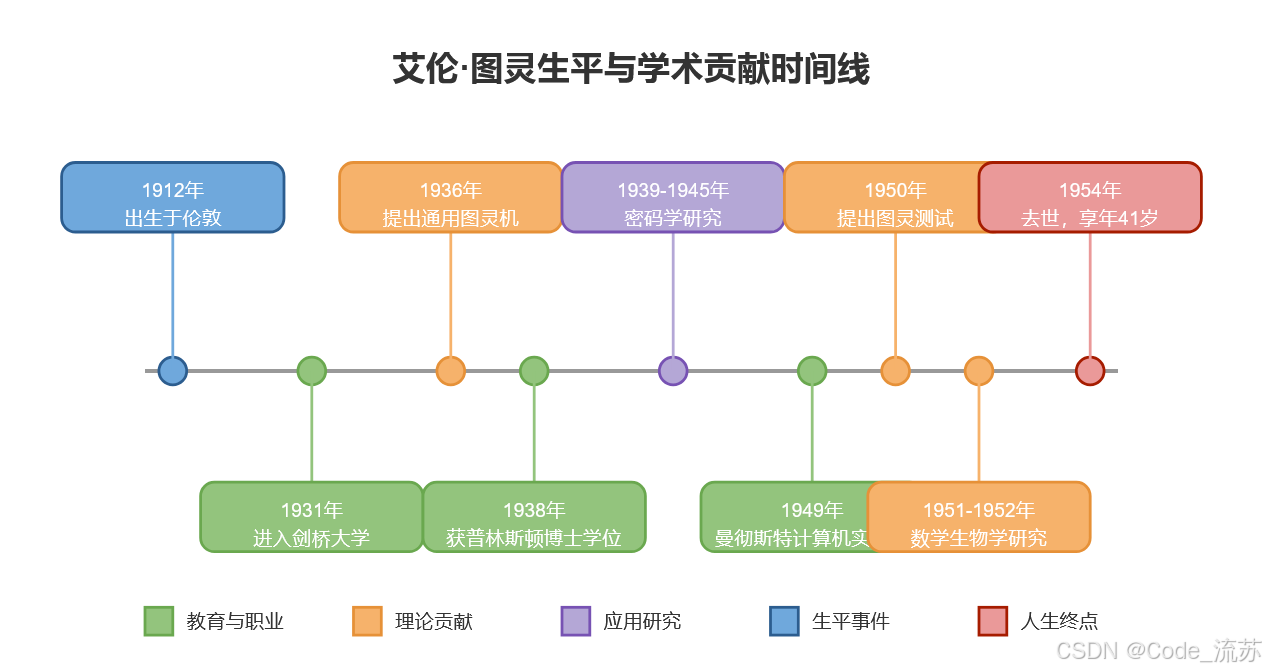
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
专栏:《Python星球日记》,限时特价订阅中ing
目录
- 一、Seaborn 简介
- 1. Seaborn 与 Matplotlib 的区别
- 2. 安装与导入
- 二、高级绘图
- 1. 分布图:探索数据分布
- Histplot():组合直方图和密度曲线
- 双变量分布图
- 2. 关系图:探索变量关系
- scatterplot():散点图
- lineplot():折线图
- 带置信区间的线图
- 3. 分类图:比较分组数据
- boxplot():箱线图
- violinplot():小提琴图
- 配对的分类图
- 三、图形组合
- 1. 使用 FacetGrid 绘制多个子图
- 使用FacetGrid绘制不同类型的图
- 2. 成对关系图:pairplot()
- 3. 自定义配色方案
- 使用预设调色板
- 自定义连续调色板
- 在图表中应用自定义调色板
- 四、实战练习:多维度数据分析
- 1. 数据准备与探索
- 2. 多维度可视化分析
- 价格与克拉数的关系
- 不同切工质量的价格分布
- 使用FacetGrid创建多个维度的关系图
- 多变量联合分布
- 成对关系分析
- 3. 价格预测因素分析
- 五、总结与拓展
- 1. 核心要点回顾
- 2. Seaborn优势总结
- 3. 进阶学习方向
- 4. 学习资源推荐
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: Python星球日记 - 第22天:NumPy 基础
欢迎来到Python星球日记第27天🪐!
今天我们将探索Seaborn,一个建立在Matplotlib基础上的高级统计数据可视化库。Seaborn提供了更优雅的界面、更美观的默认样式和更专业的统计图表,让我们能够轻松创建出令人印象深刻的数据可视化作品。
一、Seaborn 简介
1. Seaborn 与 Matplotlib 的区别
Seaborn是一个基于Matplotlib的Python数据可视化库,专注于统计数据的可视化。虽然Matplotlib提供了绘图的基础功能,但Seaborn在此基础上进行了多方面的增强和优化:
- 更美观的默认样式:Seaborn默认就提供了现代、专业的视觉风格,颜色协调且具有可读性
- 更高级的统计图表:内置了多种统计图形,如小提琴图、联合分布图、成对关系图等
- 更简洁的API:通过更少的代码就能创建复杂的可视化效果
- 集成数据结构支持:与Pandas和NumPy深度集成,可直接使用DataFrame作为输入
- 自动处理分类变量:能够自动处理分类变量的映射和标签
- 内置调色板:提供专业的配色方案,适用于各种数据可视化需求
简单来说,Matplotlib是一个全能的底层绘图库,几乎可以绘制任何图形,但需要较多的代码来调整和美化;而Seaborn则是一个专注于统计可视化的高级库,提供了更简洁的API和更美观的默认样式,特别适合于数据分析和探索过程中的可视化需求。
2. 安装与导入
安装Seaborn非常简单:
# 使用pip安装
pip install seaborn
# 使用conda安装
conda install seaborn

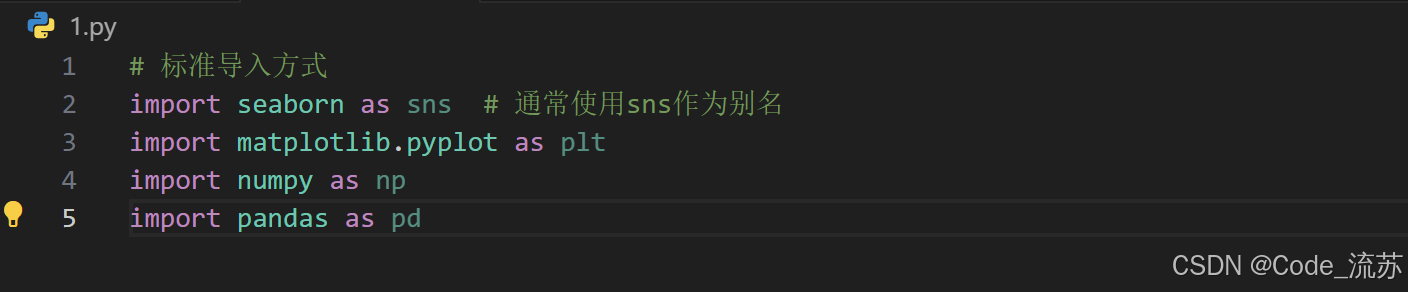
在代码中导入Seaborn:
# 标准导入方式
import seaborn as sns # 通常使用sns作为别名
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
提示:虽然Seaborn是基于Matplotlib构建的,但通常仍需要导入
matplotlib.pyplot,因为某些操作(如调整图表大小、显示图形等)仍需通过Matplotlib完成。
二、高级绘图
Seaborn 提供了多种高级图表类型,主要分为三类:分布图、关系图和分类图。这些图表类型能够帮助我们深入理解数据的分布特征和变量之间的关系。
