在机器学习领域,算法模型是解决实际问题的核心工具。
不同的算法适用于不同的数据场景和任务需求,理解它们的原理与应用是掌握机器学习的关键。
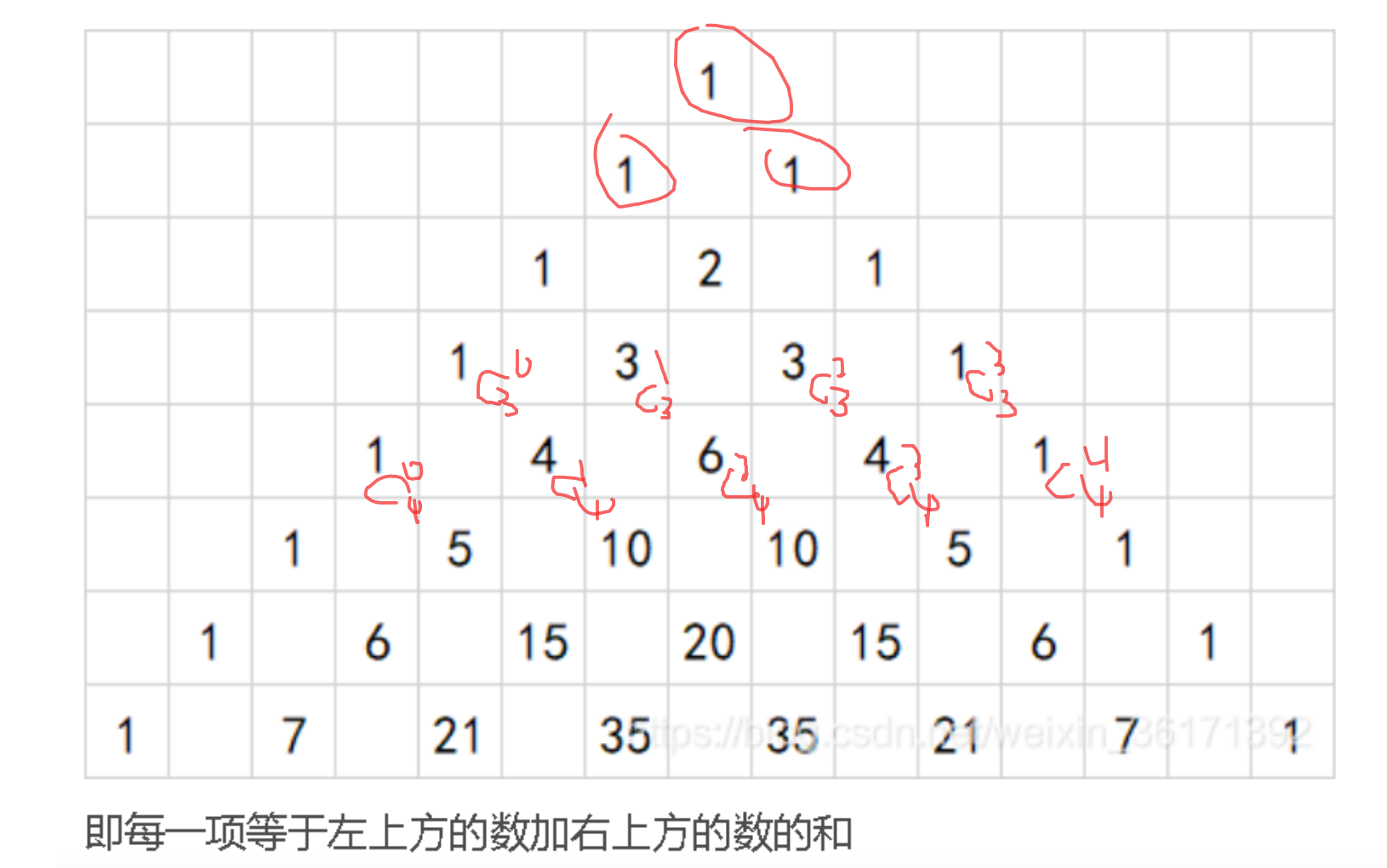
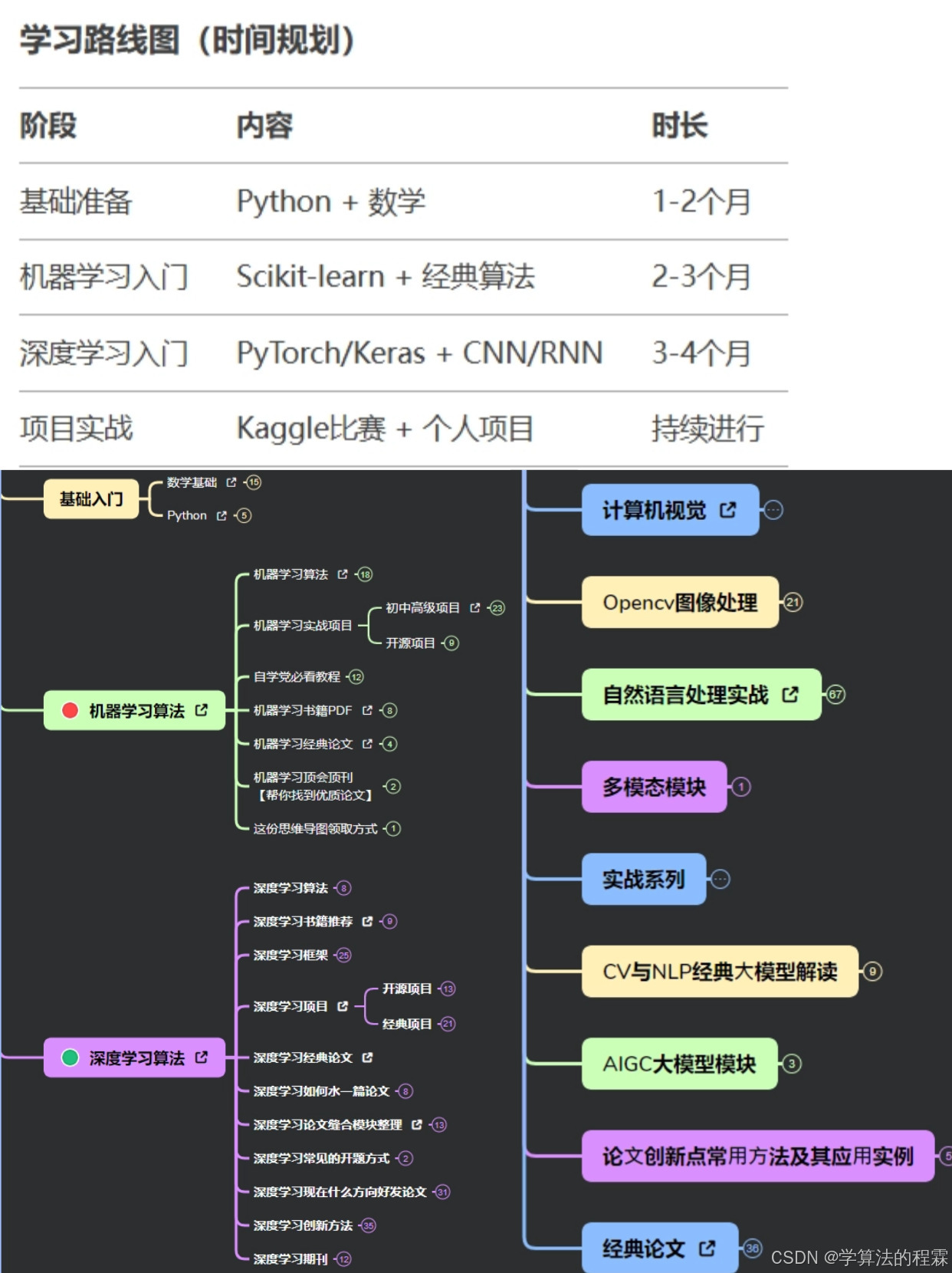
以下将详细解析 18 个核心算法模型,涵盖监督学习、无监督学习、集成学习和深度学习等多个领域,帮助读者构建完整的算法知识框架。
2025年机器学习算法籽料合集 【戳链接即可获取学习】
一、监督学习算法:数据标注下的精准预测
监督学习通过标注数据学习输入与输出的映射关系,适用于分类和回归任务。
1. 线性回归(Linear Regression)
核心思想:假设因变量与自变量呈线性关系,通过最小二乘法拟合直线(或超平面)。 公式:简单线性回归公式为,其中
为预测值,
为截距,
为斜率。
应用场景:房价预测、销售额趋势分析等连续值预测。
代码示例:
from sklearn.linear_model import LinearRegression
import numpy as np
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
model = LinearRegression().fit(X, y)
print("斜率:", model.coef_[0], "截距:", model.intercept_)2. 逻辑回归(Logistic Regression)
核心思想:通过 Sigmoid 函数将线性回归结果映射到 [0,1] 区间,用于二分类任务。
公式:
应用场景:疾病诊断、垃圾邮件分类。
代码示例:
from sklearn.linear_model import LogisticRegression
X = np.array([[1], [2], [3], [4]])
y = np.array([0, 0, 1, 1])
model = LogisticRegression().fit(X, y)
print("预测概率:", model.predict_proba([[3]]))3. 决策树(Decision Tree)
核心思想:通过特征分裂构建树结构,每个节点代表特征判断,叶子节点代表分类结果。
关键点:信息增益(ID3 算法)、基尼系数(CART 算法)用于选择分裂特征。
应用场景:客户流失分析、信用评分模型。
代码示例:
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
