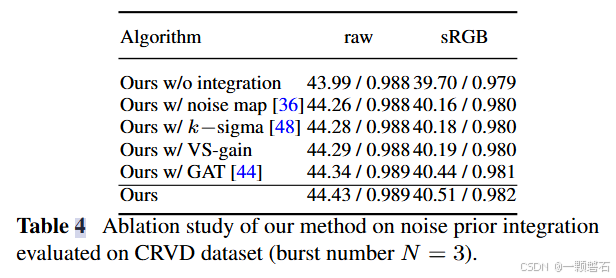
4月初,DeepSeek 提交到 arXiv 上的最新论文正在 AI 社区逐渐升温。

笔者尝试对比了“关于推理时Scaling”与现有技术,粗浅分析如下:
与LoRA的对比
- 区别:
- 应用场景:LoRA是一种参数高效微调方法,主要用于在训练阶段对模型进行微调,以适应特定的任务或数据集。而“推理时Scaling”主要关注推理阶段的性能提升,通过动态调整奖励机制来实现,不涉及模型参数的改变。
- 优化目标:LoRA旨在通过引入低秩矩阵来近似模型参数的变化,从而减少训练时的计算量和内存占用。而“推理时Scaling”则侧重于在推理过程中,通过增加计算资源来提升模型的推理能力,如逻辑一致性和事实准确性。
- 优势:
- 推理时Scaling:无需改变模型参数,避免了重新训练模型的高成本,同时能够在推理阶段灵活地提升模型性能。
- LoRA:在训练阶段能够有效减少计算资源的消耗,适用于资源有限的情况下的模型微调。
- 劣势:
- 推理时Scaling:可能需要在推理阶段投入更多的计算资源,导致推理延迟增加和计算成本上升。
- LoRA:仅在训练阶段有效,对于已经训练好的模型,在推理阶段无法进一步提升性能。
与知识蒸馏的对比
- 区别:
- 知识传递方式:知识蒸馏通过将大型教师模型的知识传递给小型学生模型,以提高学生模型的性能。而“推理时Scaling”不涉及模型间的知识传递,而是通过在推理过程中增加计算资源来提升同一模型的推理能力。
- 模型规模变化:知识蒸馏通常会减小模型的规模,以提高推理效率。而“推理时Scaling”不改变模型的规模,只是在推理阶段动态调整计算资源。
- 优势:
- 推理时Scaling:无需对模型进行重新训练或蒸馏,能够快速提升推理性能,适用于对模型规模有严格限制的场景。
- 知识蒸馏:通过减小模型规模,降低了存储和计算成本,同时保留了教师模型的大部分性能,适用于资源受限的设备部署。
- 劣势:
- 推理时Scaling:可能需要更多的计算资源,且性能提升的效果可能因任务和模型而异。
- 知识蒸馏:蒸馏过程需要额外的训练成本,且蒸馏效果可能受到教师模型质量和蒸馏方法的影响。
与模型剪枝的对比
- 区别:
- 模型结构改变:模型剪枝通过去除模型中的冗余参数或连接,减小模型规模,从而提高推理效率。而“推理时Scaling”不改变模型结构,只是在推理阶段动态调整计算资源。
- 性能提升方式:模型剪枝通过优化模型结构来提升推理效率,但可能会降低模型的表达能力。而“推理时Scaling”通过增加计算资源来提升推理性能,不会影响模型的结构和表达能力。
- 优势:
- 推理时Scaling:无需对模型进行结构修改,避免了剪枝可能导致的性能下降,同时能够灵活地根据推理需求调整计算资源。
- 模型剪枝:能够显著减小模型规模,降低存储和计算成本,适用于对模型大小有严格限制的场景,如移动设备和嵌入式系统。
- 劣势:
- 推理时Scaling:需要额外的计算资源,可能不适用于资源极度受限的环境。
- 模型剪枝:剪枝过程可能导致模型性能的下降,且需要重新训练模型以恢复性能,增加了训练成本。
与动态Batch Size的对比
- 区别:
- 资源调整方式:动态Batch Size通过在训练过程中根据计算资源和内存限制动态调整Batch Size,以提高训练效率。而“推理时Scaling”在推理阶段通过增加计算资源,如多次采样和并行采样,来提升推理性能。
- 应用场景:动态Batch Size主要用于训练阶段的资源优化,而“推理时Scaling”专注于推理阶段的性能提升。
- 优势:
- 推理时Scaling:能够在推理阶段灵活地利用计算资源,提升推理的准确性和效率,适用于对推理性能要求较高的场景。
- 动态Batch Size:在训练阶段能够有效利用计算资源,提高训练速度和效率,适用于大规模模型的分布式训练。
- 劣势:
- 推理时Scaling:可能增加推理延迟和计算成本,需要在性能提升和资源消耗之间进行权衡。
- 动态Batch Size:仅在训练阶段有效,对推理阶段的性能提升没有直接帮助。
与模型并行的对比
- 区别:
- 并行方式:模型并行通过将模型的不同部分分配到不同的计算设备上进行并行计算,以提高训练和推理速度。而“推理时Scaling”主要通过在推理过程中增加计算资源,如多次采样和并行采样,来提升推理性能。
- 目标:模型并行侧重于提高模型的训练和推理速度,特别是在处理大规模模型时。而“推理时Scaling”侧重于提升推理阶段的性能,如逻辑一致性和事实准确性。
- 优势:
- 推理时Scaling:无需对模型进行复杂的并行化处理,能够快速提升推理性能,适用于对模型并行化有困难的场景。
- 模型并行:能够有效利用多个计算设备的资源,提高大规模模型的训练和推理速度,适用于需要快速处理大量数据的场景。
- 劣势:
- 推理时Scaling:可能需要更多的计算资源,且性能提升的效果可能因任务和模型而异。
- 模型并行:实现复杂,需要对模型进行仔细的划分和优化,且可能会引入通信开销,影响整体性能。