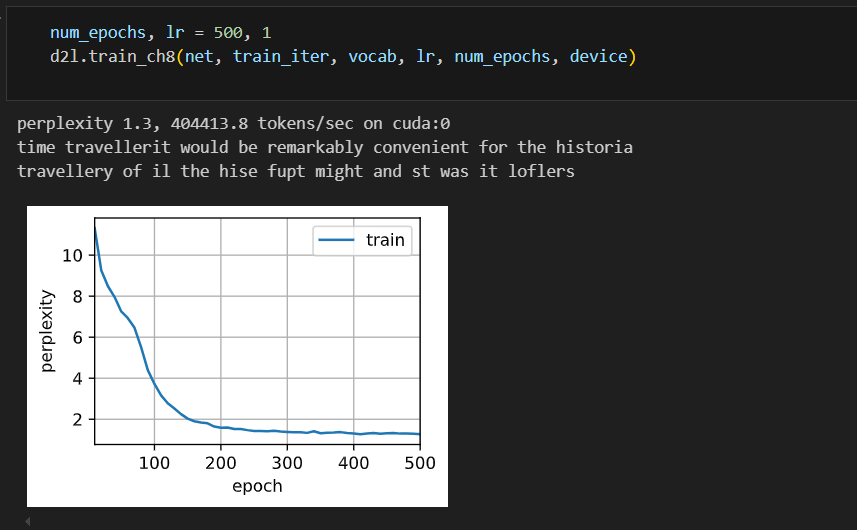
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git
一、RNN
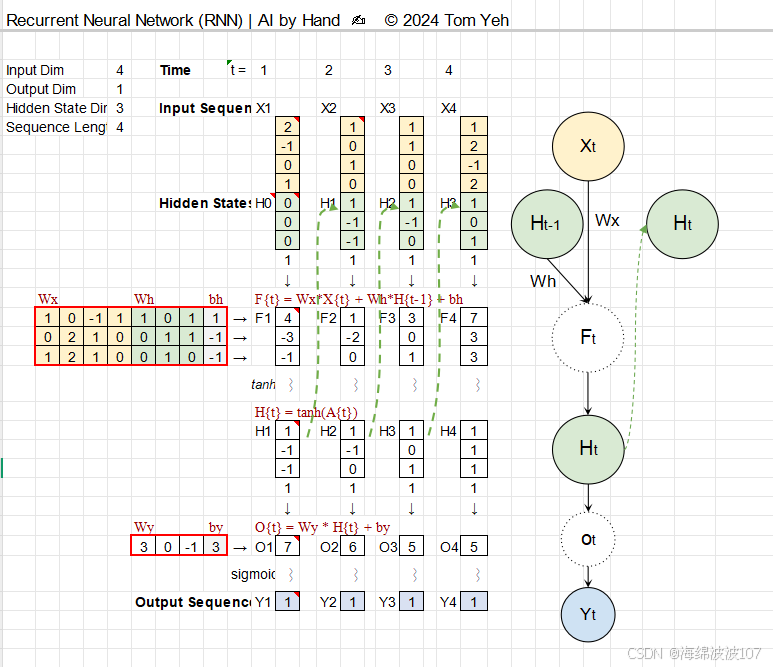
1. RNN 的核心思想
RNN 的设计初衷是处理序列数据(如时间序列、文本、语音),其核心特点是:
-
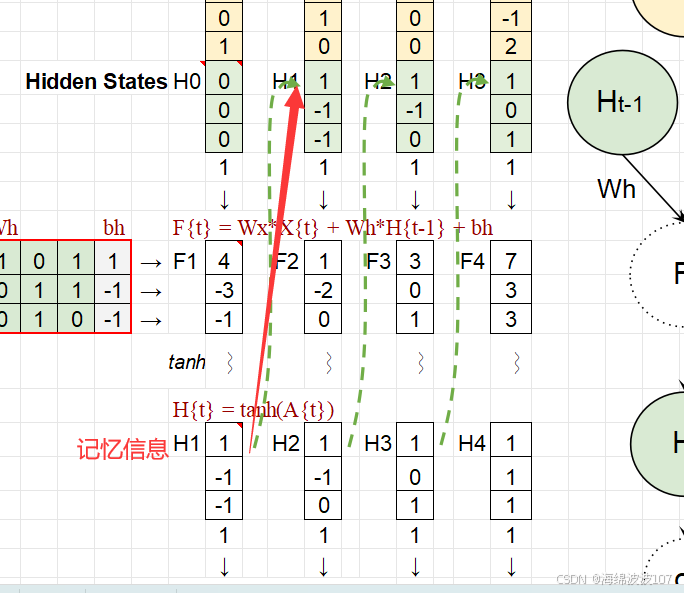
隐藏状态(Hidden State):保留历史信息,充当“记忆”。
-
参数共享:同一组权重在时间步间重复使用,减少参数量。
2. RNN 的数学表达
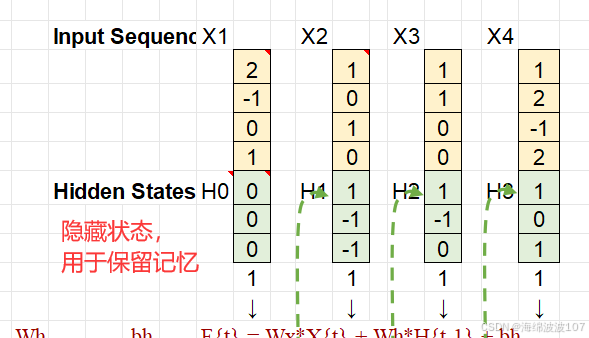
对于一个时间步 t:
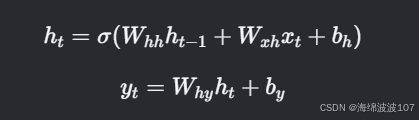
-
输入:xt(当前时间步的输入向量)。
-
隐藏状态:ht(当前状态),ht−1(上一状态)。
-
输出:yt(预测或特征表示)。
-
参数:权重矩阵 和偏置 。
-
激活函数:σ(通常为
tanh或ReLU)。
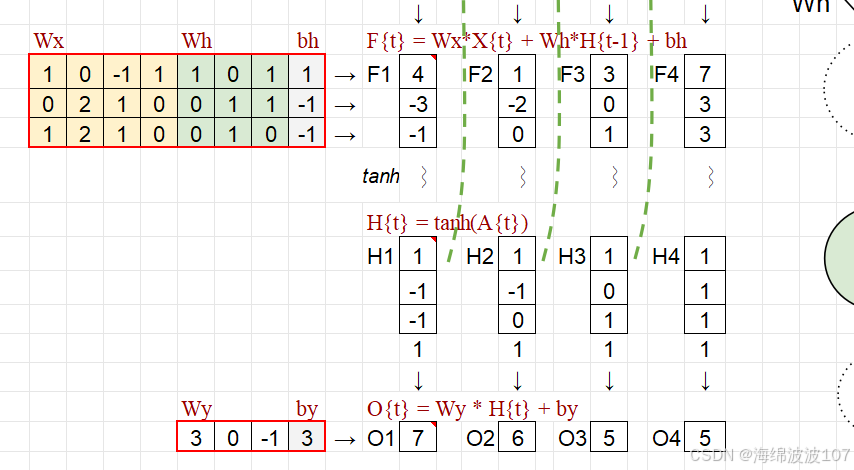
更新隐藏状态的核心操作
数学本质:非线性变换
-
At 是当前时间步的“未激活状态”,即隐藏状态的线性变换结果(上一状态 ht−1 和当前输入 xt 的加权和)。
-
tanh 是双曲正切激活函数,将 At 映射到 [-1, 1] 的范围内:
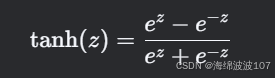
-
作用:引入非线性,使RNN能够学习复杂的序列模式。如果没有非线性,堆叠的RNN层会退化为单层线性变换。
梯度稳定性
-
tanhtanh 的导数为:

-
梯度值始终小于等于1,能缓解梯度爆炸(但可能加剧梯度消失)。
-
相比Sigmoid(导数最大0.25),tanhtanh 的梯度更大,训练更稳定。
3. RNN 的工作流程
前向传播
-
初始化隐藏状态 ℎ0h0(通常为零向量)。
-
按时间步迭代计算:
-
结合当前输入 xt 和上一状态 ht−1 更新状态 ht。
-
根据ht 生成输出 yt。
-
反向传播(BPTT)
通过时间反向传播(Backpropagation Through Time, BPTT)计算梯度:
-
沿时间轴展开RNN,类似多层前馈网络。
-
梯度需跨时间步传递,易导致梯度消失/爆炸。
4. RNN 的典型结构
(1) 单向RNN(Vanilla RNN)
-
信息单向流动(过去→未来)。
-
只能捕捉左侧上下文。
(2) 双向RNN(Bi-RNN)
-
两个独立的RNN分别从左到右和从右到左处理序列。