iris = load_iris()
model = DecisionTreeClassifier(max_depth=3).fit(iris.data, iris.target)
plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
【戳下面链接即可跳转到学习页面】
2025年机器学习算法教程+项目数据集源码
4. 支持向量机(SVM)
核心思想:在高维空间寻找最大间隔超平面,线性不可分数据可通过核函数映射到更高维空间。
公式:决策函数 ,常用核函数包括线性核、RBF 核。
应用场景:图像分类、文本情感分析。
代码示例:
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
model = SVC(kernel='rbf').fit(X_train, y_train)
print("测试集准确率:", model.score(X_test, y_test))二、无监督学习算法:挖掘数据内在结构
无监督学习无需标注数据,用于发现数据中的隐藏模式或结构。
5. K 近邻算法(KNN)
核心思想:基于 “近邻相似性”,通过投票或平均法预测未知样本类别(分类)或数值(回归)。
关键点:距离度量(欧氏距离、曼哈顿距离)、K 值选择对结果影响显著。
应用场景:图像识别中的模板匹配、推荐系统。
代码示例:
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
print("预测结果:", model.predict([[5, 3, 4, 2]]))6. 聚类算法(K-Means)
核心思想:将数据划分为 K 个簇,使簇内样本相似度高、簇间相似度低,通过迭代更新簇中心优化。
公式:目标函数,其中
为簇中心。
应用场景:用户分群、基因表达数据分析。
代码示例:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
X, _ = make_blobs(n_samples=300, centers=4)
model = KMeans(n_clusters=4).fit(X)
plt.scatter(X[:, 0], X[:, 1], c=model.labels_)
plt.scatter(model.cluster_centers_[:, 0], model.cluster_centers_[:, 1], c='red', s=200, alpha=0.5)
