参考大佬的博客 https://www.lecloud.net/post/9246290032/scalability-for-dummies-part-3-cache
参考的github https://github.com/donnemartin/system-design-primer#step-2-review-the-scalability-article
scalability
1 Clone
每台服务器都包含完全相同的代码库,并且不会在本地磁盘或内存上存储任何与用户相关的数据,例如会话或个人资料图片。
会话需要存储在所有应用程序服务器都可以访问的集中式数据存储中。它可以是外部数据库或外部持久缓存,例如 Redis。
2 Database
MongoDB 或 CouchDB。现在需要在您的应用程序代码中完成连接。越早执行此步骤,将来需要更改的代码就越少。但是,即使您成功切换到最新最好的 NoSQL 数据库并让您的应用程序执行数据集连接,很快您的数据库请求将再次变得越来越慢。您将需要引入缓存。
3 Cache
对于“缓存”,我总是指内存中的缓存,例如Memcached或Redis。请永远不要做基于文件的缓存,会让服务器的克隆和自动缩放很痛苦。
缓存是一个简单的键值存储,它应该作为应用程序和数据存储之间的缓冲层。每当您的应用程序必须读取数据时,它首先应该尝试从缓存中检索数据。只有当它不在缓存中时,它才应该尝试从主数据源获取数据。你为什么要这样做?因为缓存快如闪电. 它将每个数据集保存在 RAM 中,并在技术上尽可能快地处理请求。例如,当 Redis 托管在标准服务器上时,每秒可以执行数十万次读取操作。写入,尤其是增量,也非常非常快。
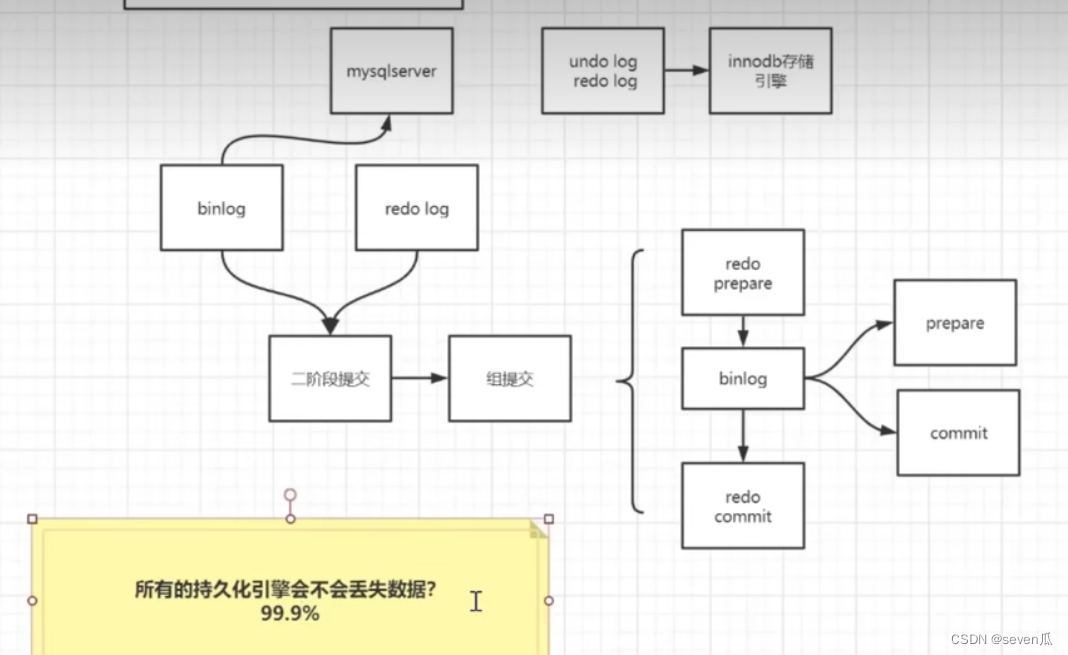
4 Asynchronism
异步 就是进程不要一个接一个完成 而是一起自己管自己进行。RabbitMQ ActiveMQ,简单的Redis 都可以完成。
用消息队列来避免 A反复去询问 b是否已经完成。
Tradeoff
一些常见的 tradeoff, 系统设计中其实就是在寻找一种平衡。
Performance vs scalability:
Performance is about the resources used to service a single request. Scalability is about how resource consumption grows when you have to service more (or larger) requests.
