🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
软件最佳实践
ML 特定的最佳实践
调试接线:可视化和测试
从一个例子开始
可视化步骤
数据加载
清洁和功能选择
特征生成
数据格式化
模型输出
系统化我们的视觉验证
分离你的顾虑
测试您的机器学习代码
测试数据摄取
测试数据处理
测试模型输出
调试训练:让你的模型学习
任务难度
数据质量、数量和多样性
数据表示
型号容量
优化问题
调试泛化:使您的模型有用
数据泄露
过拟合
正则化
数据扩充
数据集重新设计
考虑手头的任务
结论
使管道达到令人满意的性能水平很困难,需要多次迭代。本章的目标是指导您完成一个这样的迭代周期。在本章中,我将介绍调试建模管道的工具以及编写测试以确保它们在我们开始更改后仍能正常工作的方法。
软件最佳实践鼓励从业者定期测试、验证和检查他们的代码,尤其是安全或输入解析等敏感步骤。这对于 ML 应该没有什么不同,与传统软件相比,模型中的错误更难检测。
我们将介绍一些技巧,帮助您确保您的管道稳健,并且您可以尝试它而不会导致整个系统出现故障,但首先让我们深入了解软件最佳实践!
软件最佳实践
为了在大多数 ML 项目中,您将重复构建模型、分析其缺点并多次解决这些问题的过程。您还可能不止一次更改基础架构的每个部分,因此找到提高迭代速度的方法至关重要。
在ML 就像任何其他软件项目一样,您应该遵循经过时间考验的软件最佳实践。它们中的大多数无需修改即可应用于 ML 项目,例如只构建您需要的东西,通常称为 Keep It Stupid Simple ( KISS ) 原则。
ML 项目本质上是迭代的,会经历许多不同的数据清理和特征生成算法迭代,以及模型选择。即使遵循这些最佳实践,两个领域也常常最终会降低迭代速度:调试和测试。加快调试和测试编写会对任何项目产生重大影响,但对于 ML 项目更为重要,因为模型的随机性通常会将一个简单的错误变成长达数天的调查。
许多存在可帮助您学习如何调试一般程序的资源,例如芝加哥大学的简明调试指南。如果像大多数 ML 从业者一样,您选择的语言是 Python,我建议您查看标准库调试器pdb的 Python 文档。
然而,与大多数软件相比,ML 代码通常可以看似正确地执行,但会产生完全荒谬的结果。这意味着虽然这些工具和提示适用于大多数 ML 代码,但它们不足以诊断常见问题。我在图 6-1中说明了这一点:虽然在大多数软件应用程序中,拥有强大的测试覆盖率可以让我们对我们的应用程序运行良好充满信心,但 ML 管道可以通过许多测试,但仍然会给出完全错误的结果。机器学习程序不仅要运行——它还应该产生准确的预测输出。

图 6-1。ML 管道可以无错误地执行,但仍然是错误的
由于 ML 在调试方面提出了一系列额外的挑战,因此让我们介绍一些有帮助的具体方法。
ML 特定的最佳实践
什么时候ML 比任何类型的软件都更重要,仅让程序端到端执行不足以证明其正确性。整个流水线可以毫无错误地运行并生成一个完全无用的模型。
假设您的程序加载数据并将其传递给模型。您的模型接受这些输入并根据学习算法优化模型的参数。最后,经过训练的模型会根据不同的数据集生成输出。您的程序已运行,没有任何可见的错误。问题在于,仅通过运行程序,您根本无法保证模型的预测是正确的。
大多数模型只是采用给定形状的数字输入(比如表示图像的矩阵)和不同形状的输出数据(例如,输入图像中关键点的坐标列表)。这意味着即使数据处理步骤在将数据传递给模型之前损坏了数据,只要数据仍然是数字并且具有模型可以作为输入的形状,大多数模型仍会运行。
如果您的建模管道性能不佳,您如何知道这是由于模型的质量还是流程早期存在的错误?
解决 ML 中这些问题的最佳方法是采用渐进式方法。首先验证数据流,然后是学习能力,最后是泛化和推理。图 6-2显示了我们将在本章中介绍的过程的概述。
