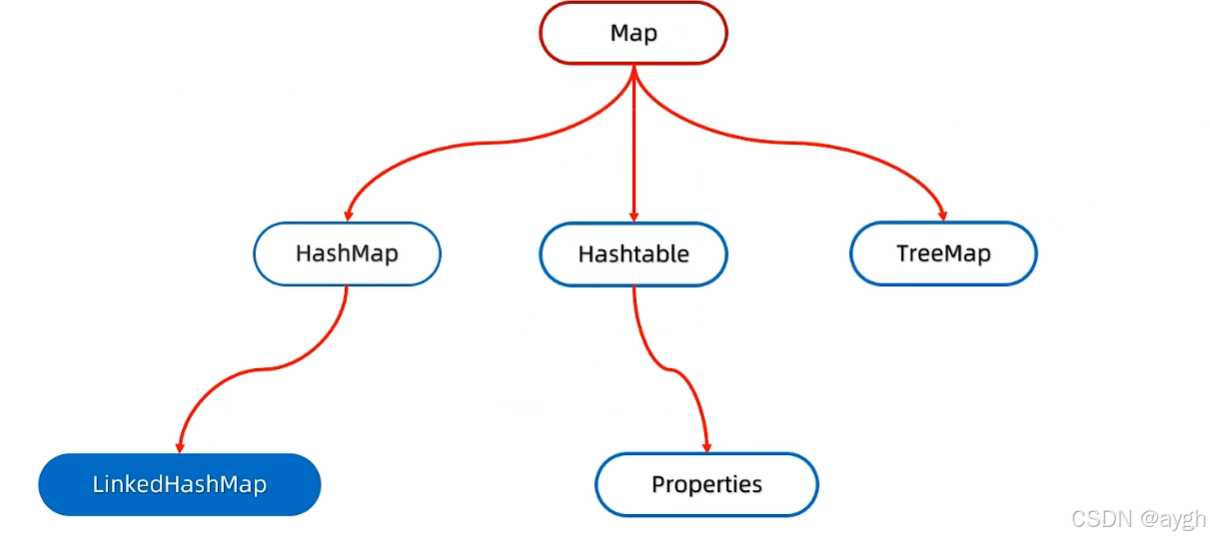
一、Map
Map常用的API
//map常用的api
//1.添加 put: 如果map里边没有key,则会添加;如果有key,则会覆盖,并且返回被覆盖的值
Map<String,String> m=new HashMap<>();
m.put("品牌","dj");
m.put("价格","9999");
String s = m.put("价格", "111");
System.out.println(s); //输出:9999
System.out.println(m); //{品牌=dj, 价格=111}
//2.删除 remove 删除成功返回value
String s1 = m.remove("品牌");
System.out.println(s1); //dj
System.out.println(m); //{价格=111}
//3.清除 clear()
// m.clear();
System.out.println(m); //{}
//4.判断集合是否有该键值 返回 布尔类型的
System.out.println(m.containsKey("价格"));
//5.判断是否含有指定值 返回布尔类型
System.out.println(m.containsValue("111"));
//6.判断集合是否为空 返回布尔类型
System.out.println(m.isEmpty()); //false
//7.集合的长度
System.out.println(m.size()); //1Map的遍历方式
一共有三种
//遍历方式一共三种
Map<String,String> m =new HashMap<>();
m.put("aaa","bbb");
m.put("ccc","ddd");
m.put("eee","fff");
//1.键找值
//生成键的set
Set<String> s1 = m.keySet();
for (String s : s1) {
System.out.println(s+"="+m.get(s));
}
//2.键值对
//entry 生成键值对 对象的set
Set<Map.Entry<String, String>> s2 = m.entrySet();
for (Map.Entry<String, String> s : s2) {
System.out.println(s.getKey()+"="+s.getValue());
}
//3.lambda表达式遍历
m.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key+"="+value);
}
});
//简化
m.forEach((key, value) ->
System.out.println(key+"="+value)
);HashMap
HashMap的键值特点:无序,不重复,无索引
如果键存储的是自定义对象,要重写hashCode方法和equals方法(学生类中)
下边代码是一个存储自定义对象Student和String的一个遍历示例:
public static void main(String[] args) {
/*
* 自定义对象,hashcode和equals得重写
* */
HashMap<Student,String> hm=new HashMap<>();
Student s1=new Student("小a",12);
Student s2=new Student("小b",14);
Student s3=new Student("小c",15);
hm.put(s1,"日照");
hm.put(s2,"青岛");
hm.put(s3,"黄岛");
//键值对的遍历方式
Set<Map.Entry<Student, String>> set1 = hm.entrySet();
for (Map.Entry<Student, String> s : set1) {
Student key = s.getKey();
String value = s.getValue();
System.out.println(key.getName()+","+key.getAge()+","+value);
System.out.println(key+","+value);
}
//lambda遍历方式
hm.forEach((student, s)->
System.out.println(student+","+s)
);
}
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
//基于name和age生成 hashcode值
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
LinkedHashMap
键的特点,有序,不重复,无索引
底层的数据结构是哈希表,再加上双向链表的机制
TreeMap
键的特点,可排序(可自定义排序的规则),不重复,无索引
底层的数据结构是红黑树
基本数据类型默认是升序
//默认是升序
// TreeMap<Integer,String> tm=new TreeMap<>(new Comparator<Integer>() {
// @Override
// public int compare(Integer o1, Integer o2) {
// return o2-o1;
// }
// });
TreeMap<Integer,String> tm=new TreeMap<>((o1, o2)->
o2-o1
);
tm.put(2,"aa");
tm.put(3,"ee");
tm.put(1,"ad");
tm.put(5,"cc");
tm.put(4,"bb");