1. 分布图:探索数据分布
分布图用于可视化 单变量 或 双变量 的分布情况,帮助我们理解数据的集中趋势、离散程度和形状特征。
Histplot():组合直方图和密度曲线
Histplot()是一个便捷的函数,可以同时绘制直方图和密度曲线:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 动态加载字体
font_path = r"C:\Windows\Fonts\simhei.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)
plt.rcParams['font.family'] = prop.get_name()
plt.rcParams['axes.unicode_minus'] = False
# 设置风格
sns.set_theme(style="whitegrid")
# 生成数据
data = np.random.normal(0, 1, 1000)
# 绘制直方图并叠加核密度曲线
plt.figure(figsize=(10, 6))
sns.histplot(data,
bins=30,
kde=True,
color="purple",
alpha=0.6,
line_kws={"color": "darkblue", "lw": 2})
plt.title('标准正态分布的Histplot图', fontsize=15)
plt.xlabel('值', fontsize=12)
plt.ylabel('频率/密度', fontsize=12)
plt.show()
可视化效果:

双变量分布图
Seaborn还可以绘制双变量的联合分布图:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 动态加载字体
font_path = r"C:\Windows\Fonts\simhei.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)
# 生成双变量数据
x = np.random.normal(0, 1, 1000)
y = x * 0.5 + np.random.normal(0, 1, 1000) # y与x相关
# 绘制双变量分布图
plt.figure(figsize=(10, 6))
sns.jointplot(x=x, y=y,
kind="scatter", # 类型:"scatter", "kde", "hex"
color="teal", # 颜色
height=8, # 图形大小
ratio=5, # 散点图与边缘分布图的大小比例
marginal_kws=dict(bins=25, fill=False)) # 边缘分布图参数
plt.suptitle('双变量联合分布图', y=1.02, fontsize=15)
plt.show()
可视化效果:
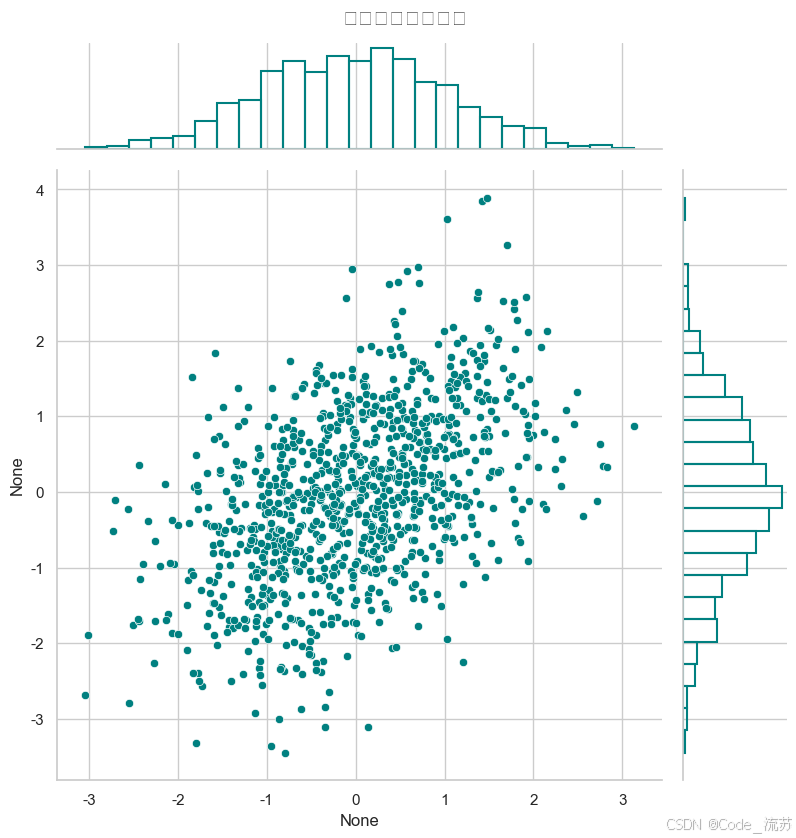
jointplot()可以生成中间的散点图和边缘的分布图,非常适合观察两个变量的联合分布和各自的边缘分布。
2. 关系图:探索变量关系
关系图用于可视化两个或多个变量之间的关系,帮助我们发现数据中的模式、趋势和相关性。
scatterplot():散点图
散点图是观察两个连续变量关系的最基本工具:
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体以避免乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 使用内置数据集
tips = sns.load_dataset("tips")
# 绘制散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x="total_bill", y="tip",
hue="time", # 按"time"分组着色