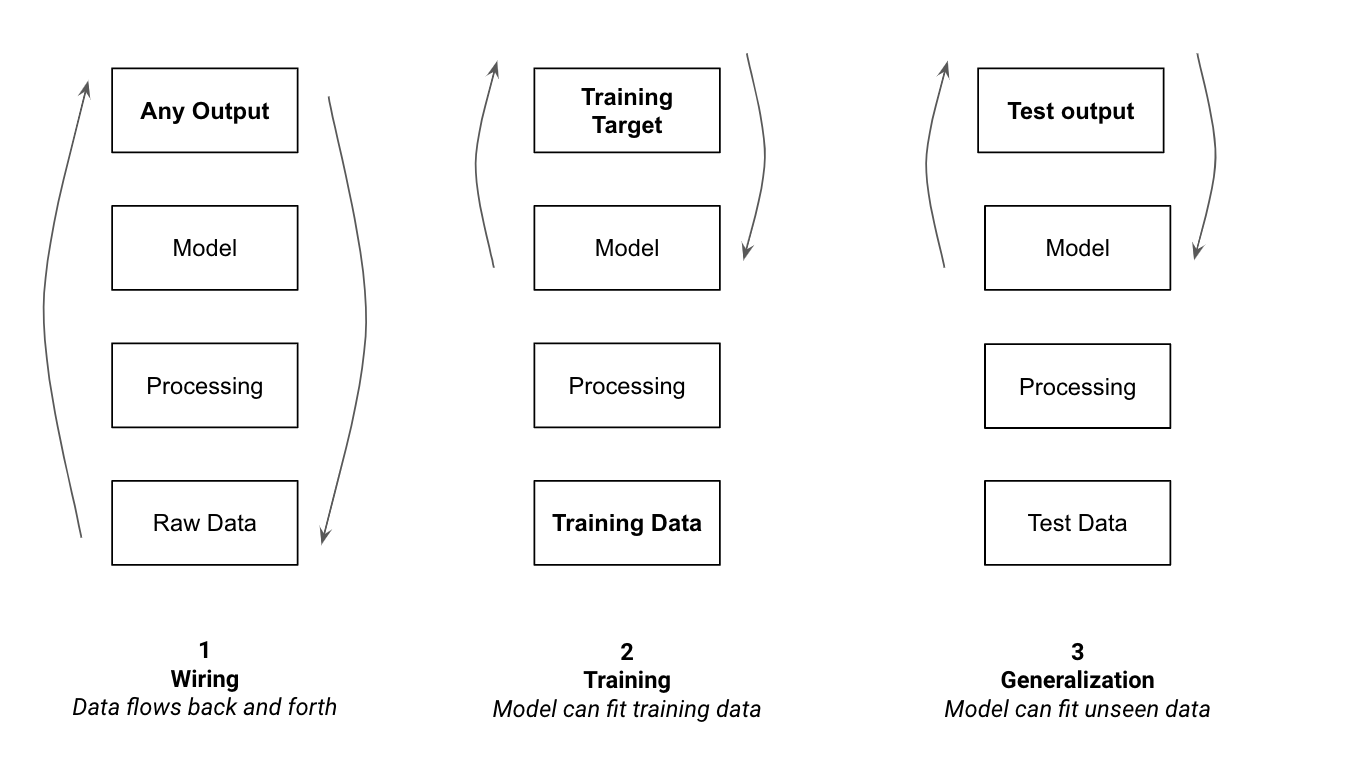
图 6-2。调试管道的顺序
本章将带您完成这三个步骤中的每一个步骤,并对每个步骤进行深入解释。当遇到令人费解的错误时,跳过此计划中的步骤可能很诱人,但绝大多数时候我发现遵循这种原则性方法是识别和纠正错误的最快方法。
让我们从验证数据流开始。最简单的方法是获取非常小的数据子集并验证它是否可以一直流过您的管道。
调试接线:可视化和测试
从一个例子开始
这此初始步骤的目标是验证您是否能够摄取数据、将其转换为正确的格式、将其传递给模型并让模型输出正确的内容。在这个阶段,你不是在判断你的模型是否能学到东西,只是判断管道是否能让数据通过。
具体是指:
-
在数据集中选择几个示例
-
让您的模型输出对这些示例的预测
-
让您的模型更新其参数以输出这些示例的正确预测
前两项侧重于验证我们的模型是否可以摄取输入数据并产生外观合理的输出。从建模的角度来看,这个初始输出很可能是错误的,但可以让我们检查数据是否一直在流动。
最后一项旨在确保我们的模型能够学习从给定输入到相关输出的映射。拟合几个数据点不会产生有用的模型,并且可能会导致过度拟合。这个过程只是让我们验证模型可以更新其参数以适应一组输入和输出。
这是第一步在实践中的样子:如果您正在训练一个模型来预测 Kickstarter 活动是否会成功,您可能计划在过去几年的所有活动中训练它。按照此提示,您应该首先检查您的模型是否可以输出两个活动的预测。然后,使用这些活动的标签(无论它们是否成功)来优化模型的参数,直到它预测出正确的结果。
如果我们适当地选择了我们的模型,它应该有能力从我们的数据集中学习。如果我们的模型可以从我们的整个数据集中学习,它应该有能力记住一个数据点。从几个例子中学习的能力是模型从整个数据集中学习的必要条件。它也比整个学习过程更容易验证,因此从一个开始可以让我们快速缩小任何潜在的未来问题。
这在此初始阶段可能出现的绝大多数错误都与数据不匹配有关:您正在加载和预处理的数据以模型无法接受的格式提供给模型。由于大多数模型只接受数值,例如,当给定值留空且具有空值时,它们可能会失败。
一些不匹配的情况可能更难以捉摸并导致静默失败。不在正确范围或形状中的管道馈送值可能仍会运行,但会产生性能不佳的模型。需要规范化数据的模型通常仍会在非规范化数据上进行训练:它们根本无法以有用的方式进行拟合。同样,将错误形状的矩阵输入模型会导致模型误解输入并产生错误的输出。
捕获此类错误更难,因为一旦我们评估模型的性能,它们就会在过程的后期出现。主动检测它们的最佳方法是在构建管道和构建测试以编码假设时可视化数据。接下来我们将看到如何做到这一点。
可视化步骤
作为我们在前面的章节中已经看到,虽然指标是建模工作的重要组成部分,但定期检查和调查我们的数据同样重要。开始时只观察几个例子可以更容易地注意到变化或不一致。
此过程的目标是定期检查更改。如果您将数据管道视为装配线,您会希望在每次有意义的更改后检查产品。这意味着在每一行检查数据点的值可能过于频繁,并且仅查看输入和输出值肯定不足以提供足够的信息。
在图 6-3中,我展示了几个示例检查点,您可以使用它们来查看数据管道。在此示例中,我们分多个步骤检查数据,从原始数据开始一直到建模输出。

图 6-3。潜在检查点
接下来,我们将介绍一些通常值得检查的关键步骤。我们将从数据加载开始,然后继续进行清理、特征生成、格式化和模型输出。
数据加载
无论您正在从磁盘或通过 API 调用加载数据,您需要验证其格式是否正确。此过程与您在执行 EDA 时经历的过程类似,但在您构建的管道上下文中完成,以验证没有错误导致数据损坏。
它是否包含您期望的所有字段?这些字段中是否有任何字段为空或具有常量值?是否有任何值位于看似不正确的范围内,例如年龄变量有时为负数?如果您正在处理文本、语音或图像,这些示例是否符合您对它们的外观、声音或读起来的期望?
