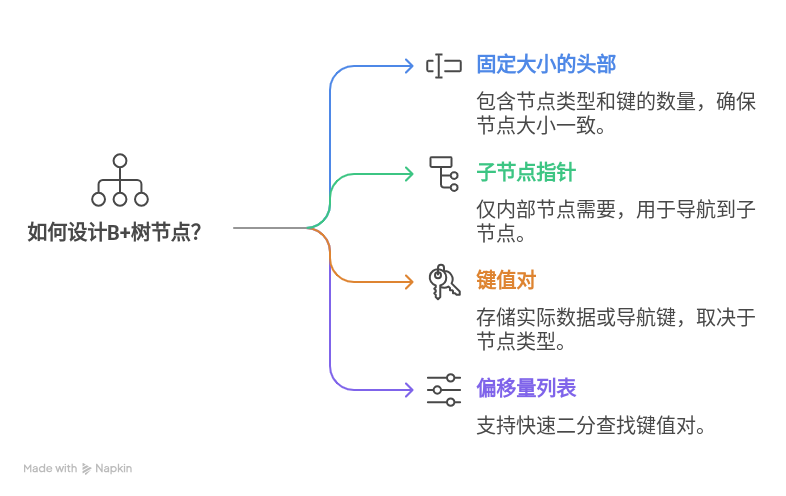
利用Stream和OpenAI构建基于RAG的AI客服聊天机器人
尽管大语言模型经过海量数据训练,但其领域专业知识仍有限。这一局限使其在需要特定数据的客服聊天机器人等应用中表现欠佳。
检索增强生成(RAG)通过让大语言模型访问外部知识源来生成更精准的响应,有效解决了这一问题。借助RAG技术,您可以让大语言模型在生成过程中从知识库获取相关信息作为上下文,从而准确回答客户咨询,打造自动化客服系统。
请注意,RAG并非增强大语言模型能力的唯一方式。另一种方法是微调模型。但对于需要庞大外部知识库或数据频繁变更的场景(如客服系统),RAG显然更为适合。
本教程将指导您使用Stream、OpenAI的GPT-4和Supabase的pgvector构建基于RAG的智能客服聊天机器人。Stream为开发者提供强大支持,可轻松构建可扩展的嵌入式聊天、视频及动态流功能,其强大的API、SDK和AI集成方案能显著加速应用开发。
教程将涵盖以下内容:
-
利用Supabase的pgvector功能,从我们的知识库创建并存储向量嵌入。pgvector提供了一种高效的方式来存储和查询向量嵌入。
知识库是指作为有用上下文依赖的外部知识来源,供您的LLM使用。 -
对客户的聊天内容进行嵌入处理,并在存储的知识库嵌入向量上进行相似性搜索。
-
配置Stream并构建我们基于RAG技术的聊天机器人。
前提条件
要跟着做,你需要:
-
一个免费的 Stream 账户。
-
一个 OpenAI 账户。
-
一个 Supabase 账户。
向量数据库设置
我们将首先使用Supabase搭建一个向量数据库,用于存储向量嵌入并执行相似性搜索。本教程将以Stream的React文档作为知识库。
进入Supabase的SQL编辑器,我们将依次执行以下操作:启用pgvector扩展、创建向量表,并编写一个能在知识库上执行相似性搜索的函数。
-- Enable pgvector
create extension if not exists vector;
-- Create documents table
create table if not exists documents (
id bigserial primary KEY,
content TEXT,
embedding vector(1536)
);
-- Create match document function
create or replace function match_documents (
query_embedding vector(1536),
match_threshold float,
match_count int
)
returns table (
id bigint,
content text,
similarity float
)
language plpgsql
as $$
begin
return query
select
documents.id,
documents.content,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where 1 - (documents.embedding <=> query_embedding) > match_threshold
order by similarity desc
limit match_count;
end;
$$;
运行上述代码以执行您的查询。这将创建一个名为documents的表,包含三列:id、content和embedding。其中content列用于存储知识库的实际文本内容,而embedding列则用于存储知识库的向量嵌入。我们还创建了一个match_documents函数,用于对documents