size="size", # 按"size"调整点大小
palette="Set2", # 调色板
data=tips) # 数据集
# 添加图表标题与轴标签
plt.title('账单金额与小费关系散点图', fontsize=15)
plt.xlabel('账单总额', fontsize=12)
plt.ylabel('小费', fontsize=12)
# 显示图表
plt.tight_layout() # 自动调整布局
plt.show()
可视化效果:
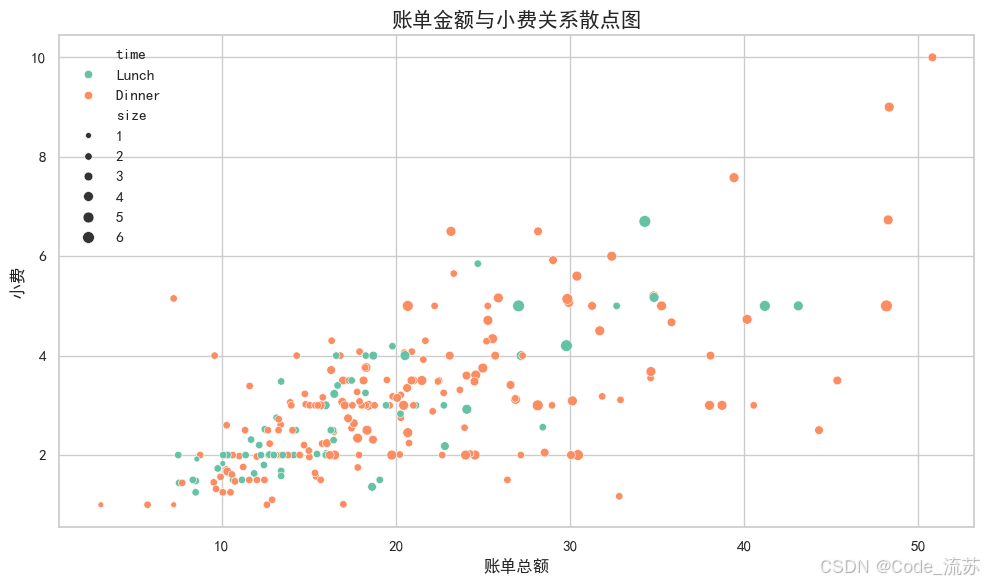
Seaborn的scatterplot()函数比Matplotlib的scatter()更强大,可以直接使用DataFrame,并且能通过hue和size参数轻松添加额外的维度。
lineplot():折线图
折线图适合展示随时间或有序类别变化的趋势:
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 使用内置数据集
flights = sns.load_dataset("flights")
# 绘制折线图
plt.figure(figsize=(12, 6))
sns.lineplot(data=flights,
x="year", y="passengers",
hue="month", # 按月份分组
palette="tab10") # 调色板
plt.title('1949-1960年各月航班乘客数量趋势', fontsize=15)
plt.xlabel('年份', fontsize=12)
plt.ylabel('乘客数量', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
可视化效果:
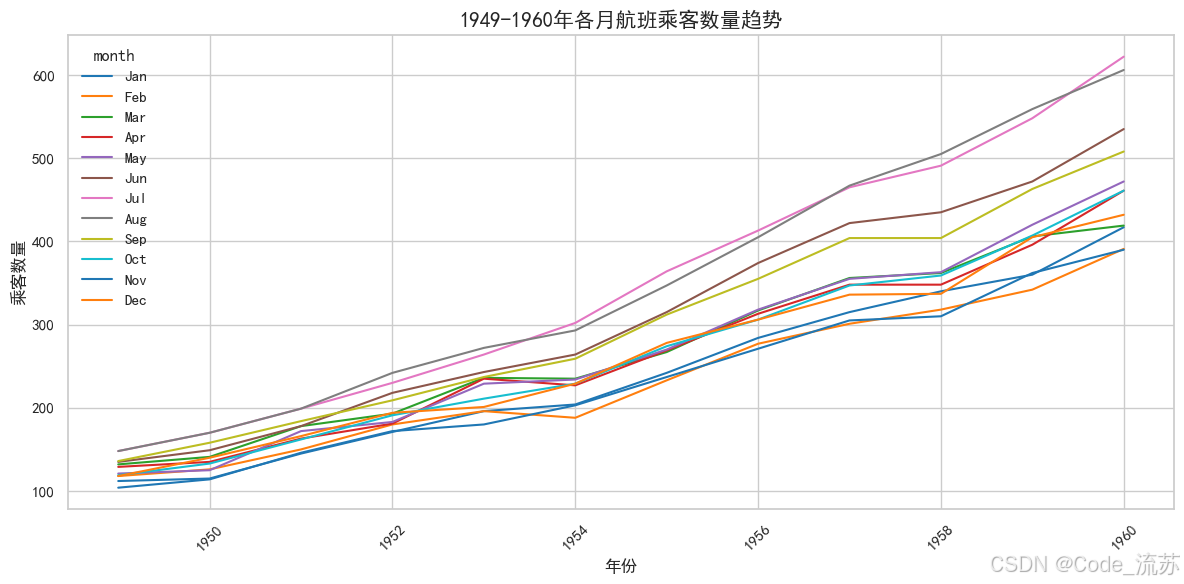
带置信区间的线图
Seaborn的线图默认会显示置信区间:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成模拟数据
np.random.seed(0)
x = np.linspace(0, 10, 100)
y = np.sin(x) + np.random.normal(0, 0.2, 100)
# 创建DataFrame
df = pd.DataFrame({'x': x, 'y': y})
# 绘制带置信区间的线图(使用新版Seaborn参数)
plt.figure(figsize=(10, 6))
sns.lineplot(x="x", y="y",
data=df,
errorbar=('ci', 95), # 使用新版语法替代ci
err_style="band") # 误差显示样式:"band"或"bars"
plt.title('带95%置信区间的线图', fontsize=15)
plt.xlabel('X值', fontsize=12)
plt.ylabel('Y值', fontsize=12)
plt.tight_layout()
plt.show()
可视化效果:
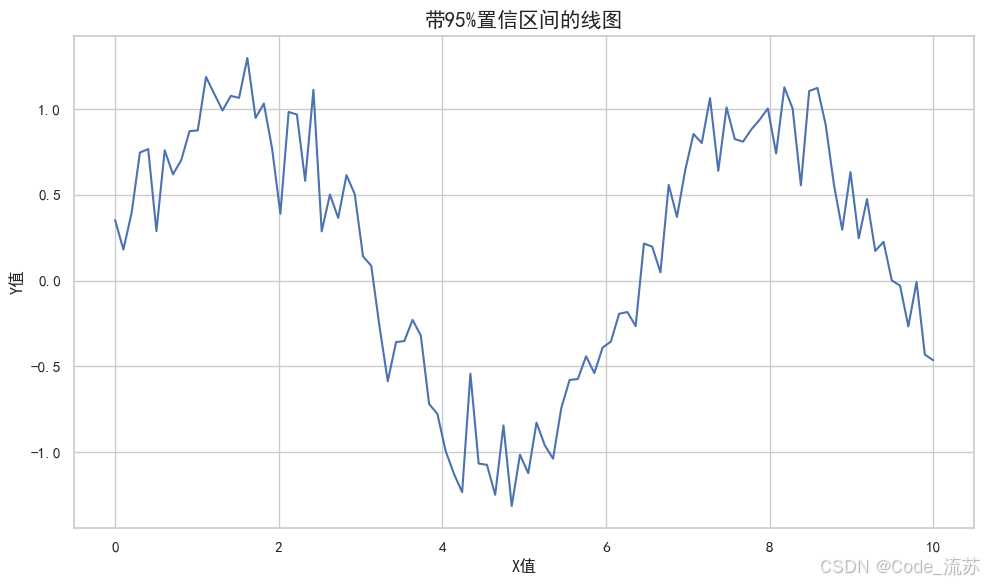
3. 分类图:比较分组数据
分类图用于分析和比较分类变量不同组别中数值变量的分布,是数据分析中非常实用的工具。
boxplot():箱线图
箱线图显示数据的四分位数和异常值,是比较不同类别数据分布的有力工具:
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 使用内置数据集
tips = sns.load_dataset("tips")
# 绘制箱线图
plt.figure(figsize=(12, 6))
sns.boxplot(x="day", y="total_bill",
hue="smoker", # 按吸烟者/非吸烟者分组
palette="Set3", # 调色板
data=tips) # 数据集