单次性能可接受的范围内 处理大量request
Latency vs throughput:
aim for maximal throughput with acceptable latency. 可接受的延迟产生最多的输出。
Availability vs consistency
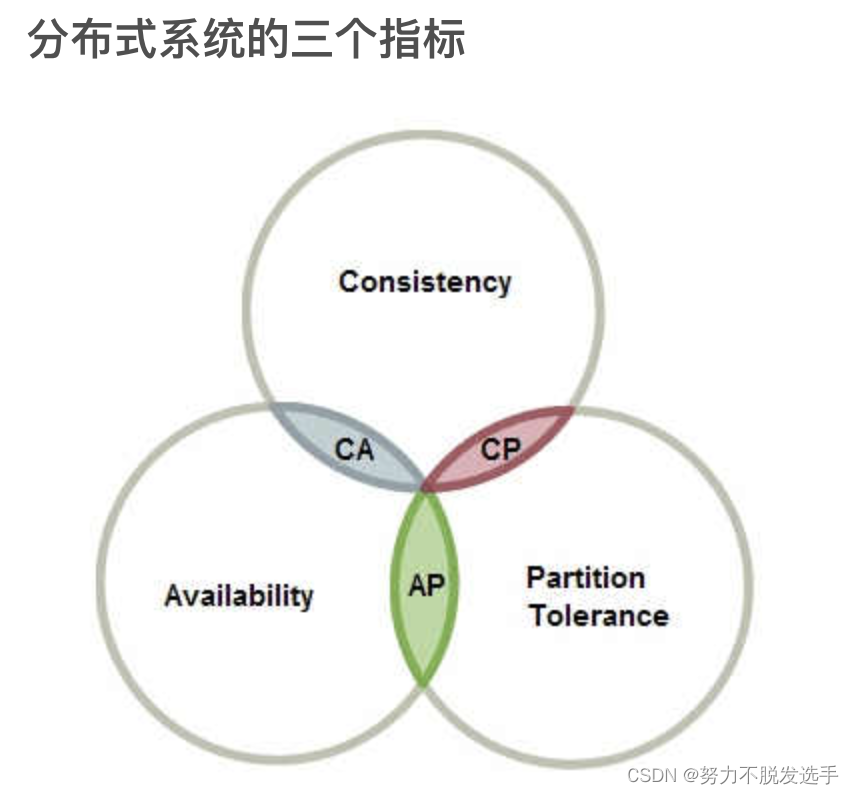
CAP定理:
- Consistency
- Availability
- Partition tolerance
这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
看下三个东西的定义:
Consistency - Every read receives the most recent write or an error 每次读都能读到最近的一次写结果
Availability - Every request receives a response, without guarantee that it contains the most recent version of the information 每次请求都能有相应,不用保证得到什么,但要“有求必应“
Partition Tolerance - The system continues to operate despite arbitrary partitioning due to network failures 当有通讯失败时 系统仍然可以运行
引用知乎高赞回答。
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
作者:知乎用户
链接:https://www.zhihu.com/question/54105974/answer/139037688
来源:知乎
以上内容 英文版一句话总结:Networks aren’t reliable, so you’ll need to support partition tolerance. You’ll need to make a software tradeoff between consistency and availability.
Failover 故障转移
即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作。 故障转移
failover (English: failover ) is the rapid activation of redundant or standby servers, systems, hardware, or networks to take over when active services or applications terminate unexpectedly.
