25年4月来自南方科技大学、百度、英国 KCL和琶洲实验室(广东 AI 和数字经济实验室)的论文“MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving”。
自动驾驶视觉问答(AD-VQA)旨在根据给定的驾驶场景图像回答与感知、预测和规划相关的问题,这在很大程度上依赖于模型的空间理解能力。先前的工作通常通过坐标的文本表示来表达空间信息,导致视觉坐标表示和文本描述之间存在语义差距。这种疏忽妨碍了空间信息的准确传递并增加了表达负担。为了解决这个问题,提出了一种基于标记(marker)的提示学习框架(MPDrive),它通过简洁的视觉标记表示空间坐标,确保语言表达的一致性并提高AD-VQA中视觉感知和空间表达的准确性。具体而言,通过聘请检测专家将物体区域与数字标签叠加来创建标记(marker)图像,将复杂的文本坐标生成转换为简单的基于文本视觉标记(marker)预测。此外,将原始图像和标记(marker)图像融合为场景级特征,并将它们与检测先验相结合以得出实例级特征。通过结合这些特征,构建双粒度视觉提示,以刺激 LLM 的空间感知能力。
自动驾驶技术发展迅速,显示出提高道路安全性、交通效率和减少人为错误的潜力 [25、45、47、52]。强大的自动驾驶系统需要能够感知复杂环境并做出明智决策的智体。最近,多模态大语言模型 (MLLM) 已成为一种有前途的自动驾驶方法,在视觉问答 (AD-VQA) 任务中展示了强大的泛化能力 [4、7、18、29、37、40、48、49、61]。
当前的 MLLM 在自动驾驶场景的空间理解方面面临挑战 [24、41、62],限制了它们在驾驶场景中准确定位、识别和描述物体及其状态的能力。虽然一些 AD-VQA 方法 [19、24、30、34、39] 试图通过对特定领域数据集进行指令调整来提高 MLLM 性能,但它们还没有充分解决空间推理优化的核心挑战。在这些方法中,一些方法 [34、41] 通过整合检测先验来增强空间理解。然而,这些方法通常以文本格式表达空间坐标,导致基于坐标的描述和语言描述之间不一致 [5、33、53],这破坏了自动驾驶中的感知准确性和精确的空间表达。
本文专注于增强自动驾驶中坐标表示和空间理解的一致性,提出基于标记(marker)的提示学习 (MPDrive),这是一种多模态框架,它使用文本索引来注释每个交通元素并直接预测相应索引的坐标。
如图所示:主流MLLM方法和 MPDrive 的比较

给定一组 m 个视图图像 {I_1,I_2,…,I_m} 和一个文本问题 Q,AD-VQA 旨在生成一个响应序列 Sˆ = (sˆ_1, sˆ_2, . . . , sˆ_N ),其中 sˆ_i 表示长度为 N 的序列中的第 i 个 token。AD-VQA 中 MLLM 的工作流程如下:1)从每个视图 I_i 中提取视觉特征的一个视觉编码器;2)将多视图特征转换为图像 token 的一个连接 MLP;3)将问题 Q 转换为文本 token 的文本 token 化器;4)融合图像 token 和文本 token 以生成响应序列 Sˆ 的 LLM。
基于这些 MLLM,提出 MPDrive 来增强空间理解能力。为清楚起见,使用单视图场景说明该方法,同时所有操作自然扩展到多视图情况。
视觉 tokens