plt.title('不同天的账单金额箱线图', fontsize=15)
plt.xlabel('星期', fontsize=12)
plt.ylabel('账单金额', fontsize=12)
plt.tight_layout()
plt.show()
可视化效果:
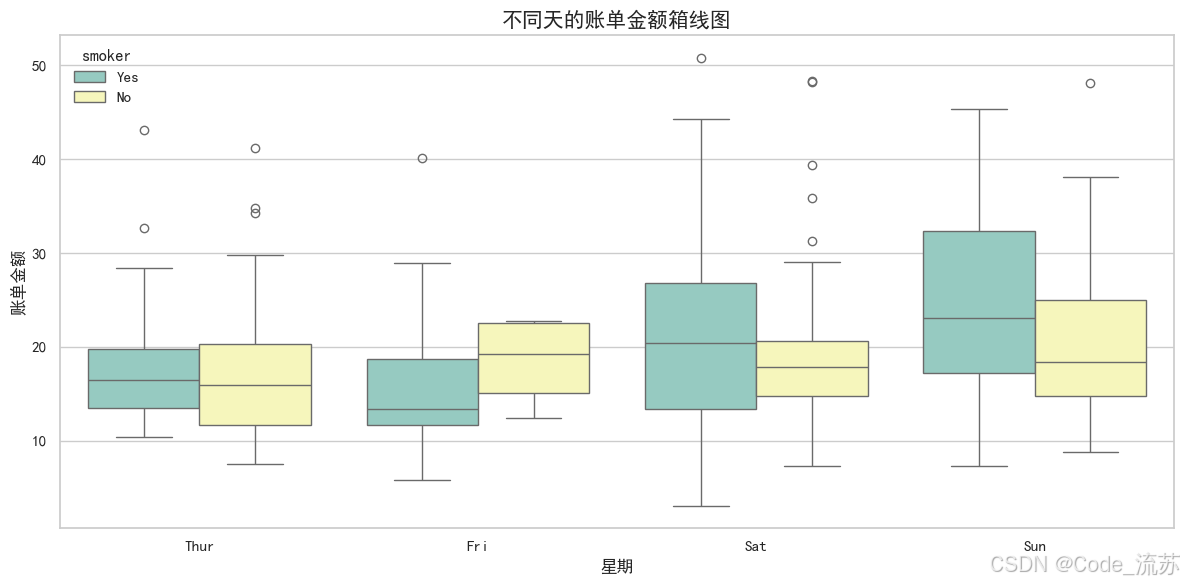
箱线图的元素含义:
- 箱体:从第一四分位数到第三四分位数,表示中间50%的数据
- 中线:表示中位数
- 触须:延伸到最小值和最大值,但不包括异常值
- 点:表示异常值
violinplot():小提琴图
小提琴图结合了箱线图和密度图的特点,展示了数据分布的密度和概率分布:
import seaborn as sns
import matplotlib.pyplot as plt
# 中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
tips = sns.load_dataset("tips")
# 绘制小提琴图
plt.figure(figsize=(12, 6))
sns.violinplot(x="day", y="total_bill",
hue="smoker", # 按吸烟者/非吸烟者分组
split=True, # 拆分两组对比
inner="quart", # 内部标记:"quart", "box", "stick", "point"
palette="Set2", # 调色板
data=tips) # 数据集
# 图表美化
plt.title('不同天的账单金额小提琴图', fontsize=15)
plt.xlabel('星期', fontsize=12)
plt.ylabel('账单金额', fontsize=12)
plt.tight_layout()
plt.show()
可视化效果:
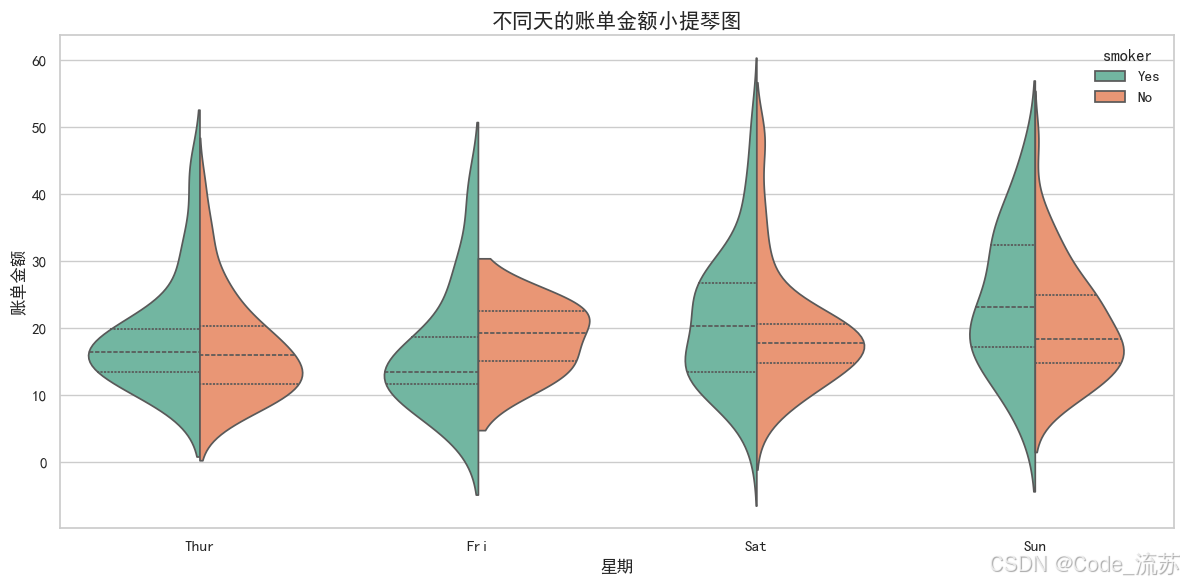
小提琴图比箱线图提供了更多信息,可以看到数据的完整概率密度分布。
配对的分类图
可以组合多种类型的分类图进行比较:
import seaborn as sns
import matplotlib.pyplot as plt
# 中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
tips = sns.load_dataset("tips")
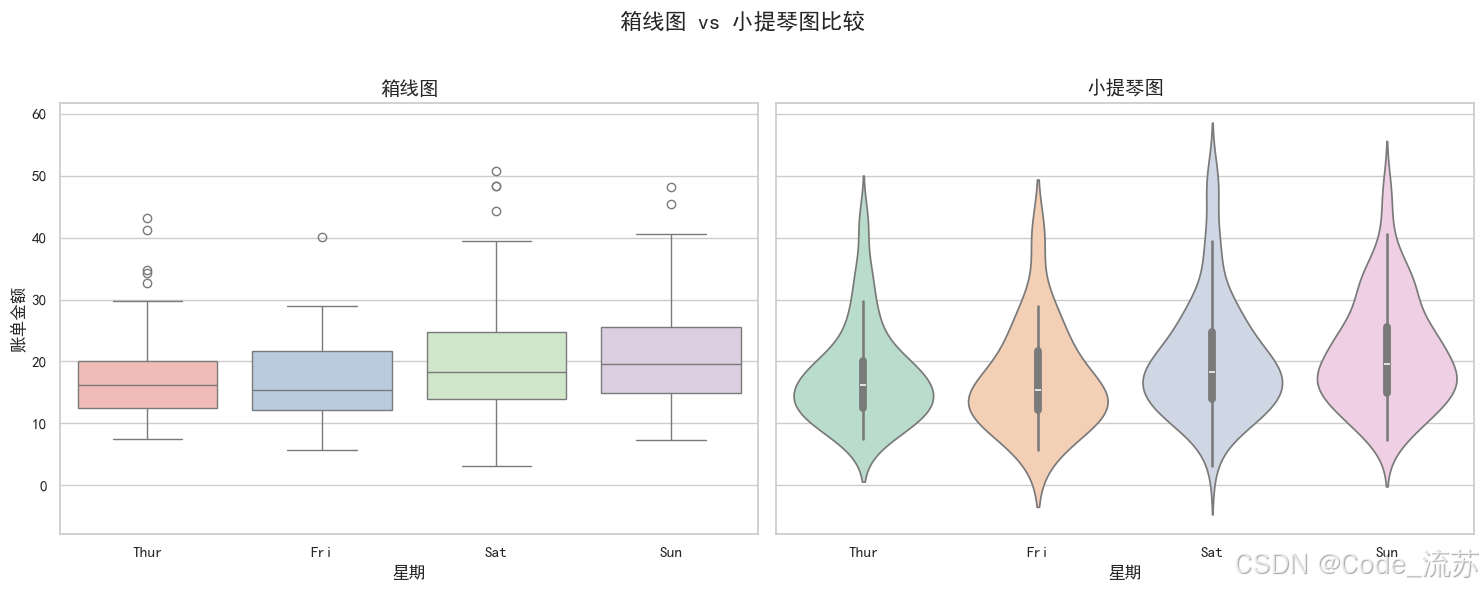
# 创建一个包含箱线图和小提琴图的组合
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6), sharey=True)
# 箱线图
sns.boxplot(x="day", y="total_bill", data=tips, ax=ax1, palette="Pastel1")
ax1.set_title('箱线图', fontsize=14)
ax1.set_xlabel('星期', fontsize=12)
ax1.set_ylabel('账单金额', fontsize=12)
# 小提琴图
sns.violinplot(x="day", y="total_bill", data=tips, ax=ax2, palette="Pastel2")
ax2.set_title('小提琴图', fontsize=14)
ax2.set_xlabel('星期', fontsize=12)
ax2.set_ylabel('') # 共享y轴,不重复显示标签
plt.suptitle('箱线图 vs 小提琴图比较', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.96]) # 调整布局
plt.show()
可视化效果:
三、图形组合
在数据分析中,我们经常需要在同一个图形中展示多个维度的数据,或者按照某个变量的不同值创建多个子图。Seaborn提供了强大的工具来实现这一点。