我们的大部分处理步骤都依赖于我们对输入数据结构所做的假设,因此验证这方面至关重要。
因为这里的目标是识别我们对数据的期望与现实之间的不一致,所以您可能想要可视化不止一个或两个数据点。可视化一个有代表性的样本将确保我们不仅观察到一个“幸运”的例子,而且错误地假设所有数据点都具有相同的质量。
图 6-4显示了本书 GitHub 存储库中数据集探索笔记本中的案例研究示例。在这里,我们存档中的数百篇帖子属于未记录的帖子类型,因此需要过滤掉。在图中,您可以看到 PostTypeId 为 5 的行,数据集文档中未引用该行,因此我们将其从训练数据中删除。
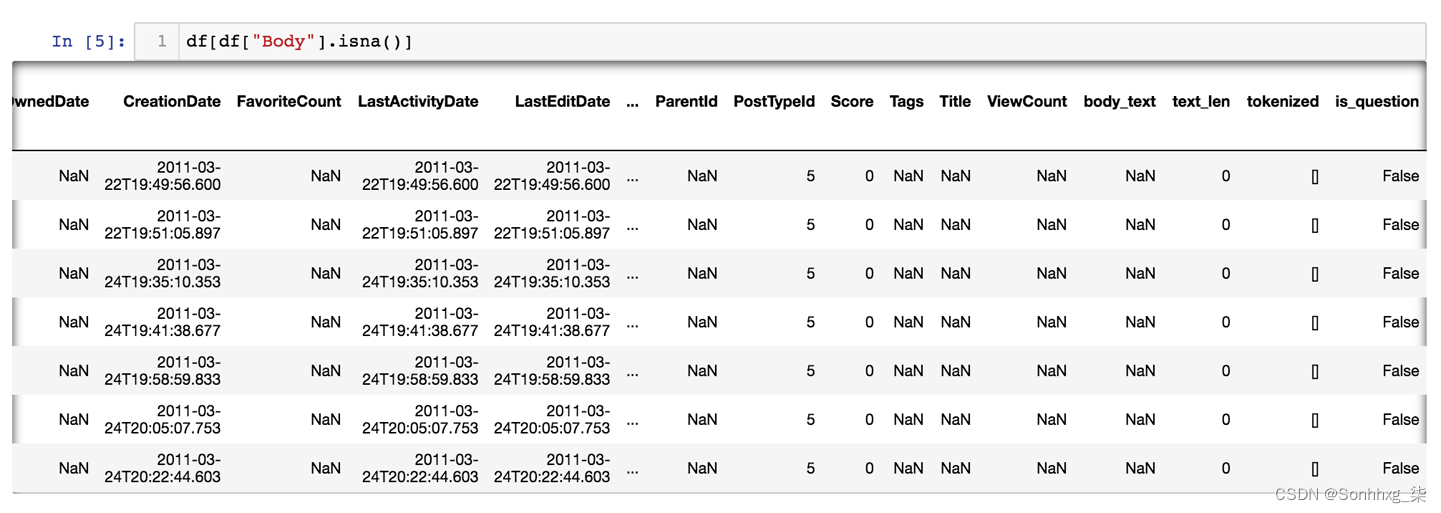
图 6-4。可视化几行数据
一旦您确认数据符合数据集文档中规定的预期,就可以开始处理它以用于建模目的了。这从数据清理开始。
清洁和功能选择
这大多数管道的下一步是删除任何不必要的信息。这可以包括模型不会使用的字段或值,也可以包括任何可能包含我们的模型在生产中无法访问的标签信息的字段(请参阅“拆分数据集”)。
请记住,您删除的每个特征都是模型的潜在预测因子。决定保留哪些特征和删除哪些特征的任务称为特征选择,是迭代模型的一个组成部分。
您应该验证没有丢失任何关键信息,所有不需要的值都被删除,并且您没有在我们的数据集中留下任何额外信息,这些信息会通过泄漏信息人为地提高我们模型的性能(参见“数据泄漏”)。
清理数据后,您需要生成一些特征供您的模型使用。
特征生成
此时,您不需要对其进行更深入的分析,因为这一步的重点是验证关于数据流经模型的假设,而不是数据或模型的有用性。
生成特征后,您应该确保它们可以以模型可以理解的格式传递给模型。
数据格式化
作为我们在前面的章节中已经讨论过,在将数据点传递给模型之前,您需要将它们转换为模型可以理解的格式。这可以包括规范化输入值、通过以数字方式表示文本来矢量化文本,或将黑白视频格式化为 3D 张量(请参阅“矢量化”)。
如果您正在处理监督问题,除了输入之外,您还将使用标签,例如分类中的类名,或图像分割中的分割图。这些还需要转换为模型可理解的格式。
在我在处理多个图像分割问题方面的经验,例如,标签和模型预测之间的数据不匹配是最常见的错误原因之一。分割模型使用分割掩码作为标签。这些掩码与输入图像大小相同,但它们包含每个像素的类标签,而不是像素值。不幸的是,不同的库使用不同的约定来表示这些掩码,因此标签通常以错误的格式结束,从而阻碍了模型的学习。
我在图 6-5中说明了这个常见的陷阱。假设一个模型期望为某个类别的像素传递值为 255 的分割掩码,否则为 0。如果用户假设掩码中包含的像素值应为 1 而不是 255,则他们可能会以“提供”中看到的格式传递其标记的掩码。这将导致面具被认为几乎完全是空的,并且模型将输出不准确的预测。

图 6-5。格式不正确的标签将阻止模型学习
同样,分类标签通常表示为零列表,在真实类别的索引处有一个零。一个简单的差一错误可能导致标签被移动,并且模型学习始终预测偏移一的标签。如果您不花时间查看您的数据,则此类错误很难排除。
因为 ML 模型将设法适应大多数数字输出,无论它们是否具有准确的结构或内容,所以这个阶段是许多棘手错误发生的地方,而这种方法对于找到它们很有用。
这是我们案例研究中此类格式化函数的示例。我生成了我们问题文本的矢量化表示。然后,我将附加功能附加到此表示中。由于该函数由多个转换和向量运算组成,可视化该函数的返回值将使我能够验证它是否按照我们预期的方式格式化数据。
def get_feature_vector_and_label(df, feature_names):
"""
Generate input and output vectors using the vectors feature and
the given feature names
:param df: input DataFrame
:param feature_names: names of feature columns (other than vectors)
:return: feature array and label array
"""
vec_features = vstack(df["vectors"])
num_features = df[feature_names].astype(float)
features = hstack([vec_features, num_features])
labels = df["Score"] > df["Score"].median()
return features, labels
features = [
"action_verb_full",
"question_mark_full",
"text_len",
"language_question",
]
