关于ADPCM
ADPCM(Adaptive Differential Pulse Code Modulation, 自适应差分脉冲编码调制) 是一种音频信号数字化编码技术, 音频压缩标准G.722, G.723, G.726 中都会使用到 ADPCM
G.722 is an ITU-T standard 7 kHz wideband audio codec operating at 48, 56 and 64 kbit/s. It was approved by ITU-T in November 1988. Technology of the codec is based on sub-band ADPCM (SB-ADPCM). The corresponding narrow-band codec based on the same technology is G.726.[1]
G.723 is an ITU-T standard speech codec using extensions of G.721 providing voice quality covering 300 Hz to 3400 Hz using Adaptive Differential Pulse Code Modulation (ADPCM) to 24 and 40 kbit/s for digital circuit multiplication equipment (DCME) applications.
G.726 is an ITU-T ADPCM speech codec standard covering the transmission of voice at rates of 16, 24, 32, and 40 kbit/s. It was introduced to supersede both G.721, which covered ADPCM at 32 kbit/s, and G.723, which described ADPCM for 24 and 40 kbit/s. G.726 also introduced a new 16 kbit/s rate. The four bit rates associated with G.726 are often referred to by the bit size of a sample, which are 2, 3, 4, and 5-bits respectively. The corresponding wide-band codec based on the same technology is G.722.
要了解ADPCM, 需要先了解PCM和DPCM.
PCM, Pulse Code Modulation, 脉冲编码调制
PCM 是声音模拟信号数字化的一种基础技术, 就是把时间连续取值连续的模拟信号变换成离散取值的数字信号, 熟悉ADC(模拟数字转换)的应该很好理解, 过程就是采样, 量化和编码.
1. 采样
用固定的频率, 对模拟信号提取样本值, 人耳能够感觉到的最高频率为20kHz, 根据奈奎斯特采样定律, Nyquist rate, 只需要每秒进行40k次采样, 就能覆盖人耳的听觉范围, 也就是说采样高于40k每秒对于普通人来说, 听觉基本上没有提升了.
In signal processing, the Nyquist rate, named after Harry Nyquist, is a value (in units of samples per second or hertz, Hz) equal to twice the highest frequency (bandwidth) of a given function or signal. When the function is digitized at a higher sample rate (see § Critical frequency), the resulting discrete-time sequence is said to be free of the distortion known as aliasing. Conversely, for a given sample-rate the corresponding Nyquist frequency in Hz is one-half the sample-rate. Note that the Nyquist rate is a property of a continuous-time signal, whereas Nyquist frequency is a property of a discrete-time system.
人类语音的频率在300 - 3000 Hz之间, 成年男性的语音基频在85-155Hz, 女性在165-255Hz, 同时会产生丰富的谐振频率, 在通信上, 需要保证 300 - 3400Hz 的频率范围才能满足正常通话, 对于这个频率范围, 需要使用 8K每秒的采样率. 通常电话的采样率为8k和16kHz.
The voiced speech of a typical adult male will have a fundamental frequency from 85 to 155 Hz, and that of a typical adult female from 165 to 255 Hz.[3] Thus, the fundamental frequency of most speech falls below the bottom of the voice frequency band as defined. However, enough of the harmonic series will be present for the missing fundamental to create the impression of hearing the fundamental tone.
日常音频信号常见的采样率为8K, 16k, 22.05k, 32k, 44.1k, 48k, 192k. 常见的无线电广播最高采样率为22.05K, CD最高采样率为44.1k, DVD最高采样率为48k, Hi-Res音频采样率可以高达192k.
2. 量化和编码
量化和编码就是把采样得到的信号幅度转换成数字值(ADC), 再组织成固定尺寸的序列. PCM实际上就是一个大数组, 数组中每个值, 代表了当前时间点上的模拟量强度, 在播放时在对应的时间点上被转换为模拟量输出(DAC).
在量化的过程中会产生误差, 一般而言, ADC的精度越高, 失真越小. 常见的量化位数为8bit, 16bit, 24bit. 模数转换都会有误差和底噪, 对于ADC而言, 除了精度, 还有转换的实现方式, 电压基准, 电磁环境等都会对转换效果造成影响.
DPCM, Differential Pulse Code Modulation, 差分脉冲编码调制
PCM 保存的是最原始的模数转换结果, 是不压缩的, 数据量比较大, 存储和通讯都会占用很大资源, 需要将数据压缩以减少通信带宽和存储的资源消耗.
