01:REST
指的是客户端和服务器之间的交互在请求之间是无状态的,从客户端到服务器的每个请求都必须包含理解请求所必须的信息,同时在请求之间的任意间隔时间点,若服务器重启,那么客户端是得不到相应的通知的.所以无状态的请求可以由任何可用的服务器回答.
在REST样式的Web服务中,每个资源都有一个地址,资源本身都是用过方法调用的目标,这些方法都是标准方法: PUT,GET,POST.
理解就是想要对互联网上的资源进行操作,就必须向资源所在的服务器发出请求,请求体重必须包含资源的网络路径,以及对资源进行的操作.
02倒排索引
下图为正排(索引对应着文本内容)

下图为倒排(以文本内容为key,id为内容)

03和mysql对应关系
es是面向文档的数据库,一条数据在这里就是一个文档,下面给出对应关系:

es里的index可以看成一个数据库,type看成数据表(逐渐被弱化7.x版本后已被删除),documents相当于行.
04索引常用命令
1.put命令用于向es服务器发出添加索引的请求:若重复添加想用的索引,会报错
eg:http://192.168.41.131:9200/shopping 向虚拟机中的服务器添加shopping索引
2.索引查询:
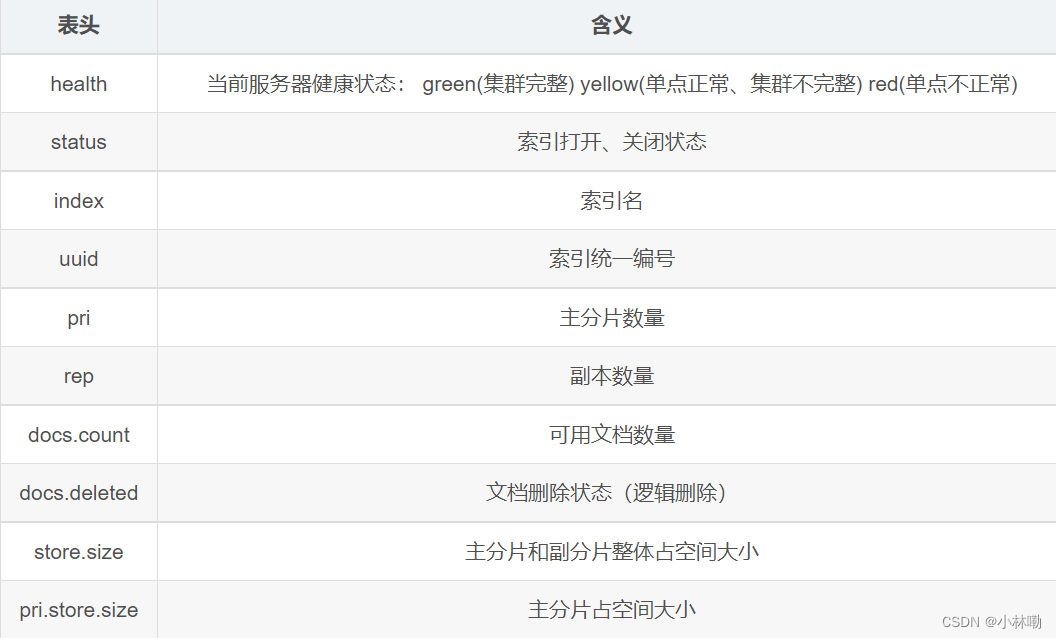
2.1查询所有的索引
http://192.168.41.131:9200/_cat/indices?v
其中_cat表示查看的意思, indices表示索引

