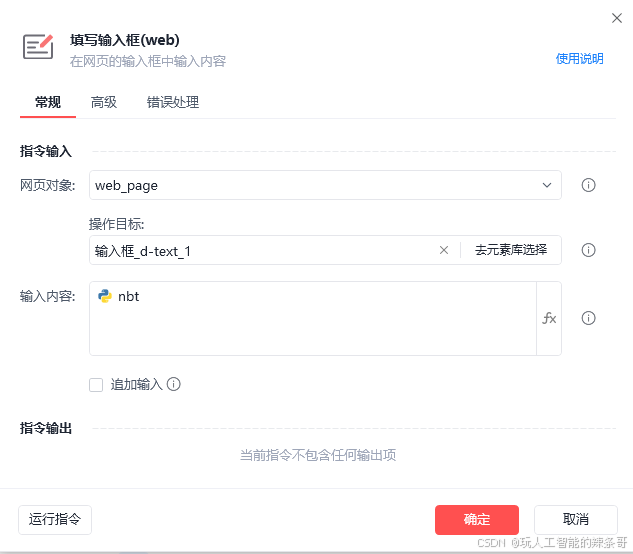
进阶篇 第 5 篇:现代预测方法 - Prophet 与机器学习特征工程

(图片来源: ThisIsEngineering RAEng on Pexels)
在前几篇中,我们深入研究了经典的时间序列统计模型,如 ETS 和强大的 SARIMA 家族。它们在理论上成熟且应用广泛,但有时也面临挑战:模型选择和参数调整可能比较复杂,并且它们本质上是线性模型(或通过变换处理非线性),对于某些复杂模式的捕捉能力有限。
幸运的是,时间序列分析领域也在不断发展,涌现出许多现代的预测方法。本篇,我们将聚焦于两种截然不同但都非常强大的现代思路:
- Facebook Prophet: 一个开源的、易于使用且对商业数据特别友好的自动化预测库。
- 机器学习方法 (特征工程视角): 一种思维上的转变,将时间序列预测重新表述为监督学习问题,核心在于如何巧妙地构建能捕捉时间信息的特征。
我们将探索这两种方法的原理、实践和适用场景,为你的时间序列工具箱增添更多利器。
Part 1: Facebook Prophet - 自动化预测“瑞士军刀”
当你需要快速、稳健地预测具有强季节性(可能包含年、周、日等多种周期)、节假日效应,并且可能存在趋势变化的业务时间序列(如销售额、网站流量、用户增长)时,Facebook 开源的 Prophet 库是一个非常值得考虑的选择。
Prophet 的设计哲学
Prophet 的设计围绕几个核心原则:
- 易用性 (Tunable): 提供直观的参数,即使非时间序列专家也能进行合理调整。默认设置通常效果不错。
- 自动化 (Fully automatic): 尽可能自动化地处理季节性、趋势变化点等,减少手动干预。
- 稳健性 (Robust): 对缺失值和异常值有较好的鲁棒性。
- 可解释性 (Interpretable): 模型结构清晰,易于理解趋势、季节性和节假日各自的贡献。
Prophet 的模型结构:解构预测
Prophet 本质上是一个基于加法模型的时间序列分解方法:
y(t) = g(t) + s(t) + h(t) + ε(t)
其中:
g(t)- 趋势项 (Trend):- 默认使用分段线性模型 (Piecewise Linear Model) 来拟合非线性趋势。Prophet 会自动检测趋势中的变化点 (Changepoints)。
- 也可以选择饱和增长模型 (Logistic Growth),当你预期增长有上限(或下限)时非常有用(需要提供
cap或floor值)。
s(t)- 季节性项 (Seasonality):- 使用傅立叶级数 (Fourier Series) 来拟合周期性模式。
- 能够同时拟合多种季节性,如年度 (
yearly_seasonality)、周度 (weekly_seasonality)、日度 (daily_seasonality)。 - 可以添加自定义的季节性周期。
h(t)- 节假日效应项 (Holidays):- 允许你指定节假日列表及其可能影响的时间窗口(例如,圣诞节不仅影响当天,可能还影响前后几天)。
- 可以轻松加入特定国家的内置节假日。
ε(t)- 误差项 (Error): 假设为正态分布的随机噪声。
Prophet 实战:快速上手
使用 Prophet 非常直接:
# 需要先安装: pip install prophet
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as plt
import statsmodels.api as sm # 借用 CO2 数据
# 1. 数据准备 (必须包含 'ds' 和 'y' 列)
co2_data = sm.datasets.co2.load_pandas().data['co2']
co2_data = co2_data.interpolate().resample('M').mean().reset_index() # 重置索引
co2_data.rename(columns={'index': 'ds', 'co2': 'y'}, inplace=True) # 重命名列
print("Prophet input data (head):")
print(co2_data.head())
# 2. 实例化并拟合模型
# 可以调整参数,如 changepoint_prior_scale (趋势灵活性), seasonality_prior_scale (季节性强度)
model = Prophet(yearly_seasonality=True, # 开启年度季节性
weekly_seasonality=False, # 关闭周季节性 (月度数据无意义)
daily_seasonality=False) # 关闭日季节性
# (可选) 添加节假日
# model.add_country_holidays(country_name='US')
model.fit(co2_data)
# 3. 创建未来日期的数据框
# 预测未来 3 年 (36个月)
future_dates = model.make_future_dataframe(periods=36, freq='M')
print("\nFuture dates dataframe (tail):")
print(future_dates.tail())
# 4. 进行预测
forecast = model.predict(future_dates)
print("\nForecast dataframe (tail with components):")
