一、前言
阅读本节需要先掌握【SPARKSQL3.0-Analyzer阶段源码剖析】
Optimizer阶段是对Analyzer分析阶段的逻辑计划【logicalPlan】做进一步的优化,将应用各种优化规则对一些低效的逻辑计划进行转换
例如将原本用户不合理的sql进行优化,如谓词下推,列裁剪,子查询共用等。
本质:【optimizer阶段是对 Analyzer生成的LogicalPlan进行优化调整生成新的LogicalPlan】
这个阶段的优化器同样是基于大量的规则(Rule),而大部分的规则都是基于直观或经验而得出的规则,随着spark社区的活跃,此优化器阶段的规则也逐渐完善丰满,可以说每一个优化规则都有其诞生的原因,不可不查。
二、示例
由于上一节的示例在优化器中没有明显sql的优化,我们这次举一个谓词下推的优化过程,其他优化规则可根据源码自行推导
此处示例使用的是dataFrameAPI,其原理和spark.sql(“”)底层大致相同,想深入了解两者区别可以看我的另一篇文章:
代码:
spark
.range(2)
.select('id as "_id")
.filter('_id === 0)
.explain(true)
打印:
== Parsed Logical Plan ==
'Filter ('_id = 0)
+- Project [id#0L AS _id#2L]
+- Range (0, 2, step=1, splits=Some(2))
== Analyzed Logical Plan ==
_id: bigint
Filter (_id#2L = cast(0 as bigint))
+- Project [id#0L AS _id#2L]
+- Range (0, 2, step=1, splits=Some(2))
== Optimized Logical Plan ==
Project [id#0L AS _id#2L]
+- Filter (id#0L = 0)
+- Range (0, 2, step=1, splits=Some(2))
......
可以看出在Optimized Logical Plan阶段中,Filter谓词节点从父节点下推到了子节点,假设数据源是数据库,那么这一步谓词下推优化可以将过滤条件下沉到数据库层面进行物理过滤,可以明显减少spark读取的数据量和带宽
三、源码
和Analyzer阶段不同,Optimizer阶段需要有action操作才会触发,这也是正常的,因其dateFrame的懒加载特点有关。
比如我们曾经执行:
val dataFrame = spark.sql("SELECT * FROM (SELECT * FROM PERSON WHERE AGE > 19) WHERE AGE > 18")
在sparkSession的sql函数中内部经历了Unanalyze和Analyze阶段后就返回新的DateSet:
def sql(sqlText: String): DataFrame = withActive {
val tracker = new QueryPlanningTracker
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) {
sessionState.sqlParser.parsePlan(sqlText) // Unresolved阶段
}
Dataset.ofRows(self, plan, tracker)
}
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan, tracker: QueryPlanningTracker)
: DataFrame = sparkSession.withActive {
val qe = new QueryExecution(sparkSession, logicalPlan, tracker)
qe.assertAnalyzed() // Resolved阶段
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema)) // 返回给main函数
}
而Optimizer阶段则只有在action操作触发物理执行计划的时候才会调用[比如dataFrame.take(1)],这里我们看QueryExecution类中的操作,如下:
// sparkPlan是物理执行计划,下一节会详细介绍
lazy val sparkPlan: SparkPlan = {
// 可以看到只有到物理执行计划才会调用assertOptimized函数
assertOptimized()
executePhase(QueryPlanningTracker.PLANNING) {
QueryExecution.createSparkPlan(sparkSession, planner, optimizedPlan.clone())
}
}
......
private def assertOptimized(): Unit = optimizedPlan // 调用lazy变量optimizedPlan
......
lazy val optimizedPlan: LogicalPlan = executePhase(QueryPlanningTracker.OPTIMIZATION) {
// 调用executeAndTrack执行优化策略,参数是withCachedData.clone()克隆结果【其实就是Analyzed-logicalPlan的克隆类】
sparkSession.sessionState.optimizer.executeAndTrack(withCachedData.clone(), tracker)
}
......
// withCachedData函数是执行analyzed阶段
lazy val withCachedData: LogicalPlan = sparkSession.withActive {
assertAnalyzed() // 如果没有解析先进行解析
assertSupported()
// 将analyzed解析后的logicalPlan克隆一份给cacheManager
sparkSession.sharedState.cacheManager.useCachedData(analyzed.clone())
}
......
