导数
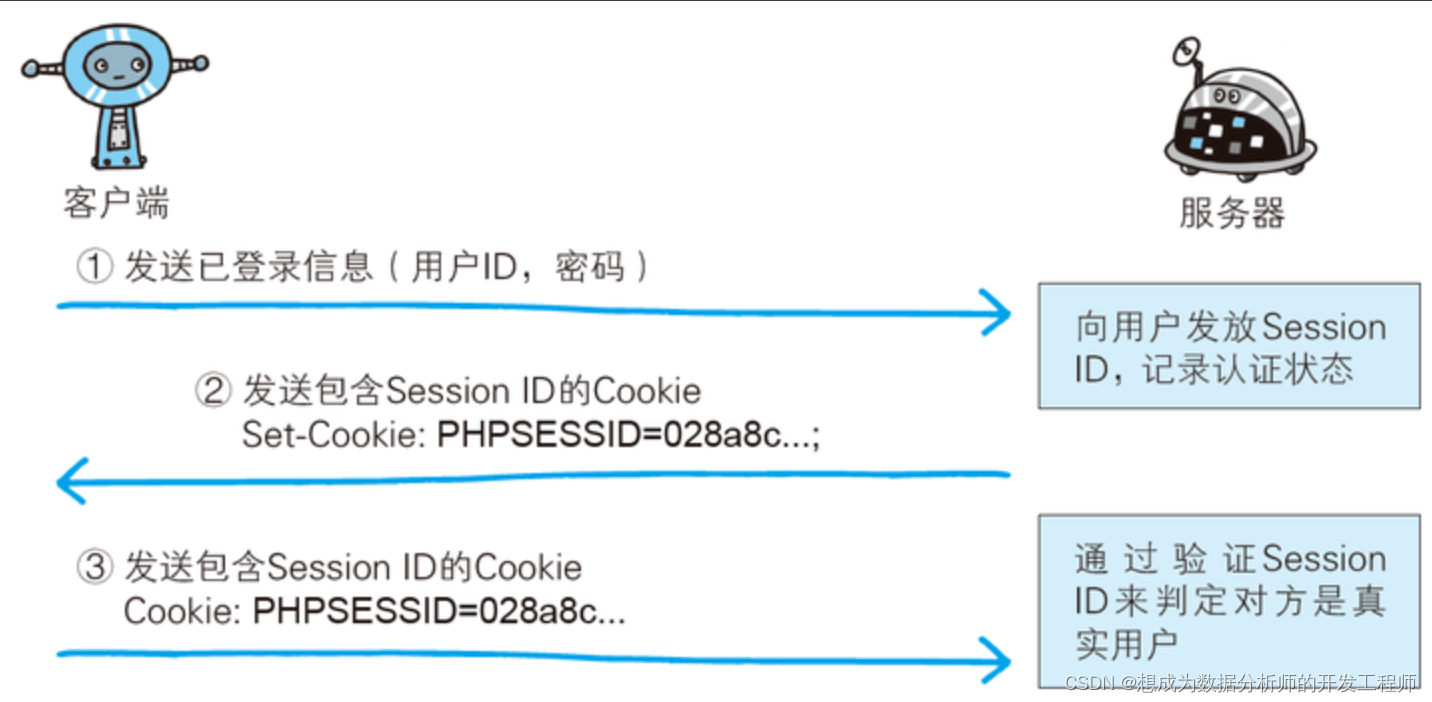
导数:表示某个瞬间的变化量,公式定义:
d
f
(
x
)
d
x
=
l
i
m
h
→
0
f
(
x
+
h
)
−
f
(
x
)
h
(4.4)
\frac{df(x)}{dx} = lim_{h \to 0}\frac{f(x + h)-f(x)}{h} \tag{4.4}
dxdf(x)=limh→0hf(x+h)−f(x)(4.4)
求导的代码实现:
import numpy as np
import matplotlib.pyplot as plt
def function_1(x):
"""函数y = 0.01x^2+0.1x"""
return 0.01 * x ** 2 + 0.1 * x
def numerical_diff(func, x):
"""函数的导数(梯度)"""
h = 1e-4
return (func(x + h) - func(x - h)) / (2 * h)
def tangent_line(f, x):
"""切线"""
d = numerical_diff(f, x) # x点处切线斜率, 即变化率
c = f(x) - d * x
"""
切线格式:y = dx + c
切线与函数f(x)交于切点(传入的x就是切点横坐标x,f(x)就是切点纵坐标y)
c = y - dx, 即上面那行代码c = f(x) - d * x
同时也是下面返回值lambda函数的格式t(x) = dx+c
"""
return lambda t: d * t + c
print(numerical_diff(function_1, 5))
# 0.1999999999990898, 函数f(x)在x=5处的导数,即此处的斜率
print(numerical_diff(function_1, 10))
# 0.2999999999986347, 函数f(x)在x=10出的导数, 即此处的斜率
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
df1 = tangent_line(function_1, 5)
y2 = df1(x) # y2 = dx + c, x = 5
df1 = tangent_line(function_1, 10)
y3 = df1(x) # y3 = dx + c, x = 10
plt.plot(x, y, label="f(x)")
plt.plot(x, y2, label="tangent_line at x=5")
plt.plot(x, y3, label="tangent_line at x=10")
