Nat. Rev. Bioeng. | 大语言模型在医学领域的革命性应用
大型语言模型(LLMs),如 ChatGPT,因其对人类语言的理解与生成能力而备受关注。尽管越来越多研究探索其在临床诊断辅助、医学教育等任务中的应用,但关于其发展、实际应用与成效的系统评估仍然缺失。因此,研究人员在本综述中系统梳理了LLMs在医学领域的发展与部署现状,探讨其面临的机遇与挑战。在发展方面,研究人员介绍了现有医学LLMs的构建原理,包括模型结构、参数规模及训练数据来源与规模;在部署方面,研究人员比较了不同LLMs在多种医学任务中的表现,并与先进的轻量级模型进行对比。

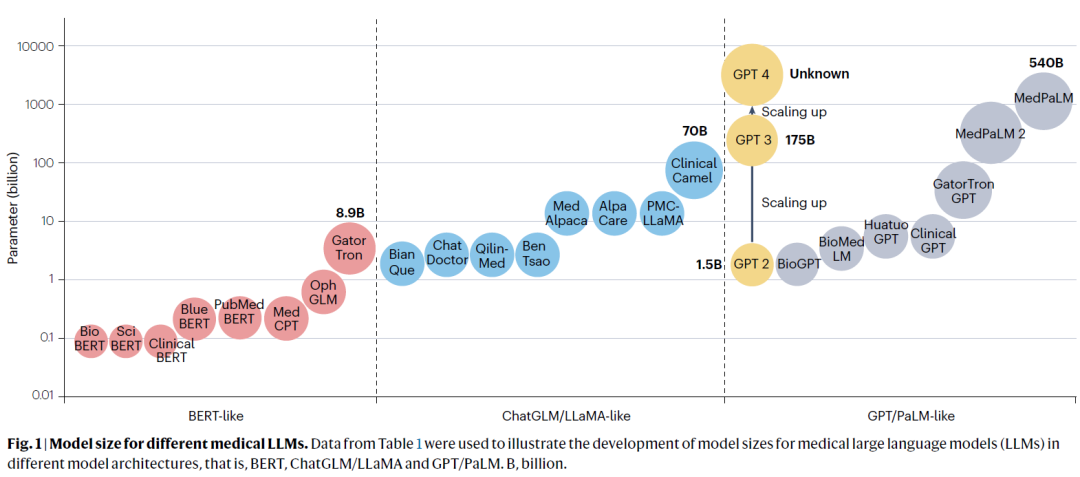
近年来,通用大语言模型(LLMs)如 PaLM、LLaMA、GPT 系列与 ChatGLM,在文本生成、摘要、问答等自然语言处理任务中取得了显著进展,并逐步拓展至医学领域。例如,部分模型在美国医学执照考试(USMLE)中已接近甚至超过人类专家的表现。基于开源LLMs(如LLaMA),研究人员构建了多种医学专用模型,如 ChatDoctor、MedAlpaca、PMC-LLaMA、BenTsao 和 Clinical Camel,以支持临床诊疗和患者管理。
尽管这些模型取得了初步成果,但仍存在诸多限制。例如,大多数模型集中于医学对话与问答场景,实际临床应用中的任务(如电子病历分析、出院小结生成、健康教育与照护计划)尚未被充分挖掘。此外,当前模型在提供实际操作建议方面仍显不足,且测试人群规模有限。
因此,研究人员在本综述中,首先分析了现有医学LLMs的构建原理,详细介绍其模型结构、参数规模及训练数据集;随后评估其在十类生物医学任务中的表现,涵盖判别与生成两类任务;接着,探讨其在七类临床场景中的部署与应用;最后,研究人员指出模型存在幻觉生成、伦理与安全隐患等挑战,并提出未来研究方向。为促进医学LLMs的可信与高效应用,研究人员倡导构建系统性的评估框架,并提供了持续更新的实用指南(https://github.com/AI-in-Health/MedLLMsPracticalGuide)。