将音频PCM的数组展开观察可以看到, 数据值与相邻的值通常是比较连续的, 不会突然很高或者突然很低, 两点之间差值不会太大, 所以这个差值可以用很少的几个位(比如4bit)表示. 这样只需要知道起始点的值和每个点的差值, 就可以还原得到原来的序列. 记录的差值序列就是DPCM数据, 这样数据量会小很多.
以8k采样率为例, 如果量化精度为16bit, 则1秒的数据量为8000 * 16 bit = 128kb, 如果用4bit的表示差值, 则1秒的 PCM 数据转成 DPCM 只需要约 32kb.
ADPCM, Adaptive Differential Pulse Code Modulation, 自适应差分脉冲编码调
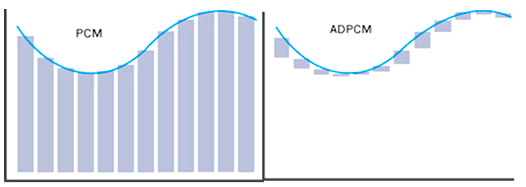
DPCM存在一个问题, 音频信号虽然比较连续性, 但是存在差值较大的情况, 例如差值超过4bit表示的范围(-15, 15) 就无法很好还原原来的PCM序列, 这时候如果增大差值宽度, 例如用6bit, 8bit表示, 可以减小这个问题, 但数据量也增大了.
ADPCM 的出发点就是解决 DPCM 的差值宽度问题, 通过定义一个差值表(例如IMA ADPCM 中使用 89个固定差值, 取值从7到32767), 将差值的范围放宽到16bit, 此时差值在数组中的编号只需要6bit就可以表示(0 - 88), 再进一步只记录编号的变化值, 就将变化量压缩到了4bit.
ADPCM算法是一个统称, 有 YAMAHA, Microsoft, IMA 等标准, 下面以嵌入式开发中最常见的 IMA ADPCM 为例进行说明
IMA ADPCM 编码
在了解编解码算法前, 先了解 IMA ADPCM 的编码格式.
16bit的 IMA ADPCM 编码产生的数据为一个数组, 数组中每个数都是4个bit(值范围为0x00到0x0F), 因为C语言编程中变量的最小单位是byte, 所以通常表示为 uint8_t 数组, 数组中每个元素存储2个 ADPCM 编码值, 或者对于32位系统使用 uint32_t, 每个元素存储8个 ADPCM 编码值.
对于IMA ADPCM, 还需要了解两个码表, 一个是差值步长码表, 一个是差值步长下标变化量码表
- 差值步长码表: 下标从0到88, 共89个值, 从小到大, 非均匀分布, 下标越大, 值之间的间隔越大, 这个码表的具体计算方式不清楚, 通过多次项拟合需要至少4次方到5次方才能拟合.
- 差值步长下标变化量码表: 下标从-7到7, ADPCM 队列中每个值可以通过这个直接查表得到下一个值的差值步长的下标变化量, 进而得到下一个值的差值步长. 值在 [-3, 3] 之间的, 变化都是-1, 也就是差值步长变小, 在[-4,-7]和[4,7]的, 变化是2,4,6,8, 可以看到对于-7和7, 差值步长会快速增大.
IMA ADPCM的编码格式说明
知道了 ADPCM 编码值的格式, 也知道了两个码表, 就可以了解 ADPCM 编码值中各个bit位的作用.
例如一个编码值为0x05, 对应二进制0101, 其中最高位为0, 代表变化为正, 输出值是在前一个值上叠加; 低三位为5, 代表差值步长下标变化量为+4, 也就是差值步长变大了, 另外第三位的每一位分别代表对应实际差值的差值步长的倍数, 参与了差值的计算
| bit位 | 值 | 含义 |
|---|---|---|
| 4 | 0 | 最高位代表了正负, 如果是0, 代表这个差值是正的, 1则表示差值是负的 |
| 3 | 1 | 1-3bit合起来代表了下一个值的差值步长下标变化量, 同时每个bit代表当前步长的一个系数, 这个bit表示1倍差值步长 |
| 2 | 0 | 这个bit表示0.5倍差值步长 |
| 1 | 1 | 这个bit表示0.25倍差值步长 |
以上会产生 1 + 0 + 0.25 = 1.25倍的差值步长, 加上固定的1/8步长, 就是说这一步产生的输出 = 前一步数值 + 当前差值步长 * 1.375, 这个值会作为下一步的数值, 同时下一步的差值步长下标+4, 也就是下一个值的计算中用到的差值步长增大了.