2.2单个索引查询:
http://192.168.41.131:9200/shopping 也就是在后面加上索引名字

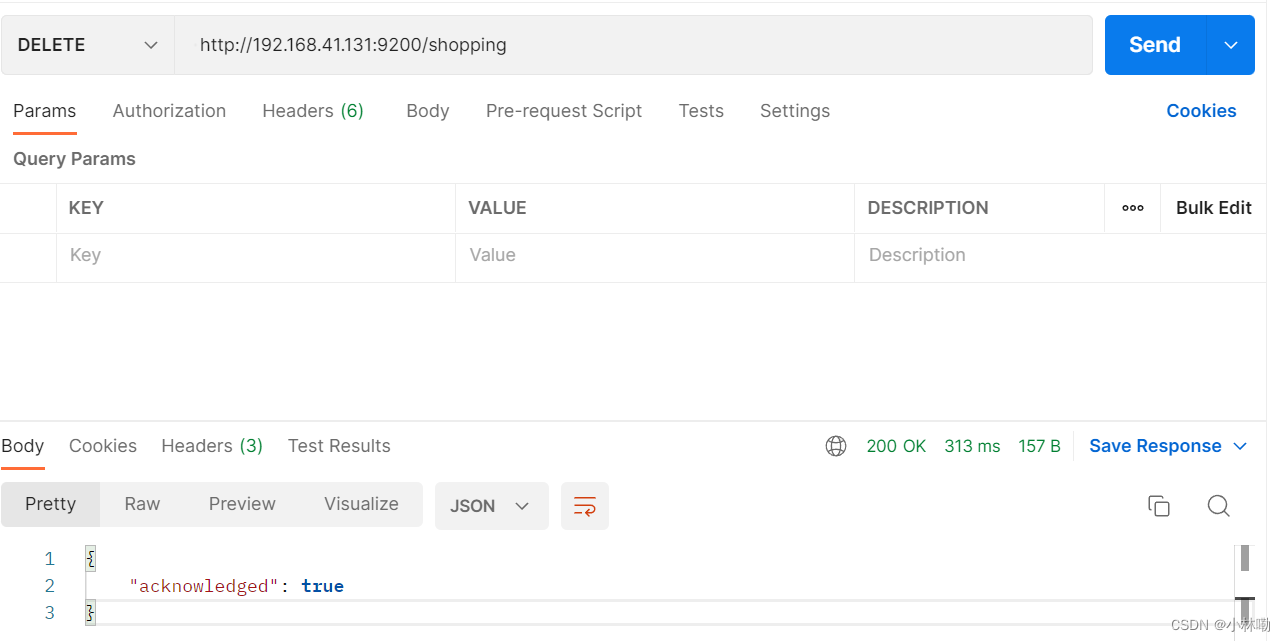
3.删除索引 就是将发送的方式改为delete即可.
http://192.168.41.131:9200/shopping
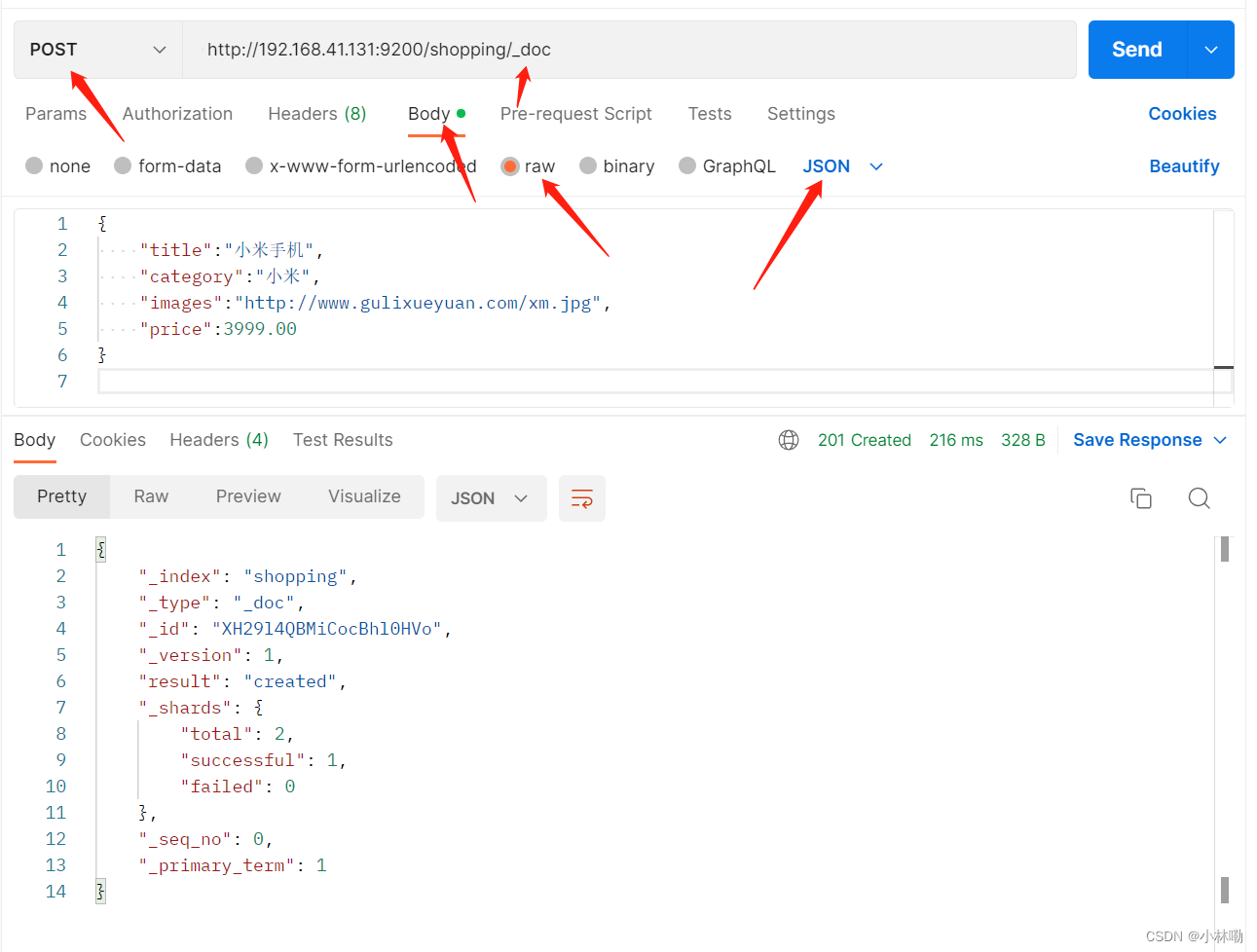
05文档创建
文档可以类比为关系型 数据库中的表数据,添加数据的格式为json.使用postman发送数据,注意post设置如下
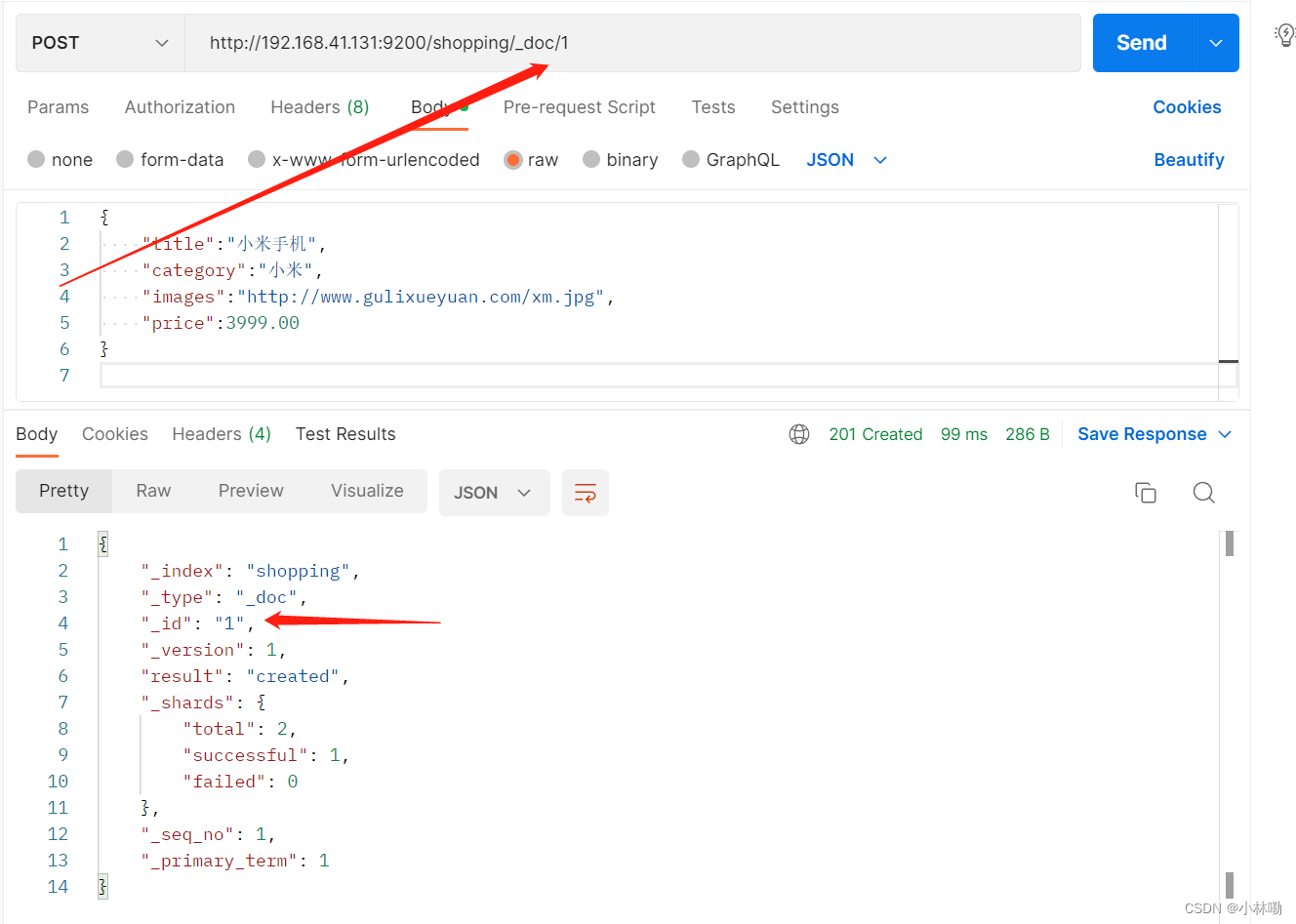
