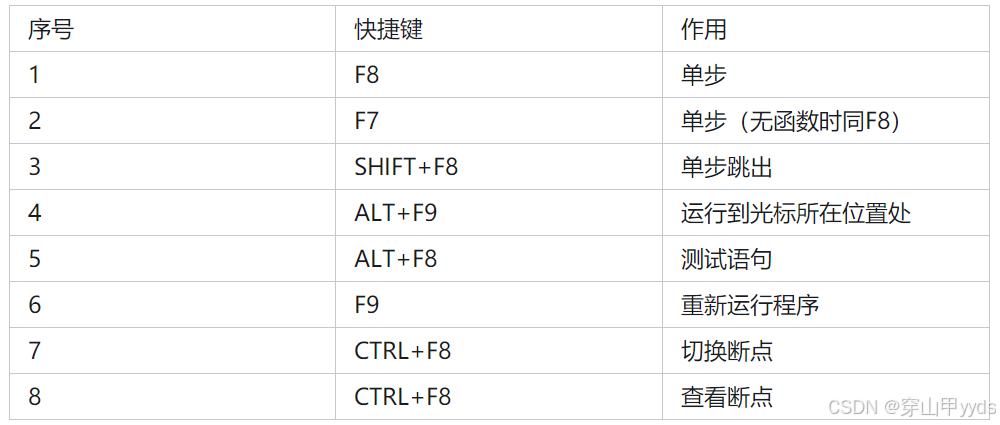
机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- 机器学习(Machine Learning)
- 简要声明
- 一、逻辑回归的基本原理
- 分类判断条件
- 模型输出的解释
- Sigmoid 函数与 Logistic 函数
- 逻辑回归模型的输出范围
- 实际应用示例
- 二、决策边界
- 决策边界的数学表达
- 线性决策边界示例
- 非线性决策边界
- 非线性决策边界的示例
- 三、代价函数
- 平方误差代价函数
- 逻辑回归的损失函数
- 损失函数的性质
- 逻辑回归的代价函数
- 代价函数的凸性
- 简化的损失函数
- 简化的代价函数
- 四、梯度下降实现
- 梯度下降算法
- 参数更新规则
- 偏导数计算
- 梯度下降步骤
- 梯度下降的实现细节
- 梯度下降的伪代码
- 向量化实现
- 特征缩放
一、逻辑回归的基本原理
逻辑回归是一种常用的分类算法,它可以将线性回归的输出映射到概率空间,从而实现二分类或多分类任务。其核心思想是通过一个线性函数来拟合数据,然后使用激活函数将其输出限制在 [0, 1] 区间内,表示为概率值。
逻辑回归模型的数学表达式为:
f w , b ( x ) = σ ( w x + b ) f_{w,b}(x) = \sigma(w x + b) fw,b(x)=σ(wx+b)
其中, f w , b ( x ) f_{w,b}(x) fw,b(x) 是模型的输出, w w w 和 b b b 分别是权重和偏置项, σ \sigma σ 是激活函数,通常使用 Sigmoid 函数,其定义为:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
通过 Sigmoid 函数,我们可以将线性回归的输出 z = w x + b z = wx + b z=wx+b 转换为概率值。当 z z z 很大时, σ ( z ) \sigma(z) σ(z) 接近于 1;当 z z z 很小时, σ ( z ) \sigma(z) σ(z) 接近于 0。

- 在单变量图中,阳性结果同时显示为红色的 ‘X’ 和 y=1。阴性结果为蓝色 ‘O’,位于 y=0 处。
在线性回归的情况下,y 不限于两个值,而是可以是任何值。 - 在双变量图中,y 轴不可用。正面结果显示为红色“X”,而负面结果则使用蓝色“O”符号。
在具有多个变量的线性回归的情况下,y 不会局限于两个值,而类似的图应该是三维的。
分类判断条件
在分类任务中,根据模型的输出来判断样本的类别。逻辑回归模型的分类判断条件如下:
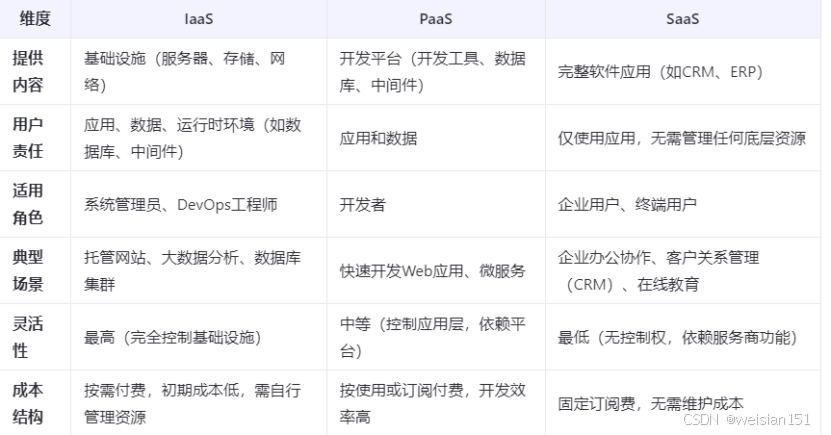
| 条件 | 分类结果 |
|---|---|
| f w , b ( x ) ≥ 0.5 f_{w,b}(x) \geq 0.5 fw,b(x)≥0.5 | y ^ = 1 \hat{y} = 1 y^=1 |
| f w , b ( x ) < 0.5 f_{w,b}(x) < 0.5 fw,b(x)<0.5 | y ^ = 0 \hat{y} = 0 y^=0 |
决策边界的选择会影响模型的分类结果,可能需要根据具体问题调整。
模型输出的解释
