众所周知,python 是面向对象的语言。
但大多数人学习 python 只是为了写出“能够实现某些任务的自动化脚本”,因此,python 更令人熟知的是它脚本语言的身份。
那么,更近一步,如果使用 python 实现并维护一个大的项目,进行软件开发,简单的串并联脚本就难以满足日常繁重的维护需求。
此时需要借鉴其他编程语言的精化,比如说 JAVA 语言中的面向对象的思想。通过将核心功能抽象化并原子化,赋予 python 脚本更高的可维护性。
这篇文章是我读 秦小波 老师的 《设计模式之禅》有感。虽然书里全篇都是Java语言,看不懂,但书中提到的 6 大程序设计原则还是让我受益匪浅。下面我将分别介绍这 6 大原则,并将尝试给出正反例帮助大家理解。
文章目录
- 单一职责原则
- 里氏替换原则
- 依赖倒置原则
- 接口隔离原则
- 迪米特原则
- 开闭原则
单一职责原则
简单理解就是,一个类、或者一个函数,只能承担一项职责。
这一设计思想指导我们,在设计业务逻辑时,要尽可能的剥离不相干的业务,降低业务逻辑的颗粒度,进而实现“原子函数”、“原子类”。
如何有效的鉴别“不相干”的业务,成为了履行单一职责原则的核心难点。一种常见的解释是:类的变更仅由一件业务决定。
一个违反了该原则的案例可以是:
class Tiger:
def walk(self):
print('walk')
def swim(self):
print('swim')
可以看到,老虎类包含了两个方法,走和游泳。然而,游泳的业务和走是相对独立的。所以说, Tiger 类将受到两种变更因素的影响,违背了单一职责的原则。
一种解决方案是将二者剥离,如下:
class Walk_animal():
def walk(self):
print('walk')
class Swim_animal():
def swim(self):
print('swim')
class Tiger(Walk_animal, Swim_animal):
pass
a_tiger = Tiger()
a_tiger.swim()
Tiger 类通过继承父类,获得游泳和走的能力,这种设计很好的遵守了单一职责原则,但凭空增加了两个类,因此在大多数业务实践中,我们也不会这样做。
秦小波 老师的 《设计模式之禅》中是这样解决的:Java 环境下,面向对象的精髓是面向接口编程。
我们通过增加接口来规范类的功能,虽然 python 原生不支持接口,但我们可以使用抽象类来实现接口类。相关教程:python–接口类与抽象类 - 知乎 (zhihu.com)
from abc import abstractmethod, ABCMeta
class Walk_animal(metaclass=ABCMeta):
@abstractmethod
def walk(self): pass
class Swim_animal(metaclass=ABCMeta):
@abstractmethod
def swim(self): pass
class Tiger(Walk_animal, Swim_animal):
def walk(self):
print('walk')
def swim(self):
print('swim')
a_tiger = Tiger()
a_tiger.swim()
这种实现方式看似更复杂,但在大型项目中,可以提高代码的可读性和可维护性。
里氏替换原则
该原则规定了继承操作的要点,通俗解释的话就是,父类能够使用的地方,将父类替换为子类,程序也能正常运行。
具体来说:
- 子类必须完全使用父类的方法;
- 子类可以有自己的个性;
- 覆写方法时,子类对应的参数类型范围只能比父类窄;
- 覆写方法时,子类对应的输出结果的类型只能比父类窄;
可以看到,里氏替换原则关注的焦点是覆写父类方法。因为正常的继承操作是一定满足上述要求的,如下:
class Walk_animal():
def walk(self):
print('walk')
class Swim_animal():
def swim(self):
print('swim')
class Tiger(Walk_animal, Swim_animal):
pass
那么一种违反里氏替换原则的案例可以是:
class do_plus:
def plus(self, addon):
return addon + 1
class math(do_plus):
def plus(self, addon):
return addon + 2
a = do_plus()
assert a.plus(1) == 2
b = math()
assert b.plus(1) == 2
会报错:
Traceback (most recent call last):
File "H:/123123123/main.py", line 65, in <module>
assert b.plus(1) == 2
AssertionError
可见,math 的覆写没有通过父类的测试案例。上述代码改为:
class do_plus:
def plus(self, addon):
return addon + 1
class math(do_plus):
def plus_2(self, addon):
return addon + 2
a = do_plus()
assert a.plus(1) == 2
b = math()
assert b.plus(1) == 2
通过了测试案例,同时子类也有了自己的个性,很好的满足了里氏替换原则的前两条。
事实上,第一条,子类必须完全使用父类的方法 更多是针对接口类的继承,接口类中的抽象方法是一定要继承的。
另一方面,后两条,则可以通过下面一段代码展示:
from typing import Union
class do_plus:
def plus(self, addon: int) -> float:
return float(addon) + 1
class math(do_plus):