-
最终输出拼接或求和,捕捉双向依赖。
(3) 深度RNN(Stacked RNN)
-
多个RNN层堆叠,高层处理低层的输出序列。
-
增强模型表达能力。
5. RNN 的局限性
(1) 梯度消失/爆炸
-
长序列中,梯度连乘导致指数级衰减或增长。
-
后果:难以学习长期依赖(如文本中相距很远的词关系)。
(2) 记忆容量有限
-
隐藏状态维度固定,可能丢失早期信息。
(3) 计算效率低
-
无法并行处理序列(必须逐时间步计算)。
6. RNN 的代码实现(PyTorch)
import torch.nn as nn
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x: [batch_size, seq_len, input_size]
out, h_n = self.rnn(x) # out: 所有时间步的输出
y = self.fc(out[:, -1, :]) # 取最后一个时间步
return y7. RNN vs. 其他序列模型
| 特性 | RNN/LSTM | Transformer | Mamba |
|---|---|---|---|
| 长序列处理 | 中等(依赖门控) | 差(O(N2)) | 优(O(N)) |
| 并行化 | 不可并行 | 完全并行 | 部分并行 |
| 记忆机制 | 隐藏状态 | 全局注意力 | 选择性状态 |
8. RNN 的应用场景
-
文本生成:字符级或词级预测。
-
时间序列预测:股票价格、天气数据。
-
语音识别:音频帧序列转文本。
二、mamba
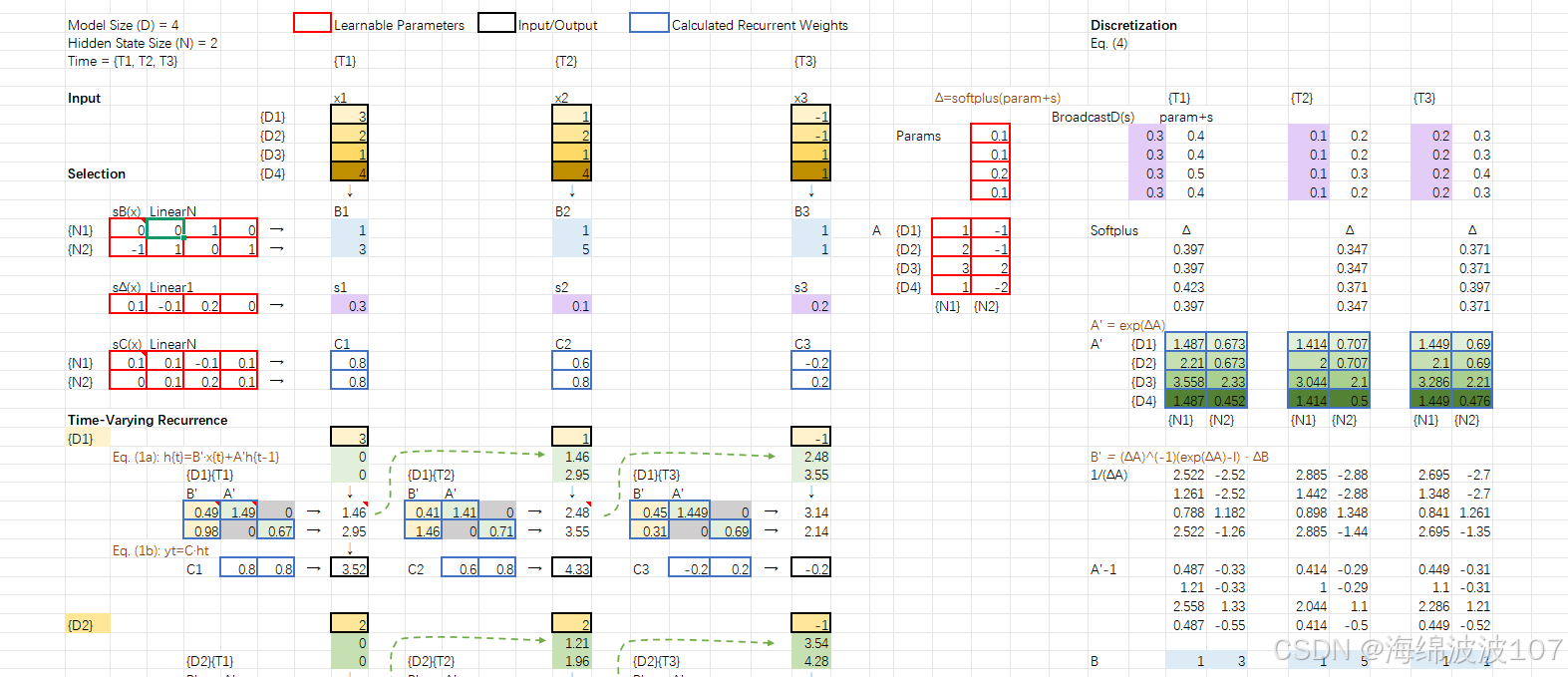
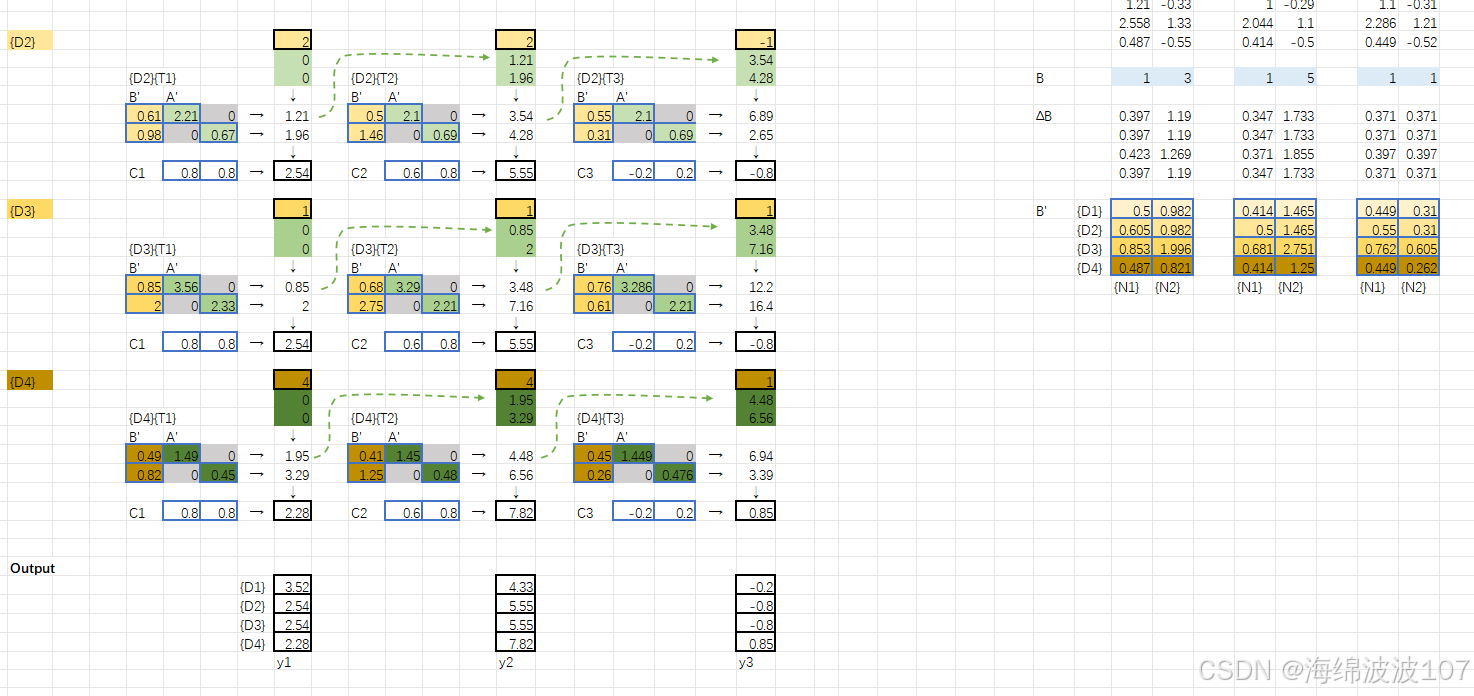
1. Mamba 的诞生背景
Mamba(2023年由Albert Gu等人提出)是为了解决传统序列模型(如RNN、Transformer)的两大痛点:
-
长序列效率问题:Transformer的Self-Attention计算复杂度为 O(N2),难以处理超长序列(如DNA、音频)。
-
状态压缩的局限性:RNN(如LSTM)虽能线性复杂度 O(N),但隐藏状态难以有效捕捉长期依赖。
Mamba的核心创新:选择性状态空间模型(Selective SSM),结合了RNN的效率和Transformer的表达力。
2. 状态空间模型(SSM)基础
Mamba基于结构化状态空间序列模型(S4),其核心是线性时不变(LTI)系统:
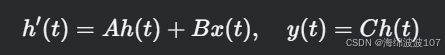
-
h(t):隐藏状态
-
A(状态矩阵)、B(输入矩阵)、C(输出矩阵)
-
离散化(通过零阶保持法):
