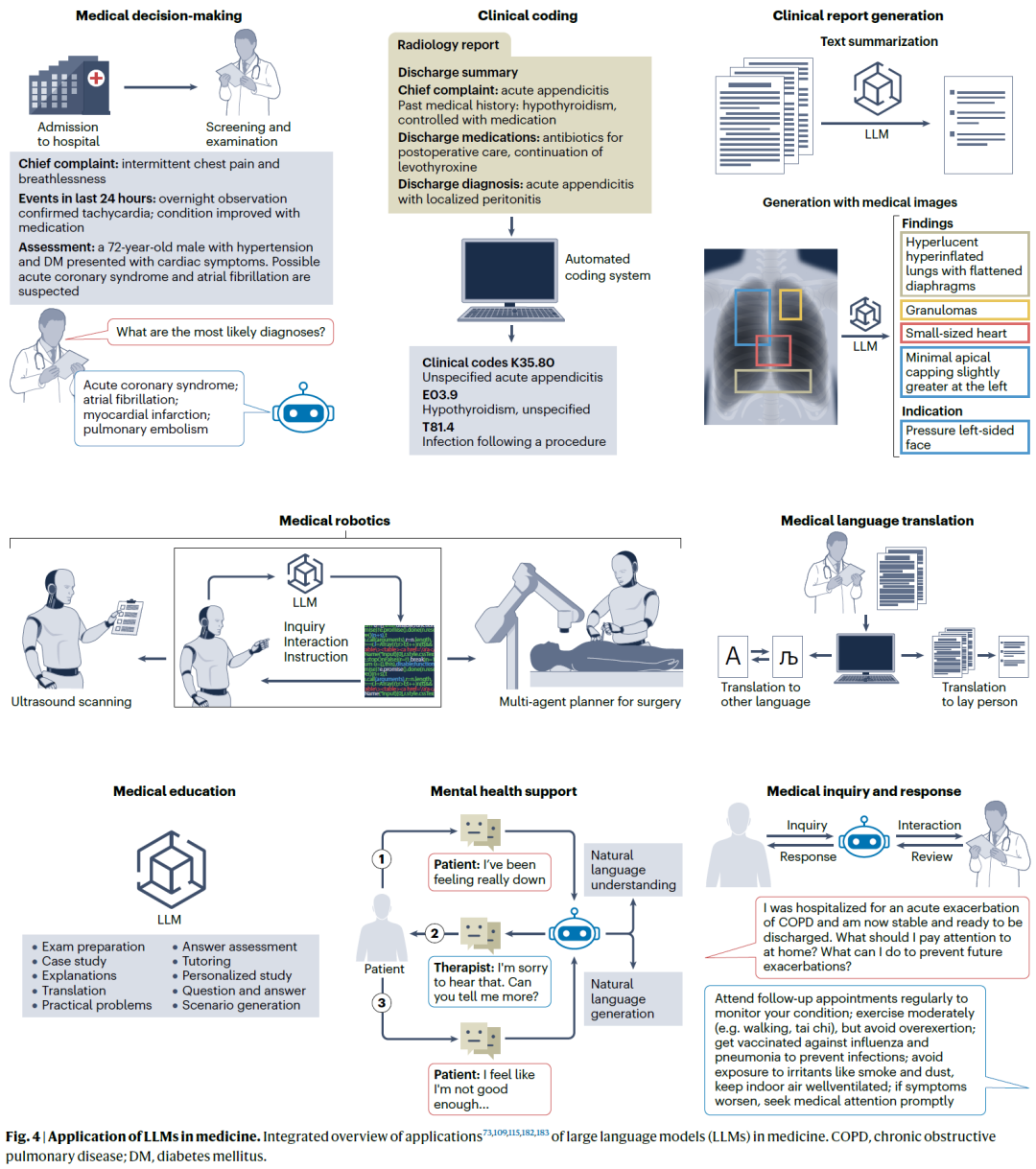
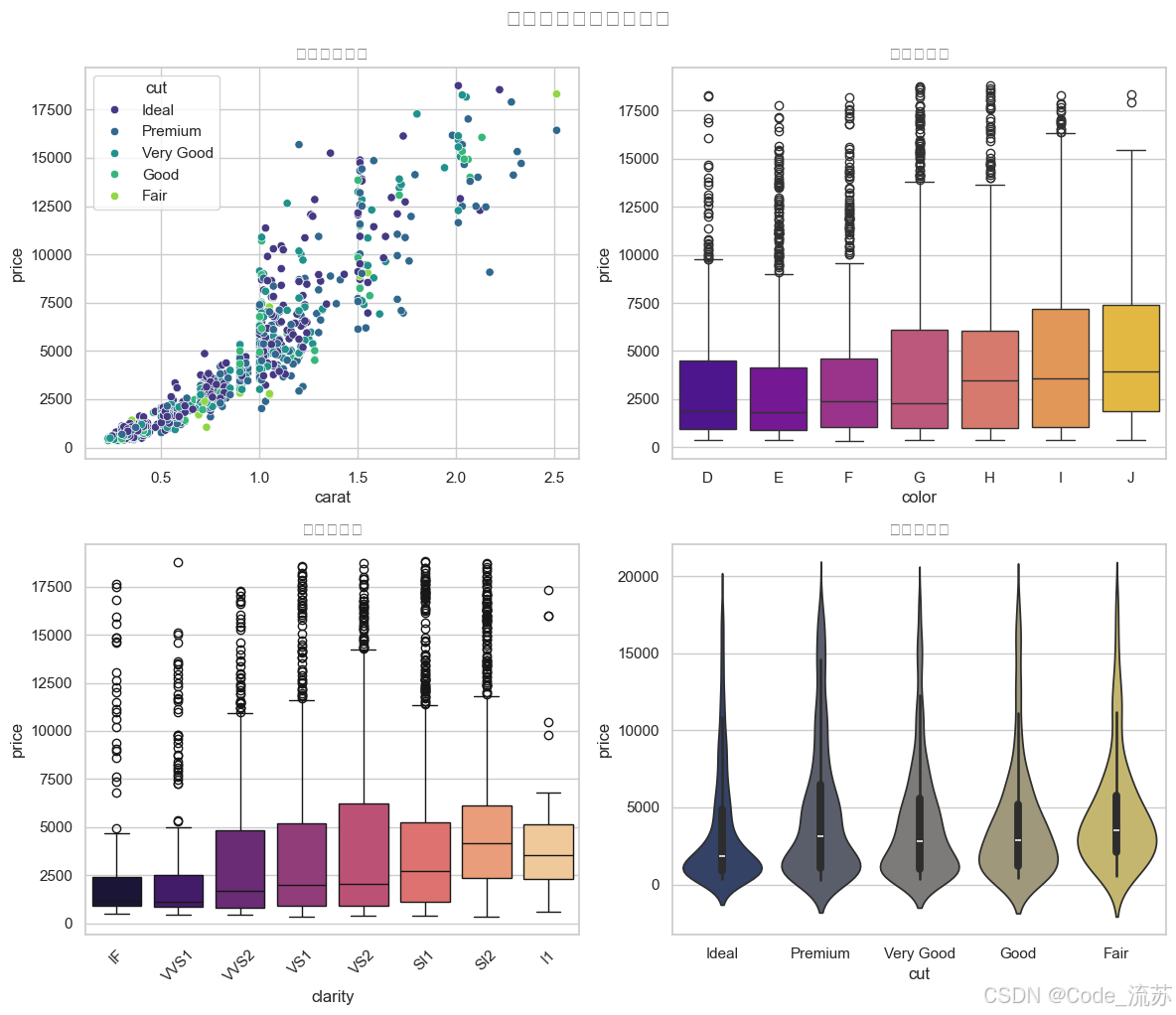
全文检索(Full-Text Search)是SQL中用于高效搜索文本数据的技术,与传统的LIKE操作或简单字符串比较相比,它能提供更强大、更灵活的文本搜索能力。
基本概念
全文检索的核心思想是将文本内容分解为可索引的单元(通常是词或词组),然后建立倒排索引(Inverted Index)来快速定位包含特定词汇的文档。
工作原理
1. 文本分析与分词(Tokenization)
-
将文本分解为词元(tokens)或词项(terms)
-
移除停用词(stop words)如"a", "the", "and"等
-
应用词干提取(stemming)将单词还原为词根形式(如"running"→"run")
-
可能还包括大小写转换、特殊字符处理等
2. 索引构建
-
创建倒排索引:记录每个词项出现在哪些文档中
-
存储词项的位置信息(用于短语搜索)
-
可能包括词频(TF)和逆文档频率(IDF)等统计信息
3. 查询处理
-
解析用户查询(可能包括布尔操作符AND/OR/NOT)
-
扩展查询(如同义词、拼写纠正)
-
使用索引快速定位相关文档
-
计算相关性得分并对结果排序
SQL中的全文检索实现
不同数据库系统的全文检索实现略有不同:
MySQL (MyISAM/InnoDB)
-- 创建全文索引
CREATE FULLTEXT INDEX idx_name ON table_name(column_name);
-- 使用全文搜索
SELECT * FROM table_name
