在计算机视觉的深度学习任务中,诸如 CNN、FCN、U-Net、DeepLab 系列模型已成为图像分类与图像分割任务的核心架构。它们在网络结构和任务上有所差异,但是否共享同一种优化机制?是否都使用梯度下降?优化过程中又有什么本质区别?本文将系统剖析这些问题。
一、它们都使用梯度下降吗?是的!
1. 梯度下降的本质
所有深度学习模型训练的目标都是最小化损失函数(Loss Function),从而提高模型对数据的拟合能力。无论是 CNN、FCN、U-Net 还是 DeepLab,其优化目标都可以归纳为:
找到一组参数 θ,使得损失函数 L(θ)最小。
这个过程是通过梯度下降算法来完成的。典型的参数更新公式为:

2.梯度下降适用于所有可微分模型
由于 CNN、FCN、U-Net、DeepLab 等模型的构建基于连续可微的张量操作(如卷积、池化、激活、上采样等),因此它们都可以使用**链式法则(Chain Rule)**进行反向传播(Backpropagation),最终实现梯度计算和参数更新。
二、优化过程的差异:从结构设计到训练策略
虽然它们都使用梯度下降作为基础优化方法,但由于网络的结构和目标不同,其优化路径和训练细节存在多个显著差异。
1.网络结构差异导致梯度流路径不同
| 模型 | 核心结构 | 对优化的影响 |
| CNN | 卷积 + 池化 + 全连接 | 通常用于分类任务,结构深时可能面临梯度消失/爆炸 |
| FCN | 去掉全连接层,改为卷积 + 上采样 | 支持像素级预测,但特征还原不够精细 |
| U-Net | 编码器-解码器结构 + 跳跃连接 | 促进细节保留,有效缓解梯度消失问题 |
| DeepLabv3+ | 空洞卷积 + ASPP + 解码器 | 多尺度上下文感知,但训练复杂,梯度传播路径更长2. |
跳跃连接(Skip Connections)的好处:
U-Net 和 ResNet 类结构都使用了跳跃连接,这有两个优势:
- 提高梯度流动效率(缓解梯度消失)
- 引入浅层特征,有助于定位边界与细节信息
空洞卷积(Atrous Conv)的作用:
DeepLab 系列大量使用空洞卷积扩大感受野,在保持分辨率的同时捕捉更大上下文,但也带来梯度稀疏的问题,需要良好的初始化与调参策略。
2.损失函数不同 —— 与任务直接相关
图像分类(CNN):
- 通常使用交叉熵损失(CrossEntropyLoss):
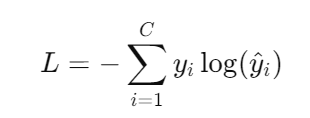
图像分割(FCN/U-Net/DeepLab):
- 需要针对每个像素进行分类 → 使用“像素级”损失
- 常见组合如下:
| 损失函数 | 用途 | 特点 |
| Pixel-wise Cross Entropy | 所有分割模型基础 | 易实现,效果好 |
| Dice Loss | 类别不平衡问题 | 强调前景区域 |
| Focal Loss | 小目标检测或前景很少时 | 聚焦困难样本,平衡简单样本的主导地位 |
| IoU Loss | 强调区域重合度 | 适合评估目标边界质量 |
3.参数优化器(Optimizer)选择不同
所有模型都用“基于梯度”的优化器,但由于结构不同、任务不同,其偏好的优化器略有差异:
| 模型 | 常用优化器 | 特性 |
| CNN | SGD / Adam | 结构简单,收敛快 |
| FCN / U-Net | Adam / RMSprop | 容忍训练不稳定、学习率不敏感 |
| DeepLabv3+ | SGD + Momentum + 学习率衰减策略 | 训练更稳定,适合复杂网络结构 |
4.正则化和 BatchNorm 等机制使用方式不同
- FCN / U-Net 有时在低分辨率阶段不使用 BN,以避免高层特征退化。
- DeepLab 系列 特别强调 SyncBN(同步 BN),保证多卡训练时统计一致,提升收敛精度。
- Dropout / L2 Regularization 有时会因分割任务精度需求较高而适当调低使用频率。
三、训练策略也会影响优化表现
虽然大家都用梯度下降,不同模型还会采取不同的训练策略来提升训练效率或结果表现:
| 策略 | 说明 |
| 学习率预热(Warmup) | 防止训练初期梯度震荡,特别适用于 DeepLab 系列 |
| 多尺度训练 | 输入图像以不同分辨率送入模型,增强模型鲁棒性 |
| 类别权重平衡 | 对小类提升权重,解决类别不平衡问题(如医学分割) |
| Fine-tuning | 用预训练模型初始化(如 ImageNet、COCO),再微调 |
四、训练过程的本质总结
无论是哪种模型,它们的训练过程都遵循统一框架:
输入图像 →
前向推理 →
计算损失 →
反向传播 →
梯度更新参数 →
优化模型性能差异主要体现在:
- 损失函数设计
- 网络结构复杂度
- 梯度传播机制
- 优化器选择
这些差异虽然不会改变“用梯度下降”这一核心机制,但会影响训练的速度、稳定性、最终性能。
四、一句话总结核心观点
CNN、FCN、U-Net、DeepLab 等模型本质上都是基于梯度下降优化参数,但由于任务目标、网络结构、损失函数设计和优化策略不同,它们的训练过程在细节上具有显著差异。
| 问题 | 答案 |
| 是否都使用梯度下降? | ✅ 是,核心优化逻辑相同 |
| 网络结构影响优化吗? | ✅ 是,结构不同 → 梯度传播机制不同 |
| 损失函数是否统一? | ❌ 不同任务使用不同损失,特别是分割任务更复杂 |
| Optimizer 选择是否固定? | ❌ 否,根据结构和任务调整优化器和训练策略 |