# forecast 包含预测值 'yhat', 置信区间 'yhat_lower', 'yhat_upper' 及各成分
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper', 'trend', 'yearly']].tail())
# 5. 可视化预测结果
fig1 = model.plot(forecast)
plt.title('Prophet Forecast for CO2 Data')
plt.xlabel('Date')
plt.ylabel('CO2 Concentration')
plt.show()
# 6. 可视化成分
fig2 = model.plot_components(forecast)
plt.show()
# 7. (可选) 模型评估 - 交叉验证
# from prophet.diagnostics import cross_validation, performance_metrics
# df_cv = cross_validation(model, initial='730 days', period='180 days', horizon = '365 days')
# df_p = performance_metrics(df_cv)
# print("\nPerformance Metrics (example):")
# print(df_p.head())



解读与定制:
plot():展示历史数据点、预测值yhat以及置信区间。plot_components():分别展示拟合出的趋势、年度季节性、周度季节性(如果开启)等成分,非常有助于理解模型的判断。- 调整参数:
changepoint_prior_scale: 增大它使趋势更灵活,减小它使趋势更平滑。seasonality_prior_scale: 增大它使季节性幅度更大。holidays: 通过pd.DataFrame提供自定义节假日。growth='logistic': 使用饱和增长,需提供cap列。
Prophet 的优缺点
优点:
- 易用性高,自动化程度好: 对新手友好,能快速得到不错的基线预测。
- 擅长处理强季节性与节假日: 这是其核心优势。
- 对趋势变化点鲁棒: 自动检测变化点。
- 结果可解释性强: 成分图清晰展示各部分贡献。
- 处理缺失值和异常值能力较好。
缺点:
- “黑盒”感相对较强: 虽然可解释,但内部细节(如傅立叶级数阶数选择)对用户不透明。
- 不直接提供 AR/MA 部分: 它不显式地对短期自相关性(如 ARMA 模型所做的)进行建模,可能在某些高度自相关的序列上表现不如 ARIMA。
- 需要特定数据格式 (
ds,y)。 - 预测区间可能偏窄: 有时对不确定性的估计可能过于乐观。
何时选择 Prophet? 当你的数据符合其设计初衷(强季节性、节假日、趋势变化),且你需要快速、稳健、易于解释的结果时,Prophet 是一个极佳的选择。
Part 2: 思维转变 - 时间序列作为机器学习问题
与 Prophet 这种“端到端”的预测工具不同,另一种强大的现代方法是将时间序列预测重新构建为一个标准的监督学习问题。这种方法的核心在于特征工程 (Feature Engineering),而不是直接对时间依赖性建模。
范式转换:从 y(t) ~ f(y(t-k), ε(t-k)) 到 y_hat(t) = f(X(t))
- 传统统计模型 (如 ARIMA): 试图直接找到
y(t)与其过去值y(t-k)和过去误差ε(t-k)之间的数学关系。 - 机器学习方法: 我们不再直接寻找这种时序关系,而是为每个时间点
t构建一个特征向量X(t),然后训练一个机器学习模型f来学习从X(t)到y(t)的映射。
这个 X(t) 必须能够捕捉到所有与预测 y(t) 相关的时间信息。
特征工程的艺术:从时间中提取信息
构建有效的特征向量 X(t) 是这种方法成功的关键。以下是一些最常用的时间序列特征类别:
-
滞后特征 (Lag Features):
- 是什么: 直接使用过去的观测值作为特征。例如,用
y(t-1), y(t-2), y(t-3)来预测y(t)。 - 作用: 捕捉短期的自相关性(类似于 AR 部分)。
- 选择: 滞后多少阶?可以基于 PACF 图的截尾阶数获得启发,或作为超参数进行调整。
- Python 实现 (Pandas
shift()):
# 假设 df 是包含 'y' 列的 DataFrame,索引是时间 df = co2_data.set_index('ds') # 假设已有 Prophet 格式数据,转回时间索引 for i in range(1, 4): # 创建 lag 1, 2, 3 df[f'lag_{i}'] = df['y'].shift(i) df.dropna(inplace=True) # 滞后操作会产生 NaN,需要处理 print("\nDataFrame with Lag Features (head):") print(df.head()) - 是什么: 直接使用过去的观测值作为特征。例如,用
-
窗口特征 / 滚动统计量 (Window Features / Rolling Statistics):
- 是什么: 计算过去一段时间窗口内的统计量。例如,过去 3 个月、6 个月或 12 个月的平均值、标准差、最大/最小值等。
- 作用: 捕捉近期的趋势、波动性或水平。
- 选择: 窗口大小是关键参数。
- Python 实现 (Pandas
rolling()):