1. 使用 FacetGrid 绘制多个子图
FacetGrid是Seaborn中最强大的功能之一,它可以按照某个分类变量的值,创建一个网格子图,每个子图显示数据的不同子集。
# 使用FacetGrid创建按time和smoker分组的小提琴图
g = sns.FacetGrid(tips,
col="time", # 按列分组变量
row="smoker", # 按行分组变量
height=4, # 子图高度
aspect=1.2) # 宽高比
# 在每个子图上映射violinplot函数
g.map_dataframe(sns.violinplot, x="day", y="total_bill", palette="Set2")
# 添加标题
g.fig.subplots_adjust(top=0.9) # 为标题腾出空间
g.fig.suptitle('按时间和吸烟状态分组的账单金额分布', fontsize=16)
# 设置坐标轴标签
g.set_axis_labels("星期", "账单金额")
g.set_titles(col_template="{col_name}时段", row_template="{row_name}")
plt.show()
使用FacetGrid绘制不同类型的图
FacetGrid不仅限于绘制同一类型的图,还可以应用不同的可视化函数:
# 创建分组的散点图,并添加回归线
g = sns.FacetGrid(tips, col="sex", row="smoker", height=4)
# 映射regplot函数
g.map_dataframe(sns.regplot, x="total_bill", y="tip",
scatter_kws={"s": 50, "alpha": 0.7},
line_kws={"color": "red"})
g.add_legend()
plt.show()
2. 成对关系图:pairplot()
当我们想要探索数据集中多个变量之间的关系时,pairplot()函数非常有用,它可以创建变量之间两两配对的散点图矩阵:
# 使用鸢尾花数据集
iris = sns.load_dataset("iris")
# 绘制成对关系图
sns.pairplot(iris,
hue="species", # 按种类着色
height=2.5, # 子图大小
diag_kind="kde", # 对角线图形类型:"hist"或"kde"
markers=["o", "s", "D"], # 不同组的标记类型
palette="Set2") # 调色板
plt.suptitle('鸢尾花数据集的成对关系图', y=1.02, fontsize=16)
plt.show()
pairplot()会在对角线上绘制每个变量的分布图,在非对角线位置绘制两个变量之间的散点图,非常适合探索性数据分析。
3. 自定义配色方案
Seaborn提供了丰富的调色板选项,可以根据数据类型和可视化目的选择合适的配色方案。
使用预设调色板
# 展示Seaborn预设调色板
plt.figure(figsize=(12, 8))
# 创建调色板列表
palettes = ["deep", "muted", "pastel", "bright", "dark", "colorblind"]
# 绘制每种调色板
for i, palette in enumerate(palettes):
plt.subplot(3, 2, i+1)
# 创建5种颜色的调色板
current_palette = sns.color_palette(palette, 5)
# 显示调色板
sns.palplot(current_palette)
plt.title(palette)
plt.tight_layout()
plt.show()
自定义连续调色板
# 创建不同类型的连续调色板
plt.figure(figsize=(12, 8))
# 单色调色板
plt.subplot(3, 1, 1)
sns.palplot(sns.light_palette("seagreen", 10))