两种切换方法
工作到备用切换(Active-passive)
关于工作到备用的故障切换流程是,工作服务器发送周期信号给待机中的备用服务器。如果周期信号中断,备用服务器切换成工作服务器的 IP 地址并恢复服务。
宕机时间取决于备用服务器处于“热”待机状态还是需要从“冷”待机状态进行启动。只有工作服务器处理流量。
工作到备用的故障切换也被称为主从切换。
双工作切换(Active-active)
在双工作切换中,双方都在管控流量,在它们之间分散负载。
如果是外网服务器,DNS 将需要对两方都了解。如果是内网服务器,应用程序逻辑将需要对两方都了解。
双工作切换也可以称为主主切换。
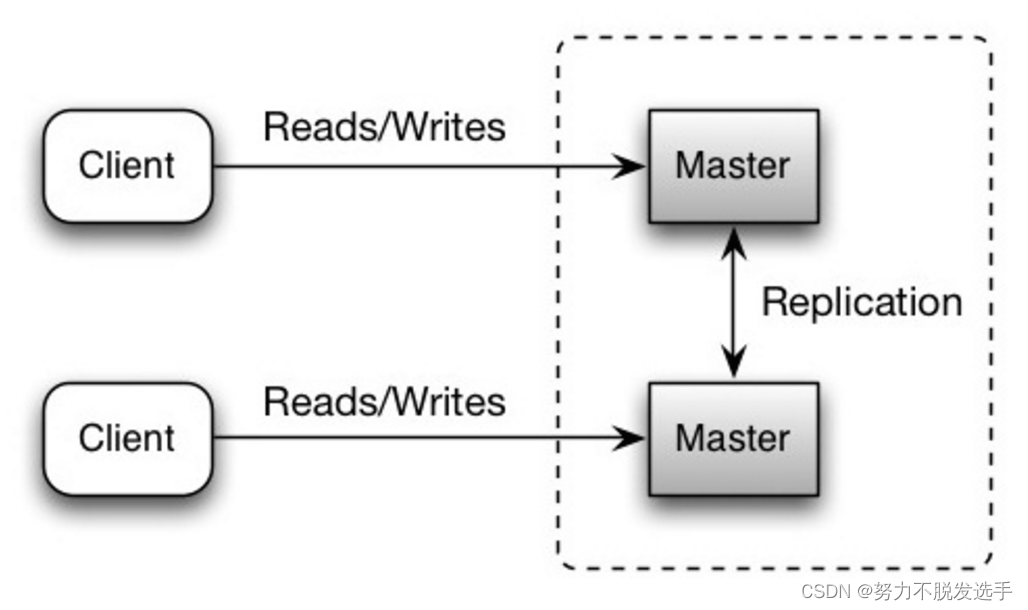
Replication 复制
主─从复制和主─主复制
master-slave
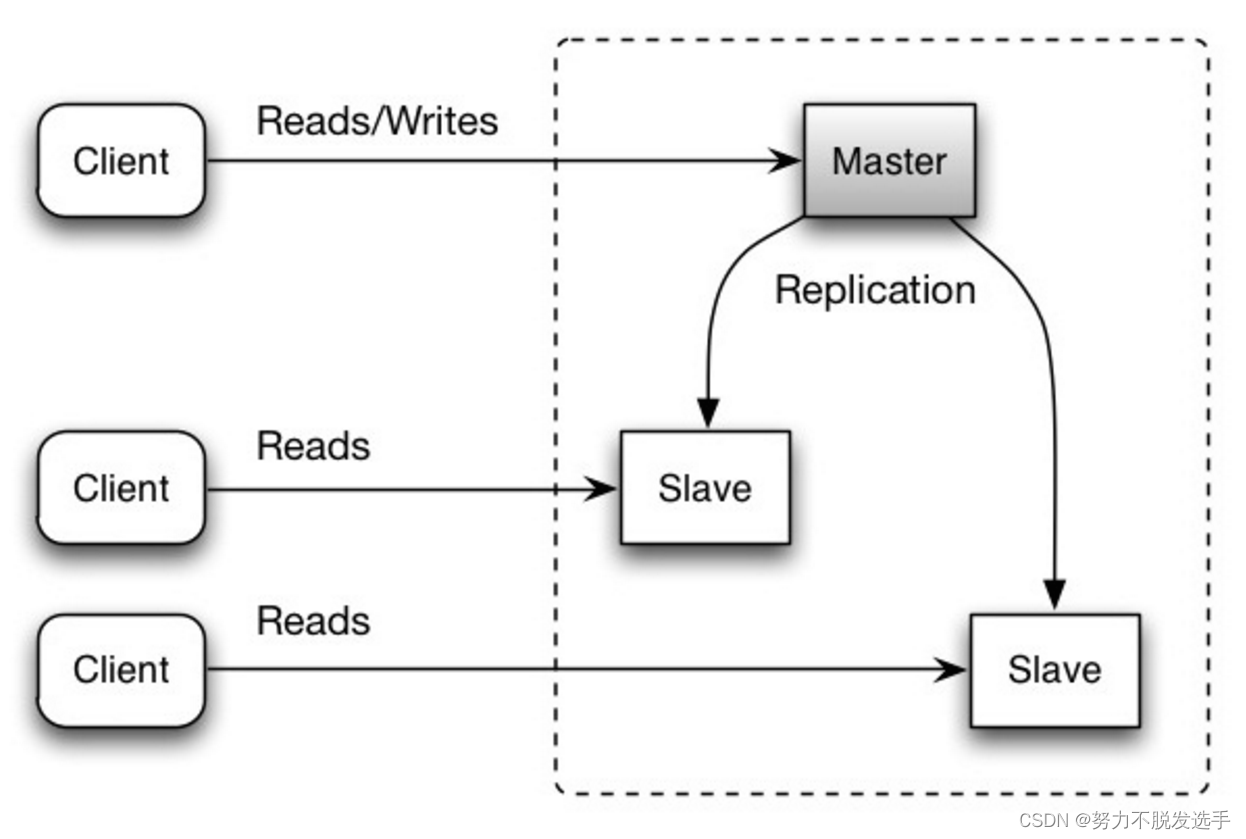
master-master
顺序, 并发(是否能同时开始) ;并行 ,串行 (是否同时执行)
-
顺序(sequential)
顺序:上一个开始执行的任务完成后,当前任务才能开始执行。 -
并发(concurrent)
并发:无论上一个开始执行的任务是否完成,当前任务都可以开始执行 -
串行(serial)
串行:有一个任务执行单元,从物理上就只能一个任务、一个任务地执行 -
并行(parallel)
并行:有多个任务执行单元,从物理上就可以多个任务一起执行
在任意时间点上,串行执行时必然只有一个任务在执行,而并行则不一定。
并发是一个核轮着做不同任务。并行是多核可以同时做不同任务。
DNS Domain name system
域名转换为 ip地址
