- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾:【深度学习】你真的理解张量了吗?|标量、向量、矩阵、张量的秩|01
- 每日一言🌼: “脑袋想不明白的,就用脚想”——《走吧,张小砚》🌺
0、前言
在张量的操作的时候,有下面几个概念总容易弄混:
- 点积
- 内积
- 外积
- 哈达玛积(Hadamard Product
- 矩阵乘法
这篇博客,我将结合这三种操作在深度学习中的运用,来讲解一下这三种操作的区别。
1、点积(Dot Product)
点积定义和计算:
点积是两个向量的之间的二元运算,结果为标量。数学意义上:取两个相等长度的数字序列(通常是坐标向量,也就是坐标点),并返回一个数字。
对于向量(一阶张量) u = [ u 1 , u 2 , ⋯ , u n ] \mathbf{u} = [u_1, u_2, \cdots, u_n] u=[u1,u2,⋯,un] 和 v = [ v 1 , v 2 , ⋯ , v n ] \mathbf{v} = [v_1, v_2, \cdots, v_n] v=[v1,v2,⋯,vn] , u , v ∈ R n \mathbf{u},\mathbf{v}\in\mathbb{R}^n u,v∈Rn,点积的定义为: 逐元素相乘,再相加
u ⋅ v = ∑ i = 1 n u i v i \mathbf{u}\cdot\mathbf{v}=\sum_{i=1}^nu_iv_i u⋅v=i=1∑nuivi
在欧几里得空间中,点积也可表示为:
u
⋅
v
=
∥
u
∥
∥
v
∥
cos
θ
(
θ
为夹角)
\mathbf{u}\cdot\mathbf{v}=\|\mathbf{u}\|\|\mathbf{v}\|\cos\theta\text{ (}\theta\text{ 为夹角) }
u⋅v=∥u∥∥v∥cosθ (θ 为夹角)
示例:
[ 1 2 ] ⋅ [ 3 4 ] = 1 × 3 + 2 × 4 = 11 \begin{bmatrix}1\\2\end{bmatrix}\cdot\begin{bmatrix}3\\4\end{bmatrix}=1\times3+2\times4=11 [12]⋅[34]=1×3+2×4=11
特点:
- 仅适用于向量(一阶张量)。
- 满足交换律 u ⋅ v = v ⋅ u \mathbf{u}\cdot\mathbf{v}=\mathbf{v}\cdot\mathbf{u} u⋅v=v⋅u
- 是内积在欧几里得空间中的特例(当内积空间为 R n \mathbb{R}^n Rn且权重矩阵为单位矩阵时)
在深度学习中的应用
首先代码是:
# 点积(向量)
u = torch.tensor([1, 2, 3])
v = torch.tensor([4, 5, 6])
# NumPy
dot_product = np.dot(u, v) # 或 u @ v,一维矩阵相乘=向量点乘
# PyTorch
dot_product = torch.dot(u, v) # 一维张量
-
余弦相似度(Cosine Similarity):
归一化点积用于衡量向量相似性:
cos ( θ ) = u ⋅ v ∥ u ∥ ∥ v ∥ = ∑ i = 1 n u i v i ∑ i = 1 n u i 2 ∑ i = 1 n v i 2 \cos(\theta)=\frac{\mathbf{u} \cdot \mathbf{v}}{\|\mathbf{u}\| \|\mathbf{v}\|} = \frac{\sum_{i=1}^{n} u_i v_i}{\sqrt{\sum_{i=1}^{n} u_i^2} \sqrt{\sum_{i=1}^{n} v_i^2}} cos(θ)=∥u∥∥v∥u⋅v=∑i=1nui2∑i=1nvi2∑i=1nuivi其中:
-
u ⋅ v \mathbf{u} \cdot \mathbf{v} u⋅v 表示向量 u \mathbf{u} u 和 v \mathbf{v} v 的点积,即 ∑ i = 1 n u i v i \sum_{i=1}^{n} u_i v_i ∑i=1nuivi。
-
∥ u ∥ \|\mathbf{u}\| ∥u∥ 和 ∥ v ∥ \|\mathbf{v}\| ∥v∥ 分别表示向量 u \mathbf{u} u 和 v \mathbf{v} v 的 L 2 L_2 L2 范数(也称为欧几里得范数),计算公式分别为 ∑ i = 1 n u i 2 \sqrt{\sum_{i=1}^{n} u_i^2} ∑i=1nui2 和 ∑ i = 1 n v i 2 \sqrt{\sum_{i=1}^{n} v_i^2} ∑i=1nvi2。
-
余弦相似度常用于对比学习(Contrastive Learning)或推荐系统。
# 计算两个特征向量的余弦相似度 def cosine_similarity(u, v, eps=1e-8): dot_product = torch.dot(u, v) norm_u = torch.norm(u) norm_v = torch.norm(v) return dot_product / (norm_u * norm_v + eps) # 用于对比损失(如InfoNCE Loss) positive_sim = cosine_similarity(anchor, positive) # 增大 negative_sim = cosine_similarity(anchor, negative) # 减小 -
2、内积(Inner Product)——点积的推广
定义和计算:
内积是点积的推广,适用于更一般的向量空间(如函数空间、矩阵空间)。对于向量或高阶张量,内积通常指在特定空间中的一种双线性运算,结果为标量。
在工科的讨论范围内,内积和点积会混在一起说。这是无可厚非的,毕竟点积是内积的一种特殊形式。
-
在 R n \mathbb{R}^n Rn空间中,内积与点积相同(一阶张量,n维向量,n个元素相乘再相加)。
-
在矩阵空间(二阶张量)中,Frobenius内积定义为:即两个形状相同的矩阵对应位置的元素相乘后求和,结果是一个标量。