医学大语言模型的构建原理
医学LLMs主要通过三种方式构建:从头预训练、基于通用模型微调,以及使用提示对齐通用模型。
预训练
预训练阶段通常使用大规模医学语料(如电子病历、临床记录和医学文献),以掩码语言建模、下一句预测和下一个词预测等目标进行训练。研究人员常用的语料库包括 PubMed、MIMIC-III 和 PMC 等。通过预训练,模型能够学习丰富的医学语言和知识,为后续任务打下基础。
微调
由于从零训练成本高昂,研究人员倾向于在通用模型基础上进行微调,方式包括监督微调(SFT)、指令微调(IFT)和参数高效微调(PEFT)等。SFT通常利用医生与患者对话、医学问答或知识图谱进行继续训练;IFT则使用“指令-输入-输出”三元组提高模型对任务指令的理解;PEFT通过引入轻量参数模块(如 LoRA、Prefix Tuning、Adapter)大幅降低计算开销。
提示学习
提示学习(Prompting)可无需更新模型参数,仅通过设计输入方式(如上下文学习、思维链提示、检索增强生成等)引导模型执行任务。这一策略灵活高效,尤其适用于缺乏训练资源或对实时响应要求较高的医学场景。
医学任务分类
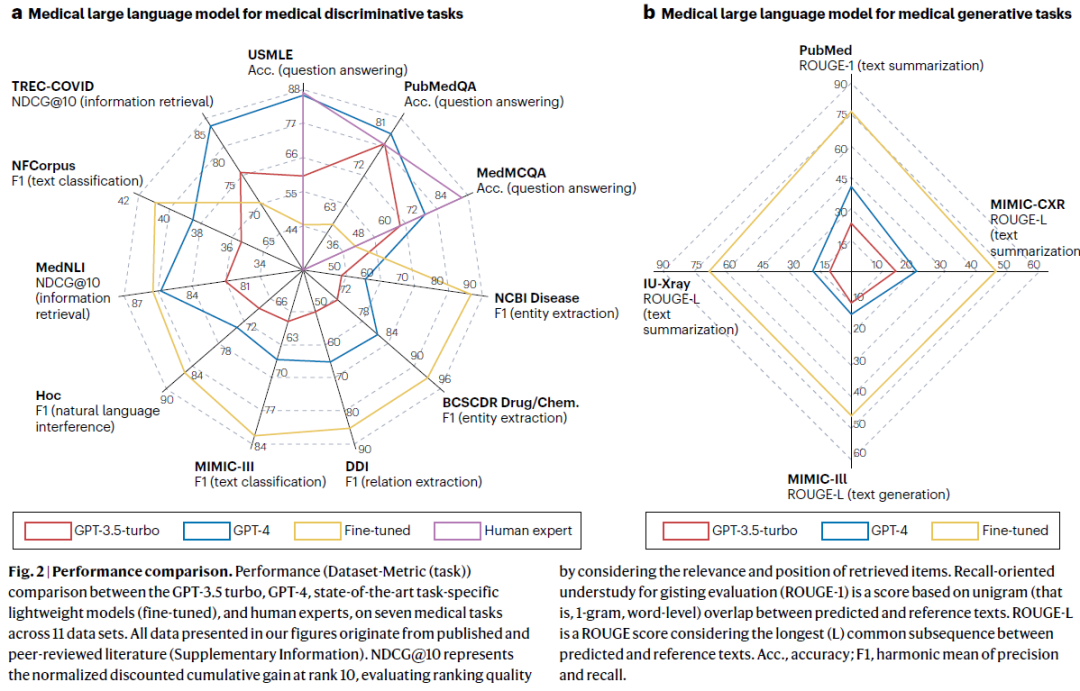
判别式任务
这类任务旨在对医学文本进行分类、抽取或推理,典型包括问答、命名实体识别、关系抽取、自然语言推理和语义相似度计算。研究人员展示了模型在电子病历、临床记录、文献等文本中提取症状、药物、疾病等实体,并能对其进行标准化映射(如 SNOMED、ICD)。
生成式任务
生成任务要求模型依据输入自动撰写医学文本,包括病历摘要、出院指导、医学科普等。相比判别任务,生成任务更具开放性,考验模型语言生成能力和医学知识表达的准确性。
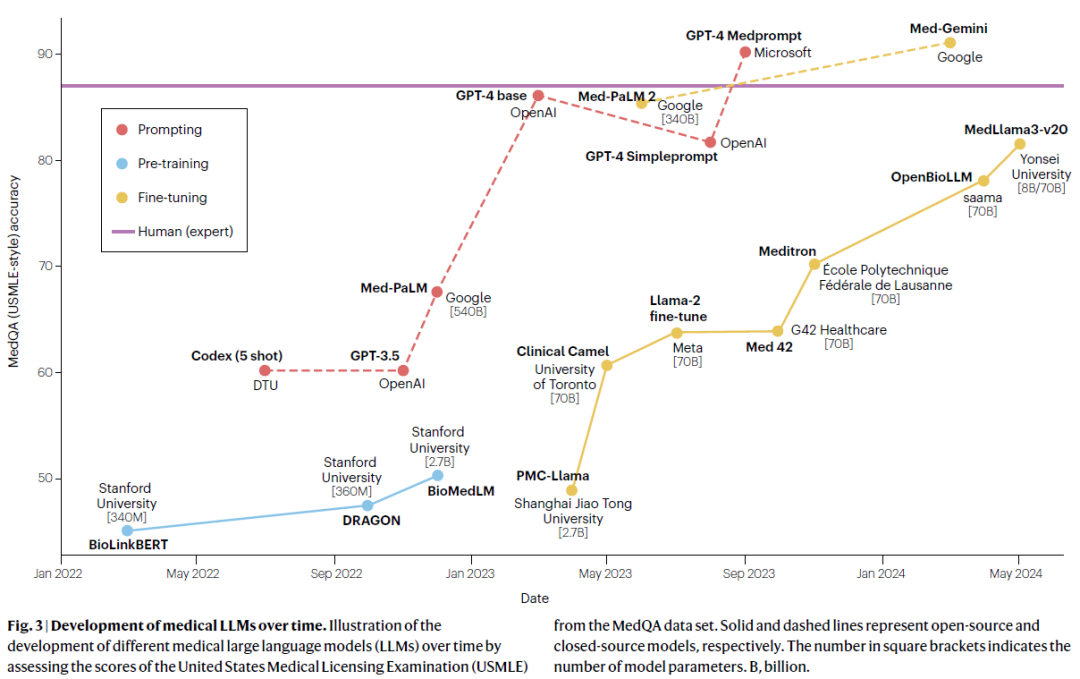
临床应用
医疗决策支持
LLMs可协助医生进行诊断、风险预测、治疗推荐和临床试验匹配。如模型可整合患者病史、检查结果和文献证据,为复杂临床决策提供支持。但目前仍缺乏大规模临床验证。
