一、小论文算法的学习
(一)资料链接
1.联邦学习:https://www.baidu.com/s
2.迁移学习概述(Transfer Learning)https://blog.csdn.net/dakenz/article/details/85954548
3.迁移学习:经典算法解析:https://blog.csdn.net/linolzhang/article/details/73358219
4.联邦学习(Federated Learning)https://blog.csdn.net/cao812755156/article/details/89598410
5.机器之心专访杨强教授:联邦迁移学习与金融领域的AI落地https://www.jiqizhixin.com/articles/2018-08-01-6
6.7种常见的迁移学习分类+论文+代码预研https://blog.csdn.net/HUSTHY/article/details/104265749
7.14 篇论文为你呈现「迁移学习」研究全貌 | 论文集精选 #04https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/78423678
8.本周论文推荐(迁移学习、图神经网络)https://blog.csdn.net/qq_27590277/article/details/106263730
9.迁移学习–综述https://blog.csdn.net/vvnzhang2095/article/details/79882013
10.迁移学习——论文集推荐https://blog.csdn.net/DL_wly/article/details/80816230
11.基于旋转森林和极限学习机的大样本集成分类算法https://www.ixueshu.com/document/22cde1e97521595b6ade618384b94eec318947a18e7f9386.html
12.集成学习之Adaboost算法原理小结https://www.cnblogs.com/pinard/p/6133937.html
13.迁移学习算法之TrAdaBoosthttps://blog.csdn.net/augster/article/details/53039489
14.结合旋转森林和Ada Boost分类器的多标签文本分类方法https://www.ixueshu.com/document/18debfaea2340c5d6778bd885a07fe56318947a18e7f9386.html
15.TSVM和TrAdaboosthttps://zhuanlan.zhihu.com/p/58305064
代码:https://github.com/ICDI0906/MachineLearning/tree/master/%E5%AE%9E%E8%B7%B5/air-quality_transfer_semi-supervised/TrAdaboost