⟨ A , B ⟩ F = ∑ i , j A i j B i j = t r ( A T B ) \langle\mathbf{A},\mathbf{B}\rangle_F=\sum_{i,j}A_{ij}B_{ij}=\mathrm{tr}(\mathbf{A}^T\mathbf{B}) ⟨A,B⟩F=i,j∑AijBij=tr(ATB)其中 tr ( ⋅ ) \operatorname{tr}(\cdot) tr(⋅)代表求矩阵的迹(trace): tr ( A T B ) = ∑ i = 1 n ( A T B ) i i = ∑ i = 1 n ∑ k = 1 m A k i B k i \operatorname{tr}(\mathbf{A}^T\mathbf{B})=\sum_{i=1}^n(\mathbf{A}^T\mathbf{B})_{ii}=\sum_{i=1}^n\sum_{k=1}^mA_{ki}B_{ki} tr(ATB)=∑i=1n(ATB)ii=∑i=1n∑k=1mAkiBki
特点:
- 广义性:内积可以定义在函数、矩阵等对象上(如 ⟨ f , g ⟩ = ∫ f ( x ) g ( x ) d x ) \langle f,g\rangle=\int f(x)g(x)dx) ⟨f,g⟩=∫f(x)g(x)dx)
- 需满足正定性、对称性和线性性(在复空间中为共轭对称性)。
- 点积是内积在有限维实数空间中的特例。
示例:
矩阵内积:
⟨
[
1
2
3
4
]
,
[
5
6
7
8
]
⟩
F
=
1
×
5
+
2
×
6
+
3
×
7
+
4
×
8
=
70
。
\left\langle\begin{bmatrix}1&2\\3&4\end{bmatrix},\begin{bmatrix}5&6\\7&8\end{bmatrix}\right\rangle_F=1\times5+2\times6+3\times7+4\times8=70。
⟨[1324],[5768]⟩F=1×5+2×6+3×7+4×8=70。
与内积的联系:内积 = 哈达玛积的所有元素之和。
内积的计算可以分解为两步:
- 先计算哈达玛积:对输入矩阵/向量逐元素相乘。
- 再求和:将哈达玛积的所有元素相加,得到标量。
| 运算 | 定义 | 输入要求 | 输出 |
|---|---|---|---|
| 哈达玛积 | A ∘ B ,逐元素相乘: C i j = A i j B i j \mathbf{A}\circ\mathbf{B}\text{,逐元素相乘:}C_{ij}=A_{ij}B_{ij} A∘B,逐元素相乘:Cij=AijBij | 同形状矩阵/张量 | 同形状矩阵 |
| 内积 | 向量: ⟨ u , v ⟩ = ∑ i u i v i 矩阵: ⟨ A , B ⟩ F = ∑ i , j A i j B i j \begin{aligned}&\text{向量:}\langle\mathbf{u},\mathbf{v}\rangle=\sum_iu_iv_i\\&\text{矩阵:}\langle\mathbf{A},\mathbf{B}\rangle_F=\sum_{i,j}A_{ij}B_{ij}\end{aligned} 向量:⟨u,v⟩=i∑uivi矩阵:⟨A,B⟩F=i,j∑AijBij | 向量同维或矩阵同形 | 标量 |
在深度学习中的应用(PyTorch代码实现
(1) 向量内积(就是点积,可以参考上面点积的应用)
import torch
u = torch.tensor([1.0, 2.0, 3.0]) # [3]
v = torch.tensor([4.0, 5.0, 6.0]) # [3]
