目录
- 前言
- 1. Better(更准)
- 2. Faster(更快)
- 3. Stronger(更壮)
前言
对应YOLOv1论文解读:You Only Look Once: Unified, Real-Time Object Detection(Yolov1) 论文详细解读
其他的论文可在该栏目搜索:论文解读栏目 (实时更新阅读)
YOLOv1检测速度快,但是精度没有R-CNN高,但它是一阶段的初始代表。
YOLOv2将其YOLOv1的精确度以及召回率提高,来提高mAP
通过题目也可看出,Yolov2的三个性能:更准确、更快、类别更多(用于检测9000种类别)
以下章节也是随着标题进行解析
1. Better(更准)
在Yolov1的基础上使用了一些改进,改进后的Yolov2在PASCAL VOC 以及 COCO上达到了很好的性能。
Yolov2:
- 多尺度训练(任意尺度大小):高分率图片,性能降低;低分率图片,性能提高。总的来说是速度和精度的权衡(总体超过了 Faster R-CNN、ResNet 以及SSD)
- 联合训练方法(联合训练了目标检测数据集和图像分类检测训练集):YOLO9000可以训练出图像中没有标签的类别。训练的数据集在COCO以及ImageNet 分类,测试的数据集在ImageNet 检测。
对应Yolov1的缺点是:
- 大多数的检测方法仍然受制于小部分的物体 (划分成7 * 7的小格子,而且每个格子只能检测一个物体)
- 定位性能差(Yolov1画框比较差)
- 召回率差(将所有目标检测出来的比较弱,这是因为7 * 7的小格子,每个小格子有两个Boxes,总共有98个,也是比较差)
本身Yolo的优点就是 :端到端,速度快,并且把目标检测问题转换为回归问题
优化思路:
网络越深,性能更好。更好更深的网络一般集成不同的网络
类似这篇文章技巧:Deep Residual Learning for Image Recognition (ResNet)论文详细解读