IMA ADPCM 的编解码例子
输入序列为
uint16_t nums[12] = {0x0010, 0x0020, 0x0030, 0x0040, 0x0050, 0x0050, 0x0050, 0x0040, 0x0400, 0x0400, 0x0400, 0x0400};
使用 IMA ADPCM 对上面的序列进行编码, 每一步的记录, 第一列为输入, 最后一列为输出
- 初始: 0x0000,
- 输入: 0x0010, 步长下标0x00, 步长0x0007, 前采样值0x0000, 输出: 编码0x7
- 输入: 0x0020, 步长下标0x08, 步长0x0010, 前采样值0x000B, 输出: 编码0x5
- 输入: 0x0030, 步长下标0x0C, 步长0x0017, 前采样值0x0021, 输出: 编码0x2
- 输入: 0x0040, 步长下标0x0B, 步长0x0015, 前采样值0x002E, 输出: 编码0x3
- 输入: 0x0050, 步长下标0x0A, 步长0x0013, 前采样值0x003F, 输出: 编码0x3
- 输入: 0x0050, 步长下标0x09, 步长0x0011, 前采样值0x004E, 输出: 编码0x0
- 输入: 0x0050, 步长下标0x08, 步长0x0010, 前采样值0x0050, 输出: 编码0x0
- 输入: 0x0040, 步长下标0x07, 步长0x000E, 前采样值0x0052, 输出: 编码0xD
- 输入: 0x0400, 步长下标0x0B, 步长0x0015, 前采样值0x0040, 输出: 编码0x7
- 输入: 0x0400, 步长下标0x13, 步长0x002D, 前采样值0x0066, 输出: 编码0x7
- 输入: 0x0400, 步长下标0x1B, 步长0x0061, 前采样值0x00B9, 输出: 编码0x7
- 输入: 0x0400, 步长下标0x23, 步长0x00D1, 前采样值0x016E, 输出: 编码0x7
解码输出的序列为
# 解码结果
0x000B, 0x0021, 0x002E, 0x003F, 0x004E, 0x0050, 0x0052, 0x0040, 0x0066, 0x00B9, 0x016E, 0x02F5
# 作为参照的原输入序列
0x0010, 0x0020, 0x0030, 0x0040, 0x0050, 0x0050, 0x0050, 0x0040, 0x0400, 0x0400, 0x0400, 0x0400
通过观察可以得到几个规律
- 解码还原的结果, 就是编码过程中每一次产生的presample
- 每一次的code, 查表得到偏移量, 叠加在当前的index上, 产生下一个index, 而index又决定了step大小
- step的大小并不会直接影响下一个presample, 而是会跟code进行计算, 最多1.875个step, 最少0.125个step
- code 第四位(高) – 决定正负
- code 第三位 – 一个step
- code 第二位 – 1/2个step
- code 第一位(低) – 1/4个step
- 不管以上何值, 都会带一个1/8 step 的变化
- 如果code大于4或小于-4, 说明差值大于一个步长, 步长需要增大, 这个规则体现在了差值步长下标变化量码表
IMA ADPCM 的代码分析
码表
/* 差值步长码表 */
const uint16_t StepSizeTable[89]={7,8,9,10,11,12,13,14,16,17,
19,21,23,25,28,31,34,37,41,45,
50,55,60,66,73,80,88,97,107,118,
130,143,157,173,190,209,230,253,279,307,
337,371,408,449,494,544,598,658,724,796,
876,963,1060,1166,1282,1411,1552,1707,1878,2066,
2272,2499,2749,3024,3327,3660,4026,4428,4871,5358,
5894,6484,7132,7845,8630,9493,10442,11487,12635,13899,
15289,16818,18500,20350,22385,24623,27086,29794,32767};
/* 差值步长下标变化量码表 */
const int8_t IndexTable[16]={0xff,0xff,0xff,0xff,2,4,6,8,0xff,0xff,0xff,0xff,2,4,6,8};
编码函数
熟悉前面的格式和编解码逻辑, 下面的代码就比较好理解了. 函数输入是一个16bit数字, 输出一个4bit数字, 中间用两个static变量, 用于存储前一步确定的差值步长下标, 以及前一次的解码值, 参与下一个值的编码计算
uint8_t ADPCM_Encode(int32_t sample)
{
// index 存储的是上一次预测的差值步长下标, 通过查表可以得到步长
static int16_t index = 0;
// predsample 存储的是上一个解码值, 解码还原时产生的就是这个值
static int32_t predsample = 0;
// 当前输入值, 编码后的输出, 4个bit
uint8_t code=0;
uint16_t tmpstep=0;
int32_t diff=0;
int32_t diffq=0;
uint16_t step=0;