def assertAnalyzed(): Unit = analyzed
// 上一节讲到的analyzed阶段
lazy val analyzed: LogicalPlan = executePhase(QueryPlanningTracker.ANALYSIS) {
sparkSession.sessionState.analyzer.executeAndCheck(logical, tracker)
}
可以看出optimized阶段是在action操作后才会执行,这样符合懒加载的设计初衷
接下来看一下sparkSession.sessionState.optimizer.executeAndTrack的操作
首先sparkSession.sessionState的optimizer是在BaseSessionStateBuilder类中构建的,默认是SparkOptimizer
这块在SparkSession构建一节讲过:
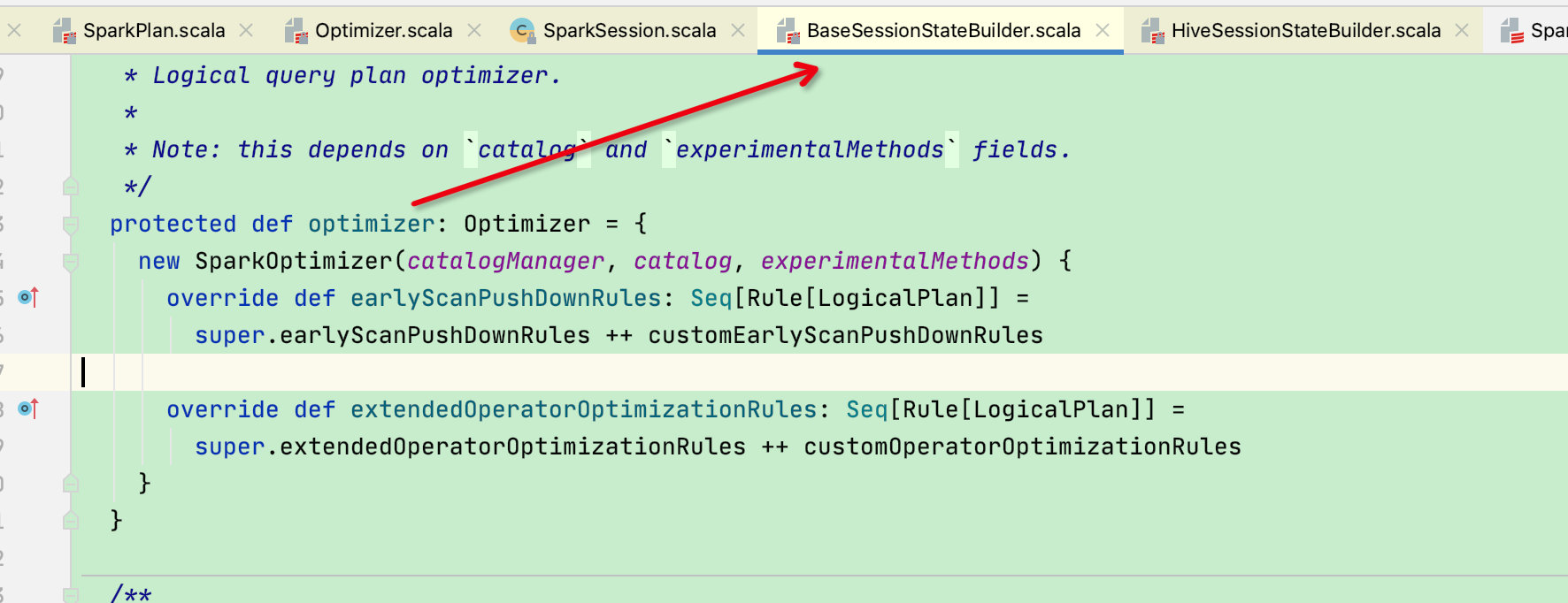
而SparkOptimizer又继承于Optimizer,而Optimizer又继承于RuleExecutor,继承关系如下:

故sparkSession.sessionState.optimizer.executeAndTrack实际上还是走的RuleExecutor类中executeAndTrack函数,这和anlyzer阶段走的函数完全一致,这里贴一下源码:
这里同样也是将所有规则构建为多个批次,并且将所有批次中规则应用于Analyzed LogicalPlan,直到树不再改变或者执行优化的循环次数超过最大限制(spark.sql.optimizer.maxIterations,默认100)
def executeAndTrack(plan: TreeType, tracker: QueryPlanningTracker): TreeType = {
QueryPlanningTracker.withTracker(tracker) {
execute(plan) // 调用execute函数
}
}
def execute(plan: TreeType): TreeType = {
var curPlan = plan
val queryExecutionMetrics = RuleExecutor.queryExecutionMeter
val planChangeLogger = new PlanChangeLogger()
val tracker: Option[QueryPlanningTracker] = QueryPlanningTracker.get
val beforeMetrics = RuleExecutor.getCurrentMetrics()
// 针对初始输入plan,运行结构完整性检查
if (!isPlanIntegral(plan)) {
val message = "The structural integrity of the input plan is broken in " +
s"${this.getClass.getName.stripSuffix("$")}."