但Yolov2要想网络的准确度和性能都变好,并不能简单地加大深度(网络深度让其参数量计算量都变多了,速度变慢了),所以此处不能加大网络,因为本身就要快,需要简化网络
解决方法:
提出一种新的方法来利用我们已有大量的分类数据,将其拓展现有的检测系统范围。该方法使用一种物体分类的分层观点,将其不同数据集结合在一起。提出一种联合训练的算法,允许在检测和分类的两个方面训练物体探测器,大致通过标记的检测图像来精确定位物体,同时使用分类图像来增加稳健性。(为监测类别贴上标签不太可能)
更好的性能往往取决于训练更大的网络或将其多个模型集合在一起。但yolov2本身简化了网络,使其成为更加精确的检测器。
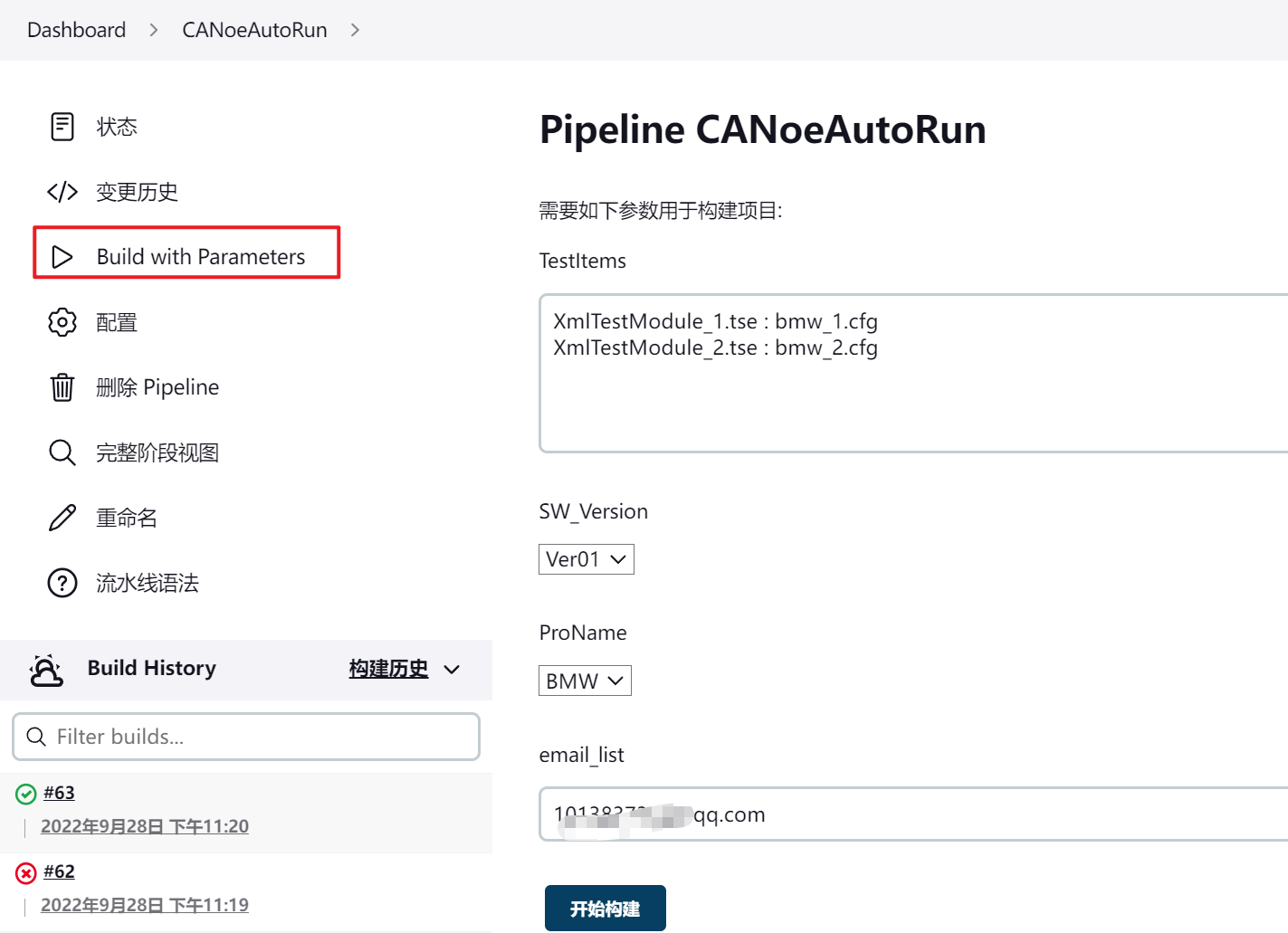
具体的优化实验可看如下图:
补充知识点:
- recall (召回率):真是目标中被检测出的比例
- 精确度:表示该框中的物体预测正确
具体优化参数以及功能如下表所示(表格中的图片可放大查看):
| 优化参数 | 中文解释 | 具体阐述 | 优点 |
|---|---|---|---|
| Batch Normalization | BN (批量标准化) | 1. BN层主要应用在神经网络卷积之后,激活函数之前 2. 比如Batch为32,此处是对每一个神经元会进行标准化,分别输出32个神经元。求均值和标准差,把每一个响应减去均值除以标准差(标准化即 均值为0,标准差为1的分布)。标准化之后,乘以γ加上β 3. 之所以加了BN层之后不用dropout层,是因为两者一起使用效果不好。偏置项也可不用(强行已经减去均值,均值已经为0) BN的训练过程: 训练阶段:响应都会缩到0附近,之后经过sigmod或者softmax,都会被拉到非饱和区,避免梯度消失,起到正则化的效果 测试阶段:γ和β都用训练阶段中全局求出的参数(测试阶段只是线性变化) | 1. 提高收敛性,消除其他形式的正则化。(在所有的卷积层中添加批量归一化,有2%的mAP提高) 2. 本身可以防止过拟合。通过BN还可不用dropout层 |