System.out.println(tm);
}自定义的数据类型,因为默认没有比较排序规则,直接添加在TreeMap会进行报错,所以要实现comparable接口(在学生类中),重写比较方法
TreeMap<Student,String> tm1=new TreeMap<>();
Student s1=new Student("小a",14);
Student s2=new Student("小b",11);
Student s3=new Student("小c",15);
tm1.put(s1,"日照");
tm1.put(s2,"青岛");
tm1.put(s3,"黄岛");
tm1.put(s2,"lll"); //覆盖
System.out.println(tm1);
// out:{Student{name = 小b, age = 11}=lll, Student{name = 小a, age = 14}=日照, Student{name = 小c, age = 15}=黄岛}
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
//基于name和age生成 hashcode值
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
//用于TreeMap排序的
@Override
public int compareTo(Student o) {
int i = this.getAge()-o.getAge();
i= i==0?this.getName().compareTo(o.getName()):i;
return i;
}
}
可变参数
可变参数就是形参的个数是可以变化的,不用再只有一个两个了这种固定值了
public static void main(String[] args) {
/*
参数的数量是可变的
格式是 int...arg 数据类型加三个点
底层就是数组
注意:
可变参数只能有一个
如果有固定参数,要写在可变参数的前面
* */
System.out.println(getSum(1,2,3));
System.out.println(getSum(1,2));
}
public static int getSum(int...arr)
{
int sum=0;
for (int i : arr) {
sum+=i;
}
return sum;
}二、创建不可变的集合
不想让别人修改集合里边的内容,就只能查询
创建不可变的集合的方法
1.List: List.of("xxx","xxxxx");
2.Set: Set.of("xxx","xxxxx"); 不可变集合里的参数必须是不重复的,否则会报错
3.Map:Map.copyof(Map的对象);
三、Stream流
Stream流有三大步1.获取Stream流,2.中间方法操作,3.终结方法操作
1.获取Stream流
1.单列集合示例
直接arr.stream()来获取
ArrayList<String> arr=new ArrayList<>();
arr.add("王大一");
arr.add("王大二");
arr.add("王大");
arr.add("大一");
arr.add("大二");
Stream<String> stream = arr.stream();
stream.forEach(name-> System.out.println(name));2.双列集合示例
双列集合无法直接使用stream流,需要生成keySet或者entrySet来实现
HashMap<String,Integer> hm=new HashMap<>();
hm.put("王大一",1);
hm.put("王大二",4);
hm.put("王一",2);
hm.put("一",3);
hm.put("大一",5);
//1.生成键值set
hm.keySet().stream().forEach(h-> System.out.println(h));
//2.生成键值对set
hm.entrySet().stream().forEach(h-> System.out.println(h));
3.数组
用Arrays.stream()方法
String[] s1={"xxx","vvv"};
Arrays.stream(s1).forEach(s-> System.out.println(s));4.零散数据
使用Stream.of()
Stream.of(1,2,3).forEach(i-> System.out.println(i));2.Stream流的中间方法
1.filter
stream流只能使用一次,所以推荐使用链式编程
只改变stream流的内容,不会改变原来集合的内容
//1.filter
ArrayList<String> array=new ArrayList<>();
Collections.addAll(array,"ygh","dxh","ygh1","ygh111","gh");
array.stream().filter(s -> s.length()==3).forEach(s-> System.out.println(s));2.limit
获取前几个元素
array.stream().limit(2).forEach(System.out::println); //输出为 ygh dxh3.skip
跳过前几个元素
array.stream().skip(4).forEach(System.out::println); //输出为 gh4.distinct
他的作用是去重,如果是自定义数据类型要重写hashcode和equals方法
ArrayList<String> array=new ArrayList<>();