def plus(self, addon: Union[int, float]) -> Union[int, float]:
return addon + 1
a = do_plus()
a_results = a.plus(1)
assert type(a_results) == float
b = math()
b_results = b.plus(1)
assert type(b_results) == float
运行后,报错信息如下:
Traceback (most recent call last):
File "H:/123123123/main.py", line 70, in <module>
assert type(b_results) == float
AssertionError
可以看到,math 拓宽了 do_plus 类的应用范围,输入类型增加了浮点型。这点是正确的,符合里氏替换原则的第三条。但输出时的类型也拓宽了,因此没有通过原有测试案例的类型检查。
解决办法就是约束输出的变量类型,如下:
from typing import Union
class do_plus:
def plus(self, addon: int) -> float:
return float(addon) + 1
class math(do_plus):
def plus(self, addon: Union[int, float]) -> float:
return float(addon) + 1
a = do_plus()
a_results = a.plus(1)
assert type(a_results) == float
b = math()
b_results = b.plus(1)
assert type(b_results) == float
总的来说,检验里氏替换原则的最简单方法就是,子类能够通过所有情况下的父类的测试案例。
依赖倒置原则
该原则在面向对象的语境下指:
- 高层模块不应该依赖于低层模块,二者均应该依赖其抽象。
- 抽象不应该依赖细节,细节应该依赖于抽象。
所谓抽象就是指接口类,细节就是实例化的接口类。
依赖倒置原则指,面向对象编程的核心是面向接口编程,即不同类之间的依赖耦合在接口层上就已经实现。
一种不满足依赖倒置原则的情况可以是:
class ase_optimizer():
def __init__(self):
self.name = 'ASE'
def ase_check(self):
print('ase check')
class xtb_optimizer():
def __init__(self):
self.name = 'xTB'
def xtb_check(self):
print('xtb check')
class checker():
def __init__(self, optimizer):
self.optimizer = optimizer
def check(self):
if self.optimizer.name == 'ASE':
self.optimizer.ase_check()
elif self.optimizer.name == 'xTB':
self.optimizer.xtb_check()
a = checker(ase_optimizer())
a.check()
这段代码中,高层模块 checker 通过调用低层模块 optimizer 完成业务逻辑,没有用到接口类,三个类均为细节,因此我们说,这是以细节为基础搭建起来的架构。
一个很显然的弊端在于:
if self.optimizer.name == 'ASE':
self.optimizer.ase_check()
elif self.optimizer.name == 'xTB':
self.optimizer.xtb_check()
如果需要增加优化器,我们要修改 checker 类,如下:
if self.optimizer.name == 'ASE':
self.optimizer.ase_check()
elif self.optimizer.name == 'xTB':
self.optimizer.xtb_check()
elif self.optimizer.name == 'gauss':
self.optimizer.gauss_check()
显然,低层业务逻辑的变动,惊动了高层业务逻辑,因此我们说,违反了依赖倒置原则。
一种改进方法如下:
from abc import abstractmethod, ABCMeta
class opt_check(metaclass=ABCMeta):
@abstractmethod
def check(self): pass
class ase_optimizer(opt_check):
def __init__(self):
self.name = 'ASE'
def check(self):
print('ase check')
class xtb_optimizer(opt_check):
def __init__(self):
self.name = 'xTB'
def check(self):
print('xtb check')
class checker():
def __init__(self, optimizer):
self.optimizer = optimizer
def check(self):
self.optimizer.check()
a = checker(ase_optimizer())
a.check()
可以看到,业务逻辑大大简化,此时如果需要新增逻辑,如下所示:
from abc import abstractmethod, ABCMeta
class opt_check(metaclass=ABCMeta):
@abstractmethod
def check(self): pass
class ase_optimizer(opt_check):