CDN Content delivery network 内容分发网络
DN 的工作原理
CDN 涉及一组分布在一个区域内的服务器。它们可以是全局的或本地的,只要它们实际覆盖用户最有可能请求内容的区域。内容提供商会将内容上传到他们的服务器,然后它会自动将该数据传播到 CDN 网络上的其他节点。CDN 服务器通常通过快速的互联网骨干连接相互连接,因此在它们之间转移大量数据只需几秒钟。
CDN 也很智能且高效。假设您是您所在地区第一个从网站请求特定文件的人。如果该文件尚未复制到离您最近的 CDN 节点,它将从下一个具有数据的节点复制到那里。
然后,本地节点将保留该副本,以防其他本地用户也需要该文件。如果在设定的时间后没有人想要该文件,它可能会被删除,直到有人再次想要它为止。这样长距离带宽只用一次,然后就只用本地带宽了。这既更快又便宜,因此主机和用户都得到了很好的交易。
Load Balance
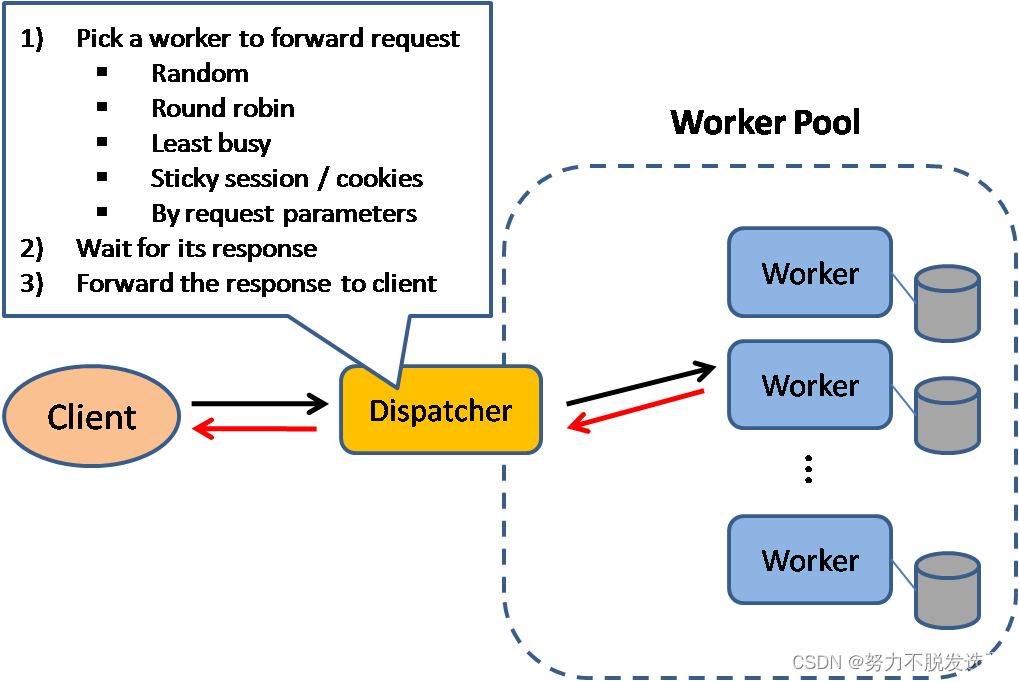
会话保持是负载均衡最常见的问题之一,也是一个相对比较复杂的问题。
会话保持有时候又叫做粘滞会话(Sticky Sessions)。
在介绍会话保持技术之前,我们必须先花点时间弄清楚一些概念:什么是连接(Connection)、什么是会话(Session),以及这二者之间的区别。需要特别强调的是,如果我们仅仅是谈论负载均衡,会话和连接往往具有相同的含义。
从简单的角度来看,
如果用户需要登录,那么就可以简单的理解为会话;
如果不需要登录,那么就是连接。