plt.scatter(5, function_1(5))
plt.scatter(10, function_1(10))
plt.xlabel("x")
plt.ylabel("f(x)")
plt.title("f(x) = 0.01x^2+0.1x")
plt.legend()
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HKHy3k60-1669107026677)(./assets/image-20221121180844506.png)]
偏导数
针对二元或多元的函数而言,比如
f
(
x
0
,
x
1
)
=
x
0
2
+
x
1
2
f(x_0, x_1) = x_0^{2} + x_1^{2}
f(x0,x1)=x02+x12
该函数的代码实现:
import numpy as np
def function_2(x):
"""函数f(x0, x1) = x0 ^ 2 + x1 ^ 2"""
return np.sum(x ** 2)
x = np.array([1, 2])
f = function_2(x)
print(f) # 5
该函数的偏导数:
对
x
0
的
偏
导
数
:
∂
f
∂
x
0
=
2
x
0
对x_0的偏导数: \frac{\partial f}{\partial x_0}=2x_0
对x0的偏导数:∂x0∂f=2x0
求某个的偏导数就把另一个当作常数
梯度
∇ f = ( ∂ f ∂ x 0 , ∂ f ∂ x 1 ) \nabla f=(\frac{\partial f}{\partial x_0},\frac{\partial f}{\partial x_1}) ∇f=(∂x0∂f,∂x1∂f)
如上式,由全部变量的偏导数汇总成的向量称为梯度
梯度的代码实现:
import numpy as np
def function_g(x):
"""f(x0, x1) = x0 ^ 2 + x1 ^ 2"""
return x[0] ** 2 + x[1] ** 2
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 还原值
return grad
print(numerical_gradient(function_g, np.array([0.0, 2.0]))) # [0. 4.]
print(numerical_gradient(function_g, np.array([3.0, 4.0]))) # [6. 8.]
print(numerical_gradient(function_g, np.array([3.0, 0.0]))) # [6. 0.]