def __init__(self):
self.name = 'ASE'
def check(self):
print('ase check')
class xtb_optimizer(opt_check):
def __init__(self):
self.name = 'xTB'
def check(self):
print('xtb check')
class gauss_optimizer(opt_check):
def __init__(self):
self.name = 'gauss'
def check(self):
print('gauss check')
class checker():
def __init__(self, optimizer):
self.optimizer = optimizer
def check(self):
self.optimizer.check()
a = checker(ase_optimizer())
a.check()
可以看到,虽然我们新增了一个低层类,但在高层 checker 上完全看不到影响。
这就是面向接口编程的奇妙之处:我们通过接口,预先指定了方法 check,因此高层在调用时,不需要了解具体的低层实现,只要知道低层,有这个 check 方法就可以完成业务逻辑的搭建。
这样带来的好处是:
- 利于并行开发。比如说10个人开发10个子类,如果按照第一种实现方式,每一个人完成开发后都需要改动高层类,这会带来潜在的风险。
- 高层类和低层类相对解耦,可以分别进行测试。
然而,做到这一步并没有完全实现依赖倒置原则。因为该原则第一条指出,高层模块也要依赖于抽象。
我们上面的改动只是实现了,低层模块依赖于抽象(接口),高层模块并没有依赖接口。我们只是利用接口简化了部分业务逻辑。
事实上,这依然是一种短视的行为。
因为我们无法预知,现在所谓的高层模块会不会在未来,也变成了庞大业务逻辑中的一个低层模块。
真正满足依赖倒置原则的实现如下:
from abc import abstractmethod, ABCMeta
class opt_check(metaclass=ABCMeta):
@abstractmethod
def opt_check(self): pass
class chk_check(metaclass=ABCMeta):
@abstractmethod
def __init__(self, optimizer: opt_check): pass
@abstractmethod
def chk_check(self): pass
class ase_optimizer(opt_check):
def opt_check(self):
print('ase check')
class checker(chk_check):
def __init__(self, optimizer: opt_check):
self.optimizer = optimizer
def chk_check(self):
self.optimizer.opt_check()
class auto_checker():
def check(self, a_checker: checker):
a_checker.chk_check()
a = auto_checker()
a.check(a_checker=checker(optimizer=ase_optimizer()))
我们首先通过两个接口 opt_check 和 chk_check ,搭建了清晰的业务逻辑框架。
from abc import abstractmethod, ABCMeta
class opt_check(metaclass=ABCMeta):
@abstractmethod
def opt_check(self): pass
class chk_check(metaclass=ABCMeta):
@abstractmethod
def __init__(self, optimizer: opt_check): pass
@abstractmethod
def chk_check(self): pass
剩余部分只是对抽象的具体实现,即细节
class ase_optimizer(opt_check):
def opt_check(self):
print('ase check')
class checker(chk_check):
def __init__(self, optimizer: opt_check):
self.optimizer = optimizer
def chk_check(self):
self.optimizer.opt_check()
可以看到,细节实现时,按照抽象的指示,填补空缺即可。此外,更高层调用高层时,依然满足依赖倒置原则:
class auto_checker():
def check(self, a_checker: checker):
a_checker.chk_check()
因为 checker 模块已经被定死了。
至此,我们完全实现了依赖倒置原则,搭建了以 抽象 为框架的业务逻辑。这部分是完全独立的,可以看作业务实现的草稿,更像是论文写作的大纲。
总的来说,依赖倒置原则对编程人员的架构能力要求很高,面向接口编程也因此成为了面向对象编程的精髓。
接口隔离原则
在面向接口的程序设计理念下,我们需要先确定业务逻辑框架,再去实现细节。因此,在设计接口时,其颗粒度要尽可能的小,不然抽象类的实例会实现一些没有必要的功能。
from abc import abstractmethod, ABCMeta
class teach(metaclass=ABCMeta):
@abstractmethod
def teach_eng(self): pass
@abstractmethod
def teach_math(self): pass
class teacher(teach):
def teach_eng(self):