// 先拿到差值步长
step = StepSizeTable[index];
// 看看当前输入值, 跟上一个输出值的差值
diff = sample-predsample;
// 如果是负的, 就给code 的高4位置1, 表示差值是负数
if (diff < 0)
{
code=8;
diff = -diff;
}
tmpstep = step;
// 以下根据差值, 计算步长的乘数系数(同时就会产生步长下标的偏移量)
// 首先是固定的 1/8个step
diffq = (step >> 3);
// 下面就是按位进行除法, 每一位的结果被依次赋值到code的3,2,1位, 同时presample的值也算出来了
if (diff >= tmpstep)
{
code |= 0x04;
diff -= tmpstep;
diffq += step;
}
tmpstep = tmpstep >> 1;
if (diff >= tmpstep)
{
code |= 0x02;
diff -= tmpstep;
diffq+=(step >> 1);
}
tmpstep = tmpstep >> 1;
if (diff >= tmpstep)
{
code |=0x01;
diffq+=(step >> 2);
}
// 到这一步, 如果code值大于等于4或小于等于-4, 就说明差值大于当前的步长(至少是1.125倍), 步长要增加, 否则步长要收缩
// 以下都是避免值越界的一些计算
if (code & 8)
{
predsample -= diffq;
}
else
{
predsample += diffq;
}
if (predsample > 32767)
{
predsample = 32767;
}
else if (predsample < -32768)
{
predsample = -32768;
}
// 查表得到下一个数的差值步长下标
index += IndexTable[code];
// 避免越界
if (index <0)
{
index = 0;
}
else if (index > 88)
{
index = 88;
}
// 避免越界
return (code & 0x0f);
}
解码函数
解码就是将ADPCM数组中的每个4bit数值, 还原回编码过程中的每个presample值.
/**
* @brief ADPCM_Decode.
* @param code: a byte containing a 4-bit ADPCM sample.
* @retval : 16-bit ADPCM sample
*/
int16_t ADPCM_Decode(uint8_t code)
{
// 上一步预测的差值步长下标
static int16_t index = 0;
// 上一步的解码值
static int32_t predsample = 0;
uint16_t step=0;
int32_t diffq=0;
// 得到当前步长
step = StepSizeTable[index];
// 根据步长和4bit编码值, 计算当前的实际差值
// 先是1/8的固定差值
diffq = step>> 3;
// 第3位, 1倍步长
if (code&4)
{
diffq += step;
}
// 第2位, 0.5倍步长
if (code&2)
{
diffq += step>>1;
}
// 第1位, 0.25倍步长
if (code&1)
{
diffq += step>>2;
}
// 根据正负符号, 加或者减, 算出解码结果
if (code&8)
{
predsample -= diffq;
}
else
{
predsample += diffq;
}
// 防止越界
if (predsample > 32767)
{
predsample = 32767;
}
else if (predsample < -32768)
{
predsample = -32768;
}
// 查表, 计算得到下一个差值步长的下标
index += IndexTable [code];
// 防止越界
if (index < 0)
{
index = 0;
}
if (index > 88)
{
index = 88;
}
// 返回解码结果
return ((int16_t)predsample);
}
总结
以上说明了ADPCM的原理, 以及通过对 IMA ADPCM 编码代码的分析, 了解 ADPCM 的具体实现. ADPCM的优点是计算简单, 对CPU和存储资源的损耗很小, 以及可观的压缩比(接近4:1), 编解码延时最短(相对其它技术), 缺点是有损压缩, 音质不算好, 压缩率也不算高. 因为对硬件要求低, 适用于低成本低功耗的嵌入式硬件. 对于资源不受限, 有高音质需求, 或者有更高压缩比需求的场景, 可以使用其它的编码算法, 例如LPCM, AAC, MP3等.
参考
- https://wiki.multimedia.cx/index.php/IMA_ADPCM
- IMA ADPCM 设计规范 A scanned, OCR’ed copy of the original IMA/DVI ADPCM specification document http://www.cs.columbia.edu/~hgs/audio/dvi/IMA_ADPCM.pdf 原始扫描件 http://www.cs.columbia.edu/~hgs/audio/dvi/