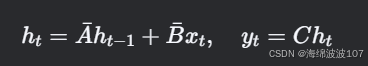
其中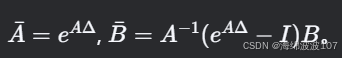
关键特性:
-
线性复杂度 O(N)(类似RNN)。
-
理论上能建模无限长依赖(通过HiPPO初始化 A)。
3. Mamba 的核心改进:选择性(Selectivity)
传统SSM的局限性:A,B,C 与输入无关,导致静态建模能力。
Mamba的解决方案:让参数动态依赖于输入(Input-dependent),实现“选择性关注”重要信息。
选择性SSM的改动:
-
动态参数化:
-
B, C, ΔΔ 由输入xt 通过线性投影生成:
-
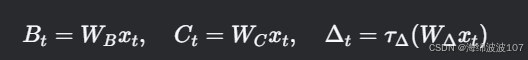
- 这使得模型能过滤无关信息(如文本中的停用词)。
-
硬件优化:
-
选择性导致无法卷积化(传统SSM的优势),但Mamba设计了一种并行扫描算法,在GPU上高效计算。
-
4. Mamba 的架构设计
Mamba模型由多层 Mamba Block 堆叠而成,每个Block包含:
-
选择性SSM层:处理序列并捕获长期依赖。
-
门控MLP(如GeLU):增强非线性。
-
残差连接:稳定深层训练。
(示意图:输入 → 选择性SSM → 门控MLP → 输出)
Time-Varying Recurrence(时变递归)

作用
打破传统SSM的时不变性(Time-Invariance),使状态转移动态适应输入序列。
-
传统SSM的离散化参数 Aˉ,Bˉ 对所有时间步相同(LTI系统)。
-
Mamba的递归过程是时变的(LTV系统),状态更新依赖当前输入。
实现方式
-
离散化后的参数 Aˉt,Bˉt 由 Δt 动态控制:
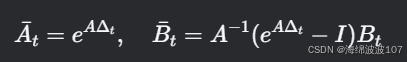
-
-
Δt 大:状态更新慢(保留长期记忆)。
-
Δt 小:状态更新快(捕捉局部特征)。
-
-
效果:模型可以灵活调整记忆周期(例如,在文本中保留重要名词,快速跳过介词)。
关键点
-
时变性是选择性的直接结果,因为 Δt,Bt,Ct 均依赖输入。
Discretization(离散化)
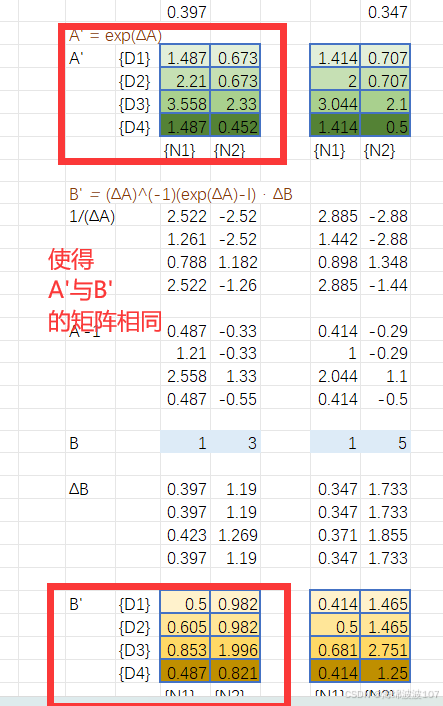
作用
将连续时间的状态空间方程(微分方程)转换为离散时间形式,便于计算机处理。
-
连续SSM:
-
离散SSM:

实现方式
-
使用零阶保持法(ZOH)离散化:
总结
-
Selection:赋予模型动态过滤能力,是Mamba的核心创新。
-
Time-Varying Recurrence:通过时变递归实现自适应记忆。
-
Discretization:将连续理论落地为可计算的离散操作。