| High Resolution Classifier | 高分辨分类器 | 背景: 目前所有分类器都在ImageNet预训练出来的,比如AlexNet(227 *227),几乎所有分类器都是小于256 * 256 ,原来的Yolov1是在224 *224 分辨率训练,之后在448的图像上训练(来回切换复杂度高) 改进: Yolov2在448 * 448的分辨率训练以10个epoch,在高分辨率图片中训练,之后在fine tune中目标检测,提升了4%的mAP | 可以使用高分辨率的输入 |
| Convolutional With Anchor Boxes | 带Anchor Boxes的全卷积(增大回归) | 背景: Yolov1的Bounding Boxes是从全连接层的张量中得到的(Yolov1的bounding Boxes没有标注长宽高,会有野蛮生长)。而Faster R-CNN手动选取先验框,模型输出的是相对于anchor Boxes的偏移量(提前预测矮胖、高瘦框)以及置信度,在卷积核中使用滑窗(比如13 * 13 输出9个) 改进: 1. 将其Yolov1最后一层全连接层去除,使用Anchor Boxes预测(Yolov1使用全连接层对边界框进行预测会丢失信息定位不准确) 2.去掉池化层让其输出有更好的分辨率 3.网络架构从418 * 418 变为416 * 416 (特征图为一个中心格子,容易检测物体) 4.下采用是32,输入416 * 416的图像,输出是13 * 13 * 5 * 25 (5个anchor个数。每个anchor都输出xywh以及置信度总共5个 外加20个类别,所以为25) | 背景所述的优点: 输出偏移量而不是输出坐标本身可以让网络更好的学习 改进的优点: 1. 