X_train, y_train = get_feature_vector_and_label(train_df, features)什么时候特别是处理文本数据时,在为模型正确格式化数据之前通常涉及多个步骤。从文本字符串到标记化列表再到包含潜在附加功能的矢量化表示是一个容易出错的过程。即使在每一步检查物体的形状也有助于发现许多简单的错误。
一旦数据采用适当的格式,您就可以将其传递给模型。最后一步是可视化和验证模型的输出。
模型输出
在首先,查看输出有助于我们了解模型的预测类型或形状是否正确(如果我们预测房价和市场持续时间,我们的模型是否输出两个数字的数组?)。
此外,当仅将模型拟合到几个数据点时,我们应该看到它的输出开始与真实标签相匹配。如果模型不适合数据点,这可能表明数据格式不正确或已损坏。
如果模型的输出在训练期间根本没有改变,这可能意味着我们的模型实际上没有利用输入数据。在这种情况下,我建议参考“站在巨人的肩膀上”来验证模型是否被正确使用。
一旦我们完成了几个示例的整个管道,就该编写一些测试来自动化一些可视化工作了。
测试您的机器学习代码
测试模型的行为很难。然而,ML 管道中的大部分代码与训练管道或模型本身无关。如果您回顾一下“从一个简单的管道开始”中的管道示例,就会发现大多数函数的行为都是确定性的,并且可以进行测试。
根据我帮助工程师和数据科学家调试模型的经验,我了解到绝大多数错误来自数据的获取、处理或输入模型的方式。因此,测试数据处理逻辑对于构建成功的 ML 产品至关重要。
有关 ML 系统潜在测试的更多信息,我推荐 E. Breck 等人的论文“ML 测试分数:ML 生产准备和技术债务减少的 Rubric”,其中包含更多示例和经验教训在谷歌部署这样的系统。
在下一节中,我们将描述为三个关键领域编写的有用测试。在图 6-6中,您可以看到每个区域,以及我们接下来将描述的几个测试示例。
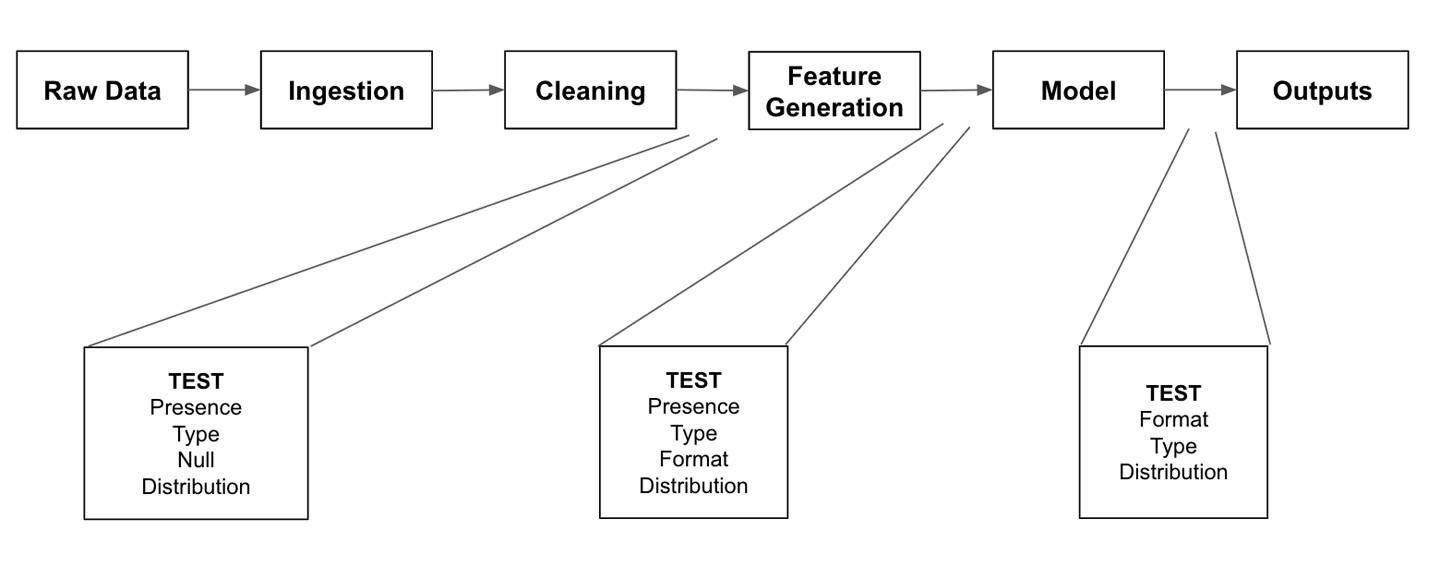
图 6-6。测试的三个关键领域
管道从摄取数据开始,因此我们首先要测试该部分。
测试数据摄取
数据通常在磁盘或数据库中序列化。将数据从存储移动到我们的管道时,我们应该确保验证数据的完整性和正确性。我们可以从编写测试开始,以验证我们加载的数据点是否具有我们需要的所有功能。
以下是三个测试,用于验证我们的解析器是否返回正确的类型(数据框),是否定义了所有重要的列,以及是否所有功能都为空。您可以在本书的 GitHub 存储库的测试文件夹中找到我们将在本章(以及其他内容)中介绍的测试。
def test_parser_returns_dataframe():
"""
Tests that our parser runs and returns a DataFrame
"""
df = get_fixture_df()
assert isinstance(df, pd.DataFrame)
def test_feature_columns_exist():
"""
Validate that all required columns are present
"""
df = get_fixture_df()
for col in REQUIRED_COLUMNS:
assert col in df.columns
def test_features_not_all_null():
"""
Validate that no features are missing every value
"""
df = get_fixture_df()
for col in REQUIRED_COLUMNS:
assert not df[col].isnull().all()我们还可以测试每个特征的类型并验证它不为空。最后,我们可以通过测试它们的平均值、最小值和最大值来编码我们对这些值的分布和范围的假设。最近,出现了诸如Great Expectations之类的库,可以直接测试特征的分布。
在这里,您可以看到如何编写一个简单的均值检验:
ACCEPTABLE_TEXT_LENGTH_MEANS = pd.Interval(left=20, right=2000)
def test_text_mean():
"""
Validate that text mean matches with exploration expectations
"""
df = get_fixture_df()
df["text_len"] = df["body_text"].str.len()
text_col_mean = df["text_len"].mean()
assert text_col_mean in ACCEPTABLE_TEXT_LENGTH_MEANS这些测试使我们能够验证,无论在存储端或数据源的 API 上进行了哪些更改,我们都可以知道我们的模型可以访问它最初训练的同类数据。一旦我们对我们摄取的数据的一致性有信心,让我们看看管道中的下一步,即数据处理。
