深入浅出讲解 Teacher Forcing 技术
在序列生成任务(例如机器翻译、文本摘要、图像字幕生成等)中,循环神经网络(RNN)以及基于 Transformer 的模型通常采用自回归(autoregressive)的方式生成输出序列。然而,在训练过程中直接采用模型自身预测的输出作为下一步的输入容易导致梯度传递问题和误差累积,从而影响模型的学习速度和稳定性。为了解决这一问题,Teacher Forcing 技术应运而生,成为训练 RNN 及其变种模型的重要手段。
1. 什么是 Teacher Forcing?
Teacher Forcing 是一种训练策略,其基本思想是在训练阶段,不使用模型上一时刻的预测结果作为当前时刻的输入,而是直接将真实的目标(ground truth)数据提供给模型。换句话说,在训练解码器(decoder)时,模型的每一步输入都由教师(即训练数据中的正确答案)提供,而不是依赖于模型自身已经生成的输出。
例如,在典型的 Seq2Seq 模型中,如果输入句子为
“Mary had a little lamb whose fleece was white as snow”
在训练时,我们通常在句首和句尾添加起始和结束标记,构成:
[START] Mary had a little lamb whose fleece was white as snow [END]
模型在时间步 t t t 的输入不再使用模型预测的 y ^ t − 1 \hat{y}_{t-1} y^t−1,而是直接使用真实的 y t − 1 y_{t-1} yt−1 来预测 y t y_t yt 。这一方式能更快地为模型提供有效的梯度信号,从而加速训练过程。
2. 为什么需要 Teacher Forcing?
2.1 自回归训练中的问题
在自回归模型中(即模型依赖于自身先前的预测进行下一步生成),如果在早期训练阶段模型输出错误,错误会通过后续步骤不断累积。例如,如果模型在生成第一步后预测错误,接下来每一步的输入都将带有错误信息,这不仅会导致训练收敛缓慢,还会使得梯度传播受到严重干扰。简单来说,由于错误传播的问题,模型在训练时很难准确捕捉到长时依赖关系。
2.2 Teacher Forcing 的作用
通过 Teacher Forcing,我们在训练过程中始终使用正确的历史信息作为输入,这样做有如下优点:
- 加速训练收敛: 由于每一时刻均使用 ground truth 信息,模型不必承受早期预测错误的累积,从而能更快学习到正确的序列依赖关系。
- 提高训练稳定性: 避免了因模型错误带来梯度消失或梯度爆炸的问题,使得训练过程更加平滑。
3. Teacher Forcing 的工作原理
以一个简单的语言模型为例,假设我们要生成下一个单词。训练过程中,模型的解码器获得以下输入和输出对:
- 初始输入: 输入
[START],期望输出Mary。 - 接下来: 尽管模型可能在第一步预测了错误的单词(例如预测为
a),但教师强制机制会忽略预测结果,而直接将正确单词Mary作为下一步的输入,期望输出had。
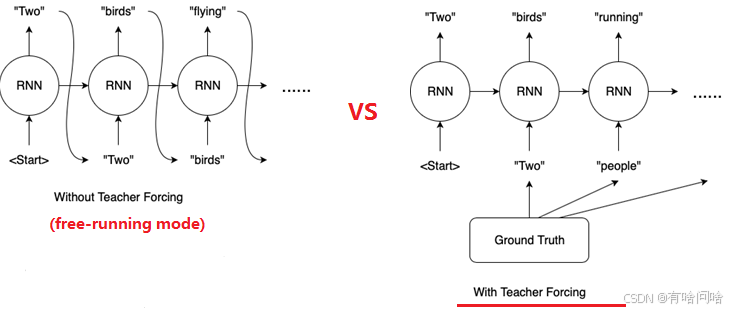
这种方式使得每一步的学习任务都基于真实序列,而非模型累积错误的生成历史。下图展示了两种训练方式的对比:
- Free-running 模式(无 Teacher Forcing): 模型每一步的输入为上一时刻预测值,若初始预测错误则可能导致后续输出全盘失误。
- Teacher Forcing 模式: 每一步都以 ground truth 作为输入,保证模型学习到正确的统计分布。
这种方法不仅能够有效降低由错误预测引发的连锁反应,还能使模型更快捕捉正确的条件概率分布。
4. Teacher Forcing 的优缺点
4.1 优点
- 训练效率高: 由于每一步都使用正确输入,模型能更快对比预测值与实际值,使得误差能及时反馈,从而加速收敛。
- 更稳定的梯度传递: 避免了因连续错误输入带来的梯度不稳定问题,使得模型在复杂长序列任务上表现更好。
4.2 缺点
- 暴露偏差(Exposure Bias): 训练过程中始终依赖 ground truth 信息,而在实际推理阶段,模型需要使用自己的预测值作为输入,导致训练与推理时输入分布不一致,这种不匹配可能导致生成质量下降。
- 推理表现不稳定: 由于训练过程中没有模拟真实生成时的累积误差,模型在测试阶段容易出现错误传递和解码偏差。
5. 对抗 Teacher Forcing 缺点的改进方法
为了解决 Teacher Forcing 带来的暴露偏差问题,研究界提出了多种改进方法:
5.1 Scheduled Sampling(预定抽样)
Scheduled Sampling 在训练过程中以一定概率选择使用模型自身的预测结果而非 ground truth 作为下一步输入,从而逐步过渡到与推理时一致的生成方式。这种方法能够在一定程度上缓解训练与推理阶段之间的差异,使模型具备“自纠正”能力。
5.2 Curriculum Learning(有计划的学习)
在 Curriculum Learning 中,模型初期主要依赖 ground truth 信息,但随着训练的进行,逐步增加使用模型预测结果的比例,让模型逐渐学会在“无教师”的环境下进行预测。
5.3 Beam Search
在推理阶段使用集束搜索(Beam Search)可以探索多个候选序列,并且在一定程度上降低因单一步错误导致的整体生成质量下降。
5.4 Professor Forcing 与 TeaForN
Professor Forcing 以及最近提出的 TeaForN 方法通过对抗训练和 N-gram 预测扩展,进一步缩小了训练与推理阶段网络动态之间的差距,从而提升了生成质量。
6. 应用场景
Teacher Forcing 在以下多个任务中得到了广泛应用:
- 机器翻译(Neural Machine Translation): 在编码器-解码器结构中,Teacher Forcing 能够加速语言生成过程,提高翻译效果。
- 文本摘要与语言生成: 保证生成文本在训练期间符合真实数据分布,从而提高摘要的连贯性与准确性。
- 图像字幕生成与语音合成: 在这些多模态任务中,Teacher Forcing 有助于模型更快收敛,改善生成质量。
7. 总结
Teacher Forcing 是一种经典且行之有效的序列生成模型训练方法,通过在训练时使用 ground truth 作为输入,极大地缓解了自回归预测中错误累积的问题。然而,它也带来了训练与推理阶段的不匹配,即所谓的暴露偏差。为了解决这一问题,当前研究者提出了 Scheduled Sampling、Curriculum Learning、Beam Search 以及更高级的对抗训练方法(例如 Professor Forcing 和 TeaForN)等改进策略。
总的来说,理解并合理运用 Teacher Forcing 及其改进方法对于提升序列生成模型的性能和稳定性具有重要意义。

![[Python] 企业内部应用接入钉钉登录,端内免登录+浏览器授权登录](https://i-blog.csdnimg.cn/direct/640ce48397194d80bae2f77f830f5b55.png)