目录
前言
1. 为什么查询性能差
2. 一次查询的生命周期
2.1 客户端与服务端通信
2.2 查询缓存
2.3 解析器
2.4 预处理器
2.5 优化器
2.6 查询引擎
2.7 存储引擎
3. 查询性能优化的思路
4.总结
前言
一说到mysql的查询性能优化,相信很多人能说出来很多的技巧和方法,如建索引、尽量不要用select *、join不要超过3张表等等,网上有很多的文章都是类似这样的技巧和方法,这些技巧有用吗?确实有用,但是分情况,不是什么情况下都适用的。另外,我认为业务场景比较复杂的时候,硬搬技巧并非明智之举。因此,我想通过这篇文章分享一下mysql查询性能优化的思路,而不是技巧。
选择正确的处理mysql查询性能问题的思路,再根据实际情况选择合适的技巧,这就是我想与大家分享的关键。
1. 为什么查询性能差
我们都知道这样一个事实,一个高性能的查询,离不开合理的表结构设计、合理的索引结构设计、合理的查询sql设计。通常情况下,收到运维关于慢sql的反馈时,表结构的设计已经完成,且轻易不能去改动,否则可能会对业务产生影响,可以做的优化思路就是从索引、查询语句本身这两个方面展开。
所谓的查询性能差,实质是指客户端发出一个sql查询请求,到服务端完成响应的所消耗的时间比较长。那么如果优化查询性能,就有必要了解清楚从客户端发出sql请求到服务端完成查询结果响应的生命周期里都经历了哪些过程?每个过程都做了哪些任务?在执行任务的规则是什么?优化查询的主要思路就是查询语句本身应该尽可能的适配这些规则,这些任务才能被高效的完成,查询的性能才能变理更好。
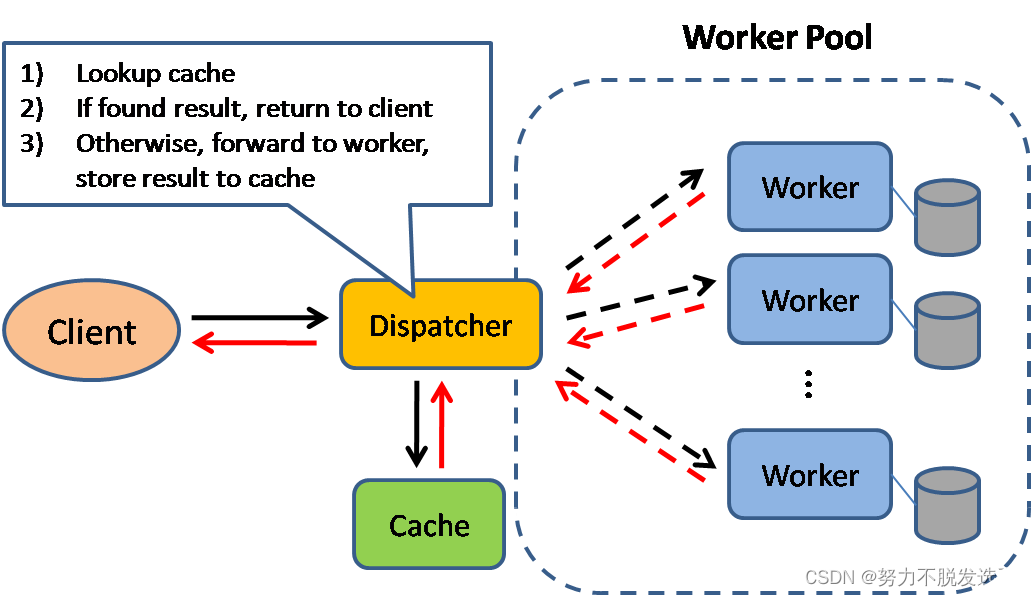
2. 一次查询的生命周期
1.sql通过网络通信协议,从客户端发磅到服务端。
2.服务端收到sql后,查询缓存是否有匹配结果,若存在缓存,则直接取出缓存中结果返回,
否则进行下一阶段。
3.服务端对sql进行解析、预处理,然后生成查询计划。
4.执行引擎根据优化器生成的查询计划,调用存储引擎的API接口,拿到查询结果,然后返回
给客户端,同是缓存查询结果,不过缓存查询结果需要手动配置才会生效。
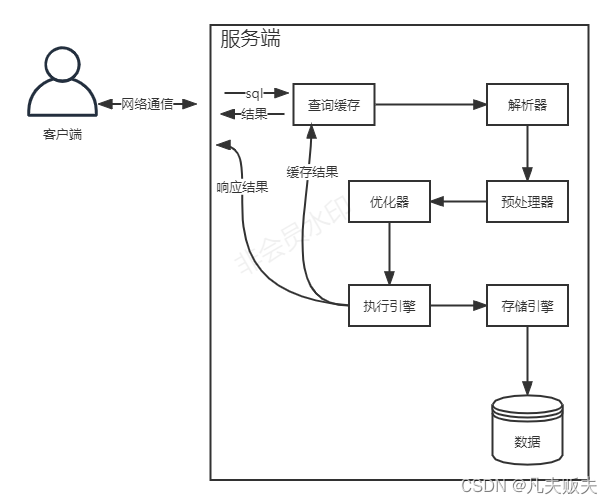
2.1 客户端与服务端通信
mysql客户端与服务端的通信协议是半双工的,意味着任何一个时刻,要么是客户端在向服务端发送请求数据,要么就是服务端在向客户端发送响应数据,这两个动作不能同时发生。
2.2 查询缓存
如果查询缓存的配置是打开,服务端收到sql后,会先查询缓存是否要命中。如果命中缓存,则校验完权限,不需要解析sql就可以从缓存中取出结果返回给客户端。
2.3 解析器
通过msyql的关键字将sql语句解析成一颗“解析树”,使用mysql的语法规则验证和解析查询,如验证是否有错误的关键字、关键字的顺序是否正确等
2.4 预处理器
预处理器根据mysql的一些规则进一步检查解析树是否合法,如表、数据列是否存在、表名和别名是否有歧义、是否拥有相应的权限配置