注意这里的数据创建时没有指定唯一数据标识,默认情况下,es服务器会自动生成一个随机标识(id),手动指定需要在创建时指定 :格式如下
{
"_index": "shopping", //索引
"_type": "_doc",//类型-文档
"_id": "1",//id
"_version": 1,//版本
"result": "created",//结果(created表示创建成功)
"_shards": {
"total": 2,//分片-总数
"successful": 1,//分片总数
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}06 主键查询,全查询
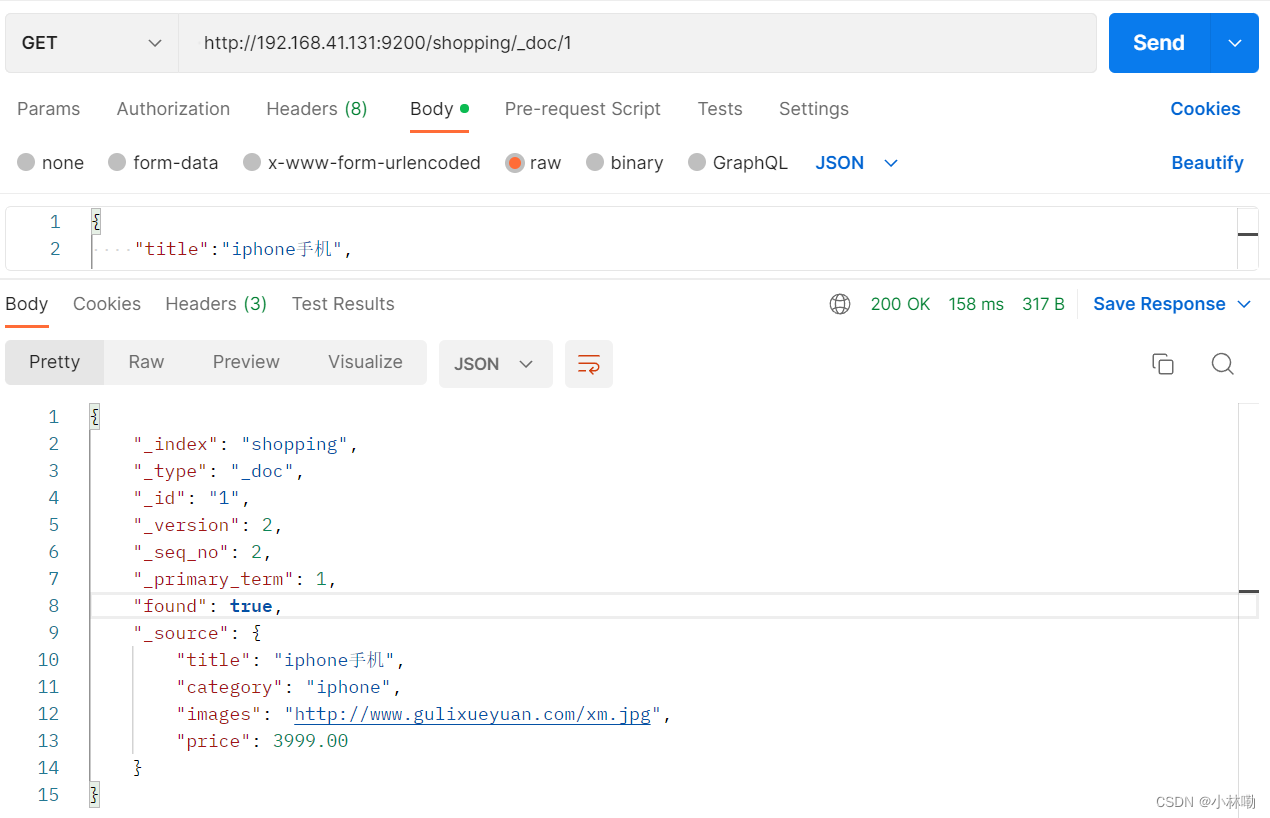
查询文档,需要指明文档的唯一性标识, 使用GET方法,类似如下
http://192.168.41.131:9200/shopping/_doc/1
如果查不到,会返回false
查询索引下所有的数据,在索引后加上_search
返回数据的格式如下
{
"took": 67,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "XH29l4QBMiCocBhl0HVo",
"_score": 1.0,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999.00
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999.00
}
}
]
}
}07修改
全量修改:
如果请求的url相同,那么输入不同的内容(请求体发生变化)会导致原有的数据被覆盖
局部修改:
将index后面添加_update,然后跟上doc的id,同样以post的形式发送,那么可以得到局部修改后的数据.注意在json中,添加了"doc"用来说明要修改的是个文档