16.迁移学习算法之TrAdaBoosthttps://www.cnblogs.com/bonelee/p/8921579.html
17.机器学习代码库网站:https://scikit-learn.org/stable/index.html
http://www.scikitlearn.com.cn/
(二)具体算法模型
1.慢性肾脏疾病
2.算法:rnn,knn,mlp,cnn
3.波士顿房价预测
4.学一下numpy pandas matplotlib——python的三个库
http://vision.stanford.edu/teaching/cs231n-demos/knn/
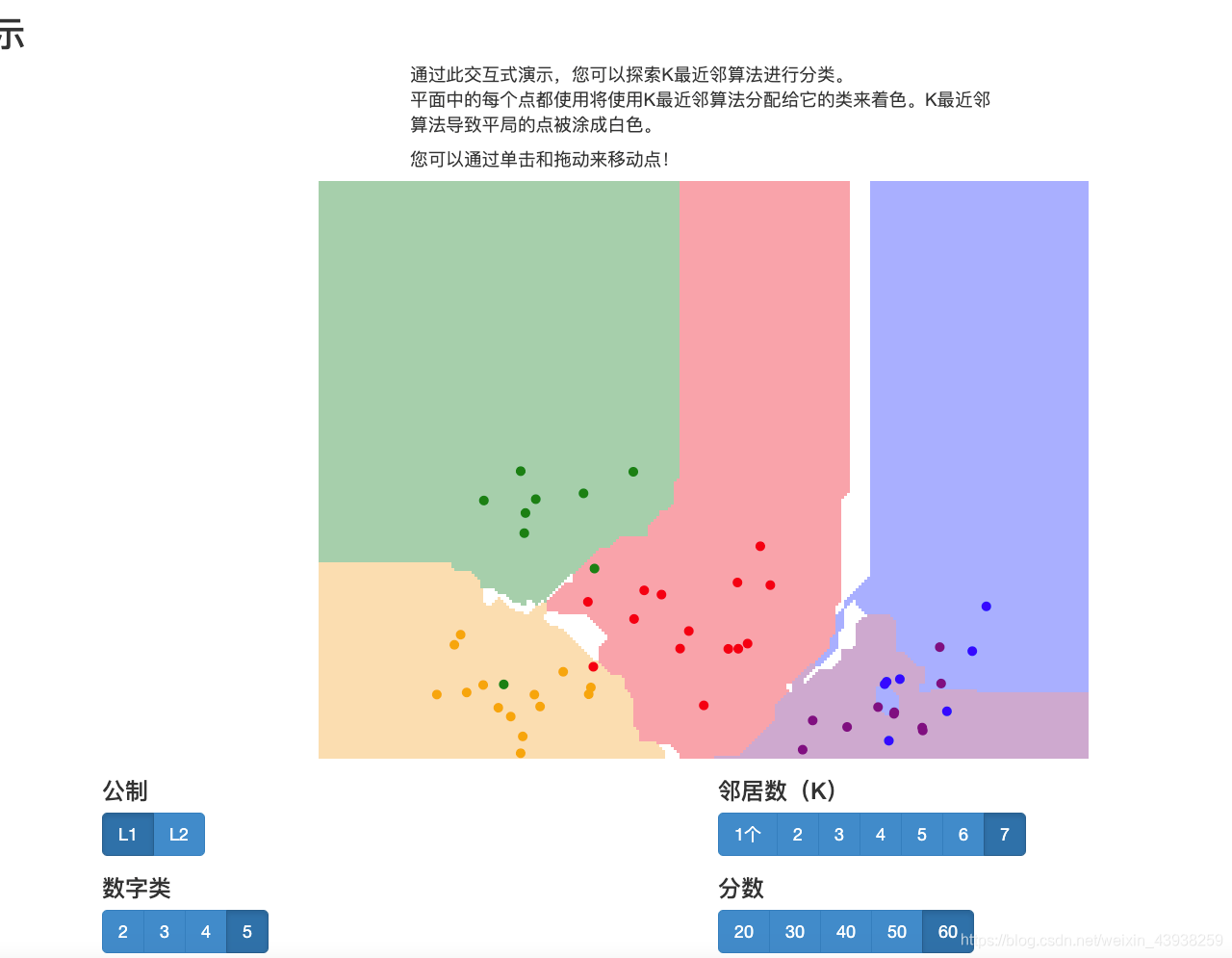
https://aistudio.baidu.com/aistudio/education/group/info/888
-
cnn-svm算法
参考资料:
(1)CNN提取图片特征,之后用SVM分类:https://blog.csdn.net/qq_27756361/article/details/80479278
(2)CNN+SVM实现多分类:https://blog.csdn.net/qq_33254870/article/details/86527295
(3)如何使用把CNN提取的特征用SVM做分类训练:http://www.caffecn.cn/?/question/1910
(4)CNN-SVM代码:http://www.pudn.com/Download/item/id/4022920.html
(5)卷积神经网络提取特征并用于SVM:https://www.cnblogs.com/chuxiuhong/p/6132814.html -
数据集
(1)UCI数据集整理(附论文常用数据集):https://blog.csdn.net/qq_32892383/article/details/82225663
(2)ckd数据:https://www.kaggle.com/mansoordaku/ckdisease/data -
参考论文
(1)一减小的特征集合慢性肾脏疾病预测:http://www.jpathinformatics.org/article.asp?issn=2153-3539;year=2017;volume=8;issue=1;spage=24;epage=24;aulast=Misir
(2)基于深度学习的慢性肾脏病自动感应系统(暂时不用):https://ieeexplore.ieee.org/document/8843936/figures#figures
(3)01-Neural network and support vector machine for the prediction of chronic kidney disease
(4)万方智搜:http://www.wanfangdata.com.cn/search/searchList.do
(5)SVM在冠心病分类预测中的应用研究 -
数据处理,特征选择
(1)Weka数据挖掘——选择属性:https://www.cnblogs.com/mrzhang123/p/5365811.html
