了。也就是block bitmap全为1,致使写入数据失败。 或者block还有,但是inode没有了,inode bitmap全为1,致使新建文件失败。 这一切都和磁盘的存储结构有关!
软硬链接
软连接


ln -s proc links 即可创建一个链接到proc可执行程序的软连接links。
软链接是一个独立的文件,有自己的inode,inode编号,可以理解为软链接文件的内容是指向文件的路径。相当于windows下的快捷方式。
硬链接
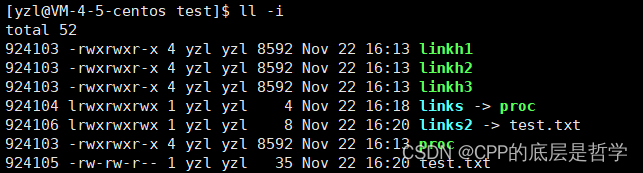
ln proc linkh1 即可创建proc可执行程序的硬链接linkh1
硬链接不是一个独立的文件,它的inode和inode编号和所链接目标文件是同一个。
创建一个硬链接,不是创建一个新文件,本质上,只是在所在目录的data block存储的目录内容中,添加一个文件名 inode编号映射对。仅此而已。
对比:
软链接和硬链接的本质区别就是:有没有独立的inode。软链接有独立的inode,硬链接没有独立的inode,它的inode就是链接文件的inode,共用一个。
因为本质上的区别,致使,当删除文件时,软链接的链接关系失效,而硬链接不会失效,因为建立硬链接之后,硬链接和原文件其实就没什么关系了,只是它们的inode一样,文件名不一样。删除链接文件不影响硬链接。
硬链接数
在我们删除proc可执行程序后,linkh1 linkh2等硬链接都没有失效,这样是怎么实现的呢?
inode存储这个文件的属性信息,其中有一个字段是引用计数字段,也就是记录有多少个文件名和此文件关联。这个就是硬链接数,即上图中的文件属性的第二列。
当我们删除一个文件时,并不是直接删除这个文件,而是将此文件的inode中的引用计数--,当等于0时,才执行删除文件的操作。
这也是为什么,当我们在Linux下新建一个目录时,目录的默认硬链接数就是2。
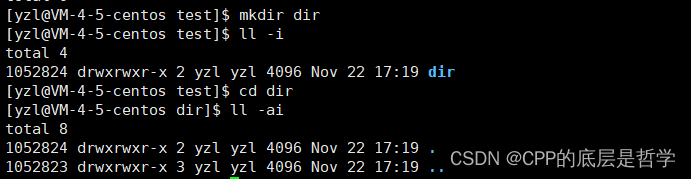
因为每一个目录下都有两个名为. 和 ..的文件,这两个文件就是两个硬链接。.文件链接dir可以看到它们的inode编号是一样的。因此我们在执行一个可执行程序时,输入./test指令,可以执行test可执行程序。
而如果在目录下新建一个子目录,则这个目录的硬链接数+1,因为子目录中有..文件,此硬链接链接的就是上级目录。其实就是这个文件名和上级目录共用一个inode。仅此而已。







![[LeetCode/力扣][Java] 0315. 计算右侧小于当前元素的个数(Count of Smaller Numbers After Self)](https://img-blog.csdnimg.cn/1e020d625eac4cf6aa7dc4c23935f875.png#pic_center)