采用Anchor Boxes可以将其分类和空间定位进行解耦,每个Anchor Boxes可以预测类别和置信度 2.总体召回率上升,但是精确度有所下降(因为原本Yolov1位 7 * 7 * 2 ,现在有了 13 * 13 * 5,图片多了精度有所下降。但是可以通过其他方法来提升精确度) |
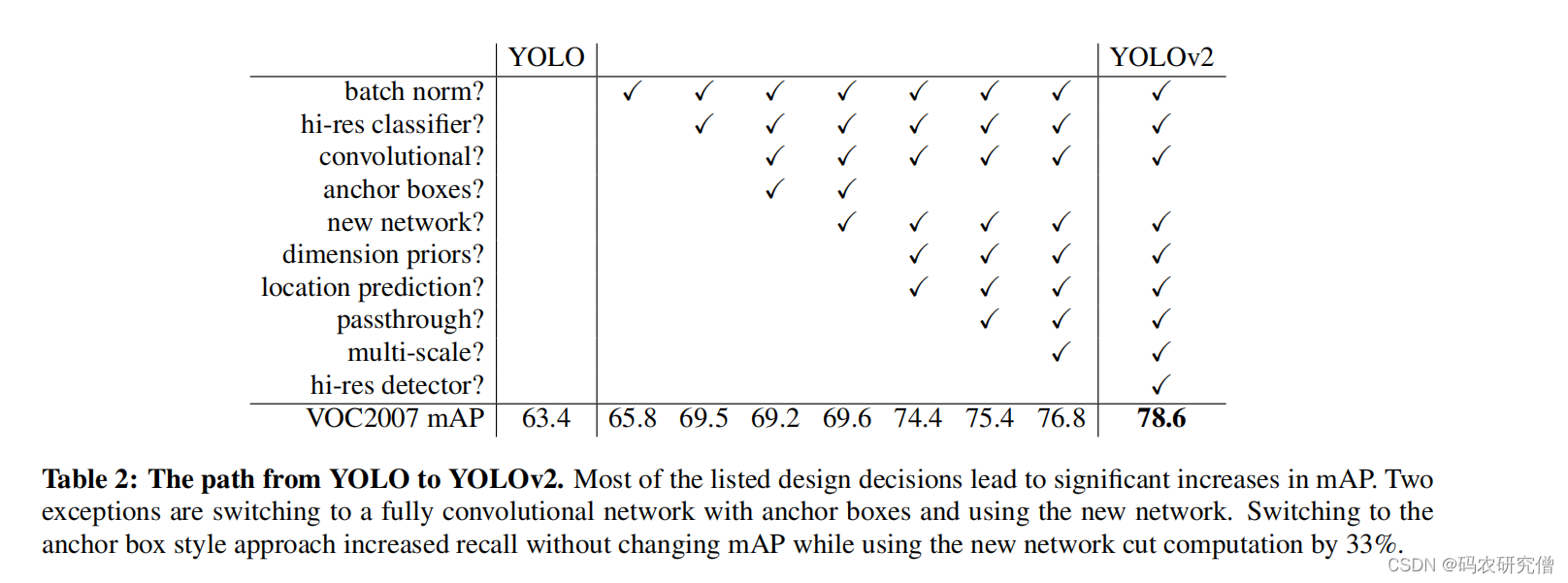
| Dimension Clusters | 标注框聚类 | 背景: Faster R-CNN 的先验框都是指定的比如长宽矮胖等(但比例可能不对) 改进:对训练集使用k - means来实现聚类(让聚类告诉长宽比是多少) k-means 补充: 此处使用的k - means为欧式距离,大框产生更大距离,小框产生更小距离。所以此处使用IOU(和Boxes的尺寸无关)。 计算数据集中的其它框以及聚类中心框的IOU,用1 减去上面的结果作为距离度量指标(聚类中心特别好,与box完全一样,距离度量指标结果为0),如图所示: 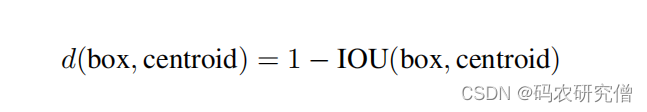 对应的k参数选择,通过如下实验(蓝框为COCO,黑框为VOC),本身anchor和位置无关,只和长宽比有关: 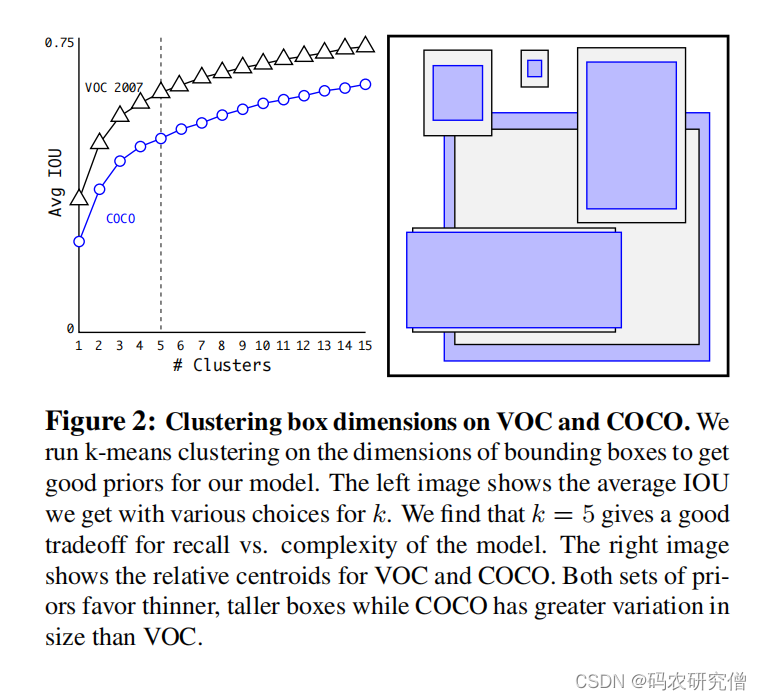 一个格子生成过多框会非常庞大,最终选择 k = 5 这个参数 补充实验结果 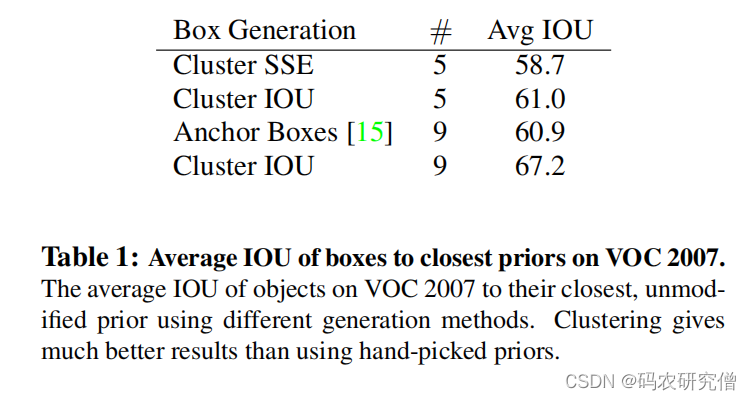 得出聚类分析的先验框比手动选择的先验框 平均IOU要高 | 聚类的框有更少的矮胖框,有更多的高瘦框。而且有很高的IOU |
| Direct location prediction | 绝对位置预测 | 背景: 模型的不稳定,导致先验框的野蛮生长,主要来源x与y。 具体公式如下: 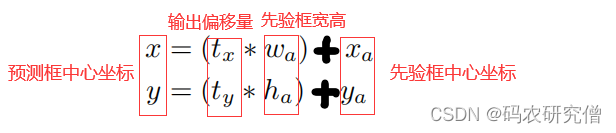 因为tx和ty这两个偏移量没有任何约束,中心坐标有约束,所以长宽会野蛮生长。