逻辑回归模型的输出可以解释为样本属于正类(1)的概率。数学表达式为:
f w → , b ( x → ) = P ( y = 1 ∣ x → ; w → , b ) f_{\overrightarrow{w}, b}(\overrightarrow{x}) = P(y = 1 | \overrightarrow{x}; \overrightarrow{w}, b) fw,b(x)=P(y=1∣x;w,b)
这意味着,给定输入特征 x → \overrightarrow{x} x 和模型参数 w → , b \overrightarrow{w}, b w,b,模型输出的是样本 y y y 属于正类(1)的概率。例如,如果 f w → , b ( x → ) = 0.7 f_{\overrightarrow{w}, b}(\overrightarrow{x}) = 0.7 fw,b(x)=0.7,表示模型预测该样本有 70% 的概率属于正类(1)。
由于概率的性质,我们有:
P ( y = 0 ) + P ( y = 1 ) = 1 P(y = 0) + P(y = 1) = 1 P(y=0)+P(y=1)=1
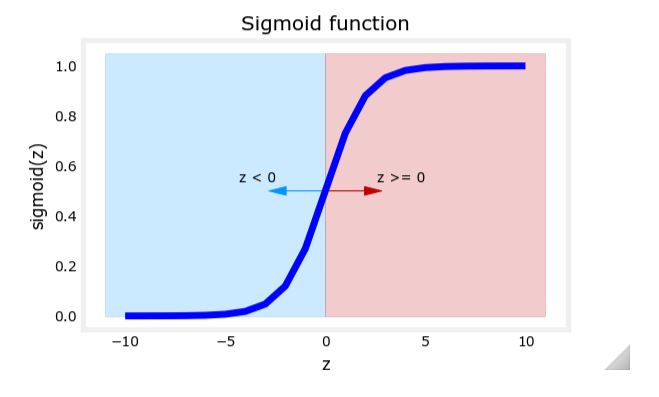
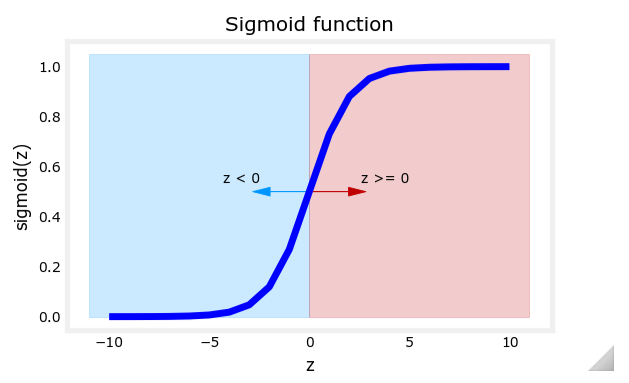
Sigmoid 函数与 Logistic 函数
为了将线性回归的输出限制在 [0, 1] 区间内,逻辑回归使用了 Sigmoid 函数(也称为 Logistic 函数)。其数学定义为:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1 + e^{-z}} g(z)=1+e−z1
其中, z z z 是线性回归的输出,即:
z = w → ⋅ x → + b z = \overrightarrow{w} \cdot \overrightarrow{x} + b z=w⋅x+b
通过 Sigmoid 函数,线性回归的输出被转换为概率值。Sigmoid 函数的曲线显示,当
z
z
z 很大时,
g
(
z
)
g(z)
g(z) 接近于 1;当
z
z
z 很小时,
g
(
z
)
g(z)
g(z) 接近于 0。
逻辑回归模型的输出范围
逻辑回归模型的输出范围在 0 和 1 之间,得益于 Sigmoid 函数的特性:
0 < g ( z ) < 1 0 < g(z) < 1 0<g(z)<1
因此,逻辑回归模型的输出可以解释为概率值,表示样本属于正类(1)的可能性。
# Generate an array of evenly spaced values between -10 and 10
z_tmp = np.arange(-10,11)
y = sigmoid(z_tmp)
np.set_printoptions(precision=3)
print("Input (z), Output (sigmoid(z))")
print(np.c_[z_tmp, y])
输出结果为

实际应用示例
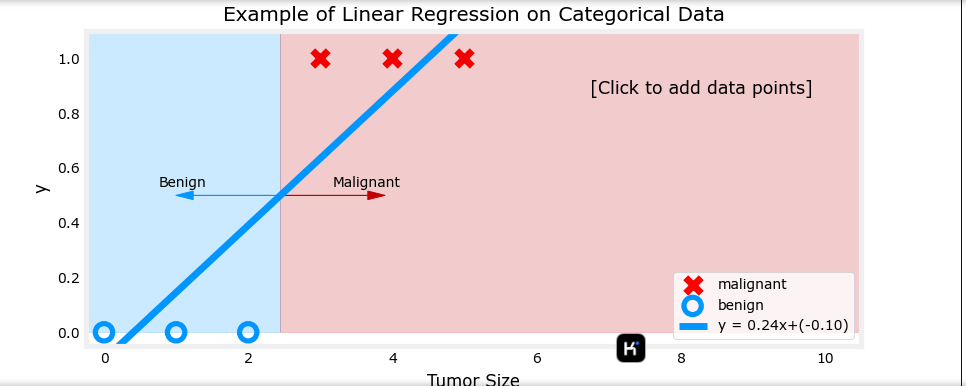
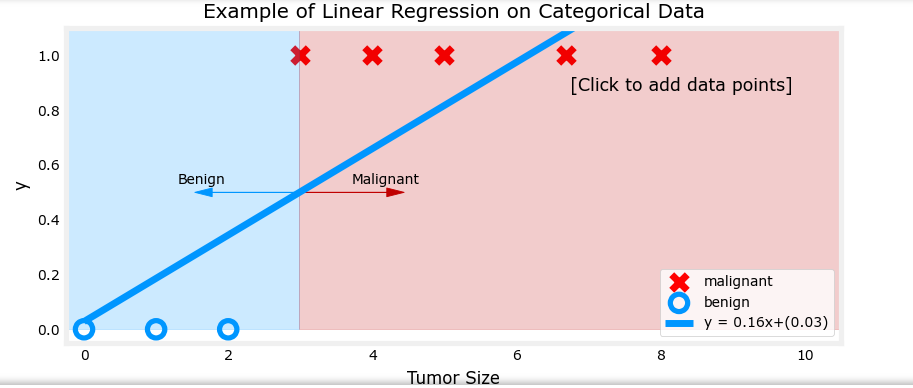
可以看见线性函数受数据影响很大
