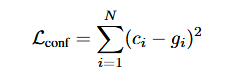论文链接:Retina : Low-Power Eye Tracking with Event Camera and Spiking Hardware
这是一篇发表在2024CVPRW上的文章,做了三个contribution:
- 将SNN放在Eye Tracking任务上。
- 提出了'Ini-30'数据集
- 部署到了Spike硬件上
还是挺有趣的。但是由于没有Spike硬件并且有别的数据集,本文只关注该论文的算法部分。
Methodology
我们为基于事件数据的眼动追踪算法提出了一种低延迟和轻量级的架构和学习规则。我们的网络是一个单一的 SNN,加了BN与卷积,同时卷积还跟着一个神经元,这样输出就可以
原文并没有给出大概的网络结构图,我根据原文画了一个,大概就是这么几个步骤:

尖峰输出通过具有固定权重的一维卷积层转换为连续值。
虽然说是端到端的,但是实际上仍然进行了把事件聚集成帧的操作(感觉某种程度被骗了),通过对数据的预处理,输入的有两种选择,固定时间间隔的聚集成帧,和固定单个帧出现的事件数量,这两种都是比较常见的将事件聚集成帧然后继续处理的方法。
因此,在经过对数据的预处理以后,能拿到64*64的事件帧图像。把这个输入到下图的网络中。为适配硬件,所以设计的是64 * 64 * 2的,这里边的信息实际上又放到了time bins里,最后输入的时候,输入的是五维信息,假设batch_size是32,time bins是40,那么有[32, 40,2,64,64]这样的信息,放进网络进行传递。
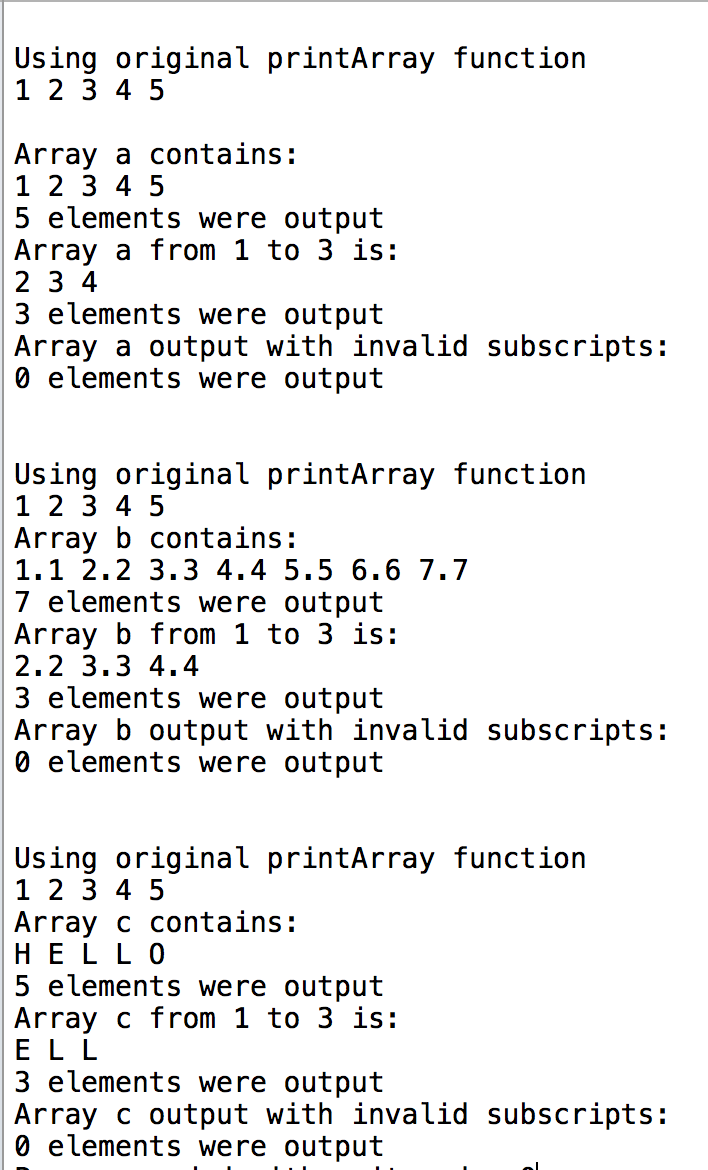
网络配置概述如下表:
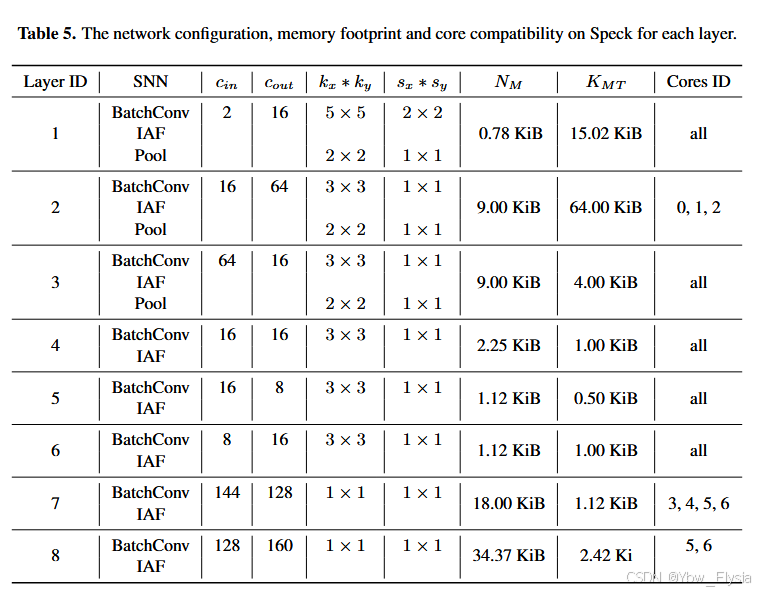
那实际上,在第6层到第7层,进行了一个Flatten,从64*64*2一直拿到第6层的3*3*16以后,然后展平。最后跟了一个时间加权和筛选器,看了一下源码。

这样我就拿到了一个展平的信息了,随后对他进行resize,变成一个[32,40,4,4,10],但是不我太理解具体怎么计算的,回头再看看YOLO。
时间加权和筛选器他称之为突触核与膜核。给了两个公式,实际上是对权重进行了从0,1到float的转化,然后按照不同比例进行转化的,其中还有一个与past information的一个concat。
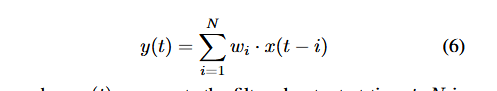
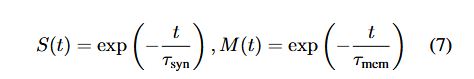
在算loss的时候,它采用了部分的Yolo Loss函数,其中一个是边界框,一个是置信度。