为了弥合空间坐标表示和语言描述之间的差距,引入了视觉 tokens。这种方法通过将空间坐标生成任务转换为直接的基于文本视觉 token 预测,简化空间坐标生成任务。如图所示,给定输入图像 I,使用检测专家 StreamPETR [43] 来识别交通目标(例如,汽车、卡车和公共汽车),遵循 [43] 中指定的目标类别。检测专家生成 K 个目标掩码,表示为二进制掩码 R = [r_1, r_2, . . . , r_K ],其中 r_k ∈ {0, 1} 表示第 k 个检测掩码。对于 r_k,计算其平均质心坐标 c_k = (x_k, y_k),它表示该目标的中心位置。带注释的标记(marker)图像 I_m 是通过修改原始图像 I 生成的,修改步骤分为两个步骤:首先,在每个物体的质心 c_k =(x_k, y_k) 处注释标记(marker)索引 k;其次,叠加相应的半透明掩码区域 r_k 来描述物体边界。此外,当问题 Q 中引用新的空间坐标 c_new(距离现有坐标超过 d 个像素)时,为其分配一个标记(marker)索引 K +1,并在 I_m 上注释该索引,以保持跨视觉和文本模态的空间推理一致性。
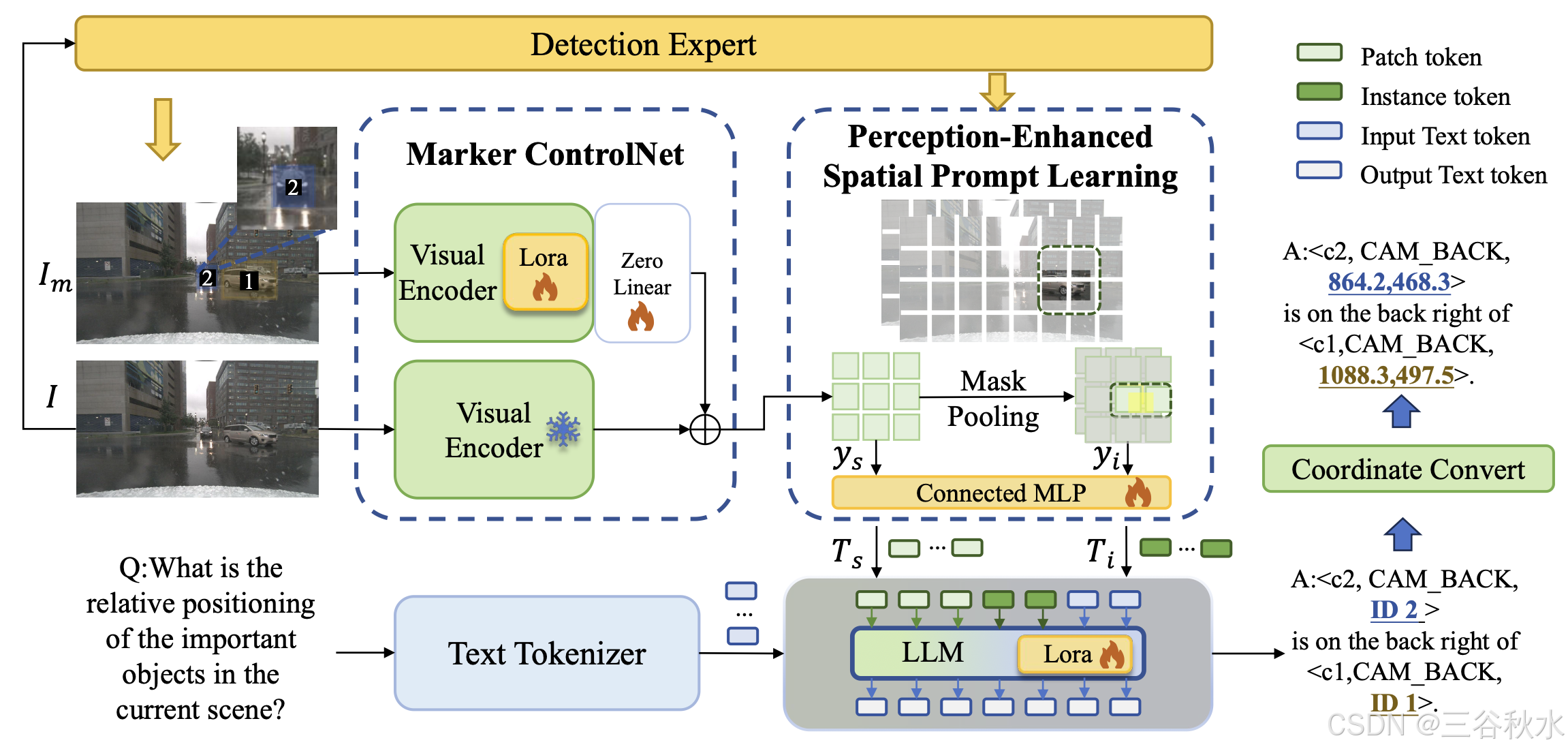
对于响应生成,利用视觉标记(Visual Marker)来提高视觉提示的有效性,并确保语言输出的一致性。具体而言,LLM 首先根据给定的图像和问题生成指示符 k,然后将该索引 k 映射到其对应的质心坐标 c_k = (x_k, y_k) 以进行精确定位。此过程允许 MPDrive 通过标记(marker)识别关键物体,而复杂的空间感知则由检测专家处理。通过避免直接坐标输出,这种方法减轻 LLM 的语言复杂性,确保文本输出的一致性。
MPDrive 架构
如上图所示,MPDrive 由两个关键组件组成:MCNet 和 PSPL。MCNet 利用原始图像和附加的视觉标记(marker)图像增强空间表征,以实现双层融合场景特征。基于这些提取的特征和检测专家,PSPL 生成场景级和实例级视觉提示,从而增强对驾驶场景信息和物体信息的理解。这些组件的集成显著提升了 MPDrive 的空间感知能力。
Marker ControlNet。为了有效保留原始图像的关键特征并充分利用视觉标记(visual marker)中的丰富信息,提出标记控制网络 (MCNet)。该模块将原始图像和视觉标记图像作为输入,并生成场景级特征。
冻结原始视觉编码器 E 的参数 θ,并创建一个具有参数 θ_c 的可训练编码器副本,记为 E_c。在训练过程中,原始视觉编码器保持冻结状态,专注于使用低秩自适应 (LoRA) [16] 在多头注意模块和秩为 16 的前馈网络上训练新的控制块。用零线性层 Z 连接原始视觉编码器和控制块,其中权重和偏差都初始化为零,参数为 θ_z 。这些层与控制块一起训练,可以有效地调整参数并提高性能。使用原始视觉编码器 E 提取原始图像特征,而使用新控制块 E_c 与 Z 结合提取视觉标记图像特征。这些特征通过元素相加组合在一起,实现场景级特征融合:
y_s = E(I; θ) + Z(E_c(I_m; θ_c); θ_z),
其中 y_s 表示场景级特征。
由于零线性层的权重和偏差参数初始化为零,上述公式中的 Z 项从零开始,从而保留原始图像特征的完整性。在后续优化阶段,将通过反向传播逐渐引入来自视觉标记图像的有益特征。
