- 早期的计算机(上世纪70年代前) 是相互独立的,各自处理各自的数据
- 上世纪70年代后,出现了基于TCP/IP协议的小规模的计算机互联互通。
- 上世纪90年代后,全球互联的互联网出现。
- 当全球互联网逐步建成(2000年左右),各大企业、政府有海量的数据亟待处理。 于是诞生了以分布式的形式(即多台服务器集群)完成海量数据处理的处理方式,并逐步发展成现代大数据体系。
Apache Hadoop对大数据体系的意义
- 第一款获得业界认可的开源分布式解决方案
- 让各类企业都可用的企业级开源分布式解决方案
- 催生出了众多的大数据体系技术栈,从Hadoop开始(2008年),大数据开始迅速发展
大数据就是:用分布式技术来处理 海量数据,得到数据背后蕴含的价值。
狭义上:大数据是一类技术栈,是一种用来处理海量数据的软件技术体系。
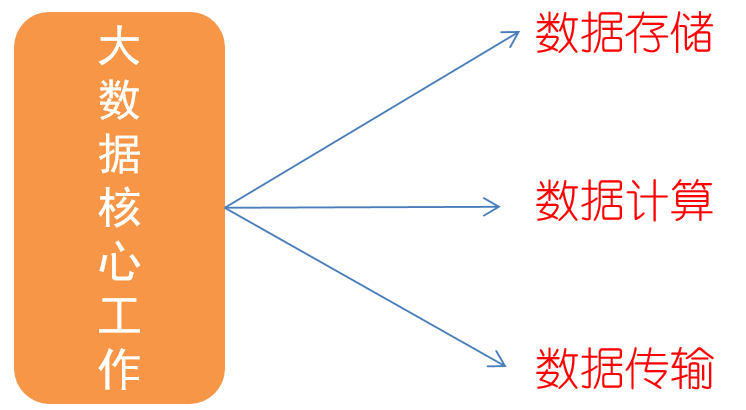
大数据的核心工作
大数据软件生态
数据存储
| Apache Hadoop - HDFS
| Hadoop框架的HDFS组件是使用 最广泛的分布式存储技术 |
| Apache HBase
| 使用非常广泛的NoSQL KV型数据库技术。HBase是基于HDFS构建的。 |
| Apache KUDU
| 使用较多的分布式存储引擎 |
| 云平台存储组件 | 各大云平台厂商也有相应的大数据存储组件,如 阿里云的OSS、UCloud的US3、AWS的S3、金山云的KS3等等 |


数据计算
| Apache Hadoop - MapReduce
| Hadoop的MapReduce组件是最早的分布式计算引擎 |
| Apache Hive
| 以SQL为开发语言的分布式计算框架。底层使用Hadoop 的MapReduce技术。 Apache Hive仍活跃在大数据一线,许多公司使用。 |
| Apache Spark
| 分布式内存计算引擎。 |
| Apache Flink
| 分布式内存计算引擎。 在实时计算(流计算)领域,Flink占据大多数的国内市场。 |




数据传输
| Apache Kafka
| 一款分布式的消息系统,可以完成海量规模的数据传输。 大数据领域的明星产品 |
| Apache Pulsar
| 一款分布式的消息系统。 有非常多的使用者。 |
| Apache Flume
| 一款流式数据采集工具,可以从非常多的数据源中完成数据采集传输的任务。 |
| Apache Sqoop
| 一款ETL工具,可以协助大数据体系和关系型数据库 之间进行数据传输。 |



![STM32单片机入门学习——第29节: [9-5] 串口收发HEX数据包串口收发文本数据包](https://i-blog.csdnimg.cn/direct/8b16e97b30104e2dafa192ba70115bdc.png)