WHERE MATCH(column_name) AGAINST('search term');SQL Server
-- 创建全文目录和索引
CREATE FULLTEXT CATALOG ft_catalog AS DEFAULT;
CREATE FULLTEXT INDEX ON table_name(column_name)
KEY INDEX pk_index_name ON ft_catalog;
-- 使用CONTAINS或FREETEXT搜索
SELECT * FROM table_name
WHERE CONTAINS(column_name, '"search term"');PostgreSQL
-- 创建全文搜索列和索引
ALTER TABLE table_name ADD COLUMN tsv_column tsvector;
UPDATE table_name SET tsv_column = to_tsvector('english', text_column);
CREATE INDEX idx_gin ON table_name USING GIN(tsv_column);
-- 使用搜索
SELECT * FROM table_name
WHERE tsv_column @@ to_tsquery('english', 'search & term');高级特性
-
相关性排序:根据匹配程度对结果排序
-
模糊搜索:处理拼写错误或近似匹配
-
短语搜索:查找精确的短语而不仅是单个词
-
同义词扩展:自动包含同义词搜索结果
-
加权搜索:为特定字段或词项分配更高权重
性能考虑
-
全文索引通常比传统索引占用更多空间
-
索引更新可能影响写入性能
-
复杂查询可能需要更多处理时间
-
需要定期优化索引以保持性能