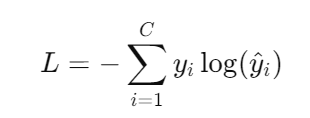一、引言
1.1 研究背景
在当今数字化时代,社交媒体已成为信息传播和公众交流的重要平台。微博作为国内极具影响力的社交媒体之一,每日产生海量的用户生成内容,涵盖新闻资讯、社交互动、娱乐八卦、热点话题讨论等多个领域。这些数据不仅反映了公众的兴趣偏好、情感态度和社会行为,还蕴含着丰富的商业价值和社会价值。对于企业而言,通过分析微博数据可以了解市场需求、消费者反馈,制定精准的营销策略;对于政府和社会机构来说,微博数据有助于监测舆情动态、了解民意,及时采取相应措施。因此,实现对微博数据的有效爬取和分析具有重要的现实意义。
1.2 Scrapy 框架定义
Scrapy 是一个专门为爬取网站数据、提取结构性信息而精心设计的 Python 应用框架。它基于异步 I/O 和事件驱动的架构,具备高效处理大量请求的能力。Scrapy 提供了丰富的内置组件,如 Spider(爬虫)、Downloader(下载器)、Scheduler(调度器)、Item Pipeline(数据管道)等,这些组件之间