MCNet 有效地结合了视觉标记(marker),使 MPDrive 能够在保留原始图像关键特征的同时,通过视觉标记的引导学习额外的语义信息。更重要的是,这种方法确保 MPDrive 能够捕获视觉标记信息,然后输出相应的基于文本的标记(marker),从而在生成空间信息时保持语言输出的一致性。
感知增强的空间提示学习。为了解决 MLLM 在空间表达能力方面的局限性,引入感知增强的空间提示学习 (PSPL),旨在通过利用场景级和实例级视觉提示来增强 MPDrive 的空间感知。
图像中的视觉标记准确地表示整个场景的空间信息。因此,MCNet 的输出特征 y_s 包含丰富的场景级空间信息。随后,通过连接的 MLP 处理 y_s 以生成场景级视觉提示 T_s。这些场景级的视觉提示显著提高了复杂场景中对空间信息的感知和准确理解。
为了进一步增强实例级空间信息的表示,引入实例级视觉提示。给定第k个检测目标及其区域掩码 r_k,场景级视觉提示 y_s,C 是通道数,W′ 是宽度,H′ 是高度,将二元区域掩码 r_k 调整为与 y_s 相同的大小,并使用掩码平均池化。
给定K个目标,获得一组实例级视觉特征{y_i1,…,y_iK}。这些特征通过连接的 MLP 处理以生成实例级视觉提示T_i。这个实例级视觉提示丰富了目标的空间表示。 PSPL 将场景级视觉提示 T_s 和实例级视觉提示 T_i 连接在一起,增强 MPDrive 的空间感知能力。
大语言模型。LLM 从文本 token 化器接收输入文本 token,从 PSPL 模块接收空间提示 Ts 和 Ti。它使用其内部模型处理这些输入,其中 LoRA 应用于多头注意模块和秩为 16 的前馈网络,生成 N 个单词的输出序列 Sˆ = (sˆ_1,sˆ_2,…,sˆ_N)。然后使用输出 token 序列 Sˆ 与真值序列 S = (s_1, s_2, …, s_N) 计算交叉熵损失。
数据集。在 DriveLM [39] 和 CODA-LM [24] 数据集上进行实验。对于 DriveLM 数据集,遵循 EM-VLM4AD [14] 和 MiniDrive [58] 采用的数据分区策略,将数据集划分为训练和验证子集,分别分配 70% 和 30% 的数据。训练集包含 341,353 个唯一的 QA 对,而验证集包含 18,817 个不同的 QA 对。每个 QA 对由六个视图图像组成:正面视图、左正面视图、右正面视图、后视图、左后视图和右后视图。对于 CODA-LM 数据集,使用 20,495 个 QA 对训练集训练 MPDrive,并使用 193 个 QA 对 mini-set 对其进行验证。每个 QA 对,都由正面图像组成。
在训练阶段,采用初始速率为 5e − 4 的余弦学习调度,并使用权重衰减为 0.01 的 AdamW [28] 优化器。对于 DriveLM 数据集,使用的批量大小为 128,并在八个 A800 GPU 上进行 3,000 次迭代训练,相当于约 1 个 epoch。对于 CODA-LM 数据集,进行 2000 次迭代训练,相当于约 12 个 epoch。在整个训练过程中,视觉编码器权重保持不变。对连接的 MLP 和零 MLP 进行微调,同时将低秩自适应(LoRA)[16] 应用于 MCNet 中的视觉都将输入图像分辨率调整为 448×448 像素。检测专家针对每幅图像动态确定检测到的物体数量 K,所有摄像机视图中的最大物体数量限制为 100 个。我们设置新的空间坐标 dth = 50。