throw new TreeNodeException(plan, message, null)
}
// 遍历不同子类实现的batches中定义的 batchs 变量, 此处batches是用的Optimizer子类的实现
batches.foreach { batch =>
// 用来对比执行规则前后,初始的plan有无变化
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// 执行直到达到稳定点或者最大迭代次数
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val startTime = System.nanoTime()
val result = rule(plan)
val runTime = System.nanoTime() - startTime
val effective = !result.fastEquals(plan)
if (effective) {
queryExecutionMetrics.incNumEffectiveExecution(rule.ruleName)
queryExecutionMetrics.incTimeEffectiveExecutionBy(rule.ruleName, runTime)
planChangeLogger.logRule(rule.ruleName, plan, result)
}
queryExecutionMetrics.incExecutionTimeBy(rule.ruleName, runTime)
queryExecutionMetrics.incNumExecution(rule.ruleName)
tracker.foreach(_.recordRuleInvocation(rule.ruleName, runTime, effective))
if (!isPlanIntegral(result)) {
val message = s"After applying rule ${rule.ruleName} in batch ${batch.name}, " +
"the structural integrity of the plan is broken."
throw new TreeNodeException(result, message, null)
}
result
}
iteration += 1
// 到达最大迭代次数, 不再执行优化
if (iteration > batch.strategy.maxIterations) {
// 只对最大迭代次数大于1的情况打log
if (iteration != 2) {
val endingMsg = if (batch.strategy.maxIterationsSetting == null) {
"."
} else {
s", please set '${batch.strategy.maxIterationsSetting}' to a larger value."
}