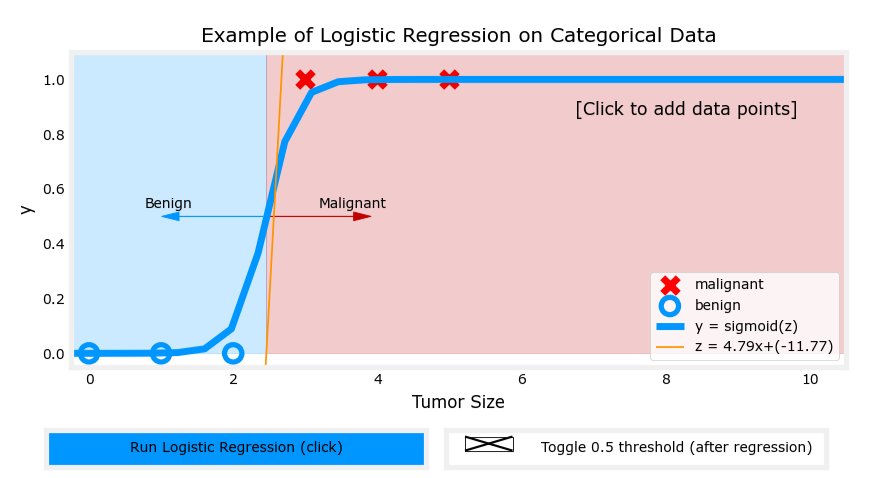
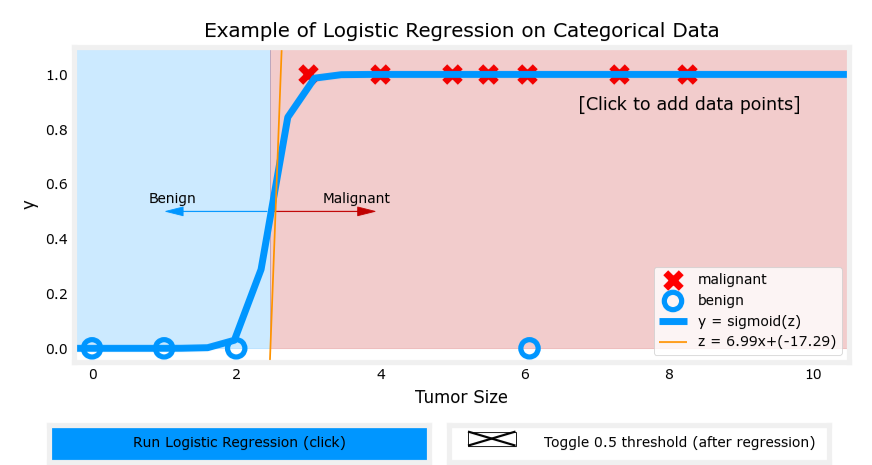
逻辑函数很好地拟合了数据
以肿瘤大小(直径,单位为厘米)为输入特征 x x x,肿瘤是否为恶性(1 表示恶性,0 表示良性)为输出 y y y。逻辑回归模型可以预测给定肿瘤大小的情况下,肿瘤为恶性的概率。
例如,假设模型预测当肿瘤大小为某个值时, f w → , b ( x → ) = 0.7 f_{\overrightarrow{w}, b}(\overrightarrow{x}) = 0.7 fw,b(x)=0.7,意味着模型认为该肿瘤有 70% 的概率为恶性。
二、决策边界
在逻辑回归中,决策边界是模型用于划分不同类别样本的边界。对于二分类任务,决策边界通常是一个阈值,例如 0.5。当模型输出大于等于 0.5 时,我们预测样本属于正类(1);当模型输出小于 0.5 时,我们预测样本属于负类(0)。
决策边界的选择对于模型的性能至关重要。在实际应用中,我们可能需要根据具体问题调整决策边界,以平衡精度和召回率。
决策边界的数学表达
决策边界的数学表达式为:
f w → , b ( x → ) ≥ 0.5 f_{\overrightarrow{w}, b}(\overrightarrow{x}) \geq 0.5 fw,b(x)≥0.5
根据 Sigmoid 函数的性质,当且仅当线性组合 z = w → ⋅ x → + b ≥ 0 z = \overrightarrow{w} \cdot \overrightarrow{x} + b \geq 0 z=w⋅x+b≥0 时, g ( z ) ≥ 0.5 g(z) \geq 0.5 g(z)≥0.5。因此,决策边界可以表示为:
w
→
⋅
x
→
+
b
=
0
\overrightarrow{w} \cdot \overrightarrow{x} + b = 0
w⋅x+b=0
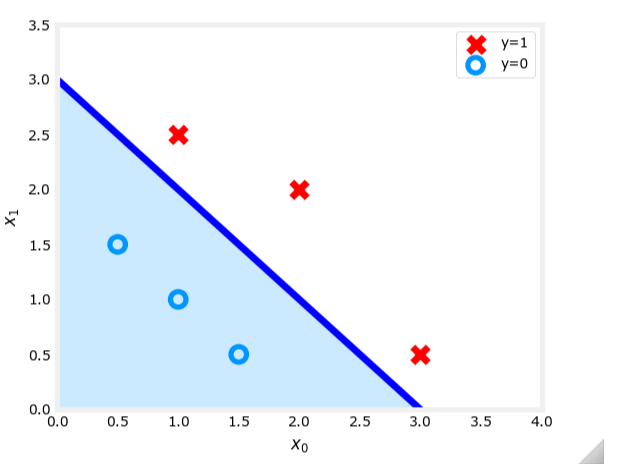
线性决策边界示例
假设我们有一个二维特征空间,其中 x 1 x_1 x1 和 x 2 x_2 x2 是两个特征。决策边界可以表示为:
w 1 x 1 + w 2 x 2 + b = 0 w_1 x_1 + w_2 x_2 + b = 0 w1x1+w2x2+b=0
例如,假设 w 1 = 1 w_1 = 1 w1=1, w 2 = 1 w_2 = 1 w2=1, b = − 3 b = -3 b=−3,则决策边界为:
x 1 + x 2 − 3 = 0 x_1 + x_2 - 3 = 0 x1+x2−3=0
即:
x 1 + x 2 = 3 x_1 + x_2 = 3 x1+x2=3
这个决策边界将特征空间划分为两个区域:当
x
1
+
x
2
≥
3
x_1 + x_2 \geq 3
x1+x2≥3 时,预测
y
^
=
1
\hat{y} = 1
y^=1;否则预测
y
^
=
0
\hat{y} = 0
y^=0。
非线性决策边界
逻辑回归模型也可以处理非线性决策边界。通过引入多项式特征,我们可以构造更复杂的决策边界。例如:
z = w 1 x 1 2 + w 2 x 2 2 + b z = w_1 x_1^2 + w_2 x_2^2 + b z=w1x12+w2x22+b