# 方法1:直接点积
dot_product = torch.dot(u, v) # 输出: 1*4 + 2*5 + 3*6 = 32.0
# 方法2:等价于求和逐元素乘积
dot_product_alt = torch.sum(u * v) # 同上
(2) 矩阵内积(Frobenius内积)
A = torch.tensor([[1.0, 2.0], [3.0, 4.0]]) # [2, 2]
B = torch.tensor([[5.0, 6.0], [7.0, 8.0]]) # [2, 2]
# 方法1:逐元素乘后求和
frobenius_inner = torch.sum(A * B) # 1*5 + 2*6 + 3*7 + 4*8 = 70.0
# 方法2:迹运算
frobenius_inner_alt = torch.trace(A.T @ B) # 同上
深度学习中的应用:
(1) 正则化(Regularization)
-
L2 正则化(权重衰减)可以看作权重矩阵与自身的内积
∥ W ∥ F 2 = ⟨ W , W ⟩ F \|\mathbf{W}\|_F^2=\langle\mathbf{W},\mathbf{W}\rangle_F ∥W∥F2=⟨W,W⟩F这样做是为了避免在求导时出现平方根运算,简化计算,避免过拟合。 -
应用场景:L2权重衰减(权重矩阵的Frobenius范数)。在 L2 权重衰减中,正则化项通常使用 L2 范数的平方
-
代码:
weight = torch.randn(100, 50, requires_grad=True) l2_reg = torch.sum(weight ** 2) # 等价于 Frobenius 内积 <weight, weight> loss = model_loss + 0.01 * l2_reg # 添加到总损失
(2) 核方法(Kernel Methods)
-
在支持向量机(SVM)或高斯过程中,内积用于计算数据在高维空间的相似性: K ( x , y ) = ⟨ ϕ ( x ) , ϕ ( y ) ⟩ K(\mathbf{x},\mathbf{y})=\langle\phi(\mathbf{x}),\phi(\mathbf{y})\rangle K(x,y)=⟨ϕ(x),ϕ(y)⟩其中 ϕ \phi ϕ 是特征映射。
-
核函数的核心思想是:直接计算高维空间中的内积 ⟨ ϕ ( x ) , ϕ ( y ) ⟩ \langle\phi(\mathbf{x}),\phi(\mathbf{y})\rangle ⟨ϕ(x),ϕ(y)⟩而无需显式构造到高维 ϕ ( x ) \phi(\mathbf{x}) ϕ(x)。对于高斯核,可以证明它对应一个无限维的特征映射(这里没有深究原理,但确实有数学公式可以证明)。
-
手动实现的高斯核
import numpy as np def rbf_kernel(x, y, sigma=1.0): """手动实现高斯核(内积形式)""" distance = np.linalg.norm(x - y) ** 2 # ||x - y||^2 return np.exp(-distance / (2 * sigma ** 2)) # K(x,y) = <φ(x), φ(y)> # 示例计算 x = np.array([1.0, 2.0]) y = np.array([3.0, 4.0]) print("手动计算高斯核:", rbf_kernel(x, y))