val message = s"Max iterations (${iteration - 1}) reached for batch ${batch.name}" +
s"$endingMsg"
if (Utils.isTesting || batch.strategy.errorOnExceed) {
throw new TreeNodeException(curPlan, message, null)
} else {
logWarning(message)
}
}
// 检查一次幂等
if (batch.strategy == Once &&
Utils.isTesting && !excludedOnceBatches.contains(batch.name)) {
checkBatchIdempotence(batch, curPlan)
}
continue = false
}
// plan不变了,到达稳定点,不再执行优化
if (curPlan.fastEquals(lastPlan)) {
logTrace(
s"Fixed point reached for batch ${batch.name} after ${iteration - 1} iterations.")
continue = false
}
lastPlan = curPlan
}
planChangeLogger.logBatch(batch.name, batchStartPlan, curPlan)
}
planChangeLogger.logMetrics(RuleExecutor.getCurrentMetrics() - beforeMetrics)
curPlan
}
}
但是注意,这一次用的batches规则可和anlyzer的规则不同,因为RuleExecutor使用的是模版设计模式,batches为抽象函数,由不同子类来实现,此次batches通过多态会调用Optimizer的实现:

这里又调用了defaultBatches

而defaultBatches被Optimizer的子类SparkOptimizer实现:此处会合并父类的defaultBashes 和 子类的规则

但大部分优化器的策略都在父类Optimizer的defaultBashes中,故这里贴一下父类的defaultBatches代码:
def defaultBatches: Seq[Batch] = {
val operatorOptimizationRuleSet =
Seq(
// Operator push down
PushProjectionThroughUnion,
ReorderJoin,
EliminateOuterJoin,
PushDownPredicates,
PushDownLeftSemiAntiJoin,
PushLeftSemiLeftAntiThroughJoin,
LimitPushDown,
ColumnPruning,
InferFiltersFromConstraints,
// Operator combine
CollapseRepartition,
CollapseProject,
CollapseWindow,
CombineFilters,