边界框可以出现在任何位置。因为模型权重是初始化的,需要很长时间学习才可学习到稳定的偏移量 改进:不是预测绝对坐标,而是预测相对grid cell的坐标。使用逻辑回归,将数字限制在0和1之间。每个grid cell预测5个值(bw 和 bh 有e的指数,限制为正数)。 具体公式如下: 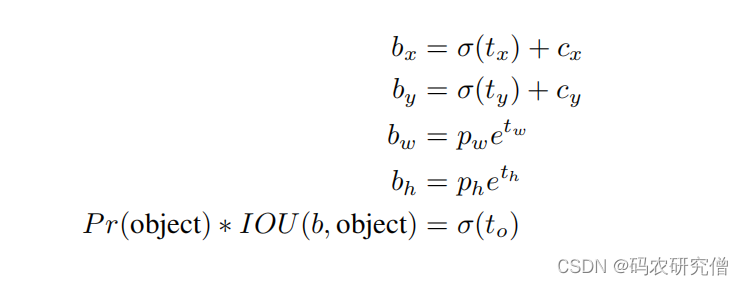 完整的图可看如下: 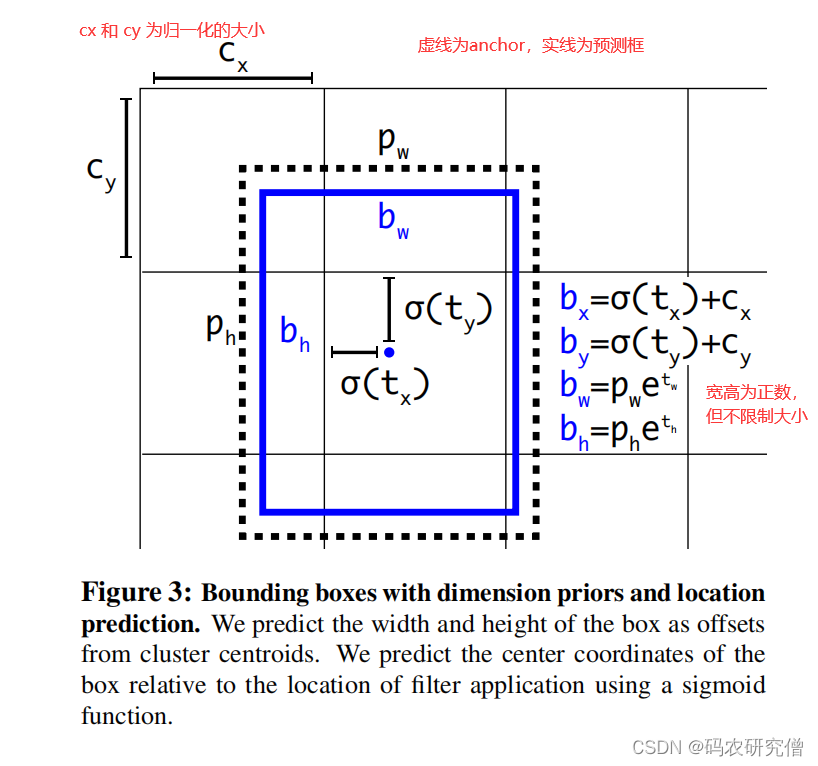 | 抑制先验框中偏移量的野蛮生长 |
| Fine-Grained Features | 细粒度特征 | 背景: 主要借鉴了Faster R-CNN 以及 SSD 将其 proposal 网络 都运行在各类的卷积核中。模型最后输出13 * 13的卷积核,可以检测小物体以及密集物体。 具体改进方法: 通过passthrough层将其高分辨率与低分辨率融合在一起(通过26 * 26 的浅层网络 和 模型的最后一层进行拼接) 详细步骤: 理论:最后一层池化层输入为26 * 26 * 512(将其下面步骤一和步骤二进行拼接) 一、26 * 26 * 512将其拆分为4块(类似Yolov5的 focus结构)变为 4 * 13 * 13 * 256(尺寸缩减为4倍,通道数变为原来的4倍) ,拼接起来为13 * 13 * 2048。 二、26 * 26 * 512 在经过池化和卷积变为 13 * 13 * 1024 三、将其步骤一和步骤二的输出进行拼接,变为13 * 13 * 3072(通过512 + 512 + 512 + 512 + 1024拼接) 代码:代码层面的处理没有理论这样,而是通过26 * 26 * 512 经过1 * 1 * 64的卷积(降维)得到26 * 26 * 64 ,在经过passthrough拆分变为 13 * 13 * 256,在与原先的13 * 13 * 1024 进行拼接 | 浅层特征加在深层的特征可以提高1%的mAP |