实际上,会话保持机制与负载均衡的基本功能是完全矛盾的。负载均衡希望将来自客户端的连接、请求均衡的转发至后端的多台服务器,以避免单台服务器负载过高;而会话保持机制却要求将某些请求转发至同一台服务器进行处理。因此,在实际的部署环境中,我们要根据应用环境的特点,选择适当的会话保持机制。
简单会话保持也被称为基于源地址的会话保持,也叫基于IP的会话保持,是指负载均衡器在作负载均衡时是根据访问请求的源地址作为判断关连会话的依据。对来自同一IP地址的所有访问请求在作负载均时都会被保持到一台服务器上去。在BIGIP设备上可以为“同一IP地址"通过网络掩码进行区分,比如可以通过对IP地址 192.168.1.1进行255.255.255.0的网络掩码,这样只要是来自于192.168.1.0/24这个网段的流量BIGIP都可以认为他们是来自于同一个用户,这样就将把来自于192.168.1.0/24网段的流量会话保持到特定的一台服务器上。
简单会话保持里另外一个很重要的参数就是连接超时值,BIGIP会为每一个进行会话保持的会话设定一个时间值,当一个会话上一次完成到这个会话下次再来之前的间隔如果小于这个超时值,BIGIP将会将新的连接进行会话保持,但如果这个间隔大于该超时值,BIGIP将会将新来的连接认为是新的会话然后进行负载平衡。
lb的缺点:
The load balancer can become a performance bottleneck if it does not have enough resources or if it is not configured properly.
Introducing a load balancer to help eliminate a single point of failure results in increased complexity.
