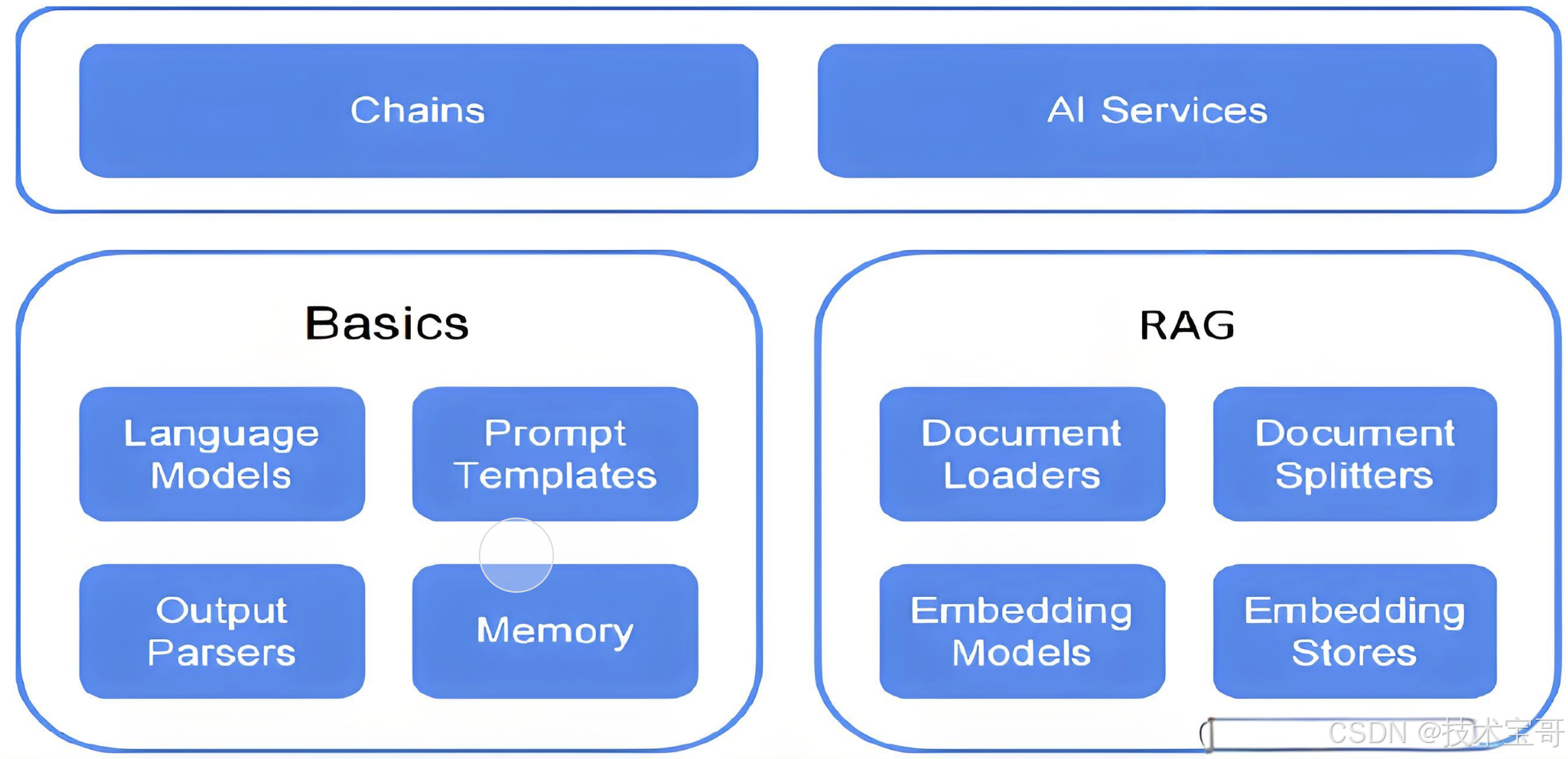
检索系统 (Retrieval)
检索系统是LangChain的核心组件之一,它提供了从各种数据源获取相关信息的能力,是构建知识增强型应用的基础。本文档详细介绍LangChain检索系统的组件、工作原理和最佳实践。
概述
检索系统解决了大型语言模型知识有限和过时的问题,允许模型访问外部信息源。LangChain的检索框架包括以下主要组成部分:
- 文档加载:从各种来源加载文本数据
- 文档处理:分割、清理和预处理文档
- 嵌入和索引:将文本转换为向量并建立索引
- 检索:搜索并获取相关文档
- 上下文增强:将检索到的信息整合到模型输入中
文档加载器
LangChain提供了100多种文档加载器,用于从不同数据源获取文档。
常见文档加载器
from langchain_community.document_loaders import (
TextLoader, PyPDFLoader, CSVLoader,
WebBaseLoader, YouTubeLoader,
DirectoryLoader, GitLoader
)
# 加载文本文件
text_loader = TextLoader("path/to/document.txt")
text_docs = text_loader.load()
# 加载PDF文件
pdf_loader = PyPDFLoader("path/to/document.pdf")
pdf_docs = pdf_loader.load()
# 加载CSV文件
csv_loader = CSVLoader("path/to/data.csv")
csv_docs = csv_loader.load()
# 加载网页内容
web_loader = WebBaseLoader(["https://www.example.com/page"])
web_docs = web_loader.load()
# 加载YouTube视频
youtube_loader = YouTubeLoader.from_youtube_url(
"https://www.youtube.com/watch?v=example",
add_video_info=True,
language=["zh-cn"]
)
youtube_docs = youtube_loader.load()
# 加载整个目录
dir_loader = DirectoryLoader("./documents/", glob="**/*.pdf")
dir_docs = dir_loader.load()
# 加载Git仓库
git_loader = GitLoader(
clone_url="https://github.com/username/repo",
repo_path="./repos/example_repo",
branch="main"
)
git_docs = git_loader.load()
文档结构
加载的文档通常包含以下属性:
from langchain_core.documents import Document
doc = Document(
page_content="文档内容",
metadata={"source": "example.txt", "page": 1, "author": "张三"}
)
文档处理
文本分割
将长文档分割成小块,以适应模型的上下文窗口:
from langchain_text_splitters import (
RecursiveCharacterTextSplitter,
CharacterTextSplitter,
TokenTextSplitter,
SentenceTransformersTokenTextSplitter
)