plt.title("单色淡色调色板 (light_palette)")
# 单色深色调色板
plt.subplot(3, 1, 2)
sns.palplot(sns.dark_palette("purple", 10))
plt.title("单色深色调色板 (dark_palette)")
# 双色渐变
plt.subplot(3, 1, 3)
sns.palplot(sns.color_palette("coolwarm", 10))
plt.title("双色渐变调色板 (coolwarm)")
plt.tight_layout()
plt.show()
在图表中应用自定义调色板
# 在图表中应用自定义调色板
plt.figure(figsize=(12, 6))
# 创建自定义调色板
custom_palette = sns.color_palette("husl", 5)
# 应用到条形图
sns.barplot(x="day", y="total_bill",
hue="smoker",
palette=custom_palette,
data=tips)
plt.title('使用自定义调色板的条形图', fontsize=15)
plt.show()
四、实战练习:多维度数据分析
在这个练习中,我们将使用Seaborn对一个真实数据集进行多维度分析和可视化。我们将使用Seaborn内置的钻石数据集,它包含了近54,000颗钻石的价格和属性数据。
1. 数据准备与探索
import seaborn as sns
# 加载钻石数据集
diamonds = sns.load_dataset("diamonds")
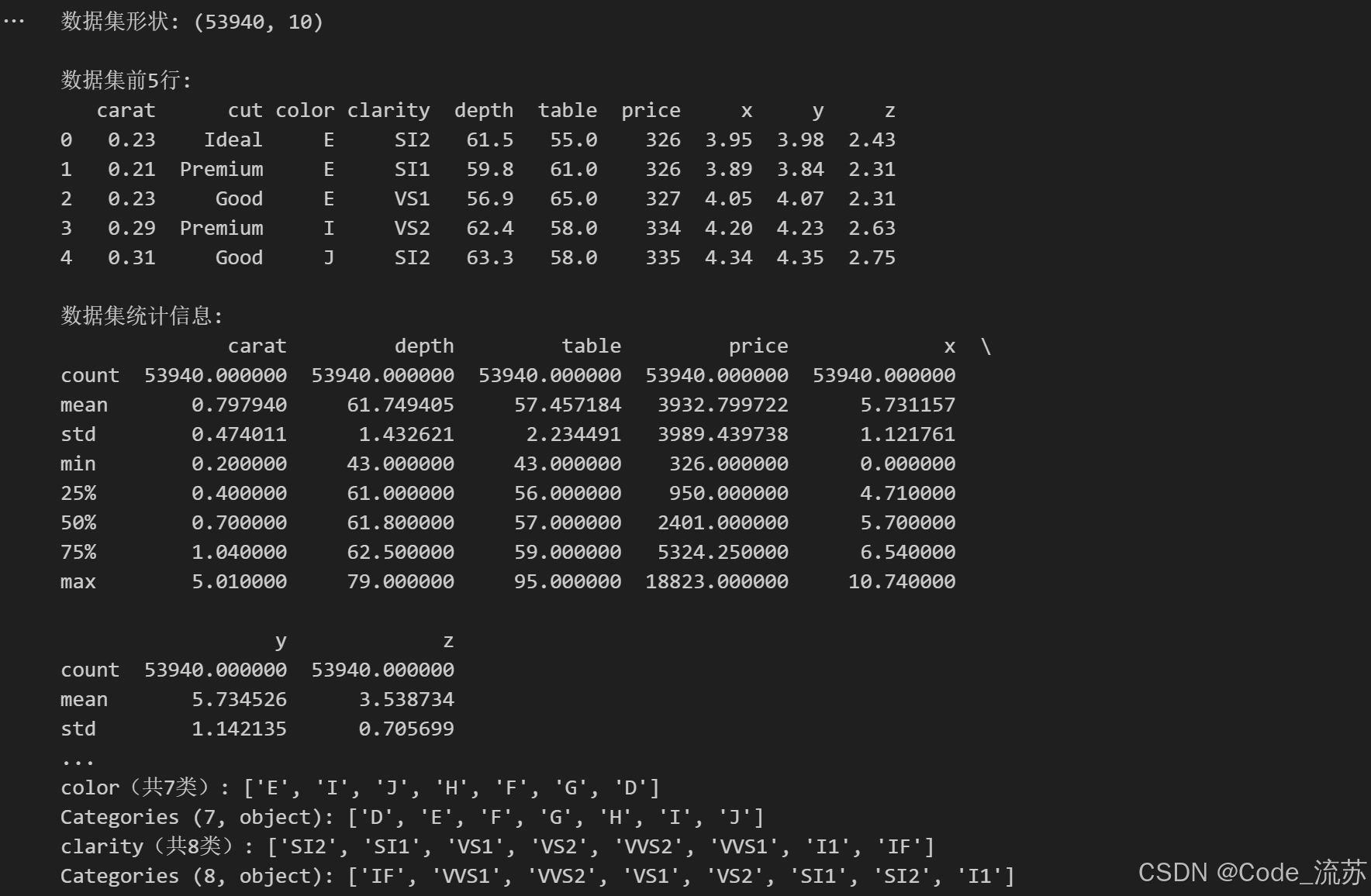
# 查看数据集形状
print("数据集形状:", diamonds.shape)
# 查看前5行数据
print("\n数据集前5行:")
print(diamonds.head())
# 查看数值型字段的统计信息
print("\n数据集统计信息:")
print(diamonds.describe())
# 查看分类变量的唯一值
print("\n分类变量的唯一值:")
for col in ['cut', 'color', 'clarity']:
unique_vals = diamonds[col].unique()
print(f"{col}(共{len(unique_vals)}类): {unique_vals}")
输出结果:
2. 多维度可视化分析
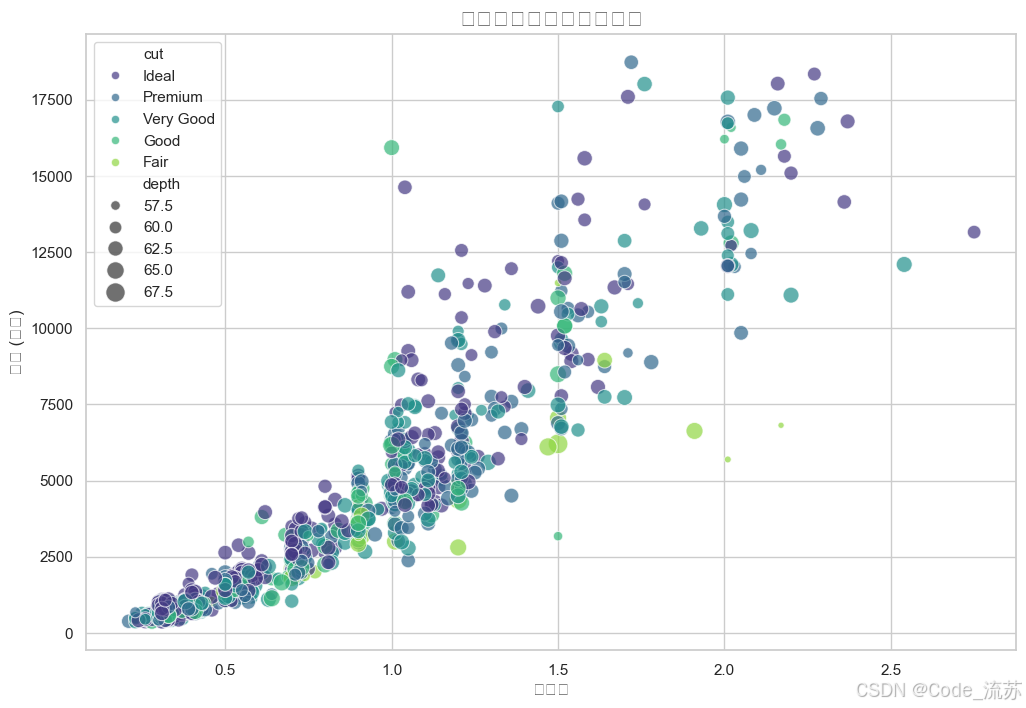
价格与克拉数的关系
# 设置Seaborn风格
sns.set_theme(style="whitegrid")
# 绘制价格与克拉数的散点图
plt.figure(figsize=(12, 8))
sns.scatterplot(x="carat", y="price",
hue="cut", # 按切工质量着色
size="depth", # 按深度调整点大小
palette="viridis", # 使用viridis调色板
sizes=(20, 200), # 点大小范围
alpha=0.7, # 透明度
data=diamonds.sample(1000)) # 为了性能,随机抽样1000颗钻石
plt.title('钻石价格与克拉数的关系', fontsize=16)
plt.xlabel('克拉数', fontsize=12)
plt.ylabel('价格 (美元)', fontsize=12)
plt.show()
输出结果:
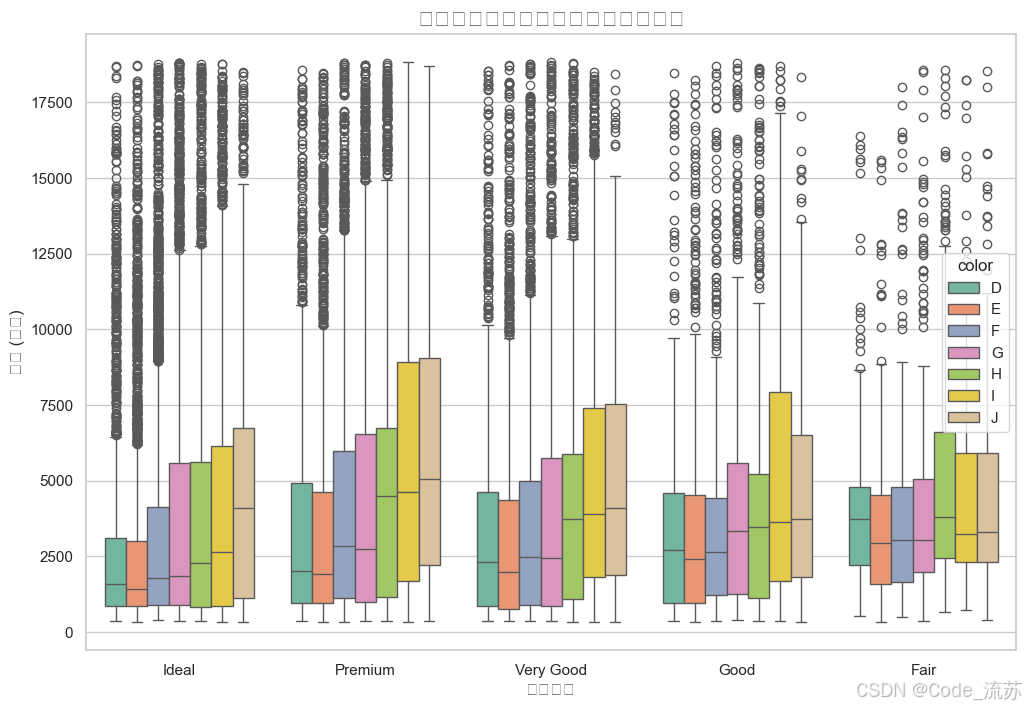
不同切工质量的价格分布
# 绘制不同切工质量的价格分布
plt.figure(figsize=(12, 8))
sns.boxplot(x="cut", y="price",
hue="color", # 按颜色分组