A single load balancer is a single point of failure, configuring multiple load balancers further increases complexity.
如果负载均衡器没有足够的资源或配置不当,它可能会成为性能瓶颈。
引入负载平衡器来帮助消除单点故障会增加复杂性。
单个负载均衡器是单点故障,配置多个负载均衡器进一步增加了复杂性。
有几种方法来选worker:
Load balancers can route traffic based on various metrics, including:
Random
Least loaded
Session/cookies
Round robin or weighted round robin
Layer 4
Layer 7
可以实现LB的东东:
K8s,NGINX,HAProxy 。。。
kubernetes实现 LB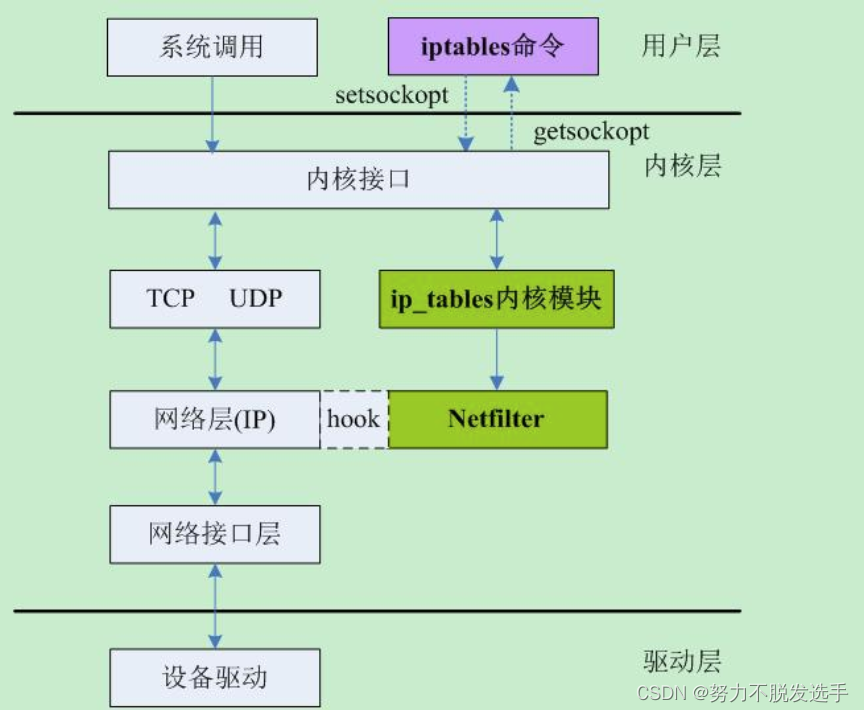
用iptables 和 net filter
Reverse proxy (web server)反向代理
转发代理和反向代理区别
转发代理位于客户端的前面,确保没有源站直接与该特定客户端通信;而反向代理服务器位于源站前面,确保没有客户端直接与该源站通信。
反向代理的实现
1)需要有一个负载均衡设备来分发用户请求,将用户请求分发到空闲的服务器上
2)服务器返回自己的服务到负载均衡设备
3)负载均衡将服务器的服务返回用户
so 反向代理需要load balance来实现
DataBase
划分成关系型和非关系型来讲 参考知乎
https://zhuanlan.zhihu.com/p/510225527
关系型数据库与ACID特性
在NoSQL流行之前的世界是属于关系型数据库的(此前还有网状数据库,但不像关系型数据库广泛应用)。
关系型数据库有扎实的理论基础、有严格的数据模式,支持事务,遵循严格的ACID特性,广泛应用在各种商业环境中,包括金融、电信等一些对数据一致性要求非常严苛的场景中。所谓ACID是指:
A
(Atomicity,原子性)
事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
C
(Consistency,一致性)
数据库要始终处于一致的状态,事务的运行不会改变数据库原本的一致性约束。通俗的理解就是参与各方达成共识,不会扯皮。
I
(Isolation,独立性)
指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
D
(Durability,持久性)
指一旦事务提交后,它所做的修改将会永久保存在数据库上,即使出现宕机也不会丢失。
