摘要
Adam优化器(Adaptive Moment Estimation)是一种广泛应用于深度学习的优化算法,通过自适应学习率加速梯度下降过程。本文从Adam的定义、算法原理、优势与局限性、应用场景及变体等方面进行调研,结合学术文献和实践经验,分析其在神经网络训练中的作用。研究表明,Adam在计算效率和鲁棒性上表现出色,尤其适合大规模数据集,但某些任务中SGD可能更具优势。
关键词:Adam优化器,自适应学习率,深度学习,梯度下降,神经网络
1 引言
深度学习模型的训练依赖于高效的优化算法,而传统的随机梯度下降(SGD)在面对复杂模型和大规模数据时往往收敛缓慢或对超参数敏感。Adam优化器(全称:Adaptive Moment Estimation)由Kingma和Ba于2014年提出,结合了动量法和RMSProp的优点,通过自适应调整学习率在深度学习领域获得广泛应用。本文旨在系统调研Adam优化器的原理、优势及应用,为研究者和开发者提供参考。
2 Adam优化器原理
2.1 算法定义
Adam是一种基于一阶梯度的优化算法,通过维护梯度的第一阶矩(均值)和第二阶矩(未中心化的方差)来动态调整学习率。其核心思想是利用历史梯度信息加速收敛,同时避免震荡。
2.2 数学公式
Adam的更新步骤如下:
- 计算梯度:
2.更新一阶矩估计:
3. 更新二阶矩估计:
4.偏差校正:
5.参数更新:
2.3 工作机制
Adam通过一阶矩捕捉梯度方向(类似动量法),通过二阶矩调整步长(类似RMSProp),实现自适应学习率。偏差校正确保早期训练稳定性,特别适合小批量数据。
3 Adam优化器的优势与局限性
3.1 优势
