一、介绍
Apache Spark 2.0引入了SparkSession,其目的是为用户提供了一个统一的切入点来使用Spark的各项功能,不再需要显式地创建SparkConf, SparkContext 以及 SQLContext,因为这些对象已经封装在SparkSession中。此外SparkSession允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。
那么在sparkSql模块中,sql各个阶段的解析的核心类则是SessionState,在后续的文章中会多次使用到SessionState的变量,故本节将介绍SessionState是如何构建的
二、构建过程
常见构建sparkSession写法:
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf)
.getOrCreate()
// hive如下:
val spark = SparkSession.builder().config(sparkConf)
.enableHiveSupport()
.getOrCreate()
getOrCreate函数
def getOrCreate(): SparkSession = synchronized {
// SparkSession只能在Driver端创建和访问
assertOnDriver()
// 首先检查是否存在有效的线程本地SparkSession,如果session不为空,且session对应的sparkContext未停止了,返回现有session
var session = activeThreadSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
applyModifiableSettings(session)
return session
}
// 线程同步执行
SparkSession.synchronized {
// 如果当前线程没有活动会话,请从全局会话获取它。
session = defaultSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
applyModifiableSettings(session)
return session
}
// 没有活动或全局默认会话。创建一个新的sparkContext
val sparkContext = userSuppliedContext.getOrElse {
val sparkConf = new SparkConf()
options.foreach { case (k, v) => sparkConf.set(k, v) }
// set a random app name if not given.
if (!sparkConf.contains("spark.app.name")) {
sparkConf.setAppName(java.util.UUID.randomUUID().toString)
}
SparkContext.getOrCreate(sparkConf)
// Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions.
}
// 这里是扩展用户指定的自定义扩展,后面会有一节单独介绍
applyExtensions(
sparkContext.getConf.get(StaticSQLConf.SPARK_SESSION_EXTENSIONS).getOrElse(Seq.empty),
extensions)
// 重点此处构建SparkSession;extensions入参为自定义扩展类,后面会有一节单独介绍。
session = new SparkSession(sparkContext, None, None, extensions)
options.foreach { case (k, v) => session.initialSessionOptions.put(k, v) }
setDefaultSession(session)
setActiveSession(session)
registerContextListener(sparkContext)
}
return session
}
在SparkSession类中有一个核心属性:SessionState,该属性存储着sparksql各个阶段的执行过程,十分重要:
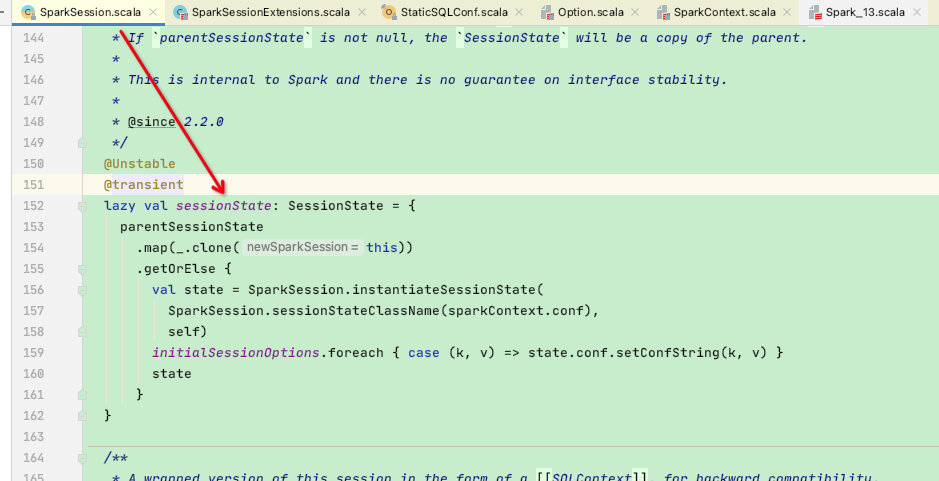
这里看一下SessionState的属性,单单从属性就能看出其重要性,属性中包含了各个阶段的执行类;sql处理的各个阶段几乎都在使用这些变量
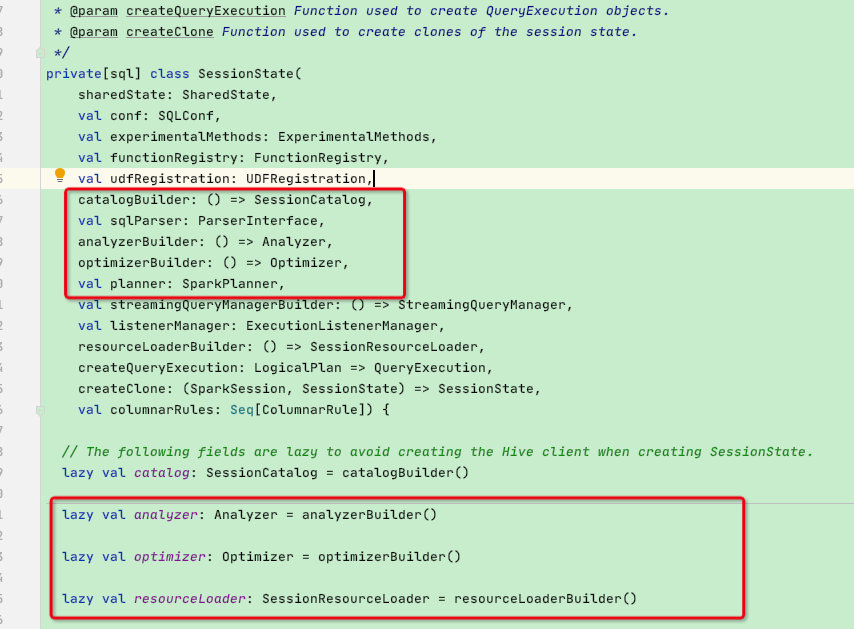
**回到SparkSession构建SessionState过程,这里贴一下源码: **
可以看到先是通过config的CATALOG_IMPLEMENTATION属性分辨构建出两种SessionState:
1、HiveSessionStateBuilder
2、SessionStateBuilder
但最终返回的是统一父类:BaseSessionStateBuilder,而且是通过BaseSessionStateBuilder.build创建SessionState。
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse {
val state = SparkSession.instantiateSessionState( // 调用instantiateSessionState函数构建SessionState