测试数据处理
后测试进入管道起点的数据是否符合我们的预期,我们应该测试我们的清理和特征生成步骤是否符合我们的预期。我们可以从为我们拥有的预处理功能编写测试开始,验证它确实按照我们的预期进行。此外,我们可以为数据摄取测试编写类似的测试,并专注于保证我们对进入模型的数据状态的假设是有效的。
这意味着在我们的处理管道之后测试数据点的存在、类型和特征。以下是对生成的特征是否存在、它们的类型以及最小值、最大值和平均值进行测试的示例:
def test_feature_presence(df_with_features):
for feat in REQUIRED_FEATURES:
assert feat in df_with_features.columns
def test_feature_type(df_with_features):
assert df_with_features["is_question"].dtype == bool
assert df_with_features["action_verb_full"].dtype == bool
assert df_with_features["language_question"].dtype == bool
assert df_with_features["question_mark_full"].dtype == bool
assert df_with_features["norm_text_len"].dtype == float
assert df_with_features["vectors"].dtype == list
def test_normalized_text_length(df_with_features):
normalized_mean = df_with_features["norm_text_len"].mean()
normalized_max = df_with_features["norm_text_len"].max()
normalized_min = df_with_features["norm_text_len"].min()
assert normalized_mean in pd.Interval(left=-1, right=1)
assert normalized_max in pd.Interval(left=-1, right=1)
assert normalized_min in pd.Interval(left=-1, right=1)这些测试使我们能够注意到管道的任何变化,这些变化会影响我们模型的输入,而无需编写任何额外的测试。当我们添加新功能或更改模型的输入时,我们只需要编写新测试。
我们现在可以对我们摄取的数据和我们对其应用的转换充满信心,所以是时候测试管道的下一部分,即模型了。
测试模型输出
相似地对于前两个类别,我们将编写测试来验证模型输出的值是否具有正确的维度和范围。我们还将测试特定输入的预测。这有助于主动检测新模型中预测质量的回归,并确保我们使用的任何模型始终根据这些示例输入产生预期的输出。当一个新模型显示出更好的综合性能时,很难注意到它的性能是否在特定类型的输入上变差了。编写此类测试有助于更轻松地检测此类问题。
在以下示例中,我首先测试模型预测的形状及其值。第三个测试旨在通过保证模型将特定措辞不佳的输入问题分类为低质量来防止回归。
def test_model_prediction_dimensions(
df_with_features, trained_v1_vectorizer, trained_v1_model
):
df_with_features["vectors"] = get_vectorized_series(
df_with_features["full_text"].copy(), trained_v1_vectorizer
)
features, labels = get_feature_vector_and_label(
df_with_features, FEATURE_NAMES
)
probas = trained_v1_model.predict_proba(features)
# the model makes one prediction per input example
assert probas.shape[0] == features.shape[0]
# the model predicts probabilities for two classes
assert probas.shape[1] == 2
def test_model_proba_values(
df_with_features, trained_v1_vectorizer, trained_v1_model