5. 为什么Mamba比Transformer更高效?
| 特性 | Transformer | Mamba |
|---|---|---|
| 计算复杂度 | O(N2) | O(N) |
| 长序列支持 | 内存受限 | 轻松处理百万长度 |
| 并行化 | 完全并行 | 需自定义并行扫描 |
| 动态注意力 | 显式Self-Attention | 隐式通过选择性SSM |
优势场景:
-
超长序列(基因组、音频、视频)
-
资源受限设备(边缘计算)
6. 代码实现片段(PyTorch风格)
class MambaBlock(nn.Module):
def __init__(self, dim):
self.ssm = SelectiveSSM(dim) # 选择性SSM
self.mlp = nn.Sequential(
nn.Linear(dim, dim*2),
nn.GELU(),
nn.Linear(dim*2, dim)
def forward(self, x):
y = self.ssm(x) + x # 残差连接
y = self.mlp(y) + y # 门控MLP
return y7. Mamba的局限性
-
训练稳定性:选择性SSM需要谨慎的参数初始化。
-
短序列表现:可能不如Transformer在短文本上的注意力精准。
-
生态支持:目前库(如
mamba-ssm)不如Transformer成熟。
三、Long Short Term Memory (LSTM)
长短期记忆网络(Long Short-Term Memory, LSTM),这是循环神经网络(RNN)的一种改进架构,专门设计用于解决传统RNN在处理长序列时的梯度消失或爆炸问题。
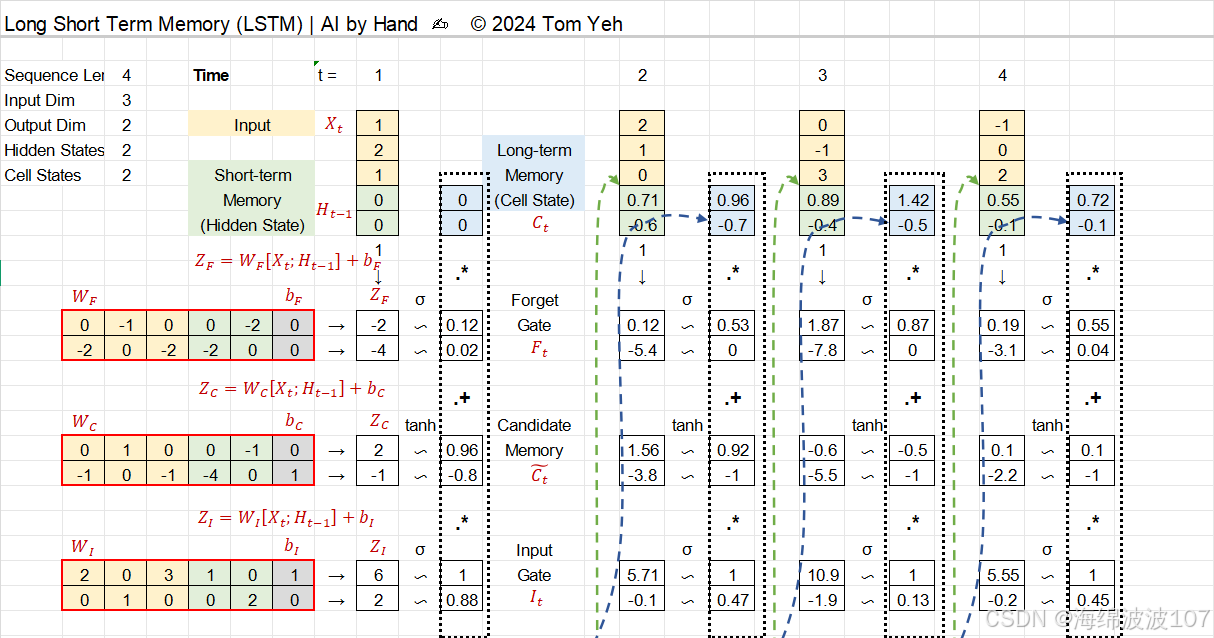
1. RNN的局限性
-
问题背景:传统RNN通过隐藏状态传递历史信息,但梯度在反向传播时会随时间步呈指数级衰减(消失)或增长(爆炸),导致难以学习长期依赖。
-
短期记忆缺陷:例如,在句子“The cat, which ate the fish, was full”中,RNN可能难以记住“cat”和“was”之间的主谓关系。
2. LSTM的核心思想
LSTM通过引入门控机制和细胞状态(Cell State),选择性保留或遗忘信息。其关键创新包括:
-
细胞状态(Ct):贯穿时间步的“信息高速公路”,允许梯度无损传播。
-
门控单元:调节信息的流动,包括:
-
遗忘门(Forget Gate):决定丢弃哪些历史信息。
-
输入门(Input Gate):决定新增哪些新信息。
-
输出门(Output Gate):决定当前隐藏状态的输出。
-
3. LSTM的数学细节
LSTM在每个时间步 t 的计算如下:
a. 遗忘门(Forget Gate)
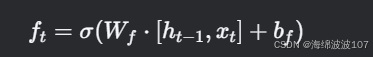
-
ft 取值0到1,0表示“完全遗忘”,1表示“完全保留”。
-
σ 是sigmoid函数,用于概率化门控信号。
b. 输入门(Input Gate)和候选值
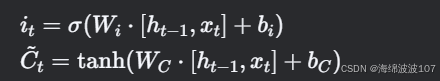
-
it 控制候选状态C~t 的哪些部分被更新到细胞状态。
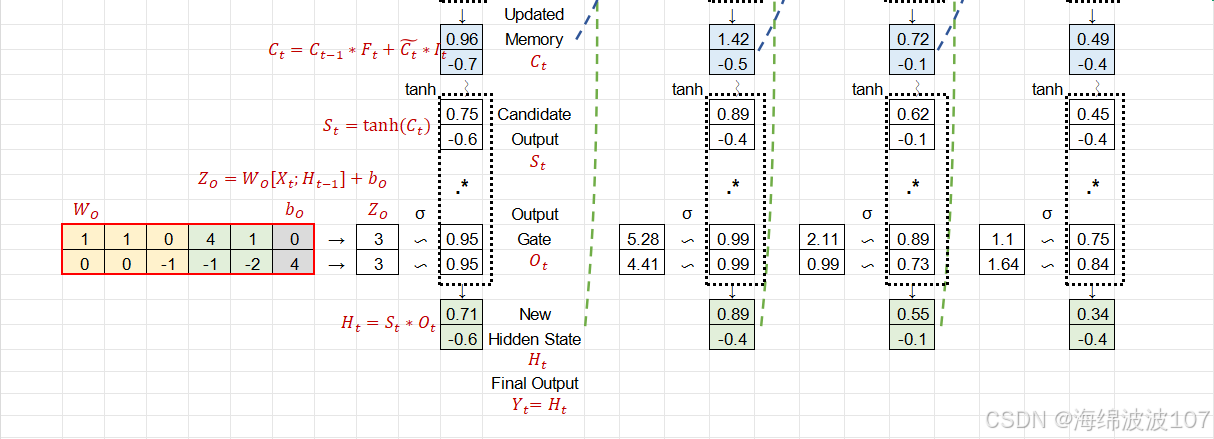
c. 更新细胞状态
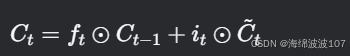
-
⊙⊙ 是逐元素乘法(Hadamard积)。
-
遗忘门和输入门共同决定细胞状态的更新。
d. 输出门(Output Gate)
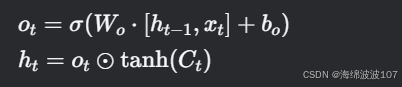
-
输出门控制细胞状态对当前隐藏状态的贡献。
想象你在阅读一本书:
-
候选记忆C~t:当前页的内容(新信息)。
-
输入门it:决定当前页的哪些内容值得记笔记(例如只记录关键句子)。
-
遗忘门 ft:决定之前的笔记中哪些部分需要擦除(例如过时的信息)。
-
细胞状态 Ct:你的笔记本,最终是“擦除旧笔记 + 添加新笔记”的结果。
上一轮细胞状态与遗忘的结果+候选记忆与输入==新的细胞状态,此时的细胞状态是长期记忆。
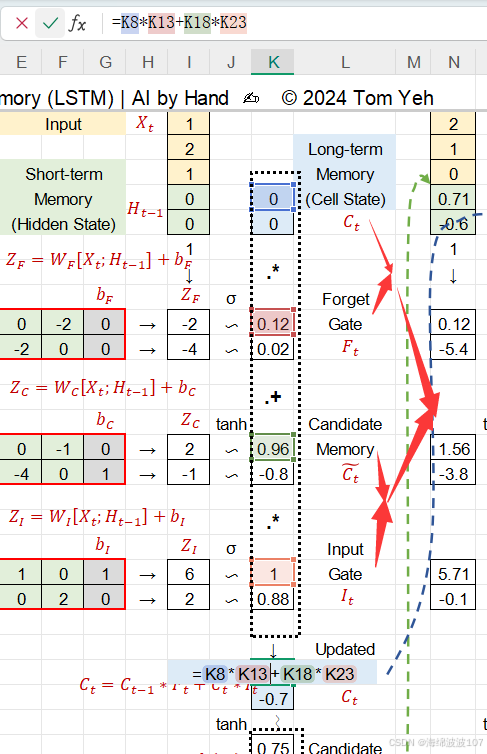
长期记忆和短期记忆的关联
长期记忆和短期记忆的关联是通过细胞状态(Ct)和隐藏状态(ht)的协同机制实现的,两者分工明确又紧密配合。
长期记忆 vs. 短期记忆的定义
-
长期记忆(细胞状态 Ct)
-
作用:跨时间步保留关键信息(如句子的主语、时间序列的周期性模式)。
-
特点:梯度通过加法更新(Ct=ft⊙Ct−1+it⊙C~t)稳定流动,避免梯度消失。
-
类比:像笔记本的“核心知识库”,内容缓慢更新,保留长期依赖。
-
-
短期记忆(隐藏状态 ht)
-
作用:编码当前时间步的上下文信息(如最近的单词或数据点)。
-
特点:受输出门(ot)调控,灵活反映当前输入的影响。
-
类比:像“工作记忆”,临时存储对下一步预测有用的信息。
-
与生物记忆的类比
-
长期记忆:类似大脑的海马体,保留重要事件。
-
短期记忆:类似前额叶皮层,处理即时任务。
-
门控机制:类似注意力机制,决定信息的转移和过滤。
长期记忆 → 短期记忆
细胞状态 Ct 通过 tanhtanh 激活和输出门 ot 生成隐藏状态 ht:
-
意义:长期记忆中的信息经筛选后影响当前输出(例如,主语“cat”通过 ��Ct 传递到 ℎ�ht,帮助预测动词“was”)。