Collections.addAll(array,"ygh","dxh","ygh1","ygh111","gh","ygh");
array.stream().distinct().forEach(System.out::println);5.concat
两个Stream流concat拼接在一起
ArrayList<String> array=new ArrayList<>();
ArrayList<String> array1=new ArrayList<>();
Collections.addAll(array,"ygh","dxh","ygh1","ygh111","gh","ygh");
Collections.addAll(array1,"ygh","dxh","ygh1","ygh111","gh","ygh");
Stream.concat(array.stream(),array1.stream()).forEach(System.out::println);6.map
map的作用是转换数据类型
这个示例是截取最后的数字,再转换为int数据类型
ArrayList<String> array=new ArrayList<>();
Collections.addAll(array,"ygh-1","dxh-1","ygh-2","ygh-3","gh-6","ygh-7");
array.stream().map(s->Integer.parseInt(s.split("-")[1]))
.forEach(System.out::println);3.Stream流的终结方法
1.forEach
遍历
2.count
统计,统计个数
ArrayList<String> array=new ArrayList<>();
Collections.addAll(array,"ygh-1","dxh-1","ygh-2","ygh-3","gh-6","ygh-7");
long count = array.stream().count();
System.out.println(count); //输出 63.toArray
将流中的数据收集进数组
toArray(s->new String[s])这里边的s表示长度,就是生成一个长度为s的String数组
ArrayList<String> array=new ArrayList<>();
Collections.addAll(array,"ygh-1","dxh-1","ygh-2","ygh-3","gh-6","ygh-7");
String[] array1 = array.stream().toArray(s -> new String[s]);
System.out.println(Arrays.toString(array1)); //输出 [ygh-1, dxh-1, ygh-2, ygh-3, gh-6, ygh-7]4.collect
将流中的数据收集集合
第一个是收集成list 也是array.stream().collect(Collectors.toList()); 示例中直接简化了
第二个是收集成set
第三个是收集成map(注意的是,如果流中所规定的键值有相同的,会报错)
ArrayList<String> array=new ArrayList<>();
Collections.addAll(array,"yg1-1","dx-1","yg-2","ygh-3","gh-6","y-7");
List<String> list = array.stream().toList();
Set<String> collect = array.stream().collect(Collectors.toSet());
Map<String, String> collect1 = array.stream().collect(Collectors.toMap(s -> s.split("-")[0], s -> s.split("-")[1]));
System.out.println(collect1);四、方法引用
方法引用就是将已经存在的方法拿过来用,当做函数式接口的方法体
方法引用要注意的事项
1.引用的地方需要是函数式接口
2.被引用的方法要存在
3.被引用的方法的形参和返回值要和抽象方法的形参和返回值一样
4.被引用方法的功能要满足当前的要求
1.引用静态方法
格式 类名::方法名
ArrayList<String> arr=new ArrayList<>();
Collections.addAll(arr,"1","2","3","4","5");
//原来的Lambda表达式
arr.stream().map(s->Integer.parseInt(s)).forEach(System.out::println);
//现在的方法引用
arr.stream().map(Integer::parseInt).forEach(System.out::println);
2.引用其他类的成员方法
格式 对象::成员方法
再细分为三类1.其他类: 其他类对象::方法名 2.本类: this::方法名 3.父类: super::方法名
3.引用构造方法
格式 类名::new
4.使用类名引用成员方法
格式 类名::成员方法(注意,抽象方法第一个参数表示引用方法的调用者。第一个参数的类型,决定了可以引用哪些类中的方法)
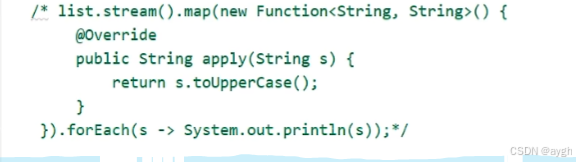
这个就只能引用String类中的方法
5.引用数组的构造方法
格式 数据类型【】::new 比如 int[ ]::new

![STM32单片机入门学习——第29节: [9-5] 串口收发HEX数据包串口收发文本数据包](https://i-blog.csdnimg.cn/direct/8b16e97b30104e2dafa192ba70115bdc.png)