# 基于字符的递归分割(推荐)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最大字符数
chunk_overlap=200, # 块之间的重叠字符数
separators=["\n\n", "\n", "。", ",", " ", ""] # 尝试优先在这些分隔符处拆分
)
# 基于令牌的分割(更精确控制token数量)
token_splitter = TokenTextSplitter(
chunk_size=500, # 每块最大token数
chunk_overlap=50 # 块之间的重叠token数
)
# 中文分割优化(基于句子变换器的分词)
chinese_splitter = SentenceTransformersTokenTextSplitter(
chunk_size=256,
chunk_overlap=20
)
# 分割文档
doc = text_loader.load()[0] # 假设已经加载了文档
chunks = text_splitter.split_documents([doc])
print(f"文档被分割成{len(chunks)}个块")
嵌入与向量存储
嵌入模型
将文本转换为向量表示:
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import HuggingFaceEmbeddings, ModelScopeEmbeddings
# OpenAI嵌入(高质量但需付费)
openai_embeddings = OpenAIEmbeddings()
# 开源嵌入选项(本地或免费)
huggingface_embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" # 多语言模型
)
# 使用中文模型(ModelScope)
chinese_embeddings = ModelScopeEmbeddings(
model_id="iic/nlp_lawbert_text-embedding-chinese_base"
)
# 生成文本嵌入
text = "这是一段示例文本"
embedding = openai_embeddings.embed_query(text)
向量存储
存储和检索文档嵌入:
from langchain_community.vectorstores import FAISS, Chroma, Milvus
# 准备文档
docs = text_splitter.split_documents(text_loader.load())
# 使用FAISS(高效的开源向量库,适合本地使用)
faiss_db = FAISS.from_documents(docs, openai_embeddings)
# 使用Chroma(开源向量数据库,支持元数据过滤)
chroma_db = Chroma.from_documents(
docs,
openai_embeddings,
persist_directory="./chroma_db" # 持久化存储路径
)
# 保存Chroma数据库
chroma_db.persist()
# 使用Milvus(分布式向量数据库,适合大规模部署)
milvus_db = Milvus.from_documents(
docs,
openai_embeddings,
connection_args={"host": "localhost", "port": "19530"}
)
检索器
基本检索
从向量存储中检索文档:
# 将向量存储转换为检索器
retriever = chroma_db.as_retriever()
# 自定义检索参数
custom_retriever = chroma_db.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k": 5} # 返回前5个最相关文档
)
# 执行检索
query = "人工智能的应用场景有哪些?"