palette="Set2", # 使用Set2调色板
data=diamonds) # 使用全部数据
plt.title('不同切工质量和颜色的钻石价格分布', fontsize=16)
plt.xlabel('切工质量', fontsize=12)
plt.ylabel('价格 (美元)', fontsize=12)
plt.xticks(rotation=0)
plt.show()
输出结果:
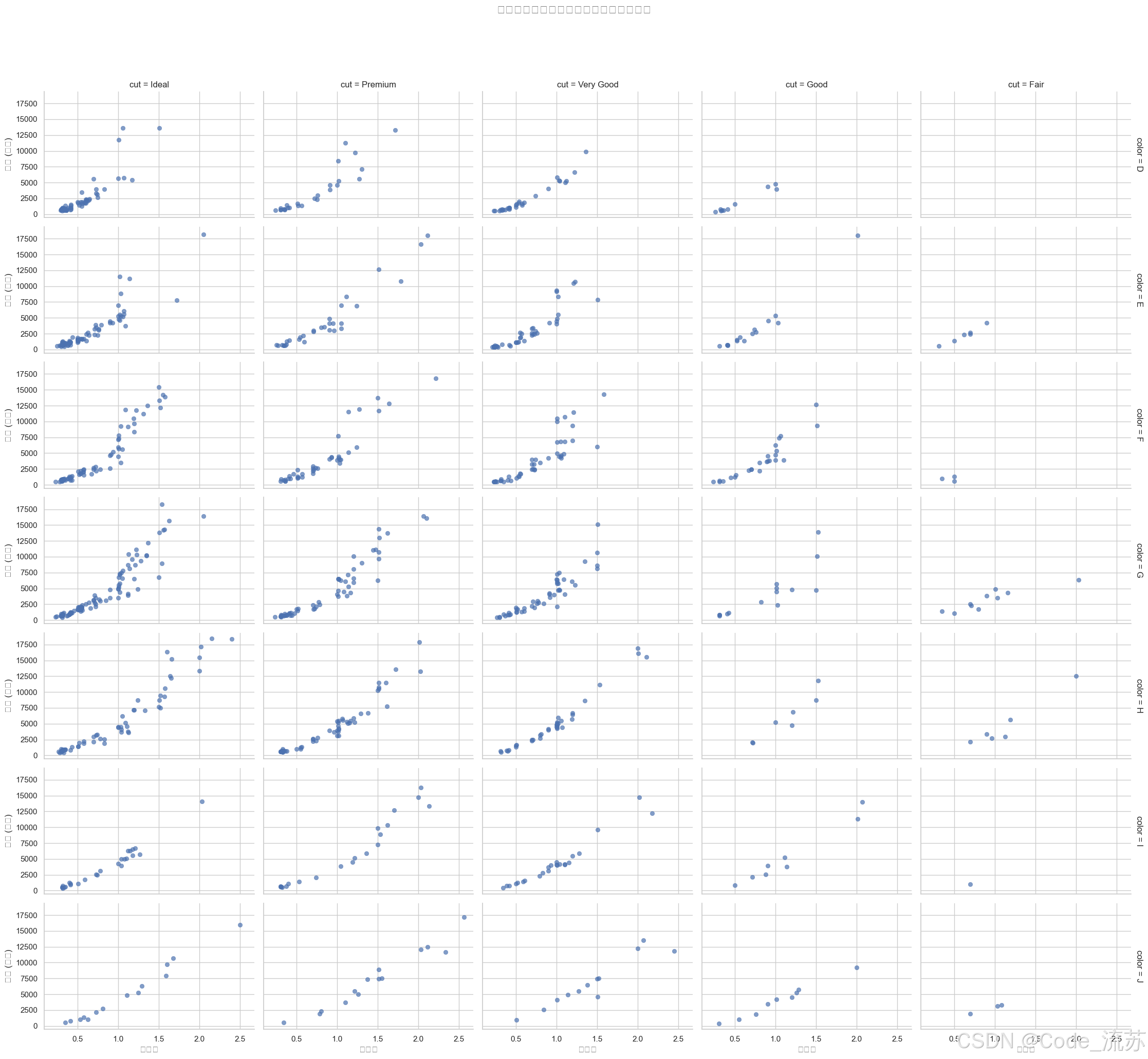
使用FacetGrid创建多个维度的关系图
# 创建按切工质量和颜色分组的散点图
g = sns.FacetGrid(diamonds.sample(1000),
col="cut", # 按列分组变量
row="color", # 按行分组变量
height=3, # 子图高度
aspect=1.5, # 宽高比
margin_titles=True)
# 在每个子图上映射散点图
g.map_dataframe(sns.scatterplot,
x="carat",
y="price",
alpha=0.7,
edgecolor=None)
# 添加标题
g.fig.subplots_adjust(top=0.9)
g.fig.suptitle('不同切工和颜色的钻石价格与克拉数关系', fontsize=16)
# 设置坐标轴标签
g.set_axis_labels("克拉数", "价格 (美元)")
plt.show()
输出结果:
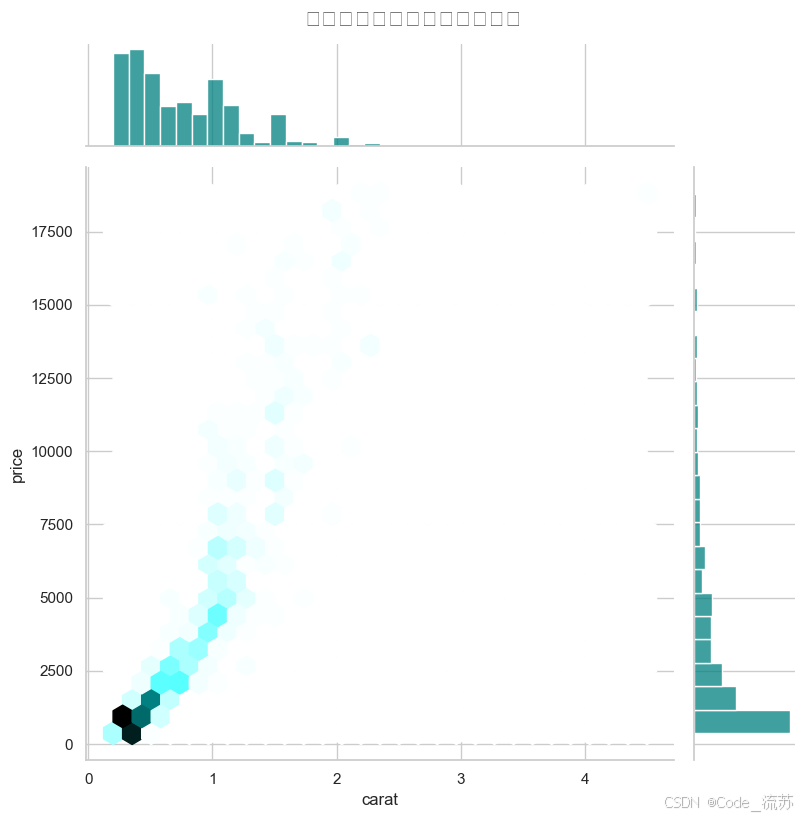
多变量联合分布
# 探索price, carat和depth的联合分布
plt.figure(figsize=(10, 8))
sns.jointplot(x="carat", y="price",
data=diamonds.sample(1000),
kind="hex", # 使用六边形箱
height=8, # 图形大小
ratio=5, # 散点图与边缘分布图的大小比例
color="teal") # 颜色
plt.suptitle('钻石价格与克拉数的联合分布', y=1.02, fontsize=16)
plt.show()
输出结果:
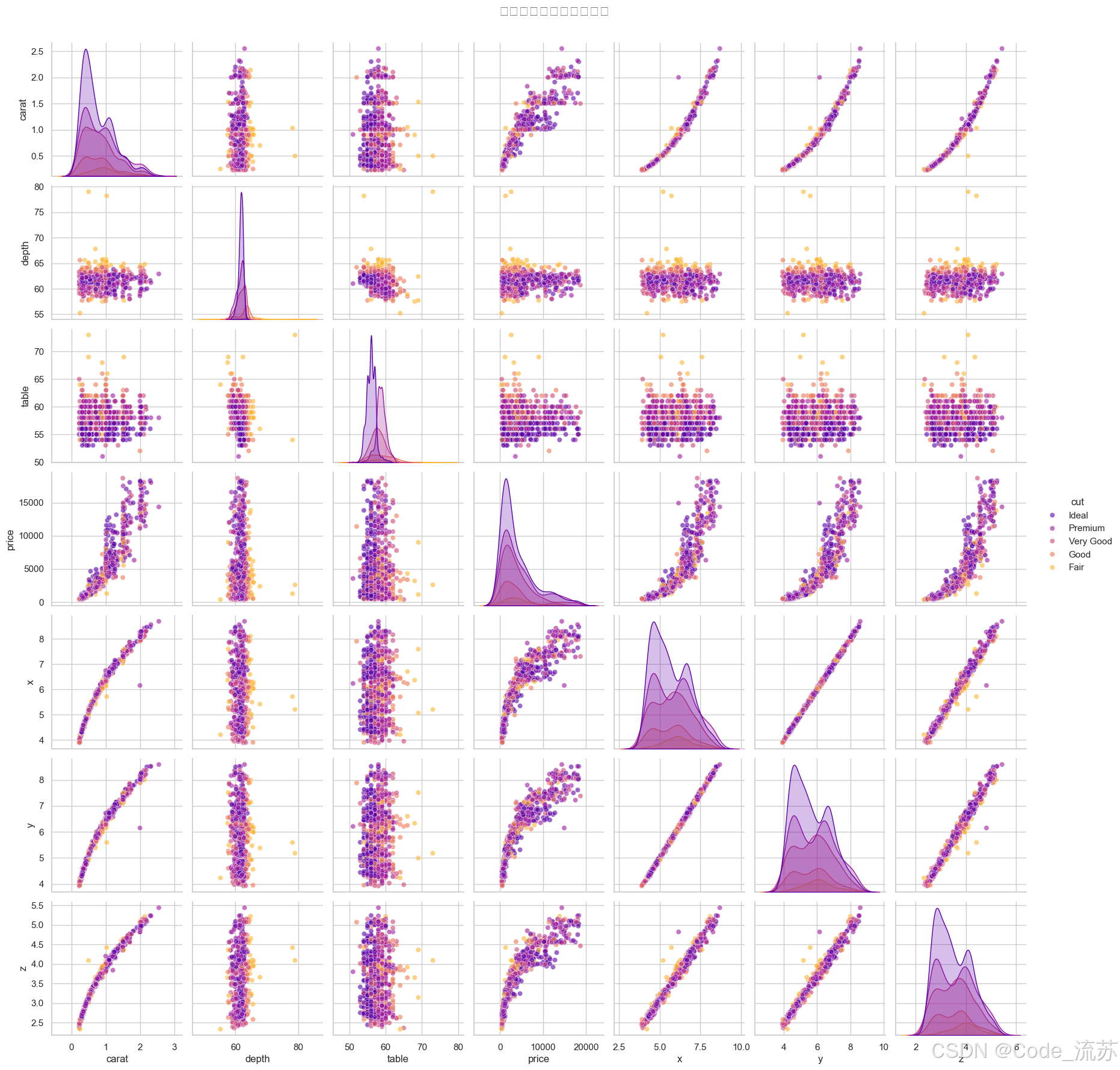
成对关系分析
# 选择数值变量进行成对关系分析
diamonds_sample = diamonds.sample(1000) # 抽样以提高性能
numeric_cols = ['carat', 'depth', 'table', 'price', 'x', 'y', 'z']
# 绘制成对关系图
sns.pairplot(diamonds_sample[numeric_cols + ['cut']],
hue="cut", # 按切工质量着色
height=2.5, # 子图大小
diag_kind="kde", # 对角线图形类型
plot_kws={"alpha": 0.6}, # 散点图参数
palette="plasma") # 调色板
plt.suptitle('钻石数据集的成对关系图', y=1.02, fontsize=16)
plt.show()
输出结果:
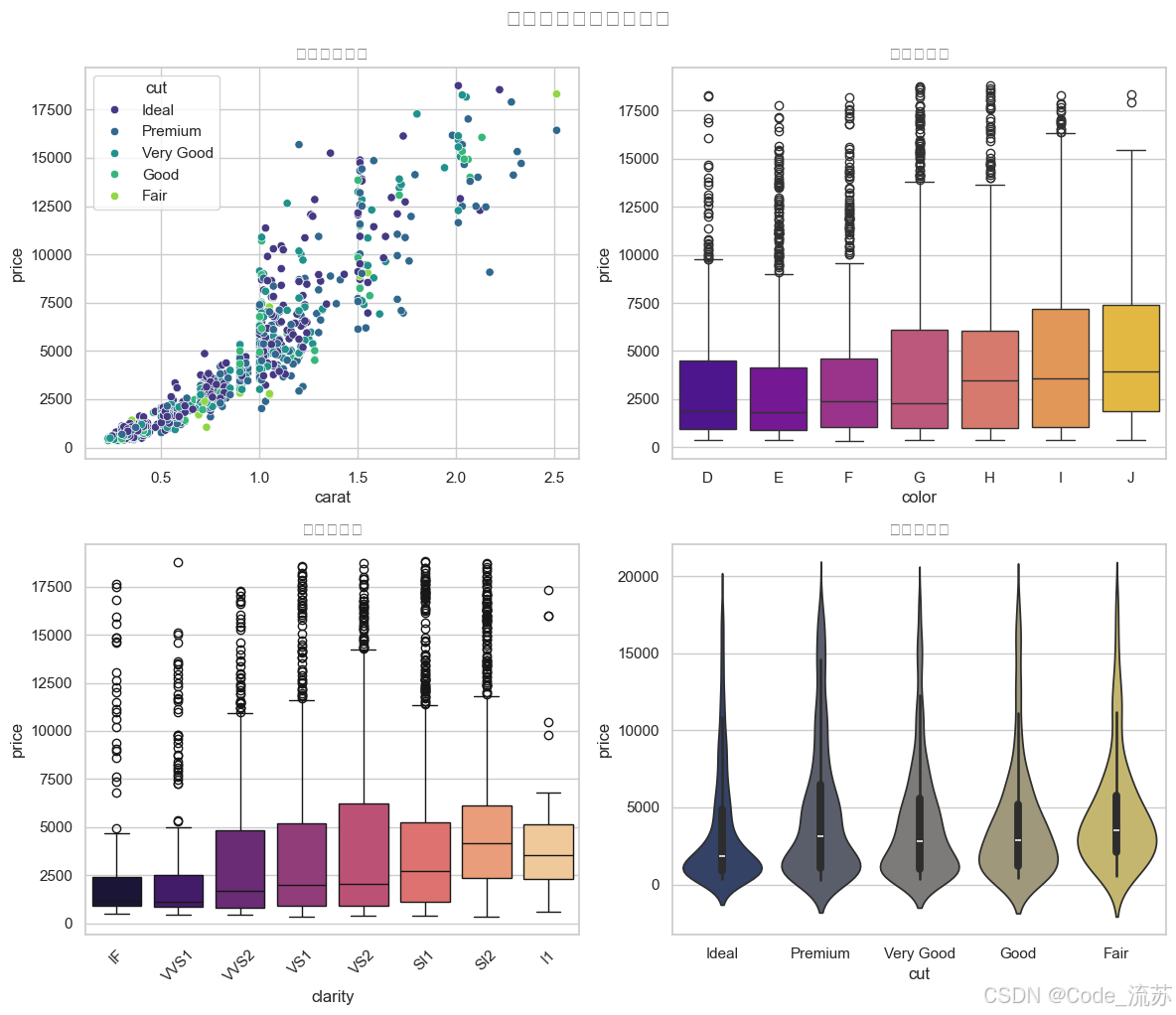
3. 价格预测因素分析
# 分析哪些因素对钻石价格影响最大
plt.figure(figsize=(12, 10))
# 创建一个包含4个子图的面板
plt.subplot(2, 2, 1)
sns.scatterplot(x="carat", y="price",
hue="cut", palette="viridis",
data=diamonds.sample(1000))
plt.title('克拉数与价格')
plt.subplot(2, 2, 2)
sns.boxplot(x="color", y="price",
palette="plasma",
data=diamonds.sample(5000))