CombineLimits,
CombineUnions,
// Constant folding and strength reduction
TransposeWindow,
NullPropagation,
ConstantPropagation,
FoldablePropagation,
OptimizeIn,
ConstantFolding,
ReorderAssociativeOperator,
LikeSimplification,
BooleanSimplification,
SimplifyConditionals,
RemoveDispensableExpressions,
SimplifyBinaryComparison,
ReplaceNullWithFalseInPredicate,
PruneFilters,
SimplifyCasts,
SimplifyCaseConversionExpressions,
RewriteCorrelatedScalarSubquery,
EliminateSerialization,
RemoveRedundantAliases,
RemoveNoopOperators,
SimplifyExtractValueOps,
CombineConcats) ++
extendedOperatorOptimizationRules
val operatorOptimizationBatch: Seq[Batch] = {
val rulesWithoutInferFiltersFromConstraints =
operatorOptimizationRuleSet.filterNot(_ == InferFiltersFromConstraints)
Batch("Operator Optimization before Inferring Filters", fixedPoint,
rulesWithoutInferFiltersFromConstraints: _*) ::
Batch("Infer Filters", Once,
InferFiltersFromConstraints) ::
Batch("Operator Optimization after Inferring Filters", fixedPoint,
rulesWithoutInferFiltersFromConstraints: _*) :: Nil
}
val batches = (Batch("Eliminate Distinct", Once, EliminateDistinct) ::
Batch("Finish Analysis", Once,
EliminateResolvedHint,
EliminateSubqueryAliases,
EliminateView,
ReplaceExpressions,
RewriteNonCorrelatedExists,
ComputeCurrentTime,
GetCurrentDatabase(catalogManager),
RewriteDistinctAggregates,
ReplaceDeduplicateWithAggregate) ::