临床编码
LLMs能自动读取临床文本并生成标准化编码(如 ICD、药物代码、手术代码),大幅提高信息管理效率。研究人员展示了多个模型在真实病历数据上的强编码表现。
报告生成
在放射学、出院记录等任务中,LLMs可生成结构化或摘要报告。部分模型结合图像分析模块,进行多模态报告生成,如 ChatCAD、MAIRA-1 等。尽管在自动评估指标(如ROUGE、BLEU)上表现良好,但临床可接受性仍需进一步评估。
医学机器人
LLMs与机器人系统结合,赋能手术操作、超声控制等任务,提升医疗自动化水平。如 GPT-4 控制的 SuFIA、UltrasoundGPT 等模型,在实验环境中展示了较强的规划与交互能力,但实地部署仍有挑战。
医学语言翻译
医学LLMs可实现跨语言术语转换及面向大众的语言简化,提升医学沟通的可达性。研究人员强调需在医学语义保持、术语准确性和语言平衡间寻求最佳策略,避免误译或信息丢失。
医学教育
研究人员探索了LLMs在医学教育中的应用,包括答疑、教材生成、个性化辅导、病例分析等。部分模型(如 Med-Gemini)结合图像能力,支持多模态教学交互。已在部分高校与医院试点使用。
精神健康支持
专为心理健康设计的LLMs(如 PsyChat、ChatCounselor)可进行文本情绪理解与辅助疏导,辅助心理咨询和早期筛查。但研究人员也指出需关注其伦理边界与应答安全性。
医疗咨询应答
研究人员构建的模型已可应对患者提出的常见问题,涵盖疾病管理、用药建议等场景。部分模型在回答准确性、连贯性及安全性评估中取得较好结果,具备向实际应用过渡的潜力。
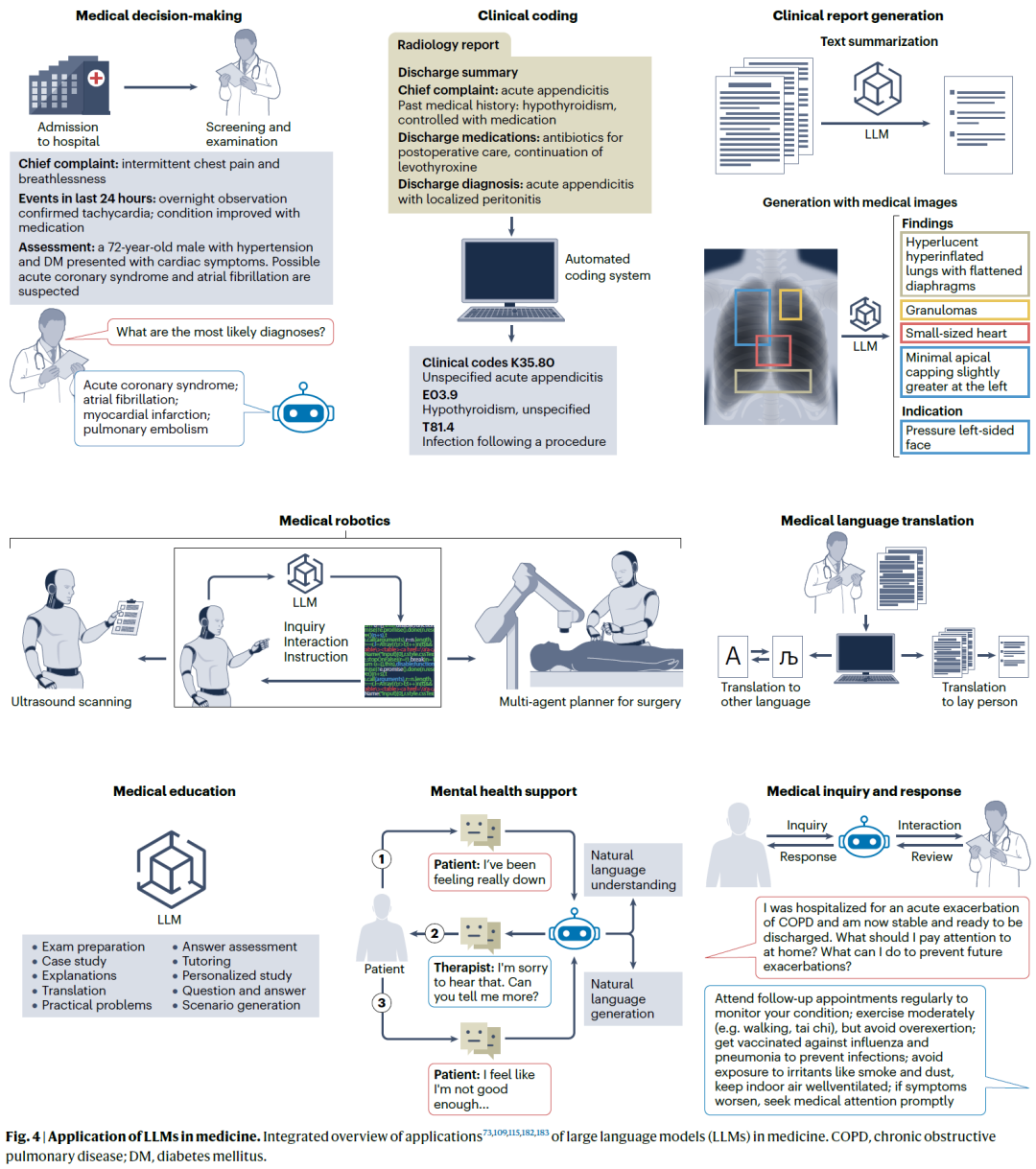
面临的挑战
幻觉生成(Hallucination)
幻觉是指模型生成了不准确或虚构的信息,分为内源性幻觉和外源性幻觉。前者表现为逻辑错误(如错误计算),后者则包括编造引文、回避问题等。在医学应用中,这类看似流畅但事实错误的内容可能误导诊断与治疗,带来严重后果。
