题目
给你一个字符串s,请你将 s分割成一些子串,使每个子串都是回文串。返回 s 所有可能的分割方案。
回文串: 是正着读和反着读都一样的字符串。
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
题解
该题目看到后首先想到的是动态规划,但是在写状态方程时发现很难写出有效的转移议程。。
通过分析发现其有回溯的特性。回溯算法的相关介绍参考大神的博客:LeetCode--回溯法心得 - 知乎。
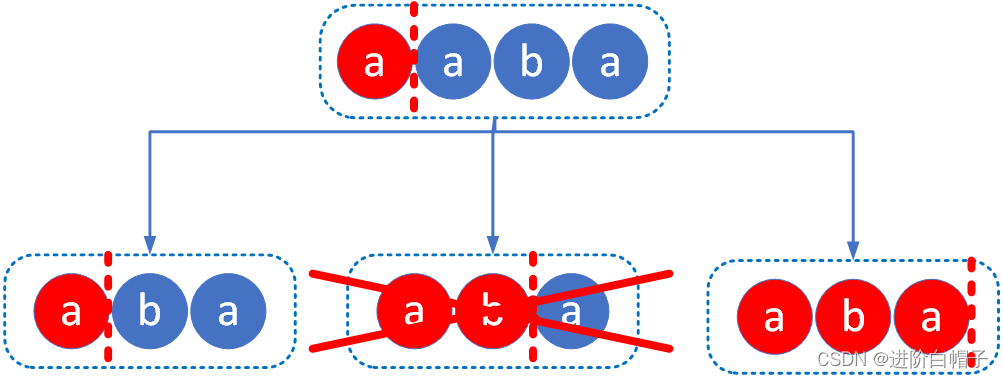
该算法的过程与人工思考的方式想同,以字符串"aaba"为例来说明算法的计算过程。
第一步
我们要找到以第一个字符a开头的回文串,然后把字符串切割成一个回文串与其余部分。其结果如下图所示。

由于后面两个结果的前面的子串并不是回文串因此就不继续考虑这两种情况。
第二步
只需要考虑前面两种情况的未处理的子串,如果第一个后半段的子串aba的处理如下图所示。
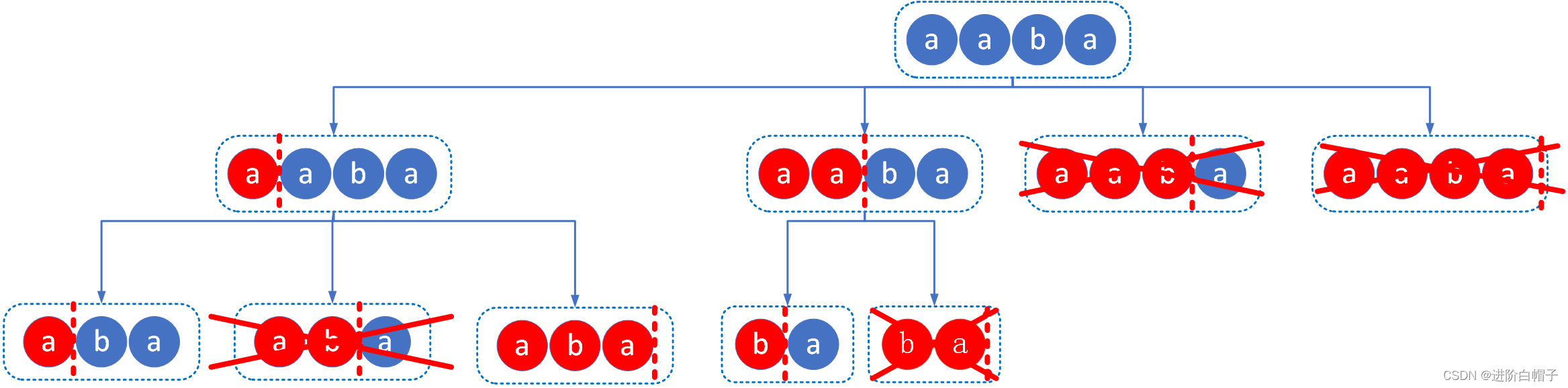
第二个字符串的未处理子串ba的如下图所示。

整个过程如下图所示。
最终
中间过程相似就不一一枚举最后上一下最终结果如下图所示。
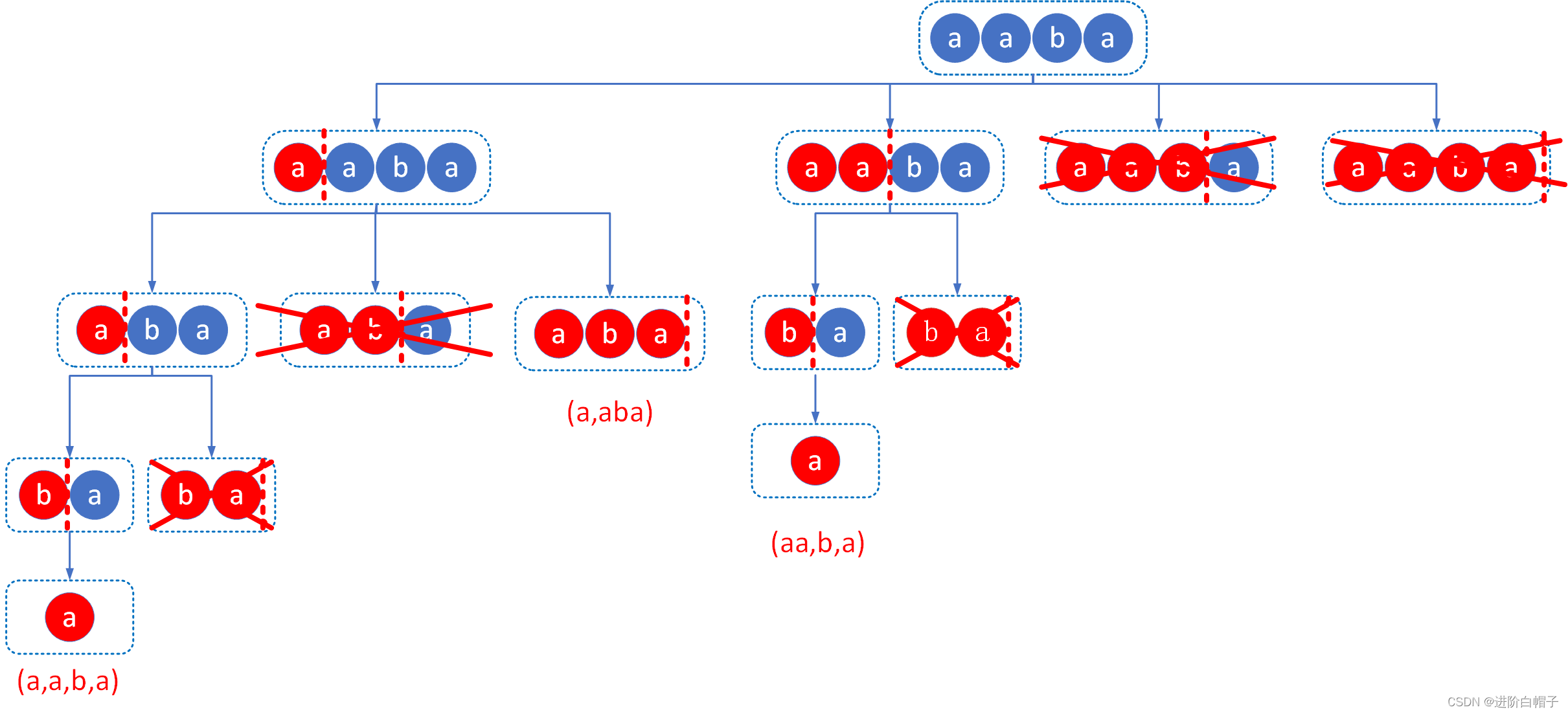
总结起来其实主要是两个模块:划分与回文串判定。
优化
回文串的判定可以进一步优化。对于前 2 个字符 aa,我们有 2 种分割方法 [aa]] 和 [a,a],当我们每一次搜索到字符串的b 时,都需要对b开始的子串判定是否是回文这就产生了重复计算。这种情况符合动态规划的使用条件。
dp[i][j]表示字符串s中的子中s[i:j]是否是回文。
状态转移方程如下所示。
dp[i][j]=dp[i+1][j-1] and s[i]==s[j]
代码
class Solution:
def partition(self, s: str) -> List[List[str]]:
n = len(s)
#初始化状态矩阵
dp = [[True] * n for _ in range(n)]
#判定子串的回文状态,动态规划
for i in range(n - 1, -1, -1):
for j in range(i + 1, n):
dp[i][j] = (s[i] == s[j]) and dp[i + 1][j - 1]
ret = list()
ans = list()
#回溯的递归函数
def dfs(i: int):
if i == n:
ret.append(ans[:])
return
for j in range(i, n):
if dp[i][j]:
ans.append(s[i:j+1])
dfs(j + 1)
#状态复原
ans.pop()
dfs(0)
return ret算法复杂度
时间复杂度:O(n*2^n)。
空间复杂度o(n^2)