relevant_docs = retriever.get_relevant_documents(query)
# 显示检索结果
for i, doc in enumerate(relevant_docs):
print(f"结果 {i+1}: {doc.page_content[:100]}...")
print(f"来源: {doc.metadata.get('source', '未知')}\n")
检索增强生成 (RAG)
基础RAG实现
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
# 创建检索链
def format_docs(docs):
return "\n\n".join([doc.page_content for doc in docs])
# 创建RAG提示模板
template = """请根据以下上下文回答问题。如果上下文中没有提供足够的信息,就说你不知道。
上下文:
{context}
问题:{question}
回答:"""
prompt = ChatPromptTemplate.from_template(template)
# 创建RAG链
rag_chain = {
"context": retriever | format_docs,
"question": RunnablePassthrough()
} | prompt | ChatOpenAI(temperature=0) | StrOutputParser()
# 执行RAG查询
result = rag_chain.invoke("深度学习和机器学习有什么区别?")
print(result)
高级RAG模式
对话RAG
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
# 创建带对话历史的RAG提示
conversational_rag_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个基于上下文的问答助手。使用提供的上下文回答用户问题。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
("system", "上下文信息:\n{context}")
])
# 创建对话历史
chat_history = ChatMessageHistory()
# 对话RAG链
conversational_rag_chain = {
"context": retriever | format_docs,
"question": RunnablePassthrough(),
"chat_history": lambda _: chat_history.messages
} | conversational_rag_prompt | ChatOpenAI() | StrOutputParser()
最佳实践
-
文档分割策略:根据文档类型选择适当的分割方法
- 通用文本:使用
RecursiveCharacterTextSplitter - 代码:使用专用代码分割器
- 结构化文档:使用专用分割器如
MarkdownHeaderTextSplitter
- 通用文本:使用
-
选择合适的块大小
- 太大:检索精度低,但可能包含更完整信息
- 太小:检索精度高,但可能缺乏上下文
- 推荐:普通文本500-1000 tokens,技术文档300-500 tokens
-
中文检索优化
- 使用专为中文优化的嵌入模型
- 使用中文分词进行文本分割
- 考虑检索更多文档以提高召回率
-
检索系统部署考虑
- 小规模/本地测试:FAISS、Chroma
- 中等规模/生产:Weaviate、Pinecone
- 大规模/企业级:Milvus、Elasticsearch with vector search
总结
检索系统是LangChain中连接大语言模型与外部知识的关键组件。通过文档加载、文本处理、向量嵌入和检索,可以构建强大的知识增强型应用。RAG架构将检索系统与生成模型结合,创建了一种既有知识深度又能保持对话灵活性的AI应用框架。
后续学习
- 模型输入输出 - 了解如何与语言模型交互
- 链 - 学习如何将检索系统集成到复杂流程中
- 智能体|后续更新 - 探索将检索系统与自主智能体结合