(3)自注意力机制中的Query-Key评分
-
虽然Transformer中的 Q K T QK^T QKT 是矩阵乘法,但每个评分 Q i ⋅ K j Q_i\cdot K_j Qi⋅Kj是向量点积(内积)
Q = torch.randn(10, 64) # [seq_len, d_k] K = torch.randn(10, 64) # [seq_len, d_k] scores = Q @ K.T # [10, 10], 每个元素是内积
3、外积(Outer Product)
定义和计算:
在线性代数中,两个坐标向量的外积(Outer product)是一个矩阵。如果这两个向量的维数分别为n和m,那么它们的外积是一个n×m矩阵。(相当于n×1的矩阵核1×m的矩阵相乘)
外积是两个向量的张量积,结果为高阶张量。对于向量 u ∈ R m \mathbf{u}\in\mathbb{R}^m u∈Rm和 v ∈ R n \mathbf{v}\in\mathbb{R}^n v∈Rn,外积生成一个矩阵(二阶张量):
u
⊗
v
=
u
v
T
=
[
u
1
v
1
⋯
u
1
v
n
⋮
⋱
⋮
u
m
v
1
⋯
u
m
v
n
]
\mathbf{u}\otimes\mathbf{v}=\mathbf{u}\mathbf{v}^T=\begin{bmatrix}u_1v_1&\cdots&u_1v_n\\\vdots&\ddots&\vdots\\u_mv_1&\cdots&u_mv_n\end{bmatrix}
u⊗v=uvT=
u1v1⋮umv1⋯⋱⋯u1vn⋮umvn
对于高阶张量,外积将它们的阶数相加(如
m
m
m阶张量和
n
n
n阶张量,计算外积,结果是
m
+
n
m+n
m+n阶张量。
特点:
- 不满足交换律 ( u ⊗ v ≠ v ⊗ u (\mathbf{u}\otimes\mathbf{v}\neq\mathbf{v}\otimes\mathbf{u} (u⊗v=v⊗u
- 用于构造高阶张量(如矩阵、三阶张量等)。
- 与叉积(Cross Product)不同(叉积仅适用于三维向量,结果为向量)。
示例:
[ 1 2 ] ⊗ [ 3 4 ] = [ 1 × 3 1 × 4 2 × 3 2 × 4 ] = [ 3 4 6 8 ] \begin{bmatrix}1\\2\end{bmatrix}\otimes\begin{bmatrix}3&4\end{bmatrix}=\begin{bmatrix}1\times3&1\times4\\2\times3&2\times4\end{bmatrix}=\begin{bmatrix}3&4\\6&8\end{bmatrix} [12]⊗[34]=[1×32×31×42×4]=[3648]
在深度学习中的应用(PyTorch代码实现
import torch
# 定义两个向量
u = torch.tensor([1, 2, 3])
v = torch.tensor([4, 5, 6])
# 计算外积
outer_product = torch.outer(u, v)