(2)算法的参考资料:https://recomm.cnblogs.com/blogpost/5818027?page=3
(3)机器学习 — 参数优化与模型选择:https://www.cnblogs.com/WayneZeng/p/9290688.html -
svm算法
(1)SVM理解与参数选择(kernel和C):https://blog.csdn.net/ybdesire/article/details/53915093 -
小论文跑代码:https://aistudio.baidu.com/aistudio/index
波士顿房价预测
学习网址:https://aistudio.baidu.com/aistudio/projectdetail/955516
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。
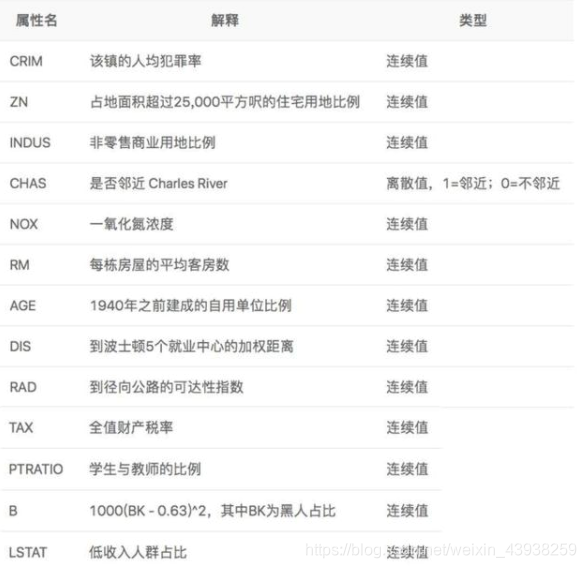
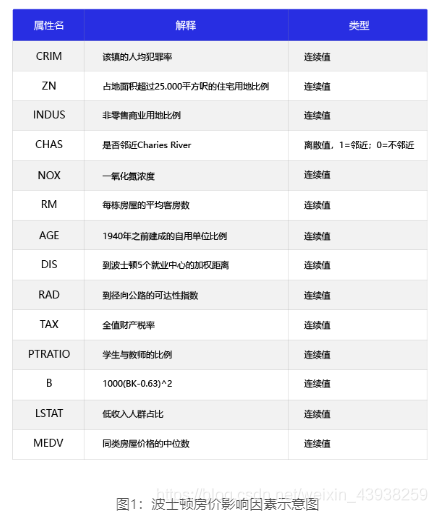
- 该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如 图1 所示。
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
一、线性回归模型

二、构建波士顿房价预测任务的神经网络模型
深度学习不仅实现了模型的端到端学习,还推动了人工智能进入工业大生产阶段,产生了标准化、自动化和模块化的通用框架。不同场景的深度学习模型具备一定的通用性,五个步骤即可完成模型的构建和训练,如 图3 所示。
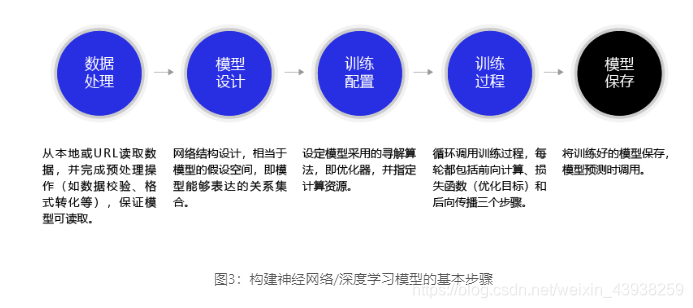
(一)数据处理
数据处理包含五个部分:
- 数据导入
- 数据形状变换
- 数据集划分
- 数据归一化处理
- 封装load data函数
数据预处理后,才能被模型调用。
1. 读入数据
通过如下代码读入数据,了解下波士顿房价的数据集结构,数据存放在本地目录下housing.data文件中。
# 导入需要用到的package
import numpy as np
import json
# 读入训练数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
data
2. 数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 查看数据
x = data[0]
print(x.shape)
print(x)
3. 数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。
三、小论文的参考网站
https://www.paperswithcode.com/sota



![[附源码]计算机毕业设计JAVA健身健康规划系统](https://img-blog.csdnimg.cn/a15c5953fa21418bbd44b6c3e1b0e514.png)