window_size = 12 # 例如,12个月滚动窗口 # 注意:rolling 计算的是包含当前点在内的窗口,预测时常用 shift 后的滞后窗口 df[f'rolling_mean_{window_size}'] = df['y'].shift(1).rolling(window=window_size).mean() df[f'rolling_std_{window_size}'] = df['y'].shift(1).rolling(window=window_size).std() df.dropna(inplace=True) print(f"\nDataFrame with Rolling Features (head, window={window_size}):") print(df[['y', f'rolling_mean_{window_size}', f'rolling_std_{window_size}']].head()) -
日期/时间特征 (Date/Time Features):
- 是什么: 从时间索引中提取信息。
- 作用: 捕捉季节性、周期性、日历效应。
- 常见特征:
- 年份 (
year) - 月份 (
month) - 星期几 (
dayofweek) - 一年中的第几天 (
dayofyear) - 一年中的第几周 (
weekofyear) - 季度 (
quarter) - 是否周末 (
is_weekend) - 周期性编码: 对于像月份、星期几这样的周期性特征,直接用数字(如 1-12)可能无法让模型理解其周期性(12月和1月是相邻的)。常用正弦/余弦变换 (Sine/Cosine Transformation) 来编码:
df['month_sin'] = np.sin(2 * np.pi * df.index.month / 12)
df['month_cos'] = np.cos(2 * np.pi * df.index.month / 12)
- 年份 (
- Python 实现 (Pandas DatetimeIndex attributes):
df['month'] = df.index.month df['year'] = df.index.year df['dayofweek'] = df.index.dayofweek # ... 其他日期特征 ... # Sine/Cosine for month df['month_sin'] = np.sin(2 * np.pi * df['month'] / 12) df['month_cos'] = np.cos(2 * np.pi * df['month'] / 12) print("\nDataFrame with Date Features (head):") print(df[['y', 'month', 'year', 'month_sin', 'month_cos']].head()) -
扩展特征 (Expansion Features):
- 特征之间的交互项(如
lag_1 * rolling_mean_12)。 - 滞后特征的差分(如
lag_1 - lag_2)。
- 特征之间的交互项(如
为什么选择机器学习方法?
- 灵活性: 可以使用任何监督学习模型(线性模型、树模型、神经网络等),选择最适合数据复杂度的模型。
- 易于加入外生变量: 将其他时间序列(如广告支出、天气)作为额外特征列加入
X(t)非常自然。 - 捕捉非线性: 许多 ML 模型(如树模型、神经网络)能很好地捕捉复杂的非线性关系和特征交互。
- 无需严格平稳性假设: 像基于树的模型对数据的平稳性要求不像 ARIMA 那样严格(尽管平稳化有时仍有助于特征工程)。
下一步(预告)
本篇我们重点展示了如何创建适用于机器学习的特征。真正的下一步是:
- 选择并训练 ML 模型: 将
X(t)作为输入,y(t)作为目标,训练如 RandomForestRegressor, XGBoost, LightGBM 等模型。 - 处理时间序列交叉验证: 使用 Walk-Forward Validation 或
TimeSeriesSplit来可靠地评估模型性能。 - 超参数调优: 结合时间序列 CV 进行模型调优。
这部分内容将在后续文章中深入探讨(或者可以作为你自行探索的方向)。
总结:现代方法的选择
今天我们探索了两种强大的现代时间序列预测方法:
- Prophet: 一个专注于易用性、自动化和处理特定业务场景(强季节性、节假日)的优秀工具库。当你需要快速、稳健、可解释的结果时,它是一个首选。
- 机器学习特征工程: 一种更通用的方法论,将预测问题转化为监督学习。其核心在于构建能够捕捉时间信息的特征,然后可以利用整个机器学习生态系统的强大模型。这种方法提供了极大的灵活性,特别适合处理复杂关系和融入多源信息。
这两种方法并非相互排斥,有时甚至可以结合使用(例如,用 Prophet 的成分作为 ML 模型的特征)。理解它们的原理、优势和局限性,将使你能够根据具体问题选择最合适的工具。
下一篇预告:
既然我们已经学会了如何为机器学习模型准备时间序列特征,下一篇我们将深入探讨如何实际应用这些模型(如 Random Forest, Gradient Boosting),并特别关注在时间序列场景下进行可靠的模型评估和验证所必须的时间序列交叉验证技术。
准备好看机器学习模型如何在时间序列上大显身手了吗?敬请期待!
(你认为 Prophet 更适合解决你遇到的哪类问题?对于机器学习方法,你觉得哪种特征工程技巧最有潜力?欢迎在评论区分享你的想法!)