ACID对数据库的要求是非常严格的,为了满足ACID有时不得不牺牲数据的可用性和系统性能,而现实生活中有些场合对数据的要求并不严格,特别是当数据量大到一定规模后,不得不采用分布式数据库时。
如果要遵循ACID越来越困难,成本越来越高,另外,还有些数据类型采用传统数据库效率非常低(比如图数据库),这就有了NoSQL数据库。
NoSQL 和BASE
NoSQL这个词最早出现在2009年,是Not Only SQL的缩写,表示不同于关系型数据库,主要指非关系型、分布式、不提供ACID的一类数据库。
本质上,NoSQL是牺牲了数据的一致性而换取了可用性和性能。近几年,各个NoSQL在尽力补上事务支持上的不足。比如,MongoDB、Aerospike都提供对事务的一定程度上支持
NoSQL数据库其实是很难严格符合CAP的,而更多的是采用BASE设计理念。BASE是eBay架构师Dan Pritchett提出,核心思想是如果无法做到强一致性,可以采用适合的方式达到最终一致性。
BA (Basically Available,基本可用)
在出现故障的时候,允许损失部分可用性,即保证核心可用。
S (Soft State,软状态)
允许系统存在中间状态,也就是系统不同节点的副本存在数据更新延时。
E (Eventual Consistency,最终一致性)
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
BASE是很多分布式系统的设计理念,其通过牺牲强一致性获得高可用性。与ACID正好相反,ACID是传统数据库常用的设计理念,追求强一致性模型。这两种设计理念没有好坏之分,毕竟适合的才是最好的。
几种主流的NoSQL数据库
NoSQL是随着互联网应用的爆发、为应对海量数据和复杂数据类型而出现和流行的,比如机器日志、网页浏览和点击数据、物联网时序数据等,数据规模很容易达到TB乃至PB级。传统数据库的性能不管是从成本上还是性能上都很难承受这些。
和传统数据库主要面向结构化数据、满足ACID特性、支持SQL语言不同,NoSQL数据库主要面向非结构化和半结构化数据,不支持或者只能部分支持SQL语言,满足最终一致性。另一方面,传统数据库具有严格的数据范式,如果修改成本非常高,而NoSQL一般没有严格的数据范式,可以根据需要灵活改变。
目前主流的NoSQL数据库主要有以下四类:
键值(Key-Value)存储数据库:这类数据库主要采用一个键和对应的值来存储数据。Key/value模型对于IT系统来说的优势在于简单、易部署。Redis、Aerospike、Memcached都属于这一类型。这类数据库经过优化通常查询性能很高,被广泛用在缓存系统。
宽列数据库:这类数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列,这些列分属于不同的列族。如Cassandra、HBase等。