plt.title('颜色与价格')
plt.subplot(2, 2, 3)
sns.boxplot(x="clarity", y="price",
palette="magma",
data=diamonds.sample(5000))
plt.title('净度与价格')
plt.xticks(rotation=45)
plt.subplot(2, 2, 4)
sns.violinplot(x="cut", y="price",
palette="cividis",
data=diamonds.sample(5000))
plt.title('切工与价格')
plt.tight_layout()
plt.suptitle('钻石价格影响因素分析', y=1.02, fontsize=16)
plt.show()
可视化结果:
五、总结与拓展
1. 核心要点回顾
在本文中,我们学习了:
- Seaborn的基本概念:它是建立在Matplotlib基础上的高级统计数据可视化库
- Seaborn与Matplotlib的区别:Seaborn提供了更美观的默认样式和更高级的统计图表
- 分布图:通过
distplot()、kdeplot()等函数可视化数据分布 - 关系图:使用
scatterplot()、lineplot()等探索变量之间的关系 - 分类图:通过
boxplot()、violinplot()等比较不同类别的数据分布 - 图形组合:使用
FacetGrid创建多维度的可视化,实现数据的深入探索 - 自定义配色:利用Seaborn丰富的调色板选项美化可视化效果
2. Seaborn优势总结
- 高级接口:简化了创建常见统计图表的过程
- 美观的默认样式:减少了样式调整的工作量
- 与Pandas无缝集成:直接支持DataFrame作为输入
- 统计功能内置:自动计算并显示置信区间、回归线等统计信息
- 分组可视化能力:轻松实现按类别分组的多维度可视化
3. 进阶学习方向
如果你想进一步提升Seaborn可视化技能,可以探索以下内容:
- 高级统计图表:如回归图(
regplot)、残差图(residplot)、二元核密度图(kdeplot) - 矩阵可视化:使用
heatmap()和clustermap()可视化大型数据矩阵 - 复杂图形定制:深入学习Seaborn与Matplotlib的结合使用,实现高度定制化的可视化
- 交互式扩展:结合Plotly或Bokeh,为Seaborn图表添加交互功能
- 深色模式:使用
set_theme(style="darkgrid")实现暗色背景的可视化效果
4. 学习资源推荐
- 官方文档:Seaborn官方文档
- 图例集:Seaborn示例图库
- 在线教程:Datacamp、Coursera上的Python数据可视化课程
- 书籍:《Python for Data Analysis》和《Python Data Science Handbook》中的可视化章节
在下一篇文章中,我们将探索如何将我们学到的数据分析和可视化技能应用于实际项目,从数据获取、清洗到分析和可视化的完整工作流程。
练习题:
- 尝试使用Seaborn的
lmplot()函数,创建一个包含回归线的散点图,并按照某个分类变量分组。 - 使用任意开放数据集,创建一个FacetGrid,展示至少3个变量之间的关系。
- 探索Seaborn的
catplot()函数,尝试使用不同的kind参数创建不同类型的分类图,比较它们的优缺点。
希望这篇文章能帮助你掌握Seaborn的强大功能,创建更加专业和美观的数据可视化作品!如有问题,欢迎在评论区留言交流!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!

![第一期:[特殊字符] 深入理解MyBatis[特殊字符]从JDBC到MyBatis——持久层开发的转折点[特殊字符]](https://i-blog.csdnimg.cn/direct/d3f8e219c42d4546a1e65476c8549e97.jpeg)