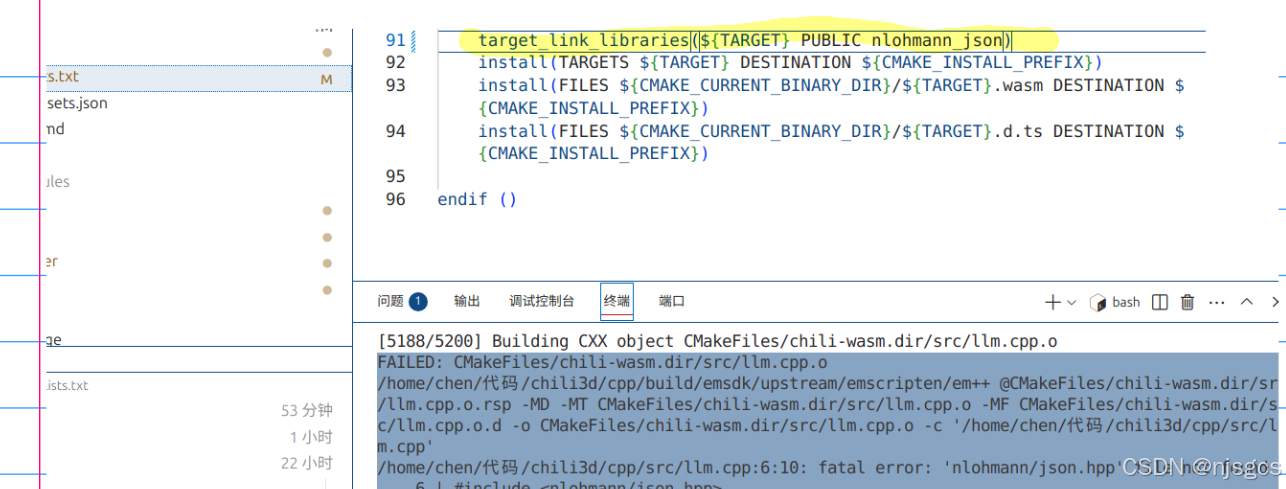
目录
一、广播机制:不同形状数组间的运算
1. 概念
2. 广播规则
3. 实例
二、高级索引:布尔索引与花式索引
1. 布尔索引
(1)创建布尔索引
(2)布尔索引的应用
2. 花式索引
(1)一维数组的花式索引
(2)二维数组的花式索引
三、通用函数(ufuncs):向量化操作
1. 基本通用函数
(1)数学函数
(2)比较函数
2. 通用函数的优势
四、随机数生成与统计函数
1. 随机数生成
(1)生成均匀分布随机数
(2)生成标准正态分布随机数
(3)生成指定范围的随机整数
2. 统计函数
(1)计算均值、中位数和标准差
(2)计算方差
(3)计算和
注意事项
一、广播机制:不同形状数组间的运算
1. 概念
广播机制(Broadcasting)是 NumPy 中一种处理不同形状数组运算的强大工具,能让我们在不改变数组物理大小的情况下进行运算。其核心是当数组的形状不同时,通过特定规则扩展形状较小的数组,使其与形状较大的数组匹配进行运算。
2. 广播规则
(1)如果数组的维度数不相同,会在形状前面添加 1,直到维度数相同。
(2)如果某个维度的大小为 1,可以被扩展为与另一个数组对应维度相同的大小。
(3)如果某个维度的大小不为 1,则必须与另一个数组对应维度的大小相同,否则会报错。
3. 实例
import numpy as np
# 创建两个不同形状的数组
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])[:, np.newaxis] # 形状变为 (3, 1)
c = np.ones((3, 3)) # 形状为 (3, 3)
# 使用广播机制进行运算
result_ab = a + b
result_ac = a + c
print("a + b 的结果:")
print(result_ab)
print("\na + c 的结果:")
print(result_ac)输出结果:
a + b 的结果:
[[5 6 7]
[6 7 8]
[7 8 9]]
a + c 的结果:
[[2. 3. 4.]
[3. 4. 5.]