- 自适应性:动态调整学习率,适应不同参数的更新需求。
- 高效性:计算开销低,内存需求小,适合大规模训练。
- 鲁棒性:对噪声梯度和稀疏梯度表现稳定。
- 易用性:默认参数(如
)适用性广,减少调参负担。
3.2 局限性
- 泛化性能:部分研究(如Wilson等人,2017)指出,Adam在某些任务中的泛化能力不如SGD with Momentum。
- 计算复杂性:相较SGD,Adam需额外计算移动平均值,增加开销。
- 收敛问题:在某些非凸优化问题中,可能收敛到次优解。
4 应用场景与实现
4.1 应用领域
Adam广泛用于计算机视觉(如图像分类)、自然语言处理(如Transformer模型)等领域,因其快速收敛和鲁棒性成为TensorFlow和PyTorch的默认优化器。
4.2 代码实现
以下为Keras中的实现示例:
from tensorflow.keras.optimizers import Adam
model.compile(optimizer=Adam(learning_rate=0.001), loss='categorical_crossentropy')PyTorch实现:
import torch.optim as optim optimizer = optim.Adam(model.parameters(), lr=0.001)5 Adam变体与改进
5.1 AMSGrad
针对Adam可能无法收敛的问题,Reddi等人(2018)提出AMSGrad,通过限制二阶矩的增长改进收敛性。Keras中可通过amsgrad=True启用。
5.2 其他变体
- AdamW:引入权重衰减正则化,改善泛化性能。