print("外积结果:")
print(outer_product)
# 等价的矩阵乘法
matrix_m = u[:,None] @ v[None,:]
assert torch.allclose(outer_product ,matrix_m )
4、哈达玛积(Hadamard Product)
是矩阵的逐元素乘积,与点积、外积无关。
哈达玛积(Hadamard Product),也称为 逐元素乘积(Element-wise Product),是一种基本的矩阵/张量运算,广泛应用于深度学习、信号处理和数值计算等领域。它与矩阵乘法完全不同,核心在于 对应位置的元素相乘,而非行列点积。
定义和计算:
对于两个形状相同的矩阵 A , B ∈ R m × n \mathbf{A},\mathbf{B}\in\mathbb{R}^{m\times n} A,B∈Rm×n,它们的哈达玛积 C = A ∘ B \mathbf{C}=\mathbf{A}\circ\mathbf{B} C=A∘B定义为:
C i j = A i j × B i j , ∀ i ∈ { 1 , … , m } , j ∈ { 1 , … , n } C_{ij}=A_{ij}\times B_{ij},\quad\forall i\in\{1,\ldots,m\},j\in\{1,\ldots,n\} Cij=Aij×Bij,∀i∈{1,…,m},j∈{1,…,n}
符号表示:
- 哈达玛积常用符号 ∘ \circ ∘ 或 ⊙ \odot ⊙
- 在代码中通常用
*或逐元素乘法函数(如np.multiply、torch.mul)
特点:
- 输入要求:两个矩阵/张量必须形状完全相同(广播机制除外)
- 对应位置相乘,输出维度不变
在深度学习中的应用:
首先哈达玛积在python中用*运算符来表示:
A = torch.randn(2, 3) # [2, 3]
B = torch.randn(2, 3) # [2, 3]
hadamard = A * B # 或 torch.mul(A, B)
- 门控机制(如LSTM/GRU)
# input_gate: [batch, hidden], candidate: [batch, hidden]
new_state = input_gate * candidate # 逐元素相乘
- 注意力掩码(Transformer)
# scores: [batch, seq_len, seq_len], mask: [seq_len, seq_len]
masked_scores = scores * mask.unsqueeze(0) # 应用掩码
5、矩阵乘法( matrix multiplication)
矩阵乘法(Matrix Multiplication)是线性代数中的核心运算,也是深度学习中最基本、最重要的操作之一。它用于将两个矩阵(或更高维张量)按照特定规则相乘,生成一个新的矩阵。
定义和计算:
矩阵乘法定义为:对于矩阵
A
∈
R
m
×
n
\mathbf{A}\in\mathbb{R}^{m\times n}
A∈Rm×n 和
B
∈
R
n
×
p
\mathbf{B}\in\mathbb{R}^{n\times p}
B∈Rn×p ,它们的乘积