08删除
删除时逻辑删除,不是物理删除,在删除后,他不会从磁盘立即移除.

09条件查询
1.可以使用url拼接的方式,但是不安全

2.使用json请求体查询(使用get方式)

3.查询全部文档内容

4.查询指定字段,注意json格式,添加了一个"_source"字段,且,位于query外侧 
5.分页查询
from指定查询的起始位置,size表示从起始位置开始的文档数量.如果搜索size大于10000,需要设置index.max_result_window参数 ,默认为10000。
6.指定数据的排序,按照price降序排序

7.多条件查询 也就是说多加几个math选项,同时注意添加了"must"字段(相当于数据库的&&字段),同时注意must后面加的是[],不是{}

如果想要表示"或" 那么使用should字段,注意filter和bool的包含关系,要把filter放到bool的括号里!!!!! gt表示大于

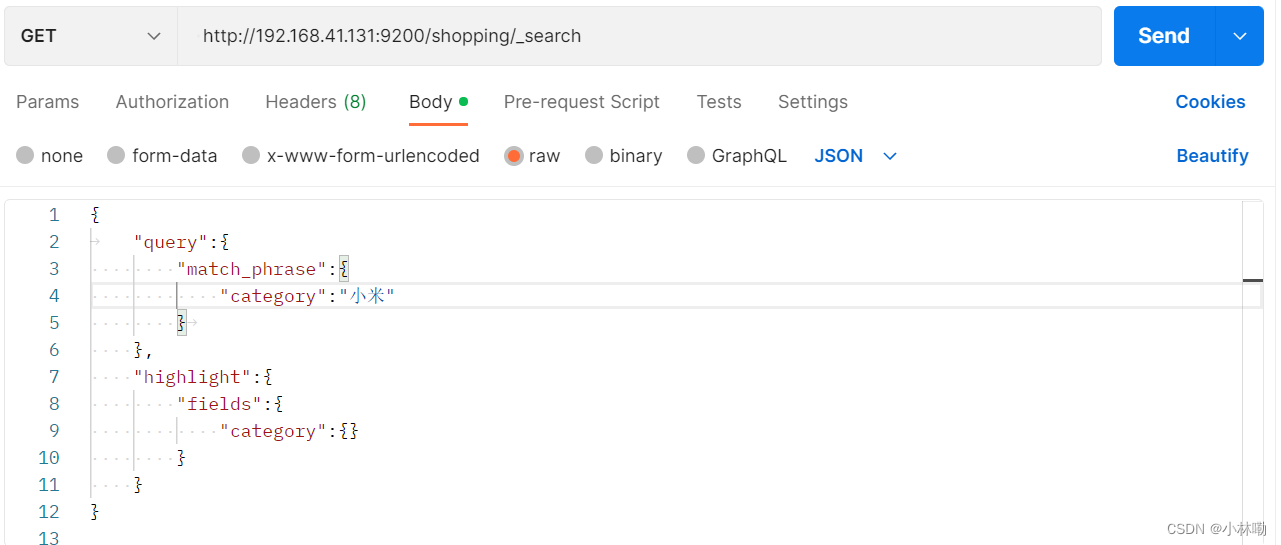
10全文检索,完全匹配,高亮查询
1.全文检索:类似搜索引擎,比如输入"小华"那么会返回品牌带有小和华任意一个字的所有标识,在本例中,显然是,小米和华为两个品牌.

2.完全匹配 将match换成 match_phrase 此时会非常严格的执行匹配,一旦不匹配会返回空.当然也可以有个调节因子,slop 表示少匹配slop个元素也可以

3.高亮查询,就是增加个highlight模块
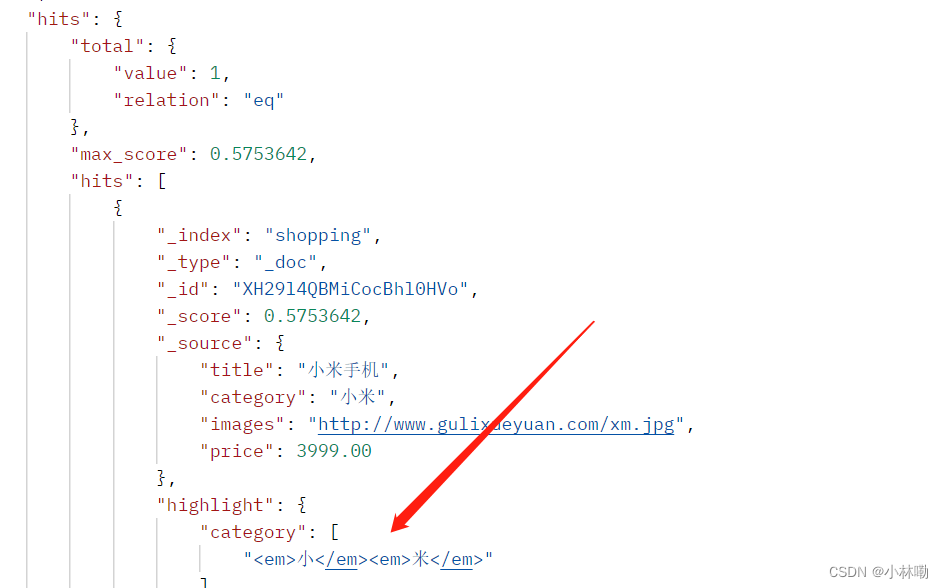
11.聚合查询
关键字:aggs,terms,聚合查询允许使用者对文档进行统计分析,类似于group by函数,当然还有其他许多聚合,比如最大值max,平均值avg.
带原始数据的聚合请求: 
如果不想带原始数据,那么,可以在args外指定一个size参数, size = 0