- NAdam:结合Nesterov动量,进一步加速收敛。
6 实验与比较
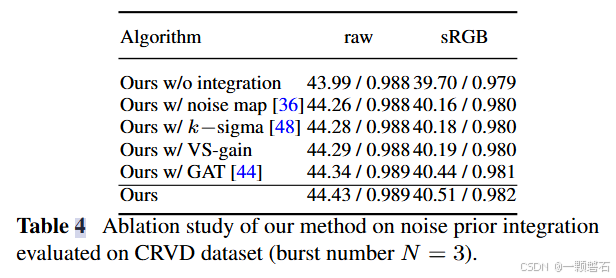
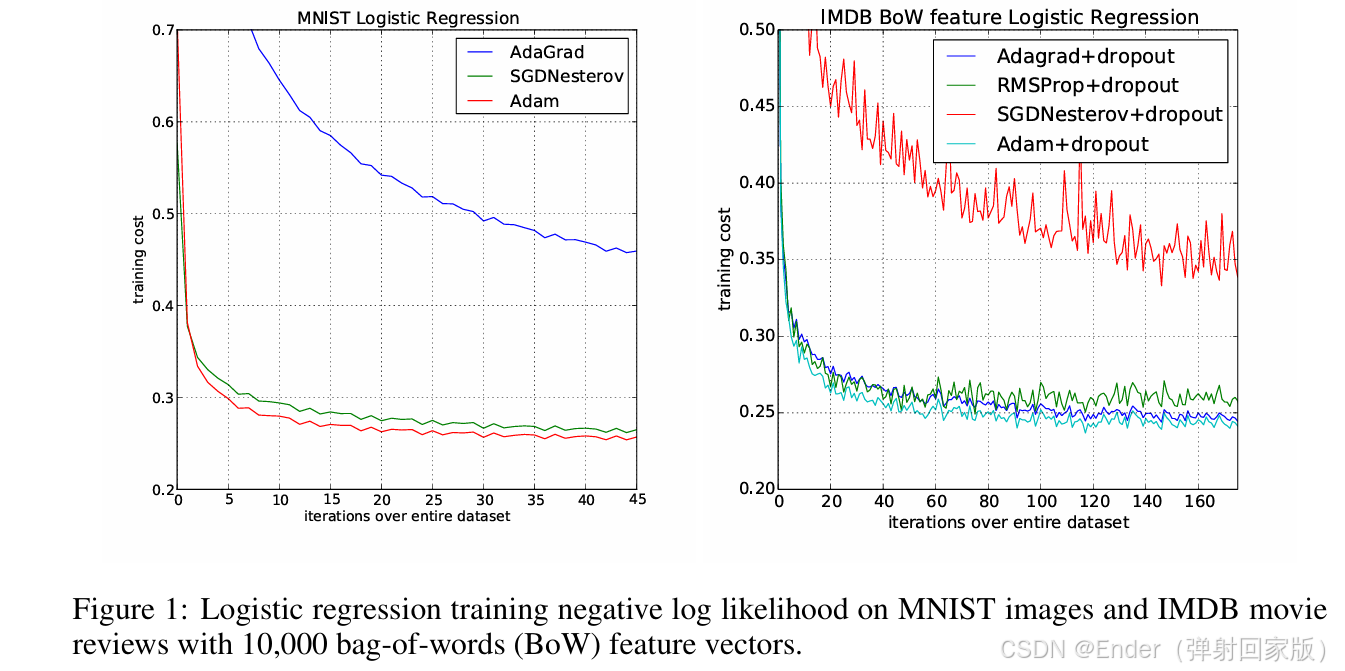
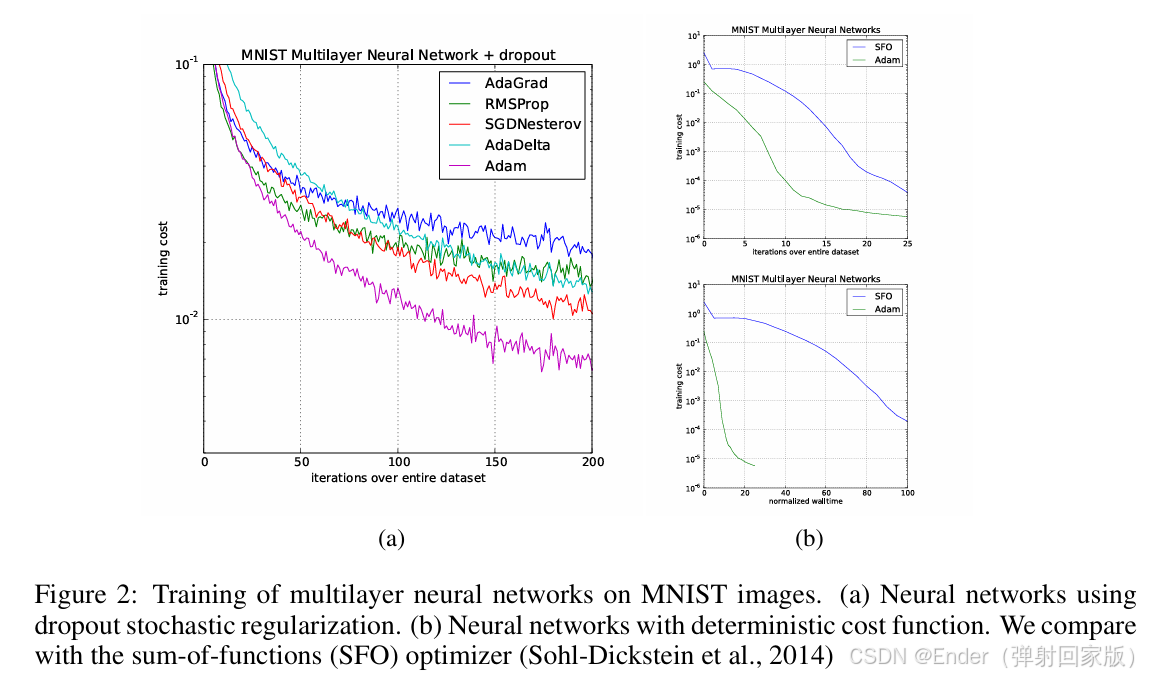
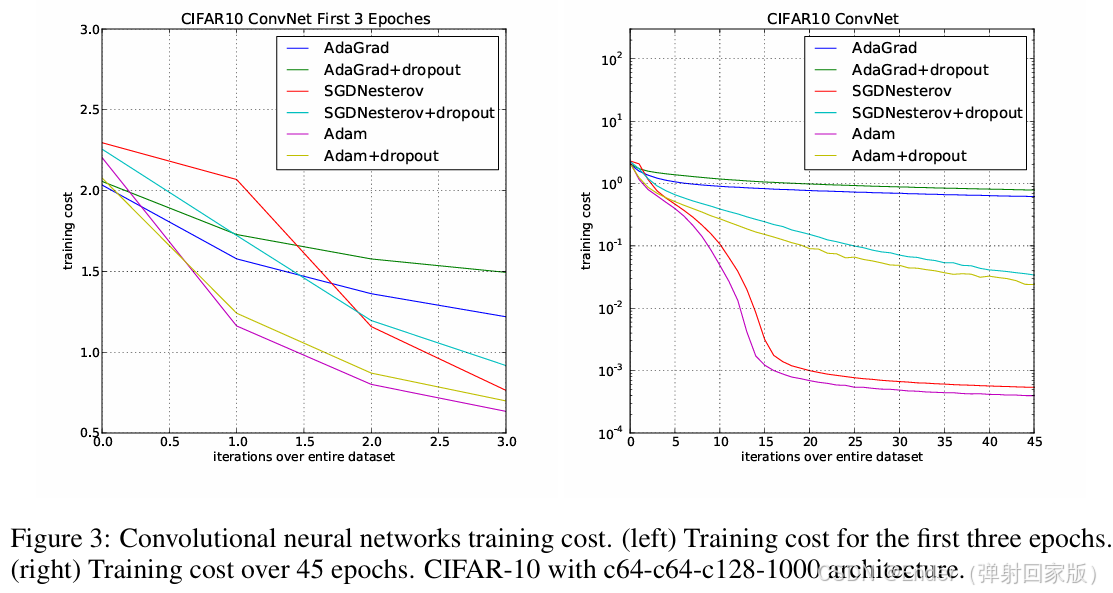
根据文献[1],Adam在MNIST和CIFAR-10数据集上的收敛速度优于SGD,但在ImageNet等大规模任务中,SGD with Momentum的泛化性能更佳。实际应用中,建议根据任务特性选择优化器。
7 结论与展望
Adam优化器凭借其自适应学习率和高效性,成为深度学习中的主流选择。然而,其泛化性能和特定场景下的局限性提示我们,应结合任务需求灵活选择优化策略。未来,Adam的变体及与其他算法的融合有望进一步提升性能。
参考文献
[1] Kingma D P, Ba J. Adam: A Method for Stochastic Optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
[2] Keras官方文档. Adam优化器[EB/OL]. Adam
, 2023.
[3] CSDN博客. Adam优化器(通俗理解)[EB/OL]. Adam优化器(通俗理解)-CSDN博客
, 2022.
[4] 动手学深度学习. Adam算法[EB/OL]. 11.10. Adam算法 — 动手学深度学习 2.0.0 documentation
, 2023.