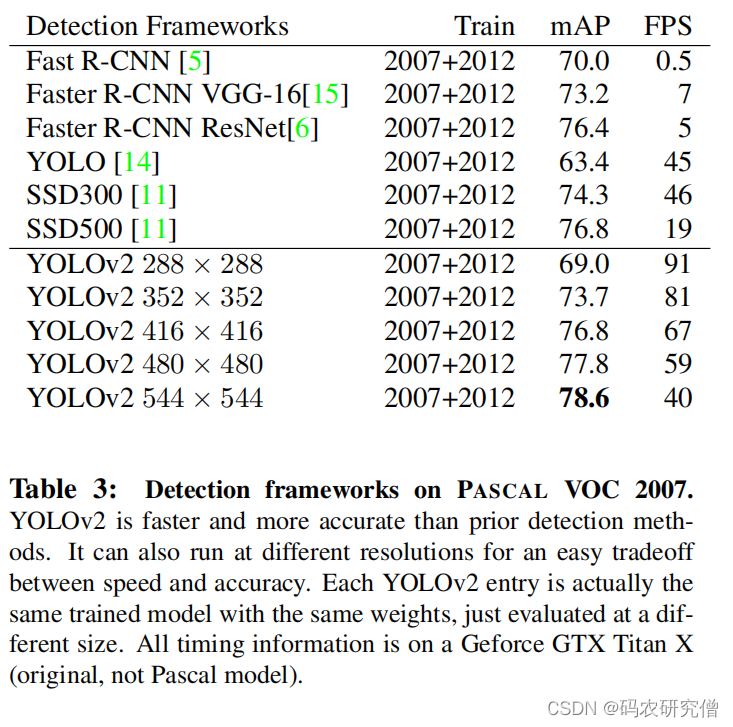
| Multi-Scale Training | 多尺度训练 | 网络结构只有卷积层和池化层(本身是Darknet-19) 为了鲁棒在不同尺度上运行,使用多尺度训练(不固定输入尺寸,每10个batches就随机输入不同尺寸大小的图片)。由于使用的下采用步长为32,输入的尺寸为32的倍数{320,352,…,608} 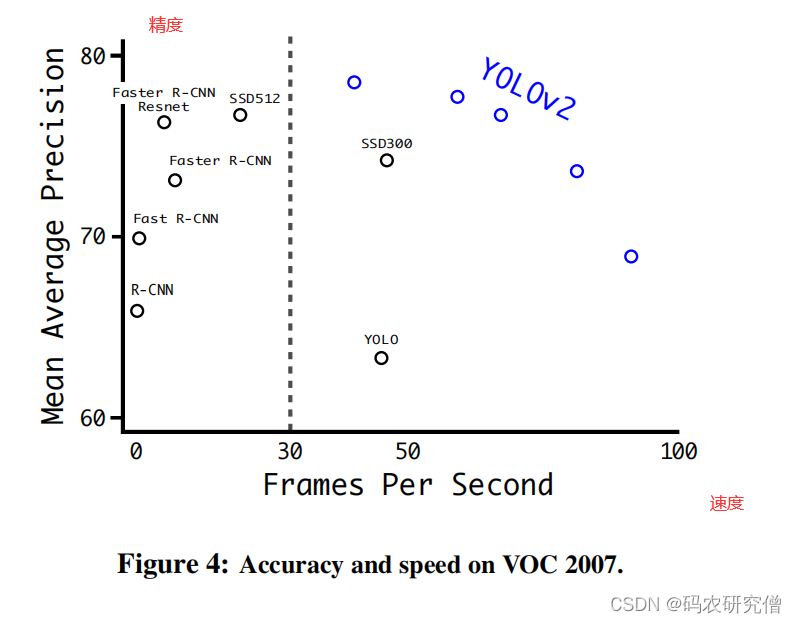 例子:如果输入的图像为320 * 320,下采用为32,输出的图像为10 * 10 | 同样网络不同尺度图片,输出的速度和精度可以达到权衡 |
除了以上的技巧以及实验,还有其他的更进一步研究:
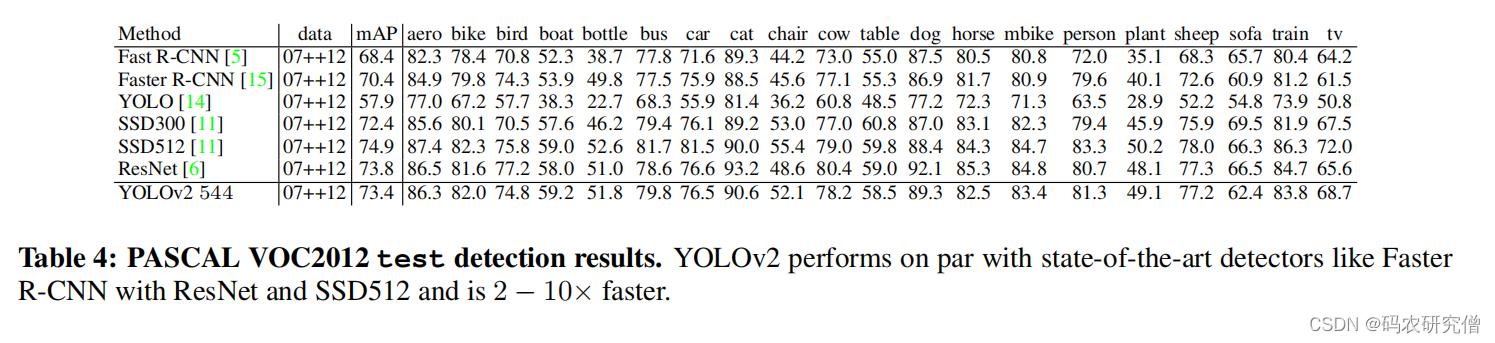
PASCAL VOC2012 数据集 目标测试的结果:
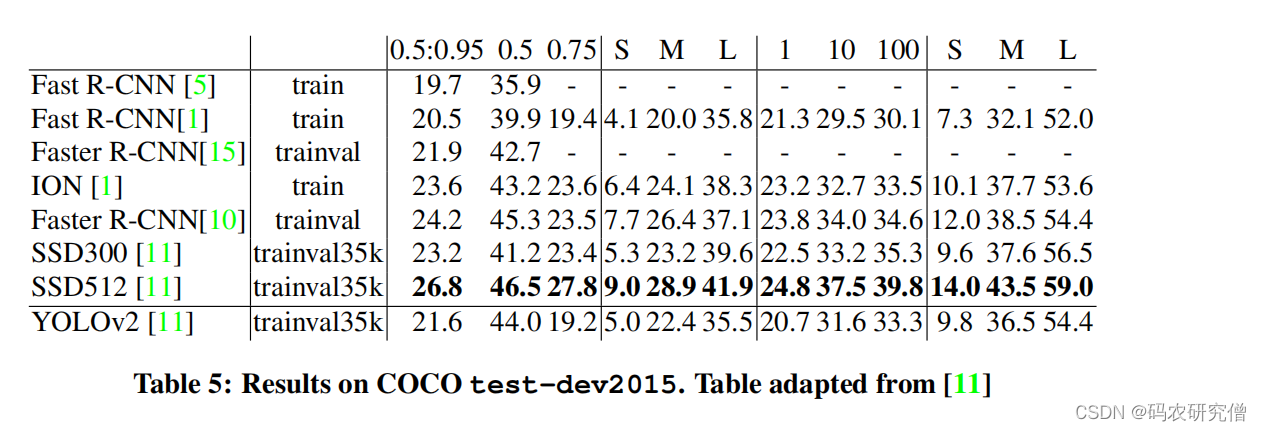
Results on COCO 数据集 目标测试的结果:
不同尺度和精度的权衡:(用的同一个网络模型,只不过不同输入尺度,之所以可以这样,取决于全局平均池化)
2. Faster(更快)
类似自动驾驶,之所以实时主要依赖低延迟
VGG-16一般作为特征提取器,但VGG-16有很大的权重,有2个全连接层(计算量很大)
Yolov1基于Googlenet网络使用了一个自定义的网络,该网络比VGG-16快,但精度比VGG-16低。
Yolov2使用了Darknet-19的网络架构
完整架构图如下所示: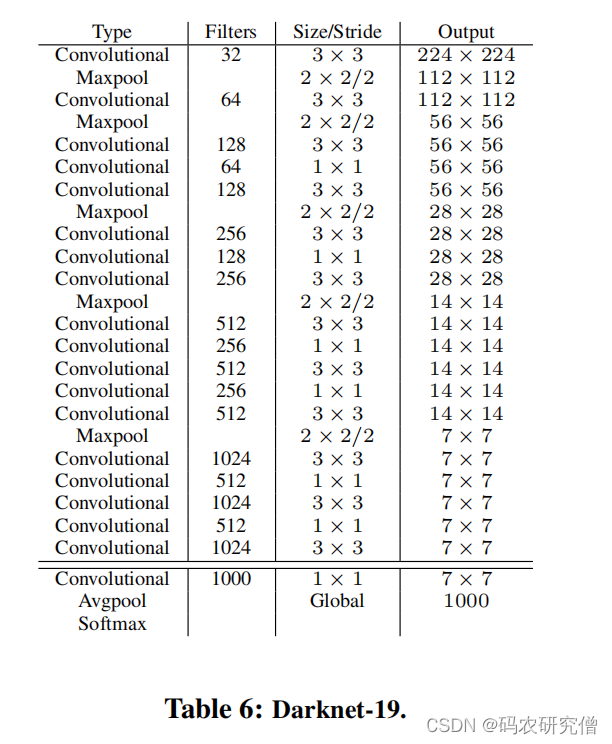
整体架构使用了19个卷积层以及5个池化层。内部主要采用3 * 3的卷积以及1 * 1的卷积(1 * 1 的卷积可用于降维处理计算,也可用于升维还原结果)