作者提供的代码,负梯度的方向:
import numpy as np
import matplotlib.pylab as plt
from mpl_toolkits.mplot3d import Axes3D
def _numerical_gradient_no_batch(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad
def numerical_gradient(f, X):
if X.ndim == 1:
return _numerical_gradient_no_batch(f, X)
else:
grad = np.zeros_like(X)
for idx, x in enumerate(X):
grad[idx] = _numerical_gradient_no_batch(f, x)
return grad
def function_2(x):
if x.ndim == 1:
return np.sum(x**2)
else:
return np.sum(x**2, axis=1)
def tangent_line(f, x):
d = numerical_gradient(f, x)
print(d)
y = f(x) - d*x
return lambda t: d*t + y
if __name__ == '__main__':
x0 = np.arange(-2, 2.5, 0.25)
x1 = np.arange(-2, 2.5, 0.25)
X, Y = np.meshgrid(x0, x1)
X = X.flatten()
Y = Y.flatten()
grad = numerical_gradient(function_2, np.array([X, Y]) )
plt.figure()
plt.quiver(X, Y, -grad[0], -grad[1], angles="xy",color="#666666")#,headwidth=10,scale=40,color="#444444")
plt.xlim([-2, 2])
plt.ylim([-2, 2])
plt.xlabel('x0')
plt.ylabel('x1')
plt.grid()
plt.legend()
plt.draw()
plt.show()
运行截图:

梯度相关内容推荐吴恩达老师机器学习课程的相关内容视频
梯度法寻找最优参数
如上面的图可以看到,梯度表示的是各点处的函数值减少最多的方向,而无法保证梯度所指方向就是函数的最小值。
函数的极小值、最小值以及被称为鞍点的地方梯度为。
极小值就是局部最小值,也就是限定在某个范围内的最小值。
鞍点是从某个方向上看是极大值,从另一个方向上看则是极小值的点。
梯度为0不一定就是最小值,也可能是极小值或者鞍点
当函数很复杂且成扁平状,学习可能会陷入无法前进的停滞期
梯度法:通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法。
梯度法的数学表示:
x
0
=
x
0
−
η
∂
f
∂
x
0
,
x
1
=
x
1
−
η
∂
f
∂
x
1
(4.7)
x_0 = x_0 - \eta \frac{\partial f}{\partial x_0},x_1 = x_1 -\eta \frac{\partial f}{\partial x_1} \tag{4.7}
x0=x0−η∂x0∂f,x1=x1−η∂x1∂f(4.7)
η
\eta
η:学习率,决定在一次学习中,应该学习多少,在多大程度上更新参数。
学习率需要事先确定为某个值,比如0.01或0.001。类似这样人工设定的参数叫超参数
在神经网络的学习中,一般会一边改变学习率的值,一边确认学习是否正确进行了。
梯度下降法代码实现:
import numpy as np
def function_g(x):
"""f(x0, x1) = x0 ^ 2 + x1 ^ 2"""
return x[0] ** 2 + x[1] ** 2
def numerical_gradient(f, x):
"""
梯度
使用的依然是导数的公式
由所有偏导数组成的向量
"""
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
# print(x.size)
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 还原值
return grad
def gradient_descent(f, init_x, lr=0.01, step_num=100):
"""
梯度下降法
返回使函数 f 值最小的参数 x
"""
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
# 输出三个位置对应的梯度
print(numerical_gradient(function_g, np.array([0.0, 2.0]))) # [0. 4.]
print(numerical_gradient(function_g, np.array([3.0, 4.0]))) # [6. 8.]
print(numerical_gradient(function_g, np.array([3.0, 0.0]))) # [6. 0.]