Batch("Union", Once,
CombineUnions) ::
Batch("OptimizeLimitZero", Once,
OptimizeLimitZero) ::
Batch("LocalRelation early", fixedPoint,
ConvertToLocalRelation,
PropagateEmptyRelation) ::
Batch("Pullup Correlated Expressions", Once,
PullupCorrelatedPredicates) ::
Batch("Subquery", FixedPoint(1),
OptimizeSubqueries) ::
Batch("Replace Operators", fixedPoint,
RewriteExceptAll,
RewriteIntersectAll,
ReplaceIntersectWithSemiJoin,
ReplaceExceptWithFilter,
ReplaceExceptWithAntiJoin,
ReplaceDistinctWithAggregate) ::
Batch("Aggregate", fixedPoint,
RemoveLiteralFromGroupExpressions,
RemoveRepetitionFromGroupExpressions) :: Nil ++
operatorOptimizationBatch) :+
Batch("Early Filter and Projection Push-Down", Once, earlyScanPushDownRules: _*) :+
Batch("Join Reorder", FixedPoint(1),
CostBasedJoinReorder) :+
Batch("Eliminate Sorts", Once,
EliminateSorts) :+
Batch("Decimal Optimizations", fixedPoint,
DecimalAggregates) :+
Batch("Object Expressions Optimization", fixedPoint,
EliminateMapObjects,
CombineTypedFilters,
ObjectSerializerPruning,
ReassignLambdaVariableID) :+
Batch("LocalRelation", fixedPoint,
ConvertToLocalRelation,
PropagateEmptyRelation) :+
// The following batch should be executed after batch "Join Reorder" and "LocalRelation".
Batch("Check Cartesian Products", Once,
CheckCartesianProducts) :+
Batch("RewriteSubquery", Once,
RewritePredicateSubquery,