plt.show()7. 主成分分析(PCA)
核心思想:通过线性变换将高维数据映射到低维空间,保留最大方差方向,用于降维和数据可视化。
公式:通过协方差矩阵特征值分解,选取前 k 个主成分(特征值最大的 k 个特征向量)。
应用场景:图像压缩、高维数据预处理。
代码示例:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(iris.data)
print("方差解释率:", pca.explained_variance_ratio_.sum())三、集成学习算法:融合多个模型的智慧
集成学习通过组合多个基模型提升预测性能,分为 Bagging、Boosting 等框架。
8. 随机森林(Random Forest)
核心思想:基于 Bagging 框架,构建多棵决策树,通过随机抽样和特征选择降低过拟合。
关键点:并行训练树模型,分类任务通过投票表决,回归任务通过均值聚合。
应用场景:结构化数据竞赛(如 Kaggle)、金融风险预测。
代码示例:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
print("特征重要性:", model.feature_importances_)9. 梯度提升(Gradient Boosting)
核心思想:基于 Boosting 框架,串行训练基模型(通常为决策树),每一步拟合前序模型的残差。
公式:通过梯度下降优化损失函数,如
应用场景:点击率预测、医疗诊断模型。
代码示例:
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=200, learning_rate=0.1)
model.fit(X_train, y_train)10. AdaBoost
核心思想:自适应提升算法,加大误分类样本权重,基分类器根据权重迭代训练,最终加权组合。
应用场景:弱分类器强化,如人脸检测中的级联分类器。
代码示例:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100, learning_rate=0.5)
model.fit(X_train, y_train)四、深度学习算法:模拟人脑的复杂建模
深度学习通过多层神经网络学习数据的层次化表示,适用于高维、非结构化数据。
11. 神经网络(全连接网络)
核心思想:由输入层、隐藏层、输出层组成,层间通过权重连接,激活函数引入非线性。
公式:前向传播,激活函数如