返回结果不包括其他条目,只有prices这一项

求平均值: 将上一步中的terms换成使用avg即可.

12映射关系
在建立 了索引之后就等于有了数据库中的database,然后我们需要创建写字段,也就是所谓的索引库映射工作,类似于关系型数据库的表结构.(建表过程).
映射:创建数据库的表字段需要的名称,类型,长度,约束等
1.新建一个索引库 user ,注意body不要带东西!

2.创建映射:插入三个属性 
3.添加数据

4.查询包含小的数据,注意url后面接的是_search

es数据类型(基本类型):
1.字符串类型:
1.text 会被分词的数据,
2.keyword 不会分词的字符串,可以设置是否需要存储 "index":"true|false"
2.数字类型:

3.Json没有日期类型,所以日期可以是
包含格式化日期的字符串,"2018-10-01"或者"2018/10/01 12:11:44"
代表时间毫秒数的长整型数字
代表时间秒数的整数
4.范围类型-range

es数据类型(复杂数据类型):
1.数组类型:array
es中没有专门的数组类型,所以使用[]定义即可.注意数组中的数据类型必须为同一类 型,不可以跨类型构建数组.
动态添加数组的时候第一个加入数组的数据类型决定了整个数组的数据类型
数组可以包含null值,空数组会被当做missing field 没有值的字段
给出一些示例:
① 字符串数组: ["one", "two"];
② 整数数组: [1, 2];
③ 由数组组成的数组: [1, [2, 3]], 等价于[1, 2, 3];
④ 对象数组: [{"name": "Tom", "age": 20}, {"name": "Jerry", "age": 18}].2.对象类型:object
json文档是分层的,文档可以包含内部对象,内部对象也可以进一步包含内部对象
添加示例,存储方式以及文档的映射结构如下
PUT employee/developer/1
{
"name": "ma_shoufeng",
"address": {
"region": "China",
"location": {"province": "GuangDong", "city": "GuangZhou"}
}
}
{
"name": "ma_shoufeng",
"address.region": "China",
"address.location.province": "GuangDong",
"address.location.city": "GuangZhou"
}
文档的映射结构:
PUT employee
{
"mappings": {
"developer": {
"properties": {
"name": { "type": "text", "index": "true" },
"address": {
"properties": {
"region": { "type": "keyword", "index": "true" },
"location": {
"properties": {
"province": { "type": "keyword", "index": "true" },
"city": { "type": "keyword", "index": "true" }
}
}
}
}
}
}
}
}
3.嵌套类型:nested
嵌套类型是对象数据类型的一个特例,可以让array类型的对象被独立索引和搜索. 嵌套对象实质是将每个对象分离出来, 作为隐藏文档进行索引.
创建映射:
PUT game_of_thrones
{
"mappings": {
"role": {
"properties": {
"performer": {"type": "nested" }
}
}
}
}
添加数据:
PUT game_of_thrones/role/1
{
"group" : "stark",
"performer" : [
{"first": "John", "last": "Snow"},
{"first": "Sansa", "last": "Stark"}
]
}
检索数据
GET game_of_thrones/_search
{
"query": {
"nested": {
"path": "performer",
"query": {
"bool": {
"must": [
{ "match": { "performer.first": "John" }},
{ "match": { "performer.last": "Snow" }}
]
}
},
"inner_hits": {
"highlight": {
"fields": {"performer.first": {}}
}
}
}
}
}