研究人员将应对幻觉的策略分为三类:
- 训练阶段修正:通过一致性强化学习或对比学习等方法优化模型权重。
- 生成阶段修正:在推理时加入“推理”机制,如多样输出采样或可信度评分筛查错误。
- 检索增强修正:结合外部文献作为提示,如使用真实资料或链式检索策略。
针对不同场景,这些方法各有优势,例如:训练修正适合结构化任务如影像报告;生成修正适用于多观点医疗问诊;检索增强对需要实时知识更新的任务如治疗建议尤为关键。
缺乏评估基准与指标
现有评估多集中于问答准确性,难以全面衡量医学LLMs的可信度、解释性与有用性。即便有部分数据集对真实健康问询进行了模拟,但仍缺乏系统的评价体系。研究人员呼吁建立覆盖真实性、解释性、专业度等维度的新型评估标准。
医学数据资源受限
当前医学训练数据规模远小于通用语料,导致模型在开源测试集上表现优异,却难以胜任真实任务(如鉴别诊断、个体化治疗)。此外,医学数据通常因伦理、法律和隐私限制而难以获取,多数数据未标注,人力标注与无监督学习受限于专家资源和误差容忍度低。
研究人员通常选择使用少量开源数据对通用模型微调,或尝试使用模型自身生成高质量合成数据。然而,合成数据因上下文单一易导致“灾难性遗忘”,使模型丧失原始知识能力。
新知识适配困难
医学知识更新频繁,训练后的模型难以高效注入新知识。一方面,旧知识难以完全删除,新旧信息的冲突可能引发错误关联;另一方面,新知识更新需具备实时性。
当前的应对策略包括:
- 模型编辑:直接修改模型参数,但通用性和稳定性较差;
- 检索增强生成(RAG):通过外部知识库引入新信息,实现快速更新而无需重新训练模型,虽不能清除旧知识,但能缓解更新滞后问题。
行为对齐不足
行为对齐指确保模型输出符合人类行为预期,尤其是在医疗对话中,模型仍难达到医生的专业水平。
研究人员提出三类对齐方法:
- 指令微调:通过明确任务指令提升模型响应质量;
- 基于人类反馈的强化学习:利用人类评分优化模型输出,常用于医疗聊天机器人与决策系统;
- 提示调优:例如“反思式提示”让模型回顾自身回答并自我修正,提升一致性与准确性。