短期记忆 → 长期记忆
-
意义:短期记忆(ht−1)指导长期记忆的更新(例如,当前输入“fish”与ht−1 结合,更新 Ct 以关联“cat ate fish”)。
4. LSTM如何解决梯度问题?
-
细胞状态的加法更新:梯度通过 Ct=Ct−1+新信息 的加法操作传递,避免了梯度连乘导致的指数衰减。
-
门控的调节作用:sigmoid函数将梯度保持在合理范围内,进一步稳定训练。
5. LSTM的变体与改进
-
Peephole Connections:让门控单元直接查看细胞状态。
-
GRU(Gated Recurrent Unit):将遗忘门和输入门合并为“更新门”,简化计算。
-
双向LSTM(Bi-LSTM):结合前向和后向信息,适用于上下文依赖的任务(如机器翻译)。
6. LSTM的实际应用
-
自然语言处理(NLP):机器翻译、文本生成、情感分析。
-
时间序列预测:股票价格、气象数据。
-
语音识别:建模音频信号的长时间依赖。
7. 代码示例(PyTorch)
import torch.nn as nn
lstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2)
input_seq = torch.randn(5, 3, 10) # (seq_len, batch, input_size)
h0 = torch.randn(2, 3, 20) # (num_layers, batch, hidden_size)
c0 = torch.randn(2, 3, 20)
output, (hn, cn) = lstm(input_seq, (h0, c0))8. 关键总结
-
LSTM的优势:通过门控机制和细胞状态,有效建模长序列依赖。
-
缺点:计算复杂度较高,参数量大。
-
现代替代方案:Transformer(基于自注意力机制)在某些任务中表现更优,但LSTM仍是序列建模的重要基础。
四、Extended Long Short Term Memory (xLSTM)
Extended Long Short-Term Memory (xLSTM),这是对传统LSTM的扩展和改进,旨在进一步提升其处理长序列依赖和复杂模式的能力。

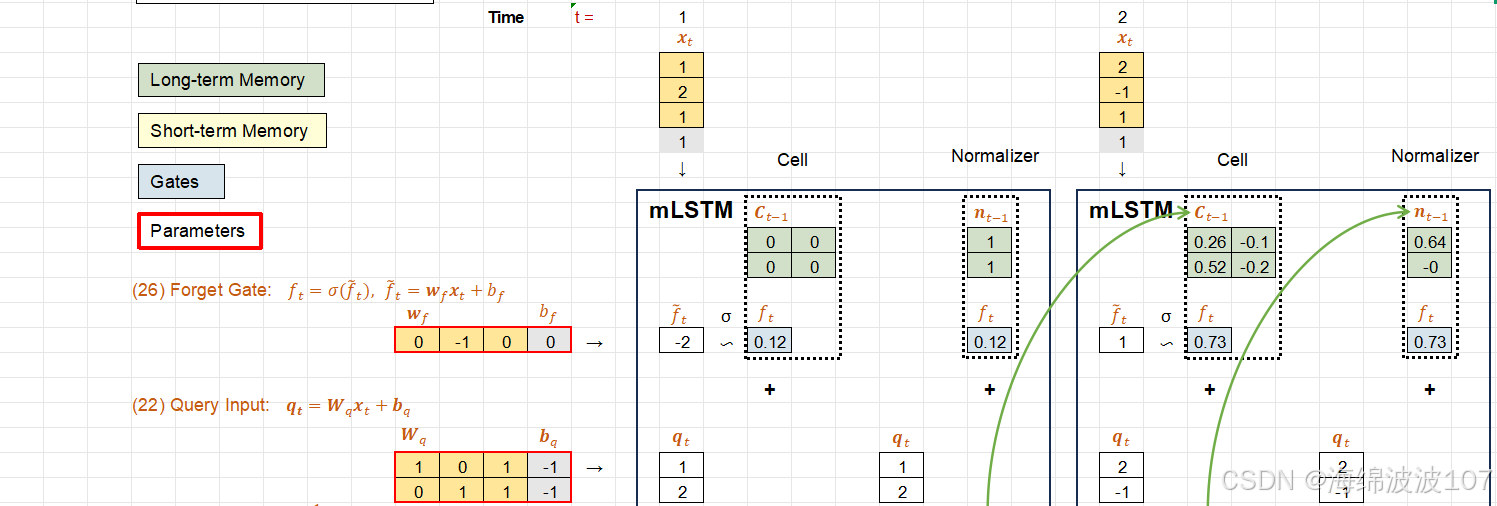
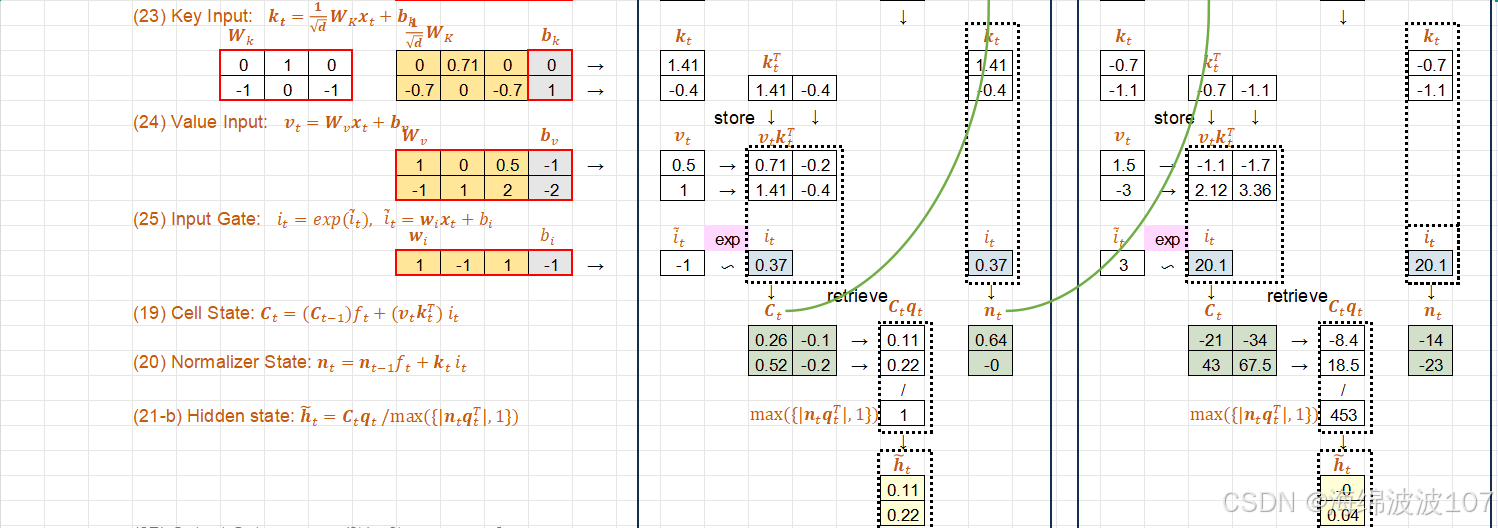

1. 传统LSTM的局限性
尽管LSTM通过门控机制和细胞状态解决了梯度消失问题,但仍存在以下不足:
-
容量有限:细胞状态的固定维度可能限制信息存储能力。
-
并行化困难:顺序依赖的门控计算难以充分利用现代硬件(如GPU)的并行能力。
-