决策边界为:
w 1 x 1 2 + w 2 x 2 2 + b = 0 w_1 x_1^2 + w_2 x_2^2 + b = 0 w1x12+w2x22+b=0
例如,假设 w 1 = 1 w_1 = 1 w1=1, w 2 = 1 w_2 = 1 w2=1, b = − 1 b = -1 b=−1,则决策边界为:
x 1 2 + x 2 2 − 1 = 0 x_1^2 + x_2^2 - 1 = 0 x12+x22−1=0
即:
x 1 2 + x 2 2 = 1 x_1^2 + x_2^2 = 1 x12+x22=1
这个决策边界是一个半径为 1 的圆,将特征空间划分为内部和外部两个区域:当 x 1 2 + x 2 2 ≥ 1 x_1^2 + x_2^2 \geq 1 x12+x22≥1 时,预测 y ^ = 1 \hat{y} = 1 y^=1;否则预测 y ^ = 0 \hat{y} = 0 y^=0。
非线性决策边界的示例
考虑一个更复杂的非线性决策边界:
z = w 1 x 1 2 + w 2 x 2 2 + w 3 x 1 3 + w 4 x 1 x 2 + w 5 x 2 3 + b z = w_1 x_1^2 + w_2 x_2^2 + w_3 x_1^3 + w_4 x_1 x_2 + w_5 x_2^3 + b z=w1x12+w2x22+w3x13+w4x1x2+w5x23+b
决策边界为:
w 1 x 1 2 + w 2 x 2 2 + w 3 x 1 3 + w 4 x 1 x 2 + w 5 x 2 3 + b = 0 w_1 x_1^2 + w_2 x_2^2 + w_3 x_1^3 + w_4 x_1 x_2 + w_5 x_2^3 + b = 0 w1x12+w2x22+w3x13+w4x1x2+w5x23+b=0
这个决策边界可以是椭圆、圆形或其他复杂的形状,具体取决于参数的选择。
决策边界是逻辑回归模型用于划分不同类别样本的边界。对于线性可分的数据,决策边界是一个线性方程;对于非线性可分的数据,可以通过引入多项式特征来构造非线性决策边界。
在实际应用中,合理选择决策边界对于提高模型的分类性能至关重要。通过调整模型参数,我们可以使决策边界更好地适应数据的分布。
三、代价函数
平方误差代价函数
在逻辑回归中,如果我们直接使用线性回归的平方误差代价函数:
J ( w → , b ) = 1 m ∑ i = 1 m 1 2 ( f w → , b ( x → ( i ) ) − y ( i ) ) 2 J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} \frac{1}{2} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)})^2 J(w,b)=m1i=1∑m21(fw,b(x(i))−y(i))2
其中, f w → , b ( x → ) = w → ⋅ x → + b f_{\overrightarrow{w}, b}(\overrightarrow{x}) = \overrightarrow{w} \cdot \overrightarrow{x} + b fw,b(x)=w⋅x+b 是线性回归模型的输出。
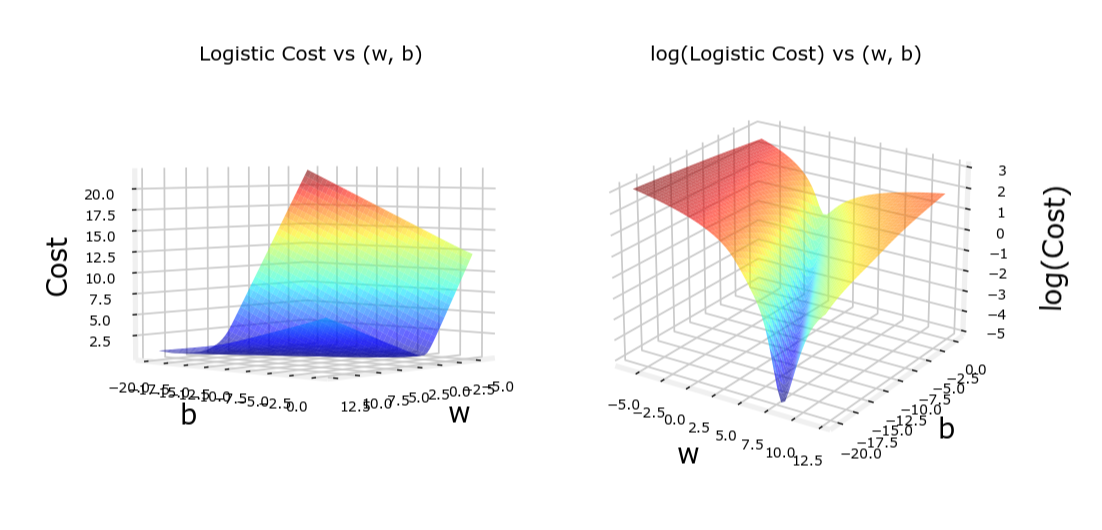