伦理与安全问题
医学LLMs引发的伦理与隐私争议日益受到关注。例如,有研究反对将ChatGPT用于生物医学论文写作;又如,提示注入可能导致模型泄露敏感数据(如邮箱地址)。这一风险来源于安全训练范围不足以覆盖模型所有能力。
研究人员建议扩大安全训练数据规模,建立系统的安全机制,以防模型在医疗场景中引发信任危机。
展望
尽管大语言模型(LLMs)已通过聊天机器人与搜索引擎影响了大众生活,但其在医疗实践中的应用仍处于初级阶段。当前评估基准多集中于医学问答任务,难以覆盖真实临床场景所需的多种能力。研究人员指出,仅依赖标准化考试(如USMLE)并不足以反映LLMs在实际诊疗中的专业表现。
因此,未来需要构建更全面的评估基准,考察模型是否具备以下能力:引用权威医学资料、适应医学知识不断更新、明确表达不确定性,以及接受临床反馈并持续迭代。同时,公平性、伦理性与健康公平性等因素也应纳入评价,不能仅依赖基础指标(如人口统计学一致性),而应结合情境进行精细化评估。例如,AMIE模型引入了医生对模型的多维度评价(包括临床推理、医患沟通和专业行为),但仍存在可扩展性和适应性不足的问题。
研究人员建议,未来评估体系可融合真实与合成数据,参照临床指南与患者安全标准,开发交互式评估平台,让临床专家实时参与反馈与模型协同测试。
多模态模型(MLLMs)与时序数据挑战
尽管现有LLMs主要针对文本任务,融合视觉、语言甚至音频的多模态大模型(MLLMs)已初现成效。例如,Med-Flamingo、LLaVA-Med、Med-Gemini等模型通过图文数据联合微调,具备放射影像理解能力。一些探索性研究还尝试将音频、图像与文本融合,用于自动牙科诊断,显示出良好潜力。
然而,医学中常见的时间序列数据(如心电图、血压监测)仍很少被有效集成至模型中。未来可探索更高效的多模态数据建模与学习方式,特别是高资源消耗模态(如视频、医学影像)下的成本优化训练方法,同时解决多模态临床数据的采集与访问难题。
基于LLMs的智能代理系统