):
df_with_features["vectors"] = get_vectorized_series(
df_with_features["full_text"].copy(), trained_v1_vectorizer
)
features, labels = get_feature_vector_and_label(
df_with_features, FEATURE_NAMES
)
probas = trained_v1_model.predict_proba(features)
# the model's probabilities are between 0 and 1
assert (probas >= 0).all() and (probas <= 1).all()
def test_model_predicts_no_on_bad_question():
input_text = "This isn't even a question. We should score it poorly"
is_question_good = get_model_predictions_for_input_texts([input_text])
# The model classifies the question as poor
assert not is_question_good[0]我们首先目视检查数据以验证它在我们的整个管道中仍然有用和可用。然后,我们编写测试以保证这些假设随着我们的处理策略的发展而保持正确。现在是处理图 6-2的第二部分的时候了,调试训练程序。
调试训练:让你的模型学习
一次您已经测试了您的管道并验证了它适用于一个示例,您知道一些事情。您的管道接收数据并成功转换它。然后它将此数据以正确的格式传递给模型。最后,模型可以获取一些数据点并从中学习,输出正确的结果。
现在是时候看看您的模型是否可以处理多个数据点并从您的训练集中学习。下一节的重点是能够在许多示例上训练您的模型并使其适合您的所有训练数据。
为此,您现在可以将整个训练集传递给模型并衡量其性能。或者,如果您有大量数据,则可以逐渐增加提供给模型的数据量,同时关注总体性能。
逐步增加训练数据集大小的优势之一是,您将能够衡量额外数据对模型性能的影响。从几百个示例开始,然后增加到几千个,然后再传入整个数据集(如果您的数据集少于一千个示例,请直接跳到完整地使用它)。
在每个步骤中,将您的模型拟合到数据上并评估其在相同数据上的性能。如果你的模型有能力从你正在使用的数据中学习,它在训练数据上的表现应该保持相对稳定。
例如,为了将模型性能置于上下文中,我建议通过自己标记一些示例并将您的预测与真实标签进行比较,来生成您的任务可接受的错误级别的估计值。大多数任务还带有不可减少的错误,代表了给定任务复杂性的最佳性能。请参见图6-7,了解与此类指标相比的常规训练性能。
模型在整个数据集上的表现应该比仅使用一个示例时更差,因为记住整个训练集比单个示例更难,但仍应保持在先前定义的范围内。
如果您能够提供整个训练集并且模型的性能达到您在查看产品目标时定义的要求,请随时继续下一节!如果不是,我在下一节中概述了模型在训练集上表现不佳的几个常见原因。
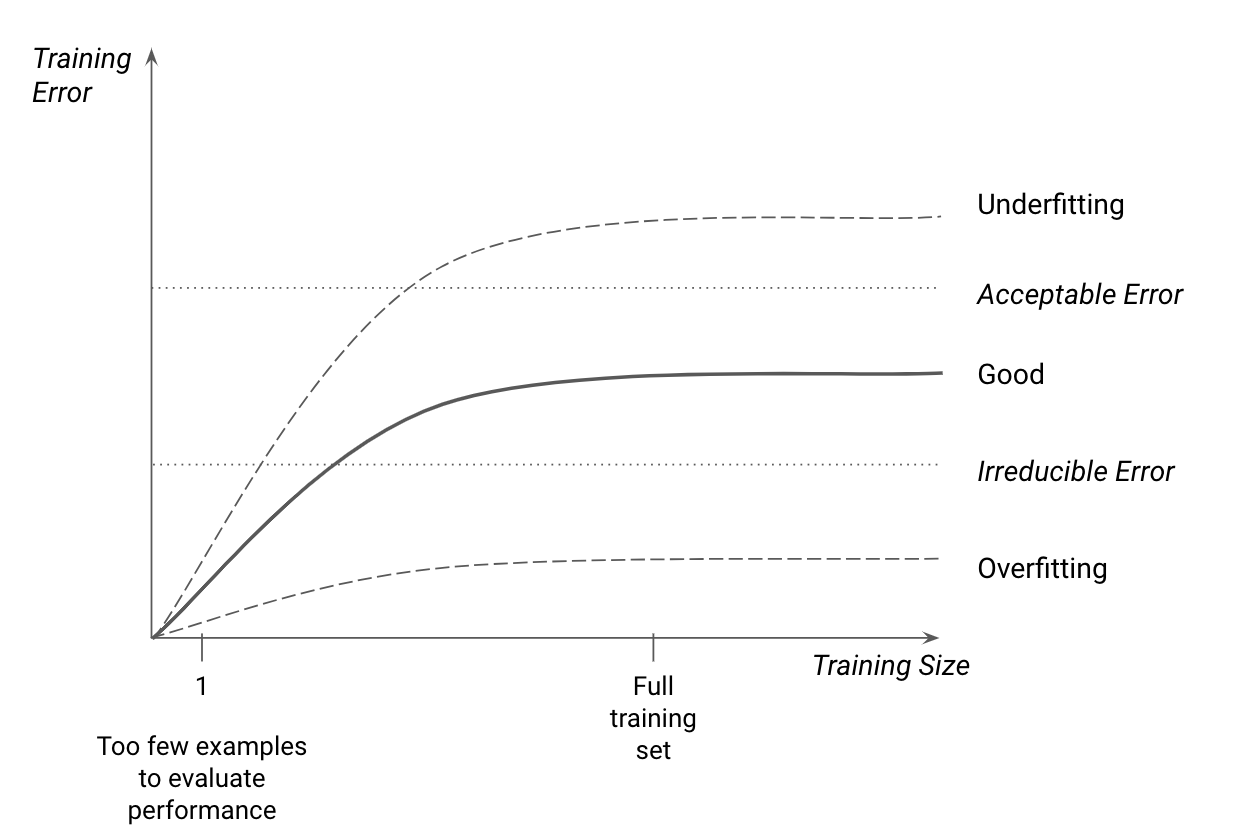
图 6-7。训练精度作为数据集大小的函数
任务难度
如果模型的性能大大低于预期,任务可能太难了。要评估一项任务的难度,请考虑:
-
您拥有的数据的数量和多样性
-
您生成的特征的预测性如何
-
模型的复杂性
让我们更详细地看看其中的每一个。
数据质量、数量和多样性
此外,您拥有的数据越少,标签中的任何错误或任何缺失值的影响就越大。这就是为什么花时间检查和验证数据集的特征和标签是值得的。
最后,大多数数据集包含异常值,即与其他数据点完全不同的数据点,模型很难处理。从训练集中移除异常值通常可以通过简化手头的任务来提高模型的性能,但这并不总是正确的方法:如果您认为您的模型可能会在生产中遇到相似的数据点,则应该保留异常值并集中注意力改进你的数据和模型,使模型能够成功地适应它们。
数据集越复杂,就越有助于研究表示数据的方法,这将使模型更容易从中学习。让我们看看这意味着什么。
数据表示
如何仅使用您为模型提供的表示来检测您关心的模式是否容易?如果一个模型在训练数据上表现不佳,您应该添加使数据更具表现力的特征,从而帮助模型更好地学习。
这可能包括我们之前决定忽略但可能具有预测性的新特征。在我们的 ML Editor 示例中,模型的第一次迭代仅考虑了问题正文中的文本。在进一步探索数据集之后,我注意到问题标题通常可以提供很多关于问题好坏的信息。将该特征重新合并到数据集中可以让模型表现得更好。