复杂模式建模不足:对某些复杂序列模式(如高频变化或超长依赖)的捕捉不够高效。
2. xLSTM的核心创新
xLSTM通过以下关键改进扩展了传统LSTM:
(1) 可扩展的细胞状态
-
动态维度调整:允许细胞状态在不同时间步动态扩展或收缩,适应不同复杂度的信息存储需求。
-
分块记忆(Chunked Memory):将细胞状态分为多个块(chunks),每块可独立更新,增强局部性和并行性。
(2) 增强的门控机制
-
多级门控:引入层次化门控(如全局门+局部门),分别控制长期和短期信息的流动。
-
自适应门控强度:根据输入动态调整门控的敏感度(例如,对高频信号使用更强的遗忘门)。
(3) 并行化设计
-
局部并行计算:通过分块记忆和矩阵化操作,部分计算可并行执行(如候选记忆的生成)。
-
硬件友好实现:优化内存访问模式以适配GPU的SIMD架构。
3. xLSTM的架构细节
以分块记忆和动态扩展为例,xLSTM的细胞状态更新步骤如下:
(1) 分块记忆初始化
将细胞状态 Ct 划分为 K 块:
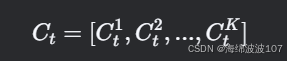
每块 Ctk 独立计算门控和候选记忆。
(2) 动态扩展机制
-
扩展信号(etk):学习当前块是否需要扩展维度:
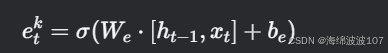
-
扩展操作:若etk>τ(阈值),则新增一个记忆单元到块 k。
(3) 块内门控计算
对每块 k 计算独立的门控和候选记忆:
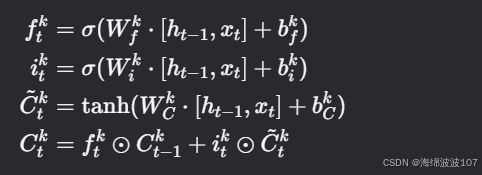
(4) 隐藏状态生成
聚合所有块的信息:
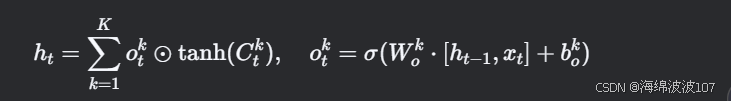
Normalizer State(归一化状态)
在 Extended Long Short-Term Memory (xLSTM) 或某些现代循环神经网络变体中,Normalizer State(归一化状态) 是一种用于稳定训练和提升模型性能的机制,通常与状态归一化(State Normalization)技术结合使用。它的核心目的是解决传统RNN/LSTM在训练过程中可能出现的梯度不稳定或状态值爆炸/消失的问题。
Normalizer State的定义
Normalizer State 是对LSTM的隐藏状态(ht)或细胞状态(Ct)进行动态归一化的中间变量,通常通过以下方式实现:
-
层归一化(Layer Normalization):对同一时间步的神经元输出进行归一化。
-
时间步归一化(Step Normalization):跨时间步对状态进行标准化。
-
可学习的缩放和平移参数:在归一化后引入可学习的参数(γ 和 β),增强表达能力。
为什么需要Normalizer State?