x_input = np.array([-3.0, 4.0])
print(gradient_descent(function_g, init_x=x_input, lr=0.1, step_num=100)) # [-6.11110793e-10 8.14814391e-10]
梯度下降法可视化:
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
from gradient_2d import numerical_gradient
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
x_history = []
for i in range(step_num):
x_history.append(x.copy())
grad = numerical_gradient(f, x)
x -= lr * grad
return x, np.array(x_history)
def function_2(x):
return x[0] ** 2 + x[1] ** 2
init_x = np.array([-3.0, 4.0])
lr = 0.1
step_num = 20
x, x_history = gradient_descent(function_2, init_x, lr=lr, step_num=step_num)
plt.plot([-5, 5], [0, 0], '--b')
plt.plot([0, 0], [-5, 5], '--b')
plt.plot(x_history[:, 0], x_history[:, 1], 'o')
plt.xlim(-3.5, 3.5)
plt.ylim(-4.5, 4.5)
plt.xlabel("X0")
plt.ylabel("X1")
plt.show()
运行结果:

原点处是函数 f ( x 0 , x 1 ) = x 0 2 + x 1 2 f(x_0,x_1)=x_0^2+x_1^2 f(x0,x1)=x02+x12的最小值,函数的取值一点点在向其靠近
神经网络的参数
上面求函数 f ( x 0 , x 1 ) = x 0 2 + x 1 2 f(x_0,x_1)=x_0^2+x_1^2 f(x0,x1)=x02+x12的最小值。
下面来对比求损失函数 L L L的最小值。
| 函数 | 损失函数 | |
|---|---|---|
| 参数 | x 0 , x 1 x_0,x_1 x0,x1 | 权重 W = ( w 11 , w 12 , w 13 w 21 , w 22 , w 23 ) W=\left(\begin{matrix}w_{11} ,w_{12},w_{13}\\w_{21},w_{22},w_{23}\end{matrix}\right) W=(w11,w12,w13w21,w22,w23) |
| 梯度 | ∇ f = ( ∂ f ∂ x 0 , ∂ f ∂ x 1 ) \nabla f=(\frac{\partial f}{\partial x_0},\frac{\partial f}{\partial x_1}) ∇f=(∂x0∂f,∂x1∂f) | ∂ L ∂ W = ( ∂ L ∂ w 11 , ∂ L ∂ w 12 , ∂ L ∂ w 13 ∂ L ∂ w 21 , ∂ L ∂ w 22 , ∂ L ∂ w 23 ) \frac{\partial L}{\partial W}=\left(\begin{matrix}\frac{\partial L}{\partial w_{11}},\frac{\partial L}{\partial w_{12}},\frac{\partial L}{\partial w_{13}}\\\frac{\partial L}{\partial w_{21}},\frac{\partial L}{\partial w_{22}},\frac{\partial L}{\partial w_{23}}\end{matrix}\right) ∂W∂L=(∂w11∂L,∂w12∂L,∂w13∂L∂w21∂L,∂w22∂L,∂w23∂L) |
损失函数计算:
使用的激活函数为softmax
def softmax(x):
"""softmax激活函数"""
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
损失函数为交叉熵误差
def cross_entropy_error(y, t):
"""交叉熵误差"""
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
import numpy as np
import activate_functions as af
import loss_functions as ls
import gradient as grad
class SimpleNet:
def __init__(self):
"""初始化权重参数"""
self.W = np.random.randn(2, 3) # 用随机数生成2行3列的矩阵
def predict(self, x):
"""预测, x为输入"""
return np.dot(x, self.W) # x为输入的矩阵,与权重W矩阵相乘
def loss(self, x, t):
"""计算损失函数"""
z = self.predict(x)
y = af.softmax(z)
loss = ls.cross_entropy_error(y, t)
return loss
net = SimpleNet() # 创建SiampleNet对象
x = np.array([0.6, 0.9]) # 输入为x0 = 0.6, x1 = 0.9
p = net.predict(x) # 前向传播,预测结果
print(p) # softmax的结果
print(np.argmax(p)) # 以softmax结果的最大值元素的下标作为预测结果
t = np.array([0, 1, 0]) # 设定正确解的为1
print(net.loss(x, t)) # 输出loss
"""输出此时梯度"""
f = lambda w: net.loss(x, t)
dW = grad.numerical_gradient(f, net.W)
print(dW)
输出结果:

最后的2行三列的矩阵就是此时的梯度,意思是:
w 11 = 0.37723279 w_{11}=0.37723279 w11=0.37723279:如果 w 11 w_{11} w11增加 h h h,那么损失函数的结果loss值就会增加0.37723279。
那么我们希望损失函数越小越好,因此如果梯度为正数那么该参数就该往负梯度方向更新,如果梯度为负数,那么该参数就该向梯度方向更新