应用场景:图像分类(如 MNIST)、简单回归任务。
代码示例:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(20,)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])12. 卷积神经网络(CNN)
核心思想:通过卷积层、池化层提取图像局部特征,减少参数数量,适用于图像任务。
应用场景:图像识别(如 ResNet)、目标检测(如 YOLO)。
代码示例(简化版):
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])五、其他重要算法
13. 朴素贝叶斯(Naive Bayes)
核心思想:基于贝叶斯定理和特征条件独立假设,计算后验概率。
应用场景:文本分类(如新闻分类)、垃圾邮件过滤。
代码示例:
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(X_train, y_train)14. 核方法(Kernel Methods)
核心思想:通过核函数将低维非线性数据映射到高维空间,转化为线性问题求解。
应用场景:SVM 处理非线性数据、核岭回归。
六、算法选择与实践建议
- 数据规模:
- 小规模数据:优先尝试逻辑回归、SVM、决策树。
- 大规模数据:深度学习(如 CNN、Transformer)或集成学习(如 XGBoost)。
- 任务类型:
- 分类:逻辑回归、SVM、随机森林、神经网络。
- 回归:线性回归、SVR、梯度提升回归树。
- 无标注数据:聚类(K-Means)、降维(PCA)。
- 特征类型:
- 结构化数据:决策树、集成学习效果更佳。
- 图像 / 文本:深度学习(CNN、RNN、Transformer)更具优势。
总结
-
机器学习算法的多样性为不同场景提供了丰富的解决方案。从线性模型到深度学习,每种算法都有其独特的假设和适用范围。实际应用中,需结合数据特点、任务目标和计算资源综合选择,并通过调参和集成方法进一步优化性能。未来,随着硬件和算法的发展,更高效的模型(如自监督学习、图神经网络)将成为新的研究热点,推动机器学习在更多领域的突破。
-
2025版:这可能是b站最全的【人工智能-数学基础】教程,共100集!微积分、概率论、线性代数、机器学习数学基础、深度学习、计算机视觉
【全198集】这才是科研人该学的计算机视觉教程!一口气学完Python、OpenCV、深度学习、PyTorch框架、卷积神经网络、目标检测、图像分割,通俗易懂!