print('teach english')
def teach_math(self):
print('teach math')
class eng_class():
def start_class(self, eng_teacher: teacher):
eng_teacher.teach_eng()
class math_class():
def start_class(self, math_teacher: teacher):
math_teacher.teach_math()
可以看到,实际业务逻辑中,英语课并不需要老师教数学。显然,我们 teacher 接口的设计是失败的。
将其拆分为两个接口,如下:
from abc import abstractmethod, ABCMeta
class eng_teach(metaclass=ABCMeta):
@abstractmethod
def teach_eng(self): pass
class math_teach(metaclass=ABCMeta):
@abstractmethod
def teach_math(self): pass
class eng_teacher(eng_teach):
def teach_eng(self):
print('teach english')
class math_teacher(math_teach):
def teach_math(self):
print('teach math')
class eng_class():
def start_class(self, eng_teacher: eng_teacher):
eng_teacher.teach_eng()
class math_class():
def start_class(self, math_teacher: math_teacher):
math_teacher.teach_math()
上述为两个接口的简易拆分,值得注意的是,接口并不是颗粒度越小越好,因为这另一方面会无端增加接口数量。
事实上,在复杂业务逻辑的实践中,我们应该把相似功能的捆绑在一起,在保证接口纯洁性的同时,尽量降低接口数量。
下图为一种接口设计:
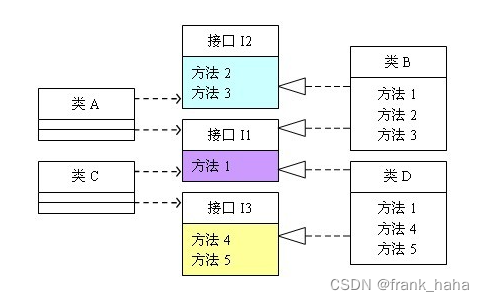
原博客
该设计中,高层模块 A 调用了低层模块 B,而低层模块 B 通过接口 I1, I2 实现了方法 1,2,3
通过整合相似功能,这种设计很好的体现了接口隔离原则。
总的来说,接口隔离原则理念上和最开始的单一职责原则类似,都在讲原子化。二者的区别在于,单一职责原则的对象是类,是实例。接口隔离原则面向的是接口,因为“面向接口编程”的理念被单独列出。
迪米特原则
该原则指出:一个对象应该对其他对象了解的越少越好。
一个违反了迪米特原则的例子如下:
class products():
def __init__(self, year):
self.year = year
class employee():
def query_products(self, query_year: int):
print(f'{query_year} has products 100')
class Boss():
def query(self, a_employee: employee, products_year: int):
prod = products(year=products_year)
a_employee.query_products(query_year=prod.year)
b = Boss()
employee_A = employee()
b.query(a_employee=employee_A, products_year=2000)
程序设计的本意是,老板通过员工获知产品信息。
老板和员工是直接朋友,然而,老板方法里冒出了 products 类,并与其产生了交流。
修改后如下所示:
class products():
def __init__(self, year):
self.year = year
class employee():
def query_products(self, query_year: int):
prod = products(year=query_year)
print(f'{prod.year} has products 100')
class Boss():
def query(self, a_employee: employee, products_year: int):
a_employee.query_products(query_year=products_year)
b = Boss()
employee_A = employee()
b.query(a_employee=employee_A, products_year=2000)
老板告知员工查询哪一年,员工据此查库存,符合我们的设计逻辑。
总的来说,迪米特法则的理念是类间解耦,弱耦合。但这会增加大量的跳转类。比如上例中,employee 就是一个跳转类,事实上,查库存的操作完全可以有老板类自己完成。所以在采用这一原则时,需要反复权衡,既要让结构清晰,又要做到高内聚低耦合。
开闭原则
开闭原则是面向对象编程的极致追求。它要求我们,软件开发过程中对扩展开放,对修改关闭。
也就是说,已经写好的代码,不能再动。如果有新的业务需求,只要在原有基础上拓展即可,因此对程序架构能力提出了极高的要求。
实现开闭原则的重要途径就是面向接口编程,如依赖倒置原则那一节所举的例子,在良好定义接口的前提下,我们可以轻松完成拓展,但又不会影响现有业务逻辑,最大程度上降低了增量开发带来的风险。
开闭原则并没有像前5条原则一样,有着清晰的定义和指导。它更多的是一种口号,是架构师的终极目标。




![【二叉树的顺序结构:堆 堆排序 TopK]](https://img-blog.csdnimg.cn/98dc1528f9bc41c3b64be6f060c1ae8f.png)