文档型数据库:文档型数据库的数据模型是半结构化的文档,它以特定的格式存储,比如JSON。如MongoDB、CouchDB等。
图数据库:图数据库采用灵活的图形模型来表达各个实体之间的关系,比如组织、人员关系等,查询非常高效。图数据库代表有Neo4J、InfoGrid等。
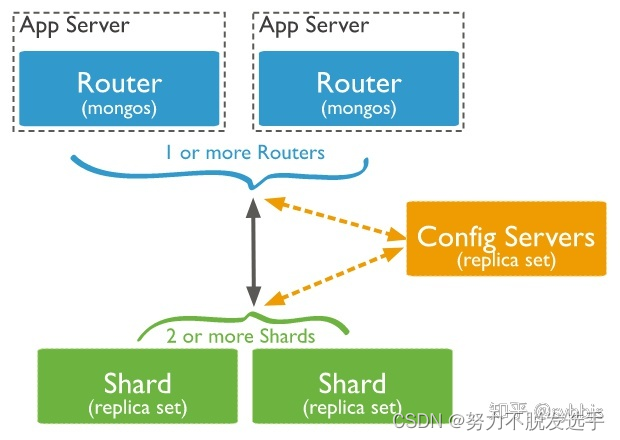
分片
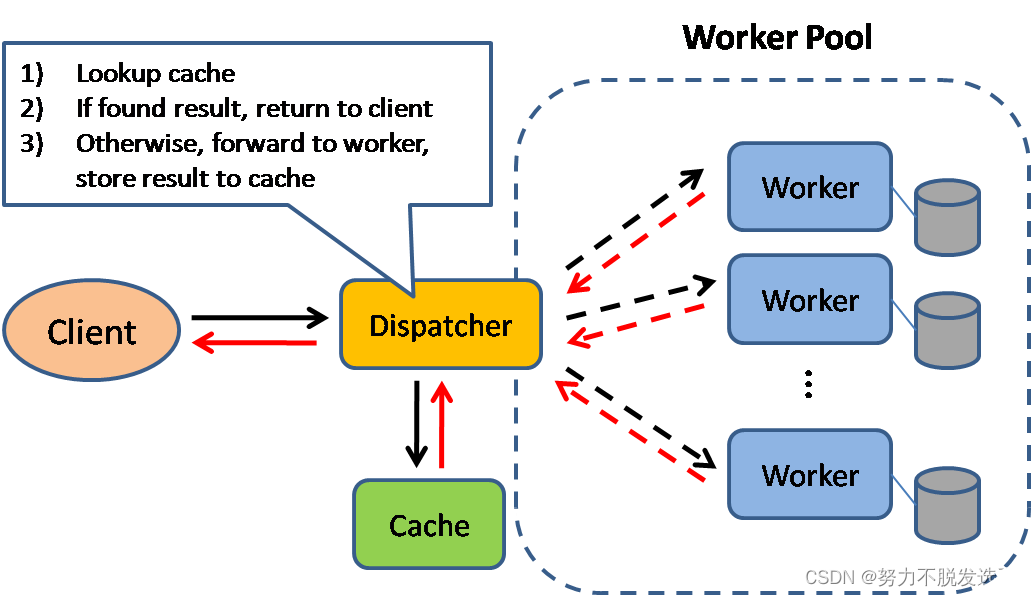
缓存
性能相关的指标
响应时间
响应时间 RT(Response-time)就是用户发出请求到用户收到系统处理结果所需要的时间。
RT 是一个非常重要且直观的指标,RT 数值大小直接反应了系统处理用户请求速度的快慢。
并发数
并发数可以简单理解为系统能够同时供多少人访问使用也就是说系统同时能处理的请求数量。
并发数反应了系统的负载能力。
QPS 和 TPS
QPS(Query Per Second) :服务器每秒可以执行的查询次数;
TPS(Transaction Per Second) :服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
书中是这样描述 QPS 和 TPS 的区别的。
QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
常见软件的 QPS
这里给出的 QPS 仅供参考,实际项目需要进行压测来计算。
Nginx :一般情况下,系统的性能瓶颈基本不会是 Nginx。单机 Nginx 可以达到 30w +。
Redis: Redis 官方的性能测试报告:https://redis.io/topics/benchmarks 。从报告中,我们可以得出 Redis 的单机 QPS 可以达到 8w+(CPU 性能有关系,也和执行的命令也有关系比如执行 SET 命令甚至可以达到 10w+QPS)。
MySQL: MySQL 单机的 QPS 为 大概在 4k 左右。
Tomcat :单机 Tomcat 的 QPS 在 2w 左右。这个和你的 Tomcat 配置有很大关系,举个例子 Tomcat 支持的连接器有 NIO、NIO.2 和 APR。 AprEndpoint 是通过 JNI 调用 APR 本地库而实现非阻塞 I/O 的,性能更好,Tomcat 配置 APR 为 连接器的话,QPS 可以达到 3w 左右。更多相关内容可以自行搜索 Tomcat 性能优化。
主要还是通过很多案例 来准备系统设计,来不及了。再过1个半小时就面试了,感觉药丸。





![[附源码]java毕业设计小区物业管理系统](https://img-blog.csdnimg.cn/4247ba9450414baba1b9d854f083a657.png)