随机森林
- 1. 随机森林介绍
- 1.1 租赁数据案例
- 2. 特征相关性分析(热图)
- 2.1 热图绘制
- 2.2 构建随机森林模型
- 2.3 不同特征合并的重要性
- 2.3.1 经纬度合并(分3类)
- 2.3.2 经纬度合并(分2类)
- 2.3.3 经纬度合并(分4类)
- 2.3.4 经纬度合并(分4类)
- 2.3.5 oob重要性
- 3. 总结
1. 随机森林介绍
在随机森林中创建决策树时,通过测量特征在减少不确定性(分类器)或方差(回归器)方面的有效性来计算特征的平均-减少-不纯重要性。问题是这种机制虽然快速,但并不总是能准确反映出重要性。Strobl等指出:“the variable importance measures of Breiman’s original random forest method … are not reliable in situations where potential predictor variables vary in their scale of measurement or their number of categories.”
互换重要性是一个更好的方法,它衡量一个特征的重要性为:将验证集或袋外(OOB)样本导入随机森林,并记录基线准确性(分类器)或 R2 得分(调节器)。对单一预测特征的列值进行修正,然后将所有测试样本重新通过随机森林,重新计算准确率或者 R2 。该特征的重要性是基线和因排列组合而造成的总体准确率或R2下降之间的差异。虽然替换机制的计算成本比杂质机制的平均下降的成本高得多,但结果更可靠。
1.1 租赁数据案例
需要安装的库: rfpimp(Random Forest Feature Importances Package)
pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com rfpimp
数据来源:Two Sigma Connect: Rental Listing Inquiries
rent.csv(租赁数据集)

from rfpimp import *
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
df_orig = pd.read_csv("C:/Users/Administrator/Desktop/rent.csv")
df = df_orig.copy()
# 突出rent.csv中价格异常值的影响
df['price'] = np.log(df['price'])
df_train, df_test = train_test_split(df, test_size=0.20)
features = ['bathrooms','bedrooms','longitude','latitude','price']
df_train = df_train[features]
df_test = df_test[features]
# 将训练集拆分,并将拆分后的数据分别赋予X_train(没有价格),y_train(价格)
X_train, y_train = df_train.drop('price',axis=1), df_train['price'] # drop():默认删除某行,若axis=1,表示删除某列数据
X_test, y_test = df_test.drop('price',axis=1), df_test['price']
# 添加随机数的列数
X_train['random'] = np.random.random(size=len(X_train)) # 返回0-1之间的随机数,矩阵大小为:len(X_train),即39481*1行随机数据
X_test['random'] = np.random.random(size=len(X_test))
df_train, df_test = train_test_split(df_orig, test_size=0.20)
features = ['bathrooms','bedrooms','price','longitude','latitude','interest_level']
df_train = df_train[features]
df_test = df_test[features]
X_train, y_train = df_train.drop('interest_level',axis=1), df_train['interest_level']
X_test, y_test = df_test.drop('interest_level',axis=1), df_test['interest_level']
X_train['random'] = np.random.random(size=len(X_train))
X_test['random'] = np.random.random(size=len(X_test))
构建随机森林分类器:
# 构建随机森林分类器
rf = RandomForestClassifier(n_estimators=100,
min_samples_leaf=5,
n_jobs=-1,
oob_score=True)
rf.fit(X_train, y_train)
imp = importances(rf, X_test, y_test) # permutation
viz = plot_importances(imp)
viz.view()
特征重要性显示:

2. 特征相关性分析(热图)
2.1 热图绘制
数据导入:
# 回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,分为一元回归和多元回归分析
# 按照因变量的多少:分为简单回归分析和多重回归分析
# 按照自变量和因变量之间的关系类型:分为线性回归分析和非线性回归分析
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, mean_absolute_error
from sklearn.model_selection import cross_val_score
from rfpimp import *
from sklearn.model_selection import train_test_split
from sklearn.base import clone
df_all = pd.read_csv("C:/Users/Administrator/Desktop/rent.csv")
num_features = ['bathrooms','bedrooms','latitude','longitude','price']
target = 'interest_level'
df = df_all[num_features + [target]]
# 计算每个卧室的中位数
df = df.copy()
df_median_price_per_bedrooms = df.groupby(by='bedrooms')['price'].median().reset_index() # reset_index():会将原来的索引index作为新的一列
# groupby()[]先以bedrooms进行分组,再提取每组中的price字段
beds_to_median = df_median_price_per_bedrooms.to_dict(orient='dict')['price'] # to_dict():将数据框数据转换为字典形式(字典为可变容器模型且可存储任意类型对象)
# 转换为字典格式,并将price字段提取出
df['median_price_per_bedrooms'] = df['bedrooms'].map(beds_to_median) # 合并两个表格
# 计算该数量卧室的价格与中间价格的比率
df['price_to_median_beds'] = df['price'] / df['median_price_per_bedrooms']
# 卧室数量与价格的比率
df["beds_per_price"] = df["bedrooms"] / df["price"]
# 房间总数(卧室、浴室)
df["beds_baths"] = df["bedrooms"]+df["bathrooms"]
del df['median_price_per_bedrooms']
df_train, df_test = train_test_split(df, test_size=0.15)
热图绘制:
from rfpimp import plot_corr_heatmap
viz = plot_corr_heatmap(df_train, figsize=(7,5))
viz.save('C:/Users/Administrator/Desktop/corrheatmap.tif')
viz
斯皮尔曼相关矩阵:

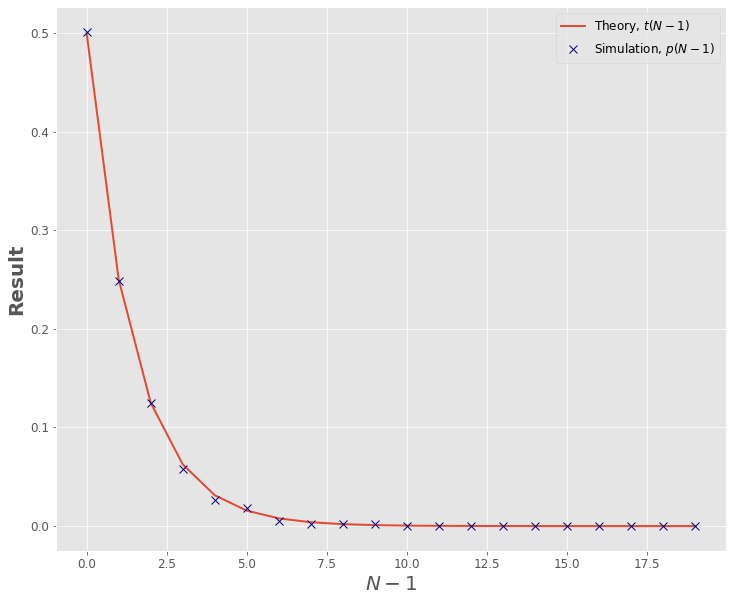
可以看出,值越大颜色越深,则数据之间的相关性越强。 比如卧室数量和卧室加浴室相关性为 0.98,相关性非常强。
2.2 构建随机森林模型
模型构建:
# 数据集拆分
X_train, y_train = df_train.drop('interest_level',axis=1), df_train['interest_level']
X_test, y_test = df_test.drop('interest_level',axis=1), df_test['interest_level']
rf = RandomForestClassifier(n_estimators=100, n_jobs=-1,
# max_features=X_train.shape[1]-1,
max_features=1.0,
min_samples_leaf=10, oob_score=True)
#训练集拟合
rf.fit(X_train, y_train)
特征重要性训练:
# 特征重要性训练
I = importances(rf, X_test, y_test)
viz = plot_importances(I)
viz.save('C:/Users/Administrator/Desktop/imp.tif')
viz

2.3 不同特征合并的重要性
2.3.1 经纬度合并(分3类)
I = importances(rf, X_test, y_test, features=['price',['latitude','longitude']])
viz = plot_importances(I, vscale=1.2)
viz.save('C:/Users/Administrator/Desktop/subset_imp.tif')
viz

2.3.2 经纬度合并(分2类)
I = importances(rf, X_test, y_test, features=[['latitude','longitude']])
viz = plot_importances(I, vscale=1.2)
viz.save('C:/Users/Administrator/Desktop/latlong_imp.jpg')
viz

2.3.3 经纬度合并(分4类)
features = ['bathrooms', 'bedrooms',
['latitude', 'longitude'],
['price_to_median_beds', 'beds_baths', 'price'],
['beds_per_price','bedrooms']]
I = importances(rf, X_test, y_test, features=features)
viz = plot_importances(I, vscale=1.3)
viz.save('C:/Users/Administrator/Desktop/grouped_imp.tif')
viz

2.3.4 经纬度合并(分4类)
features = [['latitude', 'longitude'],
['price_to_median_beds', 'beds_baths', 'beds_per_price', 'bedrooms'],
['price','beds_per_price','bedrooms']]
I = importances(rf, X_test, y_test, features=features)
viz = plot_importances(I, vscale=1.2)
viz.save('C:/Users/Administrator/Desktop/grouped_dup_imp.tif')
viz

2.3.5 oob重要性
# 兼容性测试 >= 0.22.1
I = oob_importances(rf, X_test, y_test)
plot_importances(I, vscale=1.2)

3. 总结
在机器学习中使用的特征很少是完全独立的,这使得解释特征的重要性十分困难。我们可以计算相关系数,但只能识别线性关系。一种方法是训练一个模型,使用x作为因变量,所有其他特征作为自变量,这样至少可以确定一个特征x是否依赖于其他特征。
因为随机森林给我们一个容易的出袋误差估计(oob),特征依赖函数依赖于随机森林模型。来自模型的 R2 预测误差表明使用其他特征预测特征x是很容易的。分数越高,特征x的依赖性越大。