然而,对于逻辑回归,这种代价函数可能会导致非凸问题,使得梯度下降算法难以收敛到全局最小值。
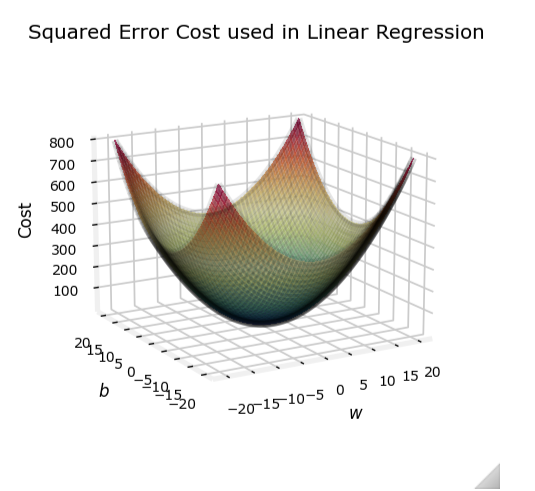
线性回归
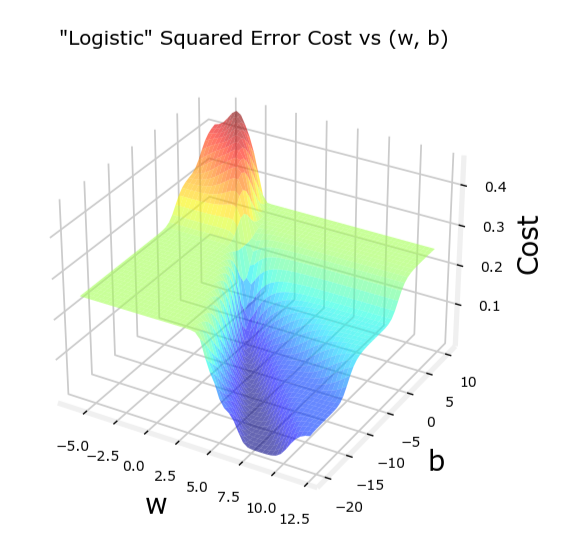
并不像线性回归的“汤碗”那么光滑
逻辑回归的损失函数
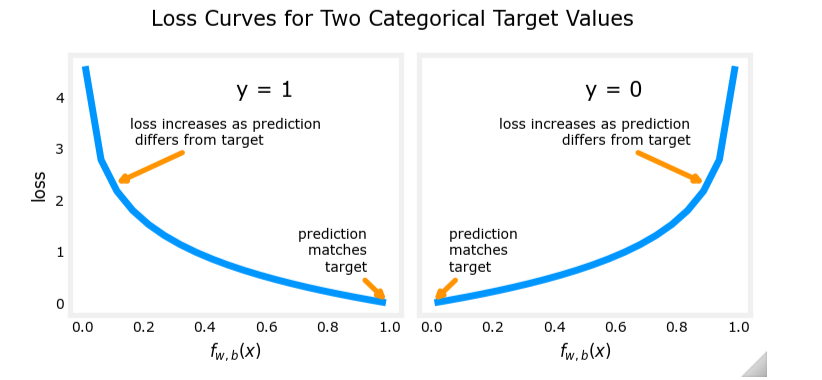
为了解决这个问题,逻辑回归采用了不同的损失函数。对于单个训练样本 ( x → ( i ) , y ( i ) ) (\overrightarrow{x}^{(i)}, y^{(i)}) (x(i),y(i)),逻辑回归的损失函数定义为:
L ( f w → , b ( x → ( i ) ) , y ( i ) ) = { − l o g ( f w → , b ( x → ( i ) ) ) if y ( i ) = 1 − l o g ( 1 − f w → , b ( x → ( i ) ) ) if y ( i ) = 0 L(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}), y^{(i)}) = \begin{cases} -log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 1 \\ -log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 0 \end{cases} L(fw,b(x(i)),y(i))={−log(fw,b(x(i)))−log(1−fw,b(x(i)))if y(i)=1if y(i)=0
其中, f w → , b ( x → ) = 1 1 + e − ( w → ⋅ x → + b ) f_{\overrightarrow{w}, b}(\overrightarrow{x}) = \frac{1}{1 + e^{-(\overrightarrow{w} \cdot \overrightarrow{x} + b)}} fw,b(x)=1+e−(w⋅x+b)1 是逻辑回归模型的输出。
损失函数的性质
-
当 y ( i ) = 1 y^{(i)} = 1 y(i)=1 时:
- 如果 f w → , b ( x → ( i ) ) → 1 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 1 fw,b(x(i))→1,损失 → 0 \to 0 →0
- 如果 f w → , b ( x → ( i ) ) → 0 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 0 fw,b(x(i))→0,损失 → ∞ \to \infty →∞
-
当 y ( i ) = 0 y^{(i)} = 0 y(i)=0 时:
- 如果 f w → , b ( x → ( i ) ) → 0 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 0 fw,b(x(i))→0,损失 → 0 \to 0 →0