SparkSession.sessionStateClassName(sparkContext.conf), // 调用sessionStateClassName函数确定构建hive还是普通SessionState
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}
// HiveSessionStateBuilder全类名,用于后面反射
private val HIVE_SESSION_STATE_BUILDER_CLASS_NAME =
"org.apache.spark.sql.hive.HiveSessionStateBuilder"
// 当调用enableHiveSupport函数时会将CATALOG_IMPLEMENTATION = hive
def enableHiveSupport(): Builder = synchronized {
if (hiveClassesArePresent) {
config(CATALOG_IMPLEMENTATION.key, "hive")
} else {
throw new IllegalArgumentException(
"Unable to instantiate SparkSession with Hive support because " +
"Hive classes are not found.")
}
}
// 通过config的CATALOG_IMPLEMENTATION属性分辨构建出两种SessionState
private def sessionStateClassName(conf: SparkConf): String = {
conf.get(CATALOG_IMPLEMENTATION) match {
case "hive" => HIVE_SESSION_STATE_BUILDER_CLASS_NAME
case "in-memory" => classOf[SessionStateBuilder].getCanonicalName
}
}
// 注意:这里将hive | in-memory的 className构建成了统一的父类BaseSessionStateBuilder,并且调用了.build()函数
private def instantiateSessionState(
className: String,
sparkSession: SparkSession): SessionState = {
try {
// invoke `new [Hive]SessionStateBuilder(SparkSession, Option[SessionState])`
val clazz = Utils.classForName(className)
val ctor = clazz.getConstructors.head
ctor.newInstance(sparkSession, None).asInstanceOf[BaseSessionStateBuilder].build() // 这里将sparkSession传参进去
} catch {
case NonFatal(e) =>
throw new IllegalArgumentException(s"Error while instantiating '$className':", e)
}
}
接下来看一下BaseSessionStateBuilder的build函数,内容较多这里贴一下核心的代码:
// 构建SessionState
def build(): SessionState = {
new SessionState(
session.sharedState,
conf,
experimentalMethods,
functionRegistry,
udfRegistration,
() => catalog, // catalog元数据,后面会在catalog一节单独介绍
sqlParser, // sql解析核心类
() => analyzer, // analyzer阶段核心类
() => optimizer, // optimizer阶段核心类
planner, // 物理计划和锡类
() => streamingQueryManager,
listenerManager,
() => resourceLoader,
createQueryExecution,
createClone,
columnarRules)
}
// 创建sql解析器
protected lazy val sqlParser: ParserInterface = {
extensions.buildParser(session, new SparkSqlParser(conf))
}
// 创建Analyzer解析器
protected def analyzer: Analyzer = new Analyzer(catalogManager, conf) {
......
}
// 创建optimizer优化器类
protected def optimizer: Optimizer = {
new SparkOptimizer(catalogManager, catalog, experimentalMethods) {
......
}
}
// 创建planner物理计划类
protected def planner: SparkPlanner = {
new SparkPlanner(session, conf, experimentalMethods) {
......
}
}
至此sql各个阶段的核心类创建准备完成,每种核心类的使用会在后面各个阶段的文种中详细展开,这里不赘述。
本节主要介绍了SessionState的构建过程和其核心函数的创建,这在后面各个阶段中会多次提及和使用。