通常可以通过迭代现有功能或以创造性的方式组合它们来生成新功能。我们在“让数据为特征和模型提供信息”中看到了一个这样的例子,当时我们研究了将星期几和月份中的某一天结合起来以生成与特定业务案例相关的特征的方法。
在某些情况下,问题出在您的模型上。接下来我们看看这些案例。
型号容量
增加数据质量和改进功能通常会带来最大的好处。当模型是性能不佳的原因时,通常意味着它不足以完成手头的任务。正如我们在“从模式到模型”中看到的,特定的数据集和问题需要特定的模型。一个不适合某项任务的模型将难以对其执行,即使它能够过拟合一些示例。
如果模型在似乎具有许多预测特征的数据集上表现不佳,请先问问自己是否使用了正确类型的模型。如果可能,请使用给定模型的更简单版本以更轻松地检查它。例如,如果随机森林模型根本没有执行,请在同一任务上尝试决策树并可视化其拆分以检查它们是否使用了您认为可以预测的功能。
另一方面,您使用的模型可能过于简单。从最简单的模型开始,可以快速迭代,但有些任务是某些模型完全无法完成的。要解决这些问题,您可能需要增加模型的复杂性。为了验证模型是否确实适用于任务,我建议查看我们在“站在巨人的肩膀上”中描述的现有技术。查找类似任务的示例,并检查使用了哪些模型来解决这些问题。使用其中一个模型应该是一个很好的起点。
如果该模型看起来适合该任务,则其表现不佳可能是由于训练过程造成的。
优化问题
什么时候处理使用神经网络等梯度下降技术拟合的模型,使用TensorBoard等可视化工具可以帮助解决训练问题。在优化过程中绘制损失时,您应该看到它开始急剧下降,然后逐渐下降。在图 6-8中,您可以看到一个 TensorBoard 仪表板示例,它描述了一个随着训练的进行损失函数(在本例中为交叉熵)。
这样的曲线可以表明损失正在非常缓慢地减少,表明模型可能学习得太慢了。在这种情况下,您可以提高学习率并绘制相同的曲线以查看损失是否减少得更快。另一方面,如果损失曲线看起来非常不稳定,则可能是由于学习率太大。

图 6-8。TensorBoard 文档中的 TensorBoard 仪表板屏幕截图
除了损失,可视化权重值和激活可以帮助您确定网络是否未正确学习。在图 6-9中,您可以看到随着训练的进行,权重分布发生了变化。如果您看到分布在几个时期内保持稳定,则可能表明您应该提高学习率。如果它们变化太大,则降低它。
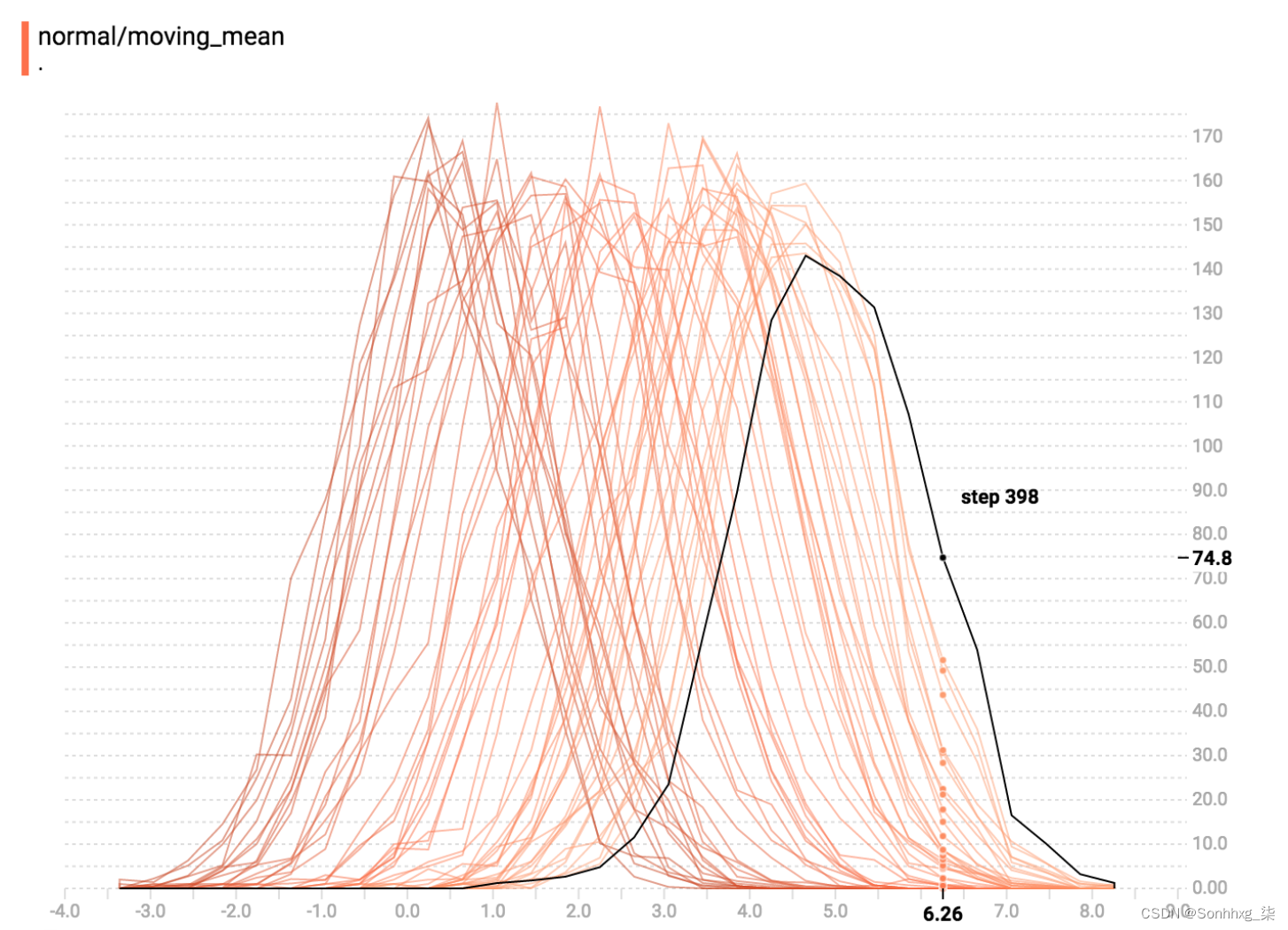
图 6-9。权重直方图随着训练的进行而变化
成功地将模型拟合到训练数据是 ML 项目中的一个重要里程碑,但这不是最后一步。构建 ML 产品的最终目标是构建一个模型,该模型可以在从未见过的示例上表现良好。为此,我们需要一个可以很好地泛化到未见示例的模型,因此接下来我将介绍泛化。
调试泛化:使您的模型有用
数据泄露
如果验证性能优于训练性能,有时可能是由于数据泄漏。如果训练数据中的示例包含有关验证数据中其他示例的信息,则模型将能够利用此信息并在验证集上表现良好。如果您对验证性能感到惊讶,请检查模型使用的功能并查看它们是否显示数据泄漏。解决此类泄漏问题将导致验证性能降低,但模型会更好。
数据泄漏可能会让我们相信模型正在泛化,但实际上并非如此。在其他情况下,通过查看保留验证集的性能可以清楚地看出模型仅在训练时表现良好。在这些情况下,模型可能会过度拟合。
过拟合
在“偏差方差权衡”中,我们看到当模型难以拟合训练数据时,我们说模型欠拟合。我们还看到过拟合是欠拟合的对立面,这就是我们的模型太适合我们的训练数据。
拟合数据太好是什么意思?这意味着,例如,模型不是学习与写作好坏相关的可概括趋势,而是可以选择训练集中个别示例中存在的特定模式,而这些模式不存在于不同的数据中。这些模式有助于它在训练集上获得高分,但对其他示例的分类没有用。
图 6-10显示了玩具数据集过度拟合和欠拟合的实际示例。过拟合模型可以完美地拟合训练数据,但不能准确地逼近潜在趋势;因此,它无法准确预测看不见的点。欠拟合模型根本没有捕捉到数据的趋势。标记为合理拟合的模型在训练数据上的表现比过拟合模型差,但在未见过的数据上表现更好。
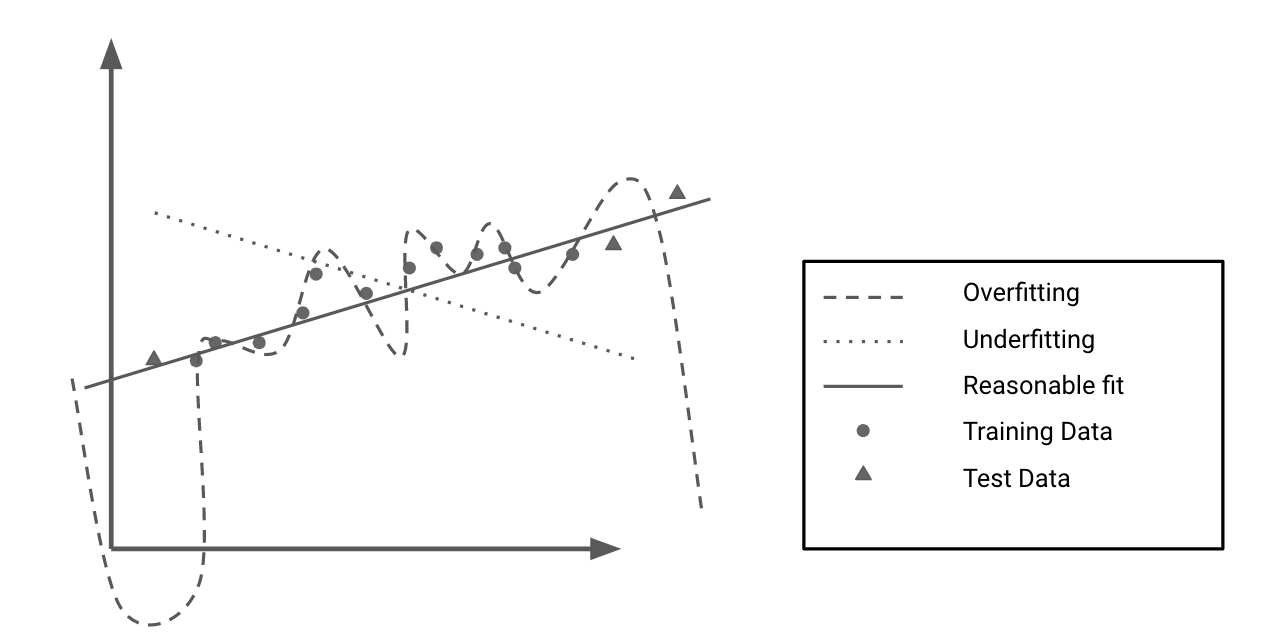
图 6-10。过度拟合与欠拟合
当一个模型在训练集上的表现明显好于在测试集上时,这通常意味着它过度拟合。它了解了训练数据的具体细节,但无法对看不见的数据执行操作。
由于过度拟合是由于模型对训练数据学习太多,我们可以通过降低模型从数据集中学习的能力来防止它。有几种方法可以做到这一点,我们将在此处介绍。
正则化
正则化增加对模型表示信息的能力的惩罚。正则化旨在限制模型关注许多不相关模式的能力,并鼓励它选择更少、更具预测性的特征。
对模型进行正则化的一种常见方法是对其权重的绝对值施加惩罚。例如,对于线性和逻辑回归等模型,L1 和 L2 正则化会在损失函数中添加一个附加项来惩罚大权重。在 L1 的情况下,此项是权重绝对值的总和。对于 L2,它是权重的平方值之和。