ColumnPruning,
CollapseProject,
RemoveNoopOperators) :+
// This batch must be executed after the `RewriteSubquery` batch, which creates joins.
Batch("NormalizeFloatingNumbers", Once, NormalizeFloatingNumbers)
// remove any batches with no rules. this may happen when subclasses do not add optional rules.
batches.filter(_.rules.nonEmpty)
}
可以看到优化策略有很多,这里贴一下比较重要的一些规则,有些可能已经更名,但并不影响阅读:
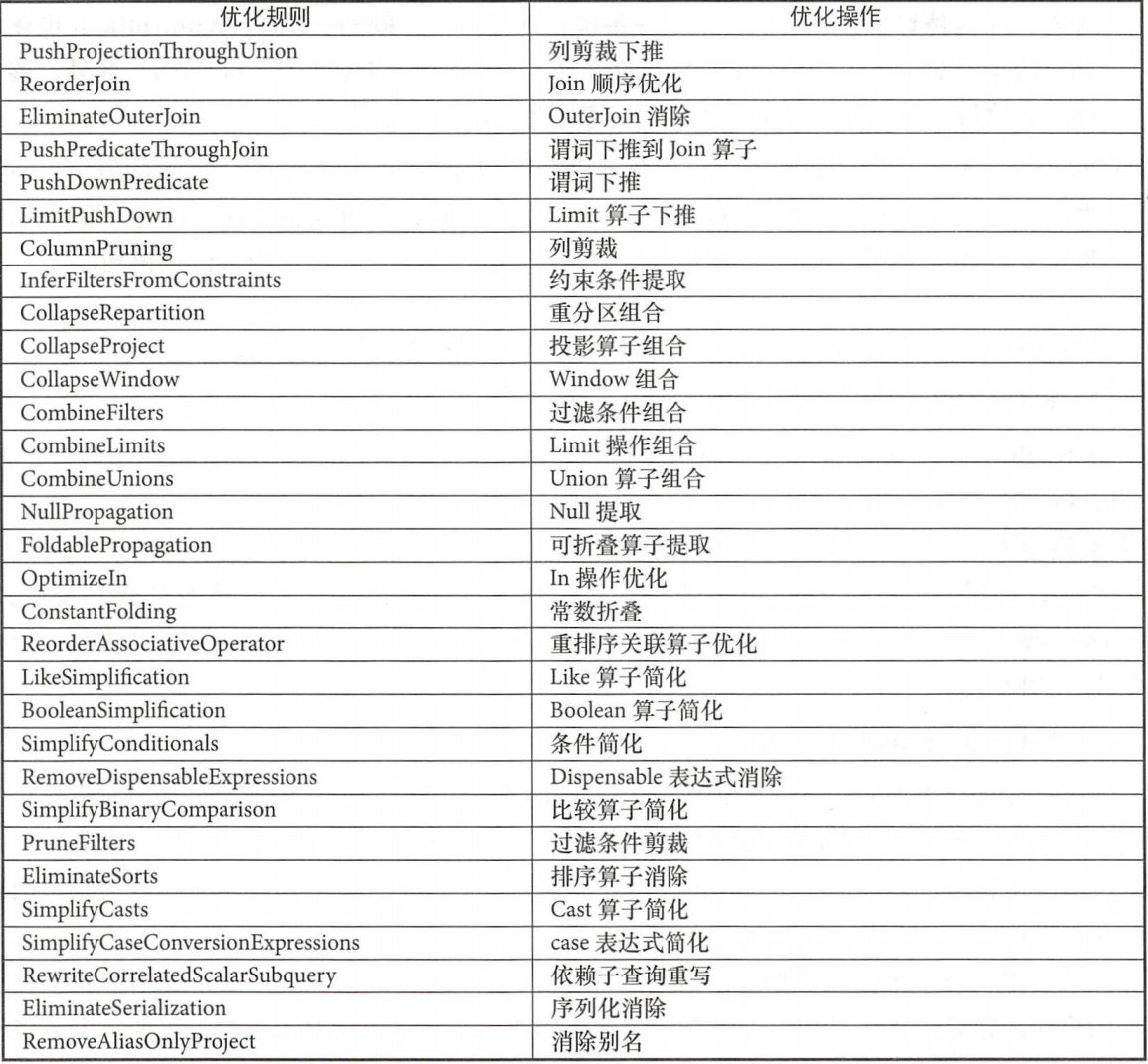
关于Batch和Rule类这里不再过多赘述,在Anlyzer阶段已经介绍过,这里我们主要关注谓词下推的优化策略:PushDownPredicates
接下来我们debug下示例中的代码,可以看到执行到了PushDownPredicates.apply函数,并且传入的logicalPlan和示例中的Anlyzer打印结果保持一致
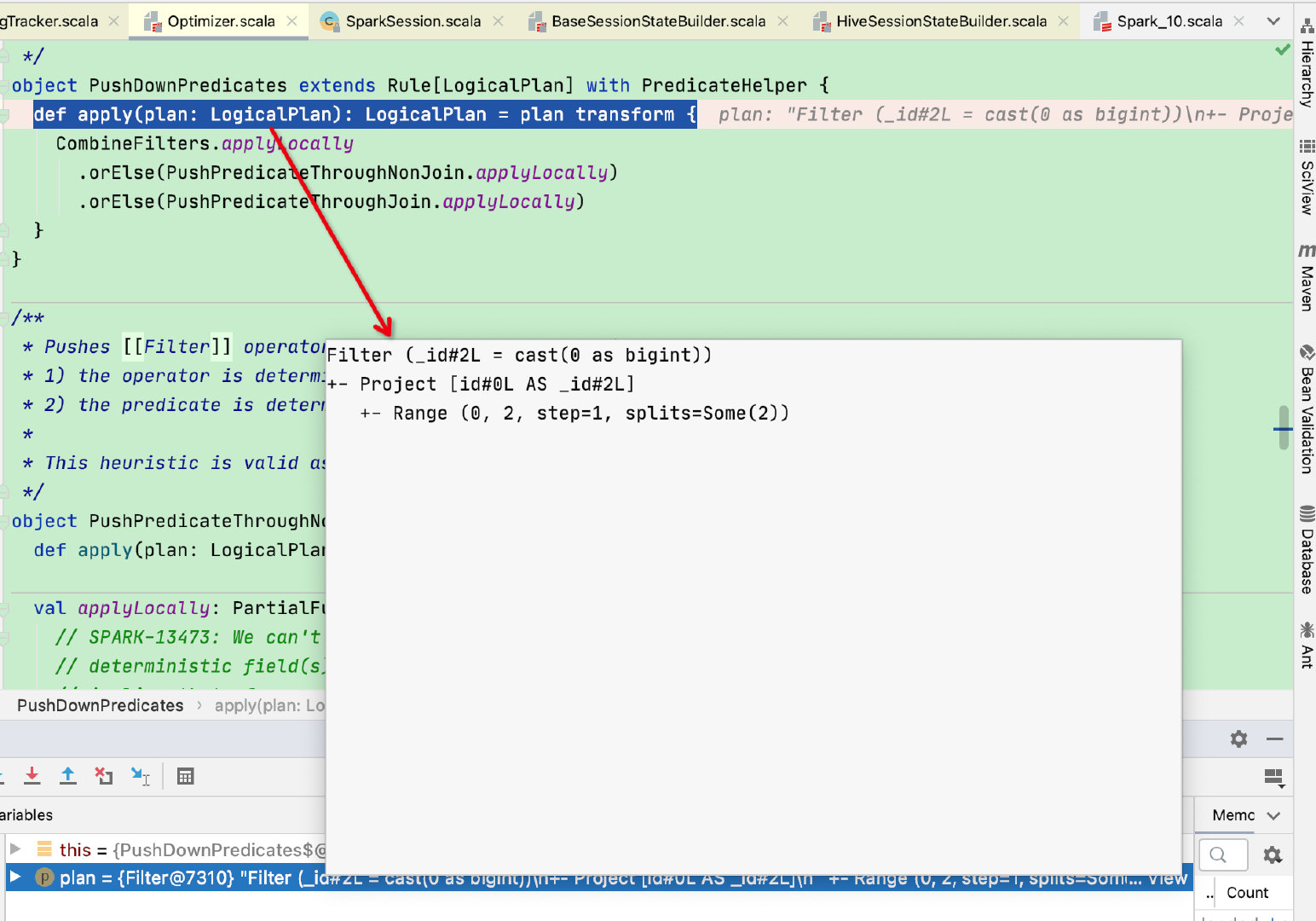
上图中可以看出PushDownPredicates是由三个类组成:CombineFilters、PushPredicateThroughNonJoin、PushPredicateThroughJoin

由于实例中没有涉及到join,故过滤优化条件在PushPredicateThroughNonJoin中实现,这里贴一下部分源码:
object PushPredicateThroughNonJoin extends Rule[LogicalPlan] with PredicateHelper {
def apply(plan: LogicalPlan): LogicalPlan = plan transform applyLocally
val applyLocally: PartialFunction[LogicalPlan, LogicalPlan] = {
// 处理Filter节点下为Project节点的情况
case Filter(condition, project @ Project(fields, grandChild))
if fields.forall(_.deterministic) && canPushThroughCondition(grandChild, condition) =>
val aliasMap = getAliasMap(project)
project.copy(child = Filter(replaceAlias(condition, aliasMap), grandChild))
// 处理Filter节点下为Aggregate节点的情况
case filter @ Filter(condition, aggregate: Aggregate)