C
=
A
B
C = AB
C=AB或写成
C
=
A
×
B
C=A\times B
C=A×B ,是一个
m
×
p
m \times p
m×p形状的矩阵。其中每个元素
C
i
j
C_{ij}
Cij的计算如下:也就是
A
\mathbf{A}
A 的第
i
i
i 行向量和
B
\mathbf{B}
B 的第
j
j
j 列向量做点积(对应元素相乘再求和)。
C
i
j
=
∑
k
=
1
n
A
i
k
B
k
j
C_{ij}=\sum_{k=1}^nA_{ik}B_{kj}
Cij=k=1∑nAikBkj
- 矩阵 A A A行和矩阵 B B B的列必须相同
- 结果矩阵的 C C C的行数 = A A A的行数,列数 = B B B的列数
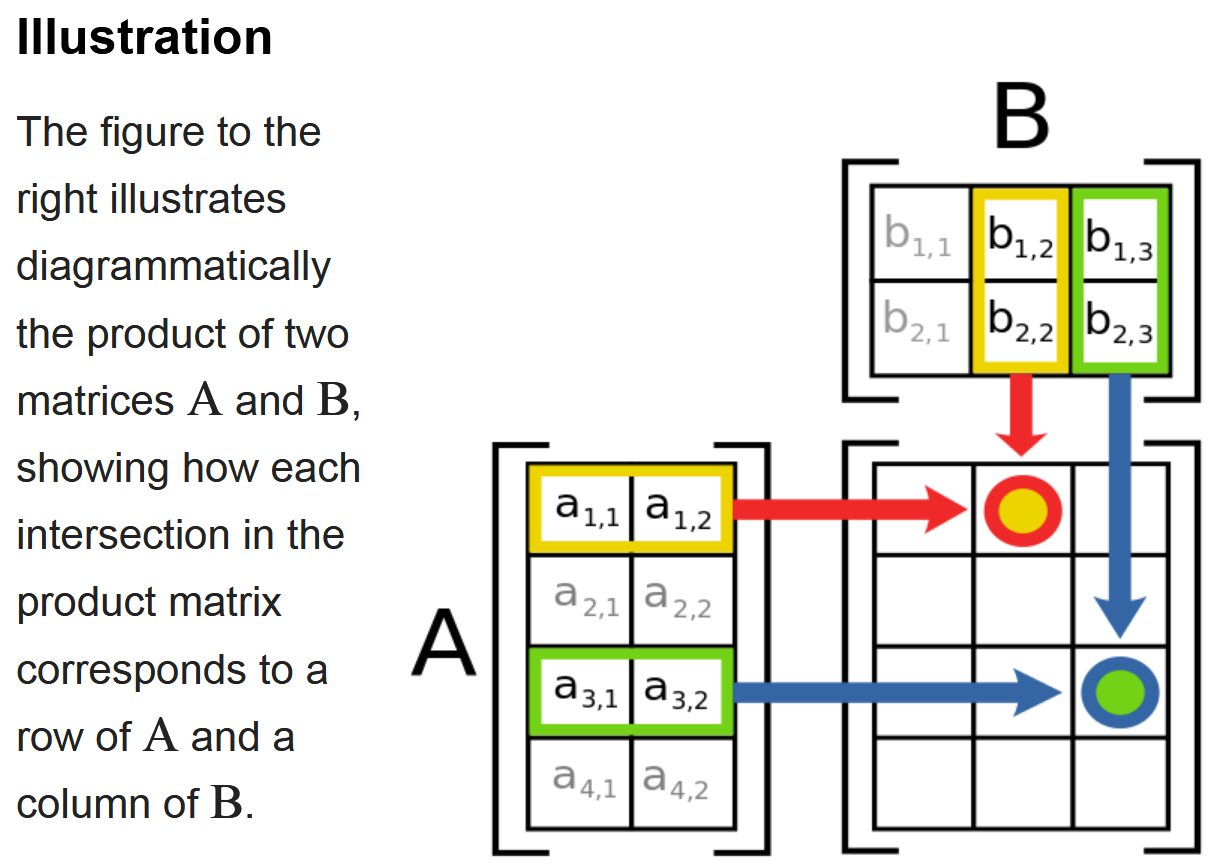
与内积的联系:
- 首先矩阵乘法的运算规则里面本来就包含了内积的概念,新矩阵的元素本来就由行向量和列向量最点积而来。
- 特殊情况:当矩阵退化为一维向量时,矩阵乘法就等同于内积。例如,对于两个一维向量
a
=
[
a
1
,
a
2
,
⋯
,
a
n
]
\mathbf{a}=[a_1,a_2,\cdots,a_n]
a=[a1,a2,⋯,an] 和
b
=
[
b
1
,
b
2
,
⋯
,
b
n
]
\mathbf{b}=[b_1,b_2,\cdots,b_n]
b=[b1,b2,⋯,bn],它们的内积
a
⋅
b
=
∑
i
=
1
n
a
i
b
i
\mathbf{a}\cdot\mathbf{b}=\sum_{i = 1}^{n}a_ib_i
a⋅b=∑i=1naibi,这可以看作是一个
1
×
n
1\times n
1×n 的矩阵和一个
n
×
1
n\times 1
n×1 的矩阵相乘。
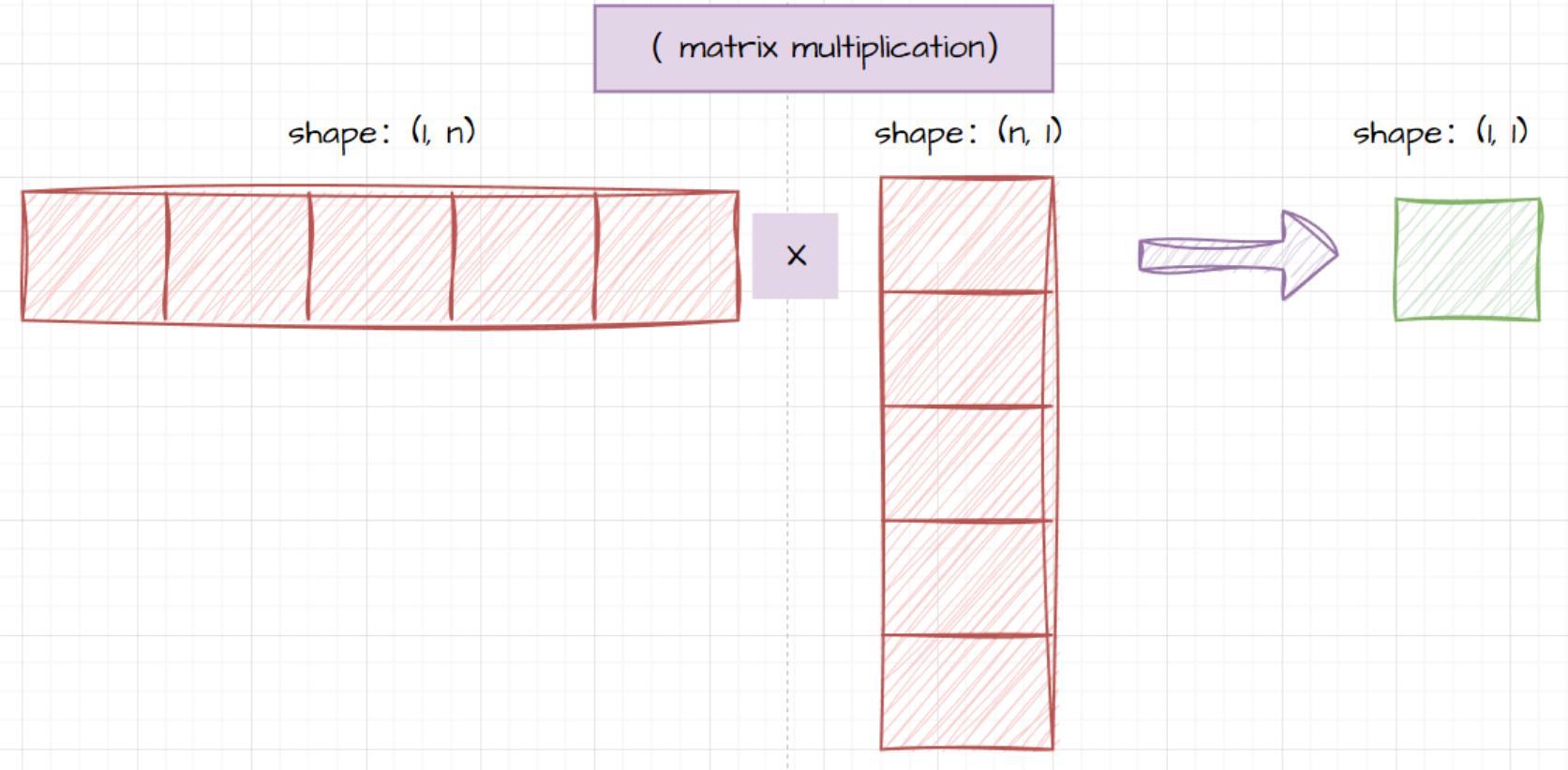
与外积的关联
- 矩阵乘法也能和外积联系起来。当一个列向量 a \mathbf{a} a(形状为 m × 1 m\times 1 m×1)和一个行向量 b \mathbf{b} b(形状为 1 × n 1\times n 1×n)相乘时,得到的结果是一个 m × n m\times n m×n 的矩阵,这个过程类似于外积的计算方式。
🙎🏻♀️几何意义
-
线性变换的组合:矩阵本身就可以代表一个线性的变换。在二维平面里,矩阵乘法可实现对二维向量的旋转、缩放、反射等几何变换。对于线性变换 A A A和 B B B, A B AB AB表示先应用 B B B的变换,再应用 A A A的变换


图片来源于B站视频:【【从0开始学广义相对论02】嫌矩阵运算难写?看看爱因斯坦怎么做的:Einstein求和约定】 https://www.bilibili.com/video/BV1LF411s7MX/?share_source=copy_web&vd_source=f81ef849101bd49f5953b524b903fdfb
-
空间映射(空间变换)⭐:将输入空间( R p \mathbb{R}^p Rp)通过 B B B映射到中间空间 ( R n ) (\mathbb{R}^n) (Rn),再通过 A A A映射到输出空间 ( R m ) (\mathbb{R}^m) (Rm)。