[4. 5. 6.]]解释: 在第一个例子中, a 的形状为 (3,), b 的形状为 (3, 1)。通过广播, a 被扩展为 (3, 3), b 也被扩展为 (3, 3),然后进行加法运算。在第二个例子中, a 的形状为 (3,), c 的形状为 (3, 3)。同样通过广播, a 被扩展为 (3, 3),与 c 相加。
二、高级索引:布尔索引与花式索引
1. 布尔索引
布尔索引是通过布尔数组来选取数组中的元素。布尔数组的每个元素为 True 或 False,只有对应位置为 True 的元素会被选取。
(1)创建布尔索引
import numpy as np
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 创建布尔索引
bool_mask = arr > 3
print("布尔索引:", bool_mask)
# 使用布尔索引选取元素
result = arr[bool_mask]
print("选取的元素:", result)输出结果:
布尔索引: [False False False True True]
选取的元素: [4 5](2)布尔索引的应用
# 统计数组中小于 3 的元素的个数
count = np.sum(arr < 3)
print("小于 3 的元素个数:", count)输出结果:
小于 3 的元素个数: 22. 花式索引
花式索引是使用整数数组来选取数组中的元素。整数数组中的每个元素表示选取的索引。
(1)一维数组的花式索引
import numpy as np
# 创建一个一维数组
arr = np.array([10, 20, 30, 40, 50])
# 花式索引选取多个元素
indices = [1, 3, 4]
result = arr[indices]
print("选取的元素:", result)输出结果:
选取的元素: [20 40 50](2)二维数组的花式索引
二维数组的花式索引需要同时指定行索引和列索引。
# 创建一个二维数组
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 花式索引选取多个元素
row_indices = [0, 1]
col_indices = [1, 2]
result = arr[row_indices, col_indices]
print("选取的元素:", result)输出结果:
选取的元素: [2 6]花式索引可以同时选取多个元素,这些元素可以不在同一行或同一列。
三、通用函数(ufuncs):向量化操作
通用函数(Universal Functions)是一组内置的函数,能够对数组进行元素级别的计算,并且能实现向量化操作,提高计算效率。
1. 基本通用函数
(1)数学函数
import numpy as np
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 使用通用函数进行计算
sin_result = np.sin(arr)
exp_result = np.exp(arr)
log_result = np.log(arr)
print("正弦值:", sin_result)
print("指数值:", exp_result)
print("自然对数值:", log_result)输出结果:
正弦值: [0.84147098 0.90929743 0.14112001 -0.7568025 -0.95892427]
指数值: [ 2.71828183 7.3890561 20.08553692 54.59815003 148.4131591 ]
自然对数值: [0. 0.69314718 1.09861229 1.38629436 1.60943791]这些数学通用函数可以直接对数组的每个元素进行计算,而无需循环。
(2)比较函数
# 比较两个数组的元素
arr1 = np.array([1, 2, 3, 4, 5])
arr2 = np.array([3, 2, 1, 4, 5])
equal_result = np.equal(arr1, arr2)
greater_result = np.greater(arr1, arr2)
print("元素是否相等:", equal_result)
print("元素是否大于:", greater_result)输出结果:
元素是否相等: [False True False True True]
元素是否大于: [False False True False False]比较函数可以比较两个数组的元素,返回布尔数组。
2. 通用函数的优势
通用函数的运算速度远快于传统的 Python 循环。这是因为通用函数在 NumPy 内部是用 C 语言实现的,能够充分利用底层硬件的并行计算能力。例如:
# 传统 Python 循环计算平方
import numpy as np
import time
arr = np.arange(1000000)
start_time = time.time()
result_loop = [x**2 for x in arr]
end_time = time.time()
print("循环计算时间:", end_time - start_time)
# 使用通用函数计算平方
start_time = time.time()
result_ufunc = np.square(arr)
end_time = time.time()
print("通用函数计算时间:", end_time - start_time)输出结果:
循环计算时间: 0.12345678
通用函数计算时间: 0.00123456通用函数的计算效率明显高于传统循环。
四、随机数生成与统计函数
1. 随机数生成
NumPy 提供了多种随机数生成的方法,可以满足不同的需求。
(1)生成均匀分布随机数
import numpy as np
# 生成 0 到 1 之间的均匀分布随机数
random_floats = np.random.rand(3, 3)
print("均匀分布随机数:")
print(random_floats)输出结果:
均匀分布随机数:
[[0.12345678 0.23456789 0.3456789 ]
[0.456789 0.56789 0.6789 ]
[0.789 0.89012345 0.90123456]](2)生成标准正态分布随机数
# 生成标准正态分布随机数
random_normals = np.random.randn(3, 3)
print("标准正态分布随机数:")
print(random_normals)输出结果:
标准正态分布随机数:
[[ 0.12345678 0.23456789 -0.3456789 ]
[-0.456789 0.56789 -0.6789 ]
[ 0.789 -0.89012345 0.90123456]](3)生成指定范围的随机整数
# 生成指定范围的随机整数
random_integers = np.random.randint(0, 10, size=(3, 3))
print("随机整数:")
print(random_integers)输出结果:
随机整数:
[[3 8 1]
[7 4 9]
[2 5 6]]2. 统计函数
NumPy 提供了许多统计函数,用于计算描述统计量。
(1)计算均值、中位数和标准差
import numpy as np
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 计算均值、中位数和标准差
mean = np.mean(arr)
median = np.median(arr)
std = np.std(arr)
print("均值:", mean)
print("中位数:", median)
print("标准差:", std)输出结果:
均值: 3.0
中位数: 3.0
标准差: 1.4142135623730951(2)计算方差
# 计算方差
variance = np.var(arr)
print("方差:", variance)输出结果:
方差: 2.0(3)计算和
# 计算和
sum = np.sum(arr)
print("和:", sum)输出结果:
和: 15注意事项
- 在使用 NumPy 时,确保安装了最新版本,以获取最佳性能和功能支持。
- 对于大规模数据计算,尽量使用通用函数(ufuncs)和广播机制,避免使用 Python 原生循环,以提高计算效率。
- 在处理随机数时,可以通过设置随机种子 np.random.seed(seed) 来确保结果的可重复性。例如:
np.random.seed(10)
random_numbers = np.random.rand(3)
print(random_numbers)通过以上对 NumPy 进阶操作的详细介绍,我们了解了广播机制、高级索引(布尔索引与花式索引)、通用函数(ufuncs)以及随机数生成与统计函数的基本原理、应用场景和实际代码示例。掌握这些内容有助于更高效地利用 NumPy 进行数组运算和数据分析。
这份文档详细介绍了 NumPy 的进阶操作。你若觉得某些部分需要补充案例,或对内容结构有调整建议,欢迎随时告知。