- 如果 f w → , b ( x → ( i ) ) → 1 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 1 fw,b(x(i))→1,损失 → ∞ \to \infty →∞
这种损失函数的设计使得模型在预测错误时付出更大的代价,从而激励模型尽可能准确地预测。
逻辑回归的代价函数
逻辑回归的代价函数是所有训练样本损失的平均值:
J ( w → , b ) = 1 m ∑ i = 1 m L ( f w → , b ( x → ( i ) ) , y ( i ) ) J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} L(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}), y^{(i)}) J(w,b)=m1i=1∑mL(fw,b(x(i)),y(i))
展开后为:
J ( w → , b ) = 1 m ∑ i = 1 m { − l o g ( f w → , b ( x → ( i ) ) ) if y ( i ) = 1 − l o g ( 1 − f w → , b ( x → ( i ) ) ) if y ( i ) = 0 J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} \begin{cases} -log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 1 \\ -log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 0 \end{cases} J(w,b)=m1i=1∑m{−log(fw,b(x(i)))−log(1−fw,b(x(i)))if y(i)=1if y(i)=0
代价函数的凸性
逻辑回归的代价函数是凸的,这意味着它只有一个全局最小值,梯度下降算法可以保证收敛到这个全局最小值。
相比之下,平方误差代价函数在逻辑回归中可能会导致非凸问题,使得梯度下降算法陷入局部最小值。
简化的损失函数
逻辑回归的损失函数可以简化为一个统一的表达式:
L ( f w → , b ( x → ( i ) ) , y ( i ) ) = − y ( i ) log ( f w → , b ( x → ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w → , b ( x → ( i ) ) ) L(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}), y^{(i)}) = - y^{(i)} \log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) - (1 - y^{(i)}) \log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) L(fw,b(x(i)),y(i))=−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))
这个表达式结合了两种情况:
- 当 y ( i ) = 1 y^{(i)} = 1 y(i)=1 时,损失函数为 − log ( f w → , b ( x → ( i ) ) ) - \log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) −log(fw,b(x(i)))
- 当 y ( i ) = 0 y^{(i)} = 0 y(i)=0 时,损失函数为 − log ( 1 − f w → , b ( x → ( i ) ) ) - \log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) −log(1−fw,b(x(i)))
简化的代价函数
逻辑回归的代价函数也可以相应地简化为:
J ( w → , b ) = − 1 m ∑ i = 1 m [ y ( i ) log ( f w → , b ( x → ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − f w → , b ( x → ( i ) ) ) ] J(\overrightarrow{w}, b) = - \frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) + (1 - y^{(i)}) \log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) \right] J(w,b)=−m1i=1∑m[y(i)log(fw,b(x(i)))+(1−y(i))log(1−fw,b(x(i)))]
这个代价函数实际上是对数似然函数的负数,因此最小化这个代价函数等价于最大化似然函数。这种方法被称为 最大似然估计(Maximum Likelihood Estimation)。
逻辑回归采用了不同于线性回归的损失函数,以适应分类问题的特点。其代价函数是凸的,保证了梯度下降算法可以收敛到全局最小值。通过最小化这个代价函数,我们可以找到最优的模型参数,使模型在训练数据上的表现最佳。
四、梯度下降实现
梯度下降算法
梯度下降是一种常用的优化算法,用于最小化代价函数。在逻辑回归中,我们使用梯度下降来更新模型参数 w j w_j wj 和 b b b,以最小化代价函数 J ( w → , b ) J(\overrightarrow{w}, b) J(w,b)。
参数更新规则
梯度下降的参数更新规则如下:
w j = w j − α ∂ ∂ w j J ( w → , b ) w_j = w_j - \alpha \frac{\partial}{\partial w_j} J(\overrightarrow{w}, b) wj=wj−α∂wj∂J(w,b)
b = b − α ∂ ∂ b J ( w → , b ) b = b - \alpha \frac{\partial}{\partial b} J(\overrightarrow{w}, b) b=b−α∂b∂J(w,b)
其中, α \alpha α 是学习率,控制每次更新的步长。
偏导数计算
对于逻辑回归,代价函数 J ( w → , b ) J(\overrightarrow{w}, b) J(w,b) 对 w j w_j wj 和 b b b 的偏导数分别为:
∂ ∂ w j J ( w → , b ) = 1 m ∑ i = 1 m ( f w → , b ( x → ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial}{\partial w_j} J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)}) x_j^{(i)} ∂wj∂J(w,b)=m1i=1∑m(fw,b(x(i))−y(i))xj(i)
∂ ∂ b J ( w → , b ) = 1 m ∑ i = 1 m ( f w → , b ( x → ( i ) ) − y ( i ) ) \frac{\partial}{\partial b} J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)}) ∂b∂J(w,b)=m1i=1∑m(fw,b(x(i))−y(i))
梯度下降步骤
- 初始化参数:随机初始化 w j w_j wj 和 b b b。
- 重复直到收敛:
- 计算当前参数下的代价函数值。
- 计算每个参数的梯度。
- 更新参数 w j w_j wj 和 b b b。
- 终止条件:当代价函数的变化小于某个阈值或达到最大迭代次数时,停止迭代。
梯度下降的实现细节
梯度下降的伪代码
Initialize w_j and b randomly
Repeat {
Compute gradients dw_j and db
Update w_j = w_j - alpha * dw_j
Update b = b - alpha * db
} until convergence
向量化实现
为了提高计算效率,梯度下降可以向量化实现,即同时更新所有参数:
w → = w → − α 1 m X → T ( f w → , b ( X → ) − y → ) \overrightarrow{w} = \overrightarrow{w} - \alpha \frac{1}{m} \overrightarrow{X}^T (f_{\overrightarrow{w}, b}(\overrightarrow{X}) - \overrightarrow{y}) w=w−αm1XT(fw,b(X)−y)
b = b − α 1 m ∑ i = 1 m ( f w → , b ( x → ( i ) ) − y ( i ) ) b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)}) b=b−αm1i=1∑m(fw,b(x(i))−y(i))
特征缩放
在梯度下降中,特征缩放(如标准化或归一化)可以加速收敛。常见的特征缩放方法包括:
- 标准化:将特征值转换为均值为 0,标准差为 1 的分布。
- 归一化:将特征值缩放到 [0, 1] 或 [-1, 1] 区间。
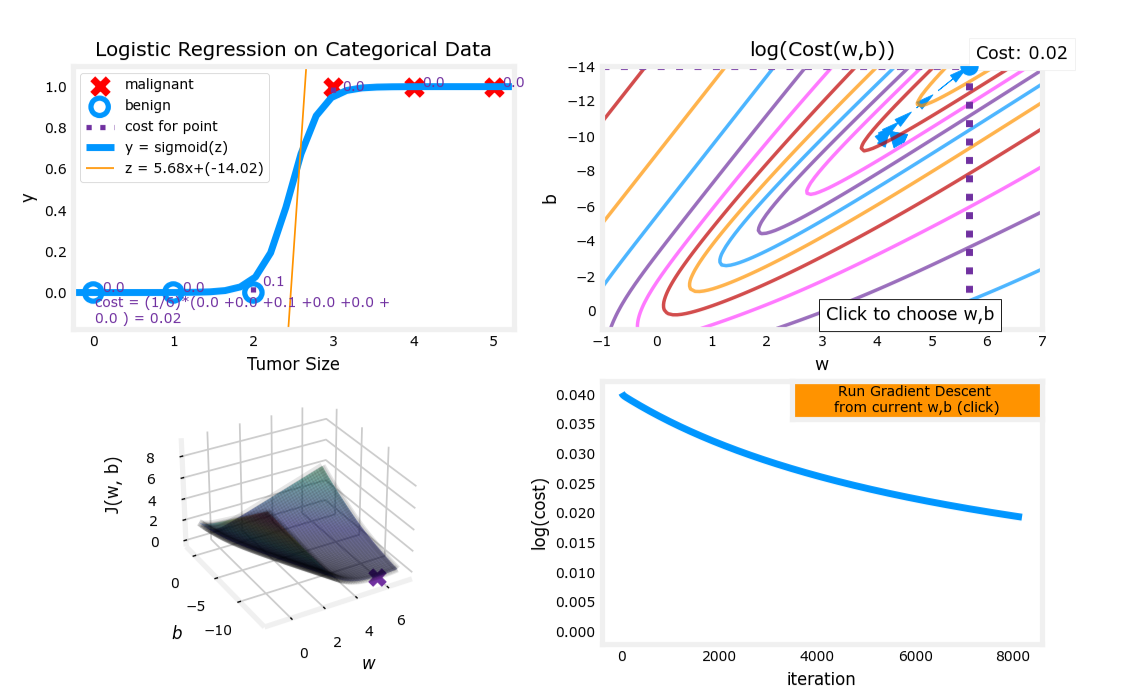
可视化梯度下降示例

![[免费]SpringBoot+Vue博物馆(预约)管理系统【论文+源码+SQL脚本】](https://i-blog.csdnimg.cn/direct/6e930f3dde3c4f2bb9cf4501c8642e1c.jpeg)