传统LSTM的缺陷:
-
状态值范围不稳定:随着时间步累积,ht 或Ct 的值可能过大或过小,导致梯度爆炸或消失。
-
训练效率低:未归一化的状态需要更谨慎的学习率调参。
Normalizer State 通过强制状态值保持合理的分布范围,从而:
-
加速收敛,
-
减少对初始化和学习率的敏感度,
-
提升模型对长序列的建模能力。
mLSTM(memory-augmented Long Short-Term Memory)
mLSTM(memory-augmented Long Short-Term Memory) 是一种通过显式外部记忆机制增强的LSTM变体,旨在解决传统LSTM在超长序列处理和复杂模式记忆中的局限性。
mLSTM的核心思想
mLSTM在传统LSTM的基础上引入了可寻址的外部记忆矩阵(External Memory Matrix),形成双轨记忆系统:
-
内部记忆:保留传统LSTM的细胞状态(Ct)和隐藏状态(ht),处理局部时序依赖。
-
外部记忆:新增一个可读写的记忆矩阵 Mt∈RN×d(N为记忆槽数量,d为向量维度),存储长期全局信息。
Query-Key-Value (QKV) 机制
在 mLSTM(memory-augmented LSTM) 中引入 Query-Key-Value (QKV) 机制,是为了实现对外部记忆的高效、灵活的读写操作,其核心思想借鉴了注意力机制(Attention)和现代记忆网络(如神经图灵机,NTM)的设计。
QKV机制在mLSTM中的作用
mLSTM中的外部记忆矩阵(Memory Matrix)需要支持基于内容的寻址,即根据当前输入动态决定从记忆库中读取哪些信息或更新哪些位置。QKV模型在此过程中的角色如下:
-
Query (Q):由当前隐藏状态生成,表示“需要从记忆中检索什么”。
-
Key (K):记忆矩阵中每个槽(memory slot)的标识,用于与Query匹配。
-
Value (V):实际存储在记忆中的信息,被读取或更新。
为什么需要QKV?
-
动态寻址:传统LSTM的细胞状态是顺序更新的,而QKV允许基于内容的跳跃式访问,更适合存储和检索分散的长期信息。
-
并行化处理:QKV的矩阵运算(如所有Key与Query的批量匹配)可高效利用GPU加速。
-
可扩展性:通过分离Key(寻址)和Value(存储),可灵活设计记忆结构(如分层记忆)。
与传统Attention的区别
尽管形式相似,mLSTM中的QKV与Transformer的Self-Attention有差异:
| 特性 | mLSTM的QKV | Transformer的QKV |
|---|---|---|
| 目标 | 管理外部记忆矩阵 | 建模序列内部关系 |
| Query来源 | 当前隐藏状态 ht | 当前输入嵌入 xt |
| Key-Value来源 | 外部记忆 Mt | 同一序列的输入 X |
| 更新频率 | 每个时间步读写一次 | 每层所有位置并行计算 |
4. xLSTM的优势
-
更强的记忆能力:动态扩展和分块设计允许模型灵活存储更多信息。
-
高效的长序列处理:分块并行化加速训练和推理。
-
适应复杂模式:多级门控可捕捉不同时间尺度的依赖关系。
5. 实际应用场景
-
超长文本建模:如书籍摘要、代码生成。
-
高频时间序列预测:如股票价格、传感器信号。
-
多模态序列:融合视频、音频和文本的跨模态依赖。
6. 代码示例(伪代码)
class xLSTMCell(nn.Module):
def __init__(self, input_size, hidden_size, num_chunks):
super().__init__()
self.num_chunks = num_chunks
# 初始化分块参数(每块独立权重)
self.W_f = nn.ParameterList([nn.Linear(input_size + hidden_size, hidden_size) for _ in range(num_chunks)])
self.W_i = nn.ParameterList(...) # 类似定义其他门控和候选记忆的权重
def forward(self, x_t, h_t_1, C_t_1_list):
h_t, C_t_list = [], []
for k in range(self.num_chunks):
# 分块计算门控和候选记忆
f_t_k = torch.sigmoid(self.W_f[k](torch.cat([h_t_1, x_t], dim=-1)))
i_t_k = torch.sigmoid(self.W_i[k](...))
C_tilde_k = torch.tanh(self.W_C[k](...))
C_t_k = f_t_k * C_t_1_list[k] + i_t_k * C_tilde_k
# 分块输出
o_t_k = torch.sigmoid(self.W_o[k](...))
h_t_k = o_t_k * torch.tanh(C_t_k)
h_t.append(h_t_k)
C_t_list.append(C_t_k)
# 聚合所有块
h_t = torch.sum(torch.stack(h_t), dim=0)
return h_t, C_t_list7. 与Transformer的对比
| 特性 | xLSTM | Transformer |
|---|---|---|
| 长序列处理 | 分块记忆+动态扩展 | 自注意力(平方复杂度) |
| 并行化 | 部分并行(分块内) | 完全并行 |
| 归纳偏差 | 强时序局部性 | 全局依赖建模 |
| 适用场景 | 超长序列、高频信号 | 通用序列任务 |
8. 总结
xLSTM通过分块记忆、动态扩展和增强门控,在传统LSTM基础上实现了:
-
更灵活的记忆管理:适应不同复杂度的信息存储需求。
-
硬件友好的并行化:分块设计平衡了顺序依赖和计算效率。
-
对复杂模式的鲁棒性:多级门控捕捉多尺度依赖。