不同的正则化方法有不同的效果。L1 正则化可以通过将无信息的功能设置为零来帮助选择信息功能(在“套索(统计)”维基百科页面上信息)。当通过鼓励模型仅利用其中一个特征来关联某些特征时,L1 正则化也很有用。
正则化方法也可以是特定于模型的。神经网络通常使用 dropout 作为正则化方法。Dropout 在训练期间随机忽略网络中一定比例的神经元。这可以防止单个神经元变得过于有影响力,从而使网络能够记住训练数据的各个方面。
对于基于树的模型,例如对于随机森林,减少树的最大深度会降低每棵树对数据过度拟合的能力,从而有助于规范森林。增加森林中使用的树木数量也会使其正规化。
防止模型过度拟合训练数据的另一种方法是使数据本身更难过度拟合。我们可以通过称为数据扩充的过程来做到这一点。
数据扩充
数据扩充是通过稍微改变现有数据点来创建新训练数据的过程。目标是人为地生成不同于现有数据点的数据点,以便将模型暴露给更多样化的输入类型。增强策略取决于数据类型。在图 6-11中,您可以看到一些潜在的图像增强。
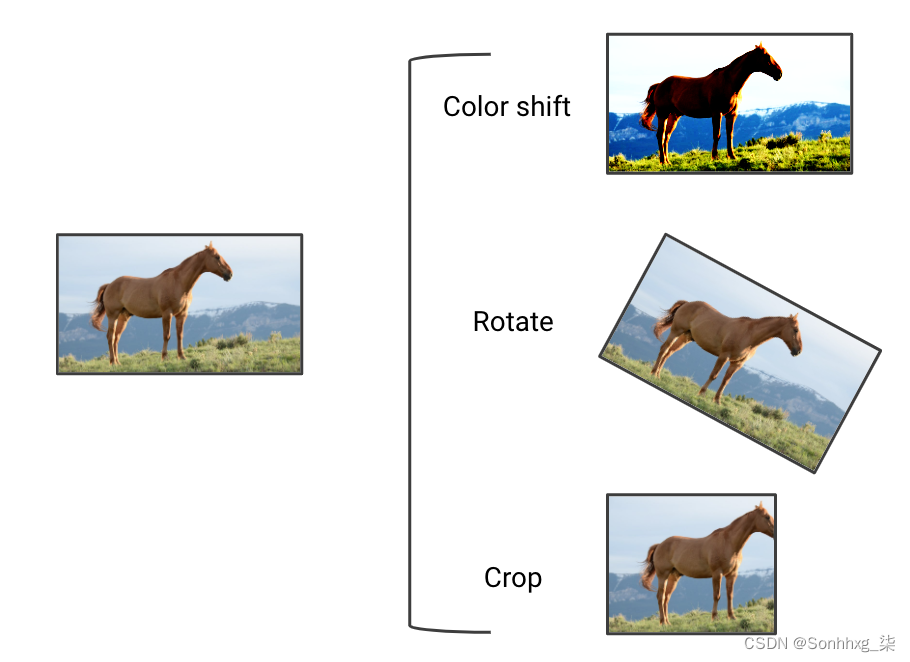
图 6-11。图像数据增强的几个例子
数据增强使训练集不那么均匀,因此更复杂。这使得训练数据的拟合更加困难,但在训练期间将模型暴露给更广泛的输入。数据增强通常会降低训练集的性能,但会提高未见数据(例如验证集和生产中的示例)的性能。如果我们可以使用扩充使我们的训练集更类似于自然环境中的示例,则此策略特别有效。
我曾经帮助一位工程师使用卫星图像来检测飓风过后被洪水淹没的道路。该项目具有挑战性,因为他只能访问非洪水城市的标记数据。为了帮助提高他的模型在飓风图像上的表现,飓风图像明显更暗且质量更低,他们建立了增强管道,使训练图像看起来更暗和更模糊。这降低了训练性能,因为现在道路更难被发现。另一方面,它提高了模型在验证集上的性能,因为增强过程将模型暴露在与它在验证集中遇到的图像更相似的图像中。数据增强有助于使训练集更具代表性,从而使模型更加健壮。
如果在使用前面描述的方法后模型在验证集上仍然表现不佳,您应该迭代数据集本身。
数据集重新设计
在在某些情况下,困难的训练/验证拆分会导致模型欠拟合并在验证集上挣扎。如果一个模型在其训练集中仅暴露于简单的示例而在其验证集中仅暴露于具有挑战性的示例,则它将无法从困难的数据点中学习。类似地,某些类别的示例在训练集中的代表性可能不足,从而阻止模型从中学习。如果训练模型以最小化聚合指标,则它可能适合大多数类,而忽略少数类。
虽然增强策略可以提供帮助,但重新设计训练分组以使其更具代表性通常是最好的前进道路。这样做时,我们应该小心控制数据泄漏,并使拆分在难度方面尽可能平衡。如果新的数据拆分将所有简单的示例分配给验证集,则模型在验证集上的性能会人为地高,但不会转化为生产结果。为了减轻对数据拆分可能质量不均的担忧,我们可以使用k 折交叉验证,我们执行 k 个连续的不同拆分,并测量模型在每个拆分上的性能。
一旦我们平衡了我们的训练和验证集以确保它们具有相似的复杂性,我们的模型的性能应该会提高。如果性能仍然不令人满意,我们可能只是在解决一个非常困难的问题。
考虑手头的任务
一个模型很难概括,因为任务太复杂了。例如,我们使用的输入可能无法预测目标。为了确保您正在处理的任务对于 ML 的当前状态具有适当的难度,我建议再次参考“站在巨人的肩膀上”,我在其中描述了如何探索和评估当前的技术状态。
此外,拥有数据集并不意味着任务是可解决的。考虑从随机输入准确预测随机输出的不可能完成的任务。你可以通过记住它来构建一个在训练集上表现良好的模型,但这个模型将无法从随机输入中准确预测其他随机输出。
如果您的模型不能泛化,那么您的任务可能太难了。您的训练示例中可能没有足够的信息来学习有意义的特征,这些特征将为未来的数据点提供信息。如果是这样,那么你遇到的问题不太适合 ML,我会邀请你重新阅读第 1 章以找到更好的框架。
结论
在本章中,我们介绍了使模型正常工作应遵循的三个连续步骤。首先,通过检查数据和编写测试来调试管道的布线。然后,让模型在训练测试中表现良好,以验证它具有学习能力。最后,验证它是否能够对看不见的数据进行归纳和产生有用的输出。
此过程将帮助您调试模型、更快地构建它们并使它们更健壮。一旦您构建、训练和调试了您的第一个模型,下一步就是判断其性能并对其进行迭代或部署。
在第 7 章中,我们将介绍如何使用经过训练的分类器为用户提供可操作的建议。然后,我们将比较 ML Editor 的候选模型,并决定应该使用哪个模型来支持这些建议。




![[LeetCode/力扣][Java] 0315. 计算右侧小于当前元素的个数(Count of Smaller Numbers After Self)](https://img-blog.csdnimg.cn/1e020d625eac4cf6aa7dc4c23935f875.png#pic_center)