每层的卷积后使用BN层收敛模型以及防止过拟合。最后使用了全局平局池化预测(各自求平均)
主要作用:减少计算量,但mAP未显著提高,兼容不同尺度的大小
| 训练阶段 | 训练过程 |
|---|---|
| 分类网络 | 初始的时候都是224 * 224,在ImageNet 1000数据集中用Darknet-19训练,训练160轮(使用了4次随机梯度下降,初始值为0.1,也就是从大到小,使用了线性衰减。使用了L2正则化初始0.0005,动量0.9),使用了标准增强,色调饱和度明度等。 之后在高分辨率下进行fine tune,在448 *448 的大分辨率下训练10轮,得到top-1准确度为76.5%,而top-5准确度为93.3% |
| 目标检测网络 | 将其最后一个卷积层、全局平均池化层以及softmax层去除,换成3 * 3 * 2014的卷积层,最后跟着1 * 1的卷积层(和最后得到的维度是一样的,也就是13 * 13 * 5 * 25),每个格子要预测125个值。 同时增加了passthrough层(浅层特征融合深层特征) 总体训练了160轮,学习率为10-3,分别在第10、60、90的时候除以10,正则化0.0005,动量0.9,类似的数据增强方法(随机裁剪,颜色变化) |
3. Stronger(更壮)
检测的类别更多,但该论文效果不佳(不过也可学习,但目前很少使用该方法,都是用比较多的标签进行训练)
联合训练分类和目标检测的数据,我们的方法使用了目标检测的标签检测目标检测相关信息
回归Bounding boxes的目标、置信度、以及预测框的物体
图像标签的物体扩展类别
训练阶段,目标检测和分类的数据集混合一起(既能学习目标检测,又能发挥海量图像的优势)
- 带目边监测的标签即反向传播整个Yolov2的损失函数
- 带图像标签的图像,只传播分类相关的损失函数
目标检测的标签只有常见的,但分类的图像更加细致(需要把标签弄为一致)?