研究人员提出,结合LLMs与外部工具、环境交互能力的“LLM智能代理”将是重要方向。这类代理可整合多种模态输入,具备推理、学习和反馈能力,能通过类人行为(如角色扮演、沟通协作)解决复杂问题。
例如,Chat-Orthopedist 可通过访问专业数据库(如 UpToDate)获取最新脊柱侧弯知识,向患者提供清晰准确的问答服务。在医疗场景中,智能代理可模拟多个医学角色,协同完成诊断任务,实现从影像到报告的整合与决策。
未来研究可探索:
- 构建兼容LLMs的数据接口,整合来自多设备的监测数据;
- 优化多代理间沟通、真实度控制与安全权限;
- 强化远程实时决策与适应性学习机制,以应对突发医疗情境。
目前医疗LLMs研究主要集中于通用医学领域,导致康复、运动医学等专科领域的研究仍相对缺乏。
医学界的主动参与
至今,大多数医学LLMs由科技公司主导开发,医学界对其训练数据来源、伦理流程与隐私保护关注不足。研究人员呼吁临床专家积极参与LLMs的构建与测试过程,包括:
- 提供高质量医学数据;
- 明确设定模型的期望目标;
- 在真实场景中检验其效益与风险。
通过这些方式,医疗界可以更好地识别与规避潜在法律和临床风险,提升LLMs在医疗中的信任度与实用性。
此外,培养“医学+技术双语人才”也至关重要。未来可探索跨学科培训框架,如在高校建立“双语教育项目”,推动基层诊所数据共享,同时加强隐私保护机制,帮助医院和医生在保障数据安全的前提下引入创新。
参考资料
Liu, F., Zhou, H., Gu, B. et al. Application of large language models in medicine. Nat Rev Bioeng (2025).
https://doi.org/10.1038/s44222-025-00279-5



![第一期:[特殊字符] 深入理解MyBatis[特殊字符]从JDBC到MyBatis——持久层开发的转折点[特殊字符]](https://i-blog.csdnimg.cn/direct/d3f8e219c42d4546a1e65476c8549e97.jpeg)