2.5 优化器
基于成本分析生成一个查询计划,所谓成本分析是指mysql本身会基于配置和一些统计信息,找到执行这条查询最好的执行计划。这个过程是非常复杂的,也是科学严谨的,所以大多数时候,基于成本分析生成的查询计划就是最好的。前一篇文章《使用mysql-explain 查询sql执行计划,你会用了吗》的主要内容就是如何通过explain命令查看解读优化器生成的查询计划,这对于查询性能的优化很帮助。千万不要遇到一个慢sql,上来就各种技巧一阵应用,结果发现没什么效果,就尴尬了。
2.6 查询引擎
查询引擎的作用就是根据优化器生的查询计划,调用存储引擎的接口,去拿数据。
2.7 存储引擎
存储引擎的作用主要就是存储数据和对外提供交互接口来提取、存储数据。
3. 查询性能优化的思路
梳理清楚一次查询的生命周期,会发现查询性能优化可以做的有两个地方:
1.客户端与服务端通信的过程
因为客户端与服务的通信协议是半双工,同一时刻要么发,要么收,不能同时收发,如果发送的数据包很长,效率就会比较差。所以这个过程的优化思路,让客户端与服务端之间的传递的数据包尽可能小一些。
客户端发送到服务端的比较复杂、体量比较大的查询sql可以切割的小一些,相对小一些的sql除了效率更高,命中缓存的概率也大。
客户端避免向服务端请求一些不需要的数据,即在sql里请求了这些数据,但是应用程序里丢掉了。比较典型的就是总是取出全部列、多表关联时返回全部列。检索了超过实际需要的数据行和列,会产生额外的负担、增加开销。
2.优化器生成查询计划的过程
使用explain对查询语句分析查询计划,查看sql匹配索引的情况、数据扫描的行数情况。索引的本质是让mysql以最高效、扫描行数最少的方式找到需要的记录,所以查询性能优化的关键还是在于尽可能的匹配上索引。网上很多文章中介绍的技巧,大部分都是基于此。
explain输出的信息列中的rows表示MySQL根据表统计信息及索引选用情况,估算找到所需的记录所需要扫描读取的行数,filtered表示按条件过滤后剩余的行数,即实际返回客户端的行数,占实际为得到结果扫描的数据行数的百分比。因此除了索引之外,尽可能扫描少的行数就能得到想要的结果,意味着更少的cpu操作、内存操作、IO操作。
4.总结
技巧是死的,方法是活的,在早期的msyql版本中,存在一些问题,对应有一些技巧能解决,但是随着版本的迭代,一些问题被解决、结构被优化,如果还在用所谓的技巧,有可能适得其反。实践是检验真理的唯一标准,如果查询性能有问题,那就先分析问题,找到原因,对症下药,切不可病急乱投医。
因此explain是一个好东西,建议仔细研究。再举个例子,下面sql是查询学生分数,当需要扫描的行数比较多的时候,即便score(分数)创建的有索引,mysql的执行计划会放弃索引,直接进行全表扫描。当需要扫描较少的行数的时候,索引才会起作用。所以,如果不分析问题,直接创建索引未必就能解决性能问题。