答案:如果使用softmax,可以联合训练的时候标签是一致的,但标签必须要互斥。所以需要使用多类别标签(一张图片可对应多个类别,类别不在互斥)
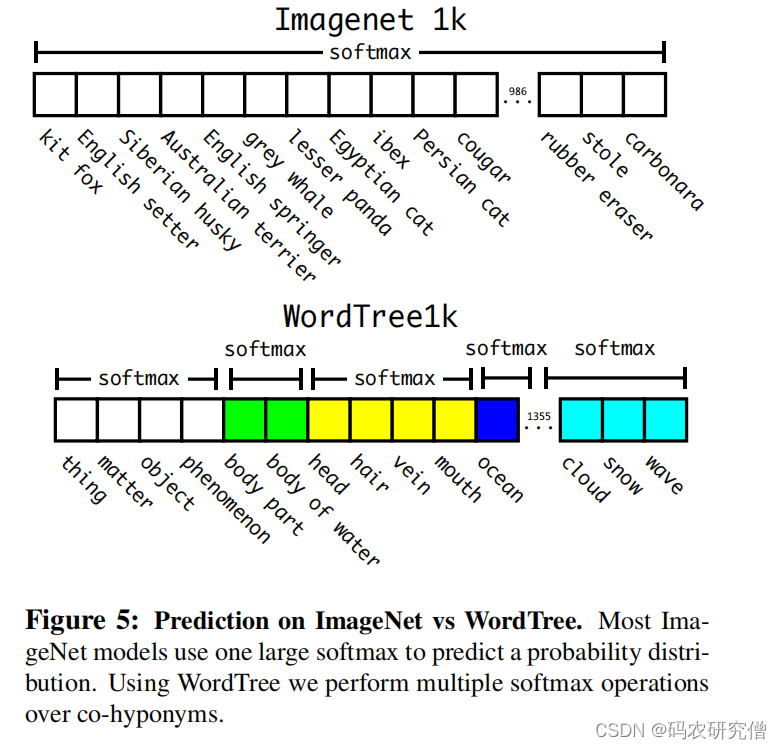
分层分类字典,需要结构化树形结构。
结合WorkNet,来一个标签就放入树中,即使有多条通向根标签的路径,选取最短的路径(符合奥卡姆剃刀原理)
最后变成了WordTree,预测每个节点的父节点概率,类似如下图:

计算节点的联合概率,只需一直相乘:

此处的Pr(physical object) = 1
在目标检测中 用置信度 来代表 Pr(physical object) ,预测出该节点在树中的可能。将其树进行上下倒转,从最高的概率开始分叉,直到达到阈值,将其最后作为物体的类别
原本是互斥,最后变为分层结构(每个类别都进行softmax,此处的类别有限,计算量不高):
不同数据集整合在一起,COCO图像分类和ImageNet融合在一起:
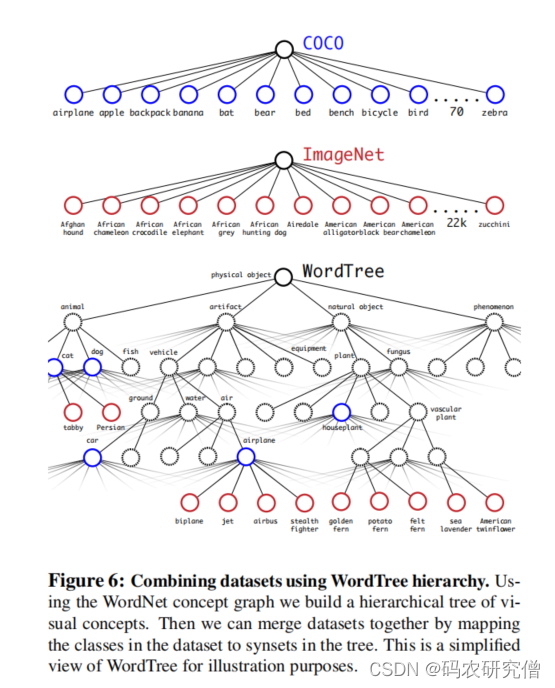
将两种数据集合在一起之后,之后到ImageNet的数据集进行目标检测(半监督学习或者弱监督学习),将其原本Yolov2的5个Anchor改为3个(限制输出大小)