......
// 处理Filter节点下为Window节点的情况
case filter @ Filter(condition, w: Window)
......
// 处理Filter节点下为Union节点的情况
case filter @ Filter(condition, union: Union) =>
......
// 处理Filter节点下为水位线节点的情况
case filter @ Filter(condition, watermark: EventTimeWatermark) =>
......
// 处理Filter节点下为其他节点的情况
case filter @ Filter(_, u: UnaryNode)
......
}
根据示例此处直接走到第一个case:
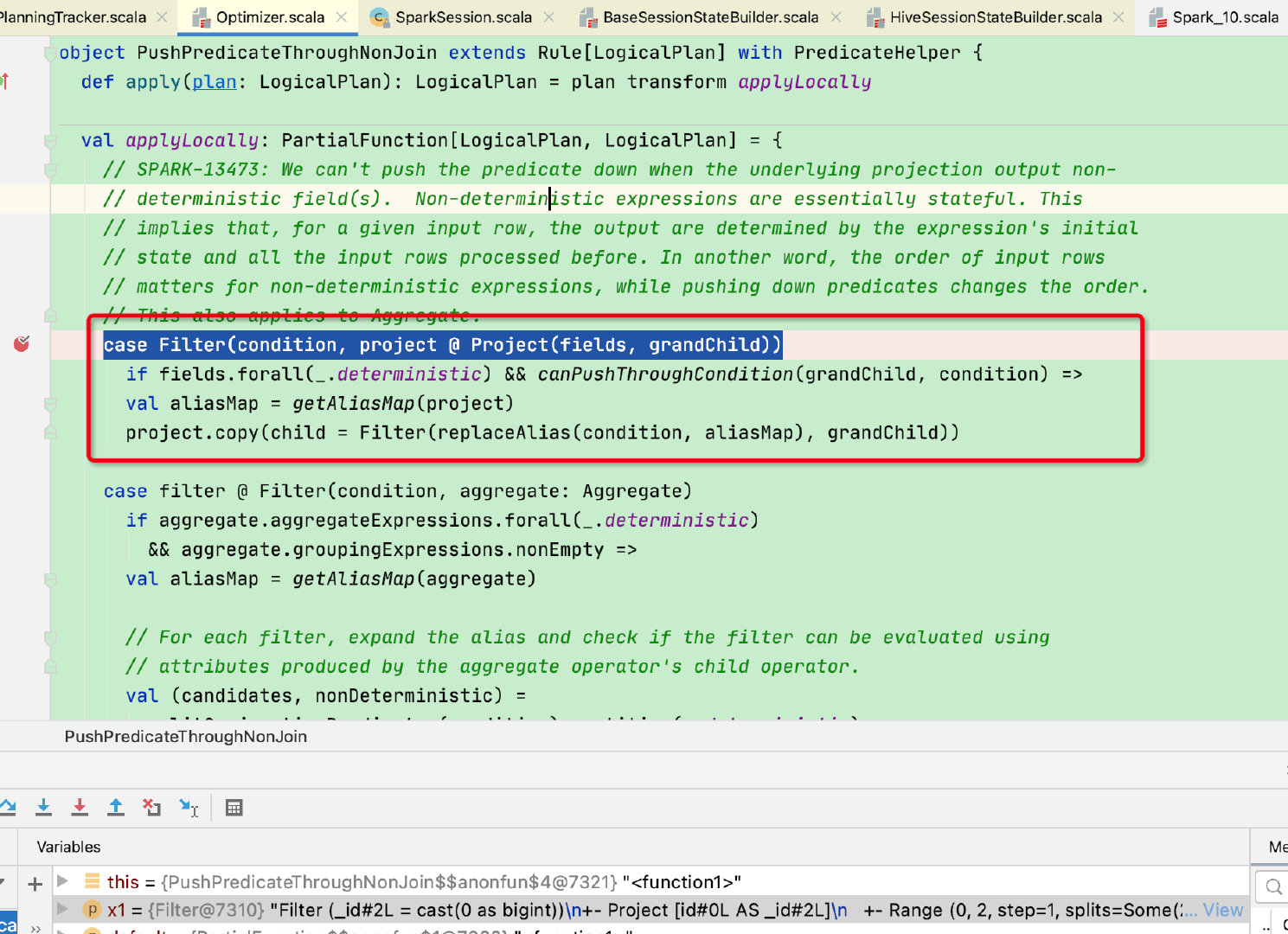
这里可以看到有两个判断条件:
1、 Project节点下的所有fields必须为确定性field
2、 canPushThroughCondition函数用于判断:condition[过滤条件]的输出和grandChild[子节点]的输出有交集
if fields.forall(_.deterministic) && canPushThroughCondition(grandChild, condition)
两个判断只有第一个判断较难理解:Project节点下的所有fields必须为确定性field,这是为何?
因为如果project里的字段是非确定性的话,下推前和下推后的查询效果不一样
比如:sql里用到了monotonically_increasing_id()函数(产生64位整数自增id的非确定性expression)
select a,b,id from (
select A,B,monotonically_increasing_id() as id from
testdata2 where a>2
)tmp where b<1
# 如果下推,就相当于:
select a,b,id from (
select A,B,monotonically_increasing_id() as id from
testdata2 where a>2 and b<1
)tmp
上面两个sql相比,过滤a>2 和 过滤(a>2 and b<1)两种情况下,该sql的数据得到的对应的自增id的情况是不一样的,其它的不确定函数还有rand()函数, 过滤a>2 和 过滤(a>2 and b<1)两种情况下,取rand() 的效果肯定也是不一样的,故要先判断Project节点下的所有fields必须为确定性field

再回到case Filter:当符合条件后先获取对应关系,随后重新构建logicalPlan关系,完成谓词下推

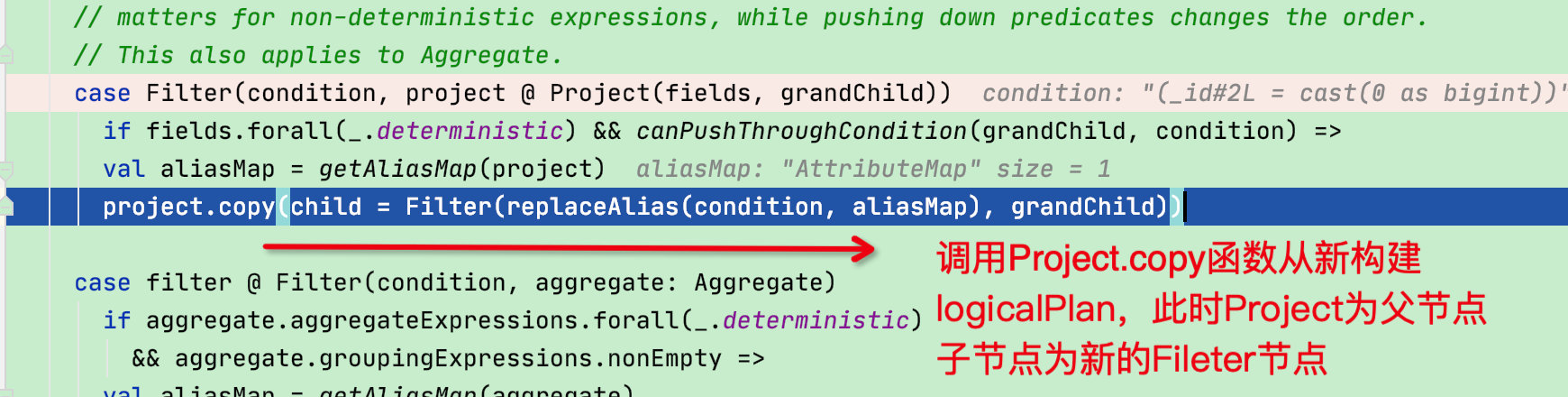
最终返回的logicalPlan赋值给QueryExecution的optimizedPlan:符合示例打印结果,完成谓词下推
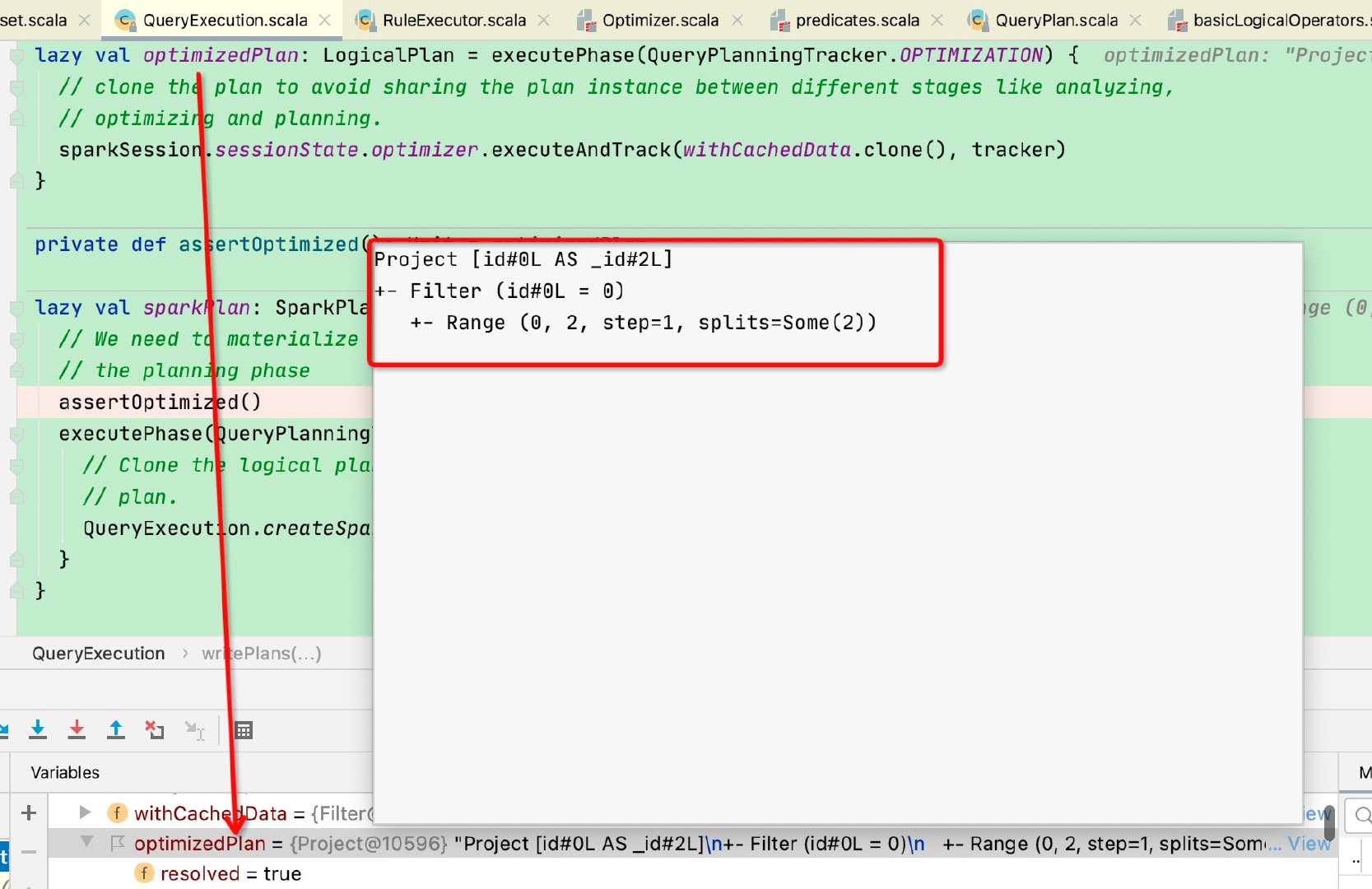
至此optimized阶段结束