示例代码
import torch
# 创建两个矩阵
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6], [7, 8]])
# 进行矩阵乘法
C = torch.matmul(A, B)
C = torch.mm(A, B) # [3, 5] 或 A @ B
print(C)
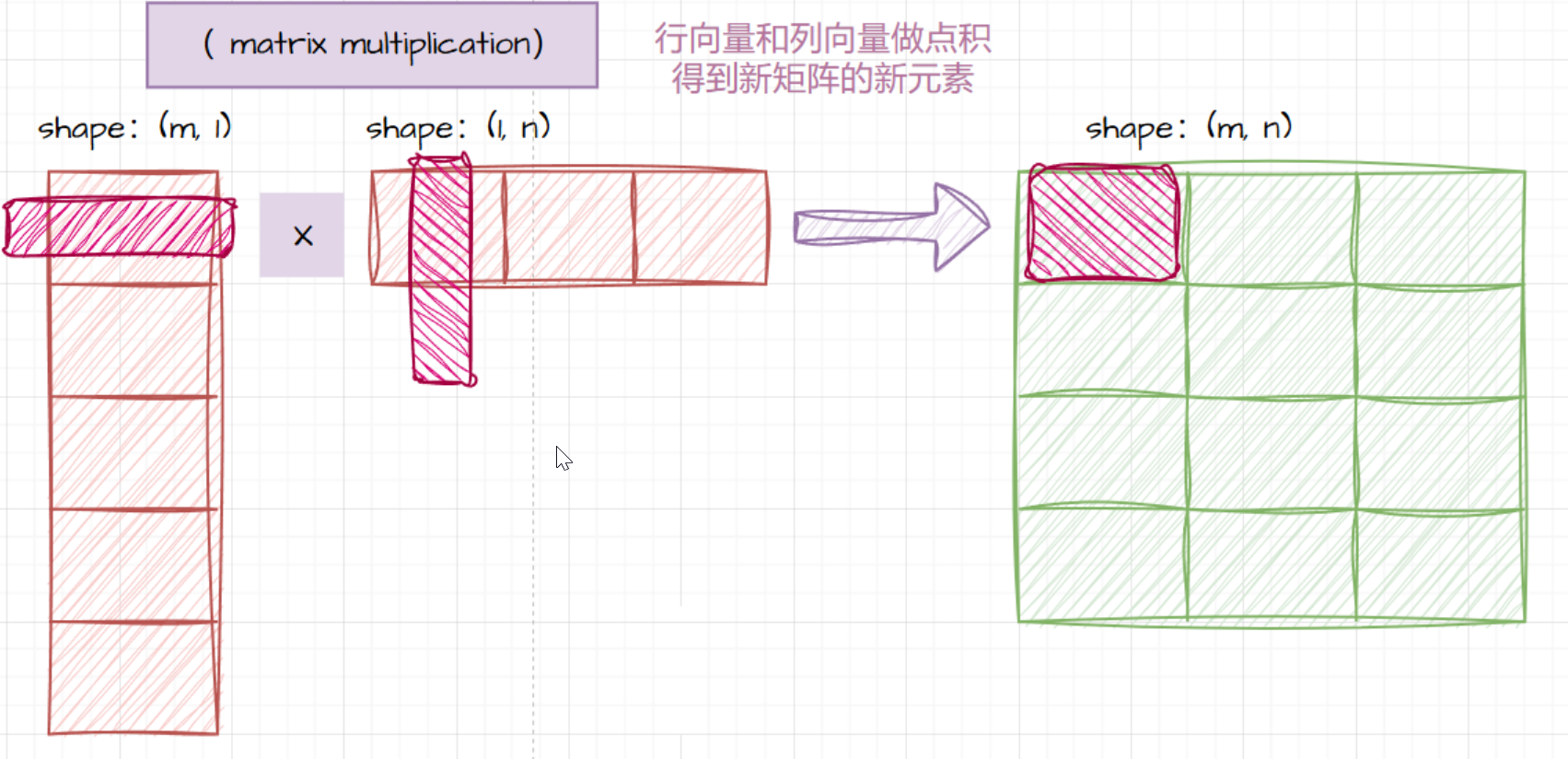
在这个例子中,矩阵 C \mathbf{C} C 的每个元素都是通过 A \mathbf{A} A 的行向量和 B \mathbf{B} B 的列向量做点积得到的。
torch.matmul 和 torch.mm 都可用于执行张量乘法,但它们存在一些区别
torch.mm:仅适用于二维张量(即矩阵)。若输入不是二维张量,会抛出错误。torch.matmul:支持更灵活的输入维度,可处理多种维度组合的张量乘法。具体规则如下:- 若两个输入都是一维张量,计算的是它们的点积(内积),返回一个标量。
- 若两个输入都是二维张量,执行的是常规的矩阵乘法,与
torch.mm效果相同。 - 若一个输入是一维张量,另一个是二维张量,会自动对一维张量进行维度扩展以完成矩阵乘法,结果为一维张量。
- 若输入张量的维度超过二维,
torch.matmul会将最后两个维度视为矩阵维度进行乘法,其他维度作为批量维度处理。
总结
对比总结表
| 运算 | 数学符号 | 代码实现(PyTorch) | 输入要求 | 输出规则 |
|---|---|---|---|---|
| 矩阵乘法 | A B \mathbf{A} \mathbf{B} AB | A @ B 或 torch.mm(A, B) | 前列=后行 | 行列点积求和 |
| 点积(内积) | u ⋅ v \mathbf{u} \cdot \mathbf{v} u⋅v | torch.dot(u, v) | 同维向量 | 标量 |
| 外积 | u ⊗ v \mathbf{u} \otimes \mathbf{v} u⊗v | torch.outer(u, v) | 任意两向量 | 矩阵(( \mathbf{u} \mathbf{v}^T )) |
| 哈达玛积 | A ∘ B \mathbf{A} \circ \mathbf{B} A∘B | A * B 或 torch.mul(A, B) | 同形状矩阵/张量 | 逐元素相乘 |
| 克罗内克积 | A ⊗ B \mathbf{A} \otimes \mathbf{B} A⊗B | torch.kron(A, B) | 任意两矩阵 | 分块扩展矩阵 |
| 逐元素除法 | A ⊘ B \mathbf{A} \oslash \mathbf{B} A⊘B | A / B 或 torch.div(A, B) | 同形状矩阵/张量 | 逐元素相除 |
关键点
- 矩阵乘法是深度学习最核心的运算(如全连接层、注意力机制)。
- 哈达玛积用于逐元素操作(如激活函数、掩码)。
- 外积和克罗内克积在特定场景(如推荐系统、量子计算)中非常有用。
- 代码中注意区分
*(哈达玛积)和@(矩阵乘法),这是常见的错误来源!
参考
- 点积、内积、外积、叉积、张量积——概念区分
- 豆包、Deepseek(感谢)