文章目录
- c++内存管理
- c/c++的内存区域划分
- 回顾c语言动态内存管理
- c++动态内存管理
- new和delete的使用
- new和delete的底层逻辑
- operator new函数和operator delete函数
- new和delete的实现
- 操作方式不匹配的情况
- 定位new
- new/delete和malloc/free的区别
c++内存管理
在以往学习c语言的过程中,我们就已经学过对堆上的内存空间进行管理,就是使用malloc、calloc、realloc函数开辟空间,使用free函数进行释放空间。
当然c++作为对c语言的升级语言,是兼容c的用法的。但是在c++中使用这几个函数还是有一些缺陷的,所以c++引入了新的方式进行管理内存。具体的将会在后面进行讲解。
c/c++的内存区域划分
我们经常说局部变量存储在栈区,函数调用要开辟函数栈帧,说明内存区域有个地方是栈区。而我们经常使用的动态内存管理函数管理的是堆上的内容,其实堆也是内存空间中的一个分区。现在让我们来看看c/c++的内存区域划分:

大致是分为这么五个空间。内核空间是系统使用的,我们写的代码是无法访问这个区域的。
栈区是向下增长的,内部会存储一些局部变量或者函数栈帧。
堆区向上增长,这个部分的内存是可以让程序员自行分配和释放的。
数据段存放的是全局变量和静态变量,代码段存储的是常量。
正常来说,我们写的代码系统会自动处理到对应的区域,而堆区不一样。堆区是专门留给程序员自行分配的一块空间。我们所谓的动态内存管理,其实就是管理堆区的内存。其他地方我们是无法访问或者直接使用的。
为了更好理解以上内容,下面举一个例题加深理解:
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
char char2[] = "abcd";
const char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}
选择题:
选项: A.栈 B.堆 C.数据段(静态区) D.代码段(常量区)
globalVar在哪里?____
staticGlobalVar在哪里?____
staticVar在哪里?____
localVar在哪里?____
num1 在哪里?____
char2在哪里?____
*char2在哪里?___
pChar3在哪里?____
*pChar3在哪里?____
ptr1在哪里?____
*ptr1在哪里?____
第一个部分是很简单的,直接看图回答就可以了:
globalVar为全局变量,staticGlobalVar 、staticVar为静态变量,存储在数据段。
localVar是开辟在main函数的局部变量,存储在栈区。
num1单独出现是数组首元素的地址,这个数组也是main函数的临时变量,所以也在栈区。
第二个部分会比较难一点:
char2本质是个定义在main函数中的数组,在栈区。
而*char2很多人会误以为是”abcd“这个常量字符串的首元素,其实并不然,因为在main函数中开辟数组char2,将常量字符串复制给char2而已。所以*char2其实是被复制的那个的首元素,main函数里面那个,所以是在栈区。
而pchar3本质上也是main函数中定义的一个指针变量,所以存储在栈区。
const char* pChar3 = "abcd";这种写法是把常量字符串的地址(首元素的地址)给pchar3,所以对pchar3的解引用*pChar3是在常量区的那个"abcd"的首元素,所以*pchar3在数据段。
ptr1仍然是开辟在栈区上的一个指针变量,存储在栈区。
但是我们知道,ptr1指向的空间其实是在堆区上开辟的,也就是说,内部存储的数据是存放在堆区的,所以对ptr1解引用*ptr1是在堆区。
可以再画个图梳理一下:

回顾c语言动态内存管理
由于这部分内容已经讲过,所以就简单带过一下。
c语言中提供了三个函数用于开辟堆区内存:malloc、calloc、realloc。
三者的区别就是,malloc是一次性开辟内存空间,但不做初始化。calloc相比于malloc就是多了一个对内存中所有内容初始化为0的操作。而realloc是可以动态扩容的。
而c语言对于堆区内存释放是使用free函数的,应当养成良好习惯,用完内存如果后续不使用了就及时释放,以防内存泄漏。
对于更具体的内容可以参考另一篇文章:c语言之动态内存管理
c++动态内存管理
这个部分开始,将重点介绍c++中是如何对堆区的内存进行动态管理的。
new和delete的使用
c++中提供了两个操作符,即new和delete。很明显,看意思就能知道:
new是用来开辟内存的。delete是释放内存的。
先来看new的用法:
int main() {
//动态内存申请一个int的空间
int* ptr1 = new int;
//动态内存申请5个int空间
int* ptr2 = new int[5];
return 0;
}
变量声名的时候还是一样的,对于后面的用法,就是new + 数据类型。如果要开辟多个,就需要加入方括号。就很像开辟一个数组。
当然c++是支持再开辟内存的时候进行初始化的:
int main() {
//动态内存申请一个int的空间
int* ptr1 = new int;
//开辟一个int空间初始化为8
int* ptr3 = new int(8);
//动态内存申请5个int空间
int* ptr2 = new int[5];
//开辟五个int空间进行初始化
int* ptr4 = new int[5] {1, 2, 3, 4, 5};
return 0;
}
对于多个空间的初始化,其实和数组的行为是一致的:
若不进行初始化,则是随机值。若进行初始化,必须从前往后依次初始化,没有初始化的位置会默认为0。其实就是和数组类似。使用是十分简单的。
当然new可开辟的不只是内置数据类型,也可以是自定义类型,所以试试对类开辟内存:
class A {
public:
A(int a = 0, int b = 0,int c = 0) {
cout << "A()" << endl;//可以证明调用了默认构造函数
_a = a;
_b = b;
_ptr = new int(c);
}
private:
int _a;
int _b;
int* _ptr;
};
int main() {
A* PtrA = new A[4]{ (1,2,3),(1,2),(1) };
return 0;
}
我们来看一下对于这个A类的开辟是怎么样的:

从结果来看,我们发现开辟四个类对象的空间,调用了四次A类的默认构造函数。也就是说对于自定义类型,使用new操作符是会自行调用其默认构造函数。那么也就是说,我们再开辟空间的同时就可以完成类的初始化工作了。
我们来看看我们传入的参数是否奏效:

我们想要像这样一次性的赋值,发现是失败的。因为这是一个逗号表达式,取最后的值进行赋值。也就是PrtA[i] = int类型值,同时也发生了隐式类型转换。
所以要一次性传入多个值,就需要按照上一篇文章再类型转换中的写法:将所有的参数放在以恶搞大括号内进行传参:

这样做就成功了。这是需要特别注意的。
讲完了new的用法,我们再来看看delete的用法:
delete就是对开辟的内存空间进行释放:
int main() {
int* p1 = new int(5);
int* p2 = new int[5] {0};
delete p1;
delete[] p2;
return 0;
}
用法就是delete后面直接跟要释放的空间的起始地址。但是需要注意的是:如果删除的是多个空间,那就需要使用delete[]进行匹配,否则会出现问题。这个我们等下会将,先记住用法即可。
那对于自定义类型呢:
class A {
public:
A(int a = 0, int b = 0, int c = 0) {
cout << "A()" << endl;//可以证明调用了默认构造函数
_a = a;
_b = b;
_ptr = new int(c);
}
~A() {
cout << "~A()" << endl;//可以证明调用了析构函数
_a = _b = 0;
delete _ptr;
}
private:
int _a;
int _b;
int* _ptr;
};

从结论来看,对自定义类型使用delete的时候会自动调用其析构函数。
我们进入调试看看:

我们可以看到很明显是成功执行了对析构函数的调用的。
所以new相比于malloc等函数是更加有优势的。因为c语言中学习的那几个函数只能一次性开辟空间,或者初始化的内容为0,有时候可能不太满足要求。特别是对自定义类型数据,而使用new则解决了这个问题。
而delete再释放内存的时候还会自动调用自定义类型的析构函数,如果直接使用<kbd<free函数,那么像图中这种情况,类中也是有内存开辟的,但是直接使用<kbd<free只能针对于类类型的空间释放,其内部还是需要手动释放或者手动调用析构函数。所以<kbd<delete也是更加有优势。
所以以后尽量都会使用new和delete方式进行动态内存的管理。
new和delete的底层逻辑
本部分将会重点讲解new和delete的底层逻辑,理解底层逻辑是非常重要的。
operator new函数和operator delete函数
引入:
new和delete是用户进行动态内存申请和释放的操作符。
operator new 和operator delete才是系统提供的全局函数。
new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间。
先看看这两个函数的源码:
/*
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间
失败,尝试执行空 间不足应对措施,如果改应对措施用户设置了,则继续申请,否
则抛异常。
*/
void* __CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{
// try to allocate size bytes
void* p;
while ((p = malloc(size)) == 0)
if (_callnewh(size) == 0)
{
// report no memory
// 如果申请内存失败了,这里会抛出bad_alloc 类型异常
static const std::bad_alloc nomem;
_RAISE(nomem);
}
return (p);
}
/*
operator delete: 该函数最终是通过free来释放空间的
*/
void operator delete(void* pUserData)
{
_CrtMemBlockHeader* pHead;
RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));
if (pUserData == NULL)
return;
_mlock(_HEAP_LOCK); /* block other threads */
__TRY
/* get a pointer to memory block header */
pHead = pHdr(pUserData);
/* verify block type */
_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));
_free_dbg(pUserData, pHead->nBlockUse);
__FINALLY
_munlock(_HEAP_LOCK); /* release other threads */
__END_TRY_FINALLY
return;
}
/*
free的实现
*/
#define free(p) _free_dbg(p, _NORMAL_BLOCK)
看着很复杂,但是实际上我们开始看到了一些眼熟的内容。如在operator new函数中发现了malloc函数 、在operator delete函数中发现了free函数,也就是说,这两个函数底层逻辑其实还是走的c语言那套,只不过是进行了更高级的包装。因为刚刚说到了对于自定义的类型是要进行自行调用默认构造函数和析构函数的。
当然有的人会问了,这个都没有返回值啊,怎么样检查内存开辟是否成功呢?
这里先稍微提及一下:这两个函数对于内存开辟是否成功并不是通过返回值来检查的。
c语言中malloc那几个函数在开辟失败的时候会返回空指针,所以我们会通过返回值检查。但是c++中,如果一旦出现问题,系统会抛异常,即可以认为将一个异常的信号抛出。那我们就可以尝试去捕获,然后调用对应函数就可以知道出现什么问题了:
int main() {
int count = 0;
try
{
int** ptr = new int* [100000];
int i = 0;
while (1) {
ptr[i] = new int[100000];
count++;
cout << count << endl;
}
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
这里我们来试探一下,在x64平台下,每次开辟100000个int类型数据的空间能开辟多少次:

这里我们就是使用了抛异常和捕获异常的方式来判断内存是否开辟成功。当连续开辟这么多个字节到61048次的时候,抛出了异常。我们捕获,使用其内部函数what进行查看是什么问题。这个bad allocation就是内存不足了。
但是我们发现可以开辟那么多空间,我们平常写的练习或者刷题目是很难达到这个内存不足的要求的。所以我们当前情况下可以先只进行了解抛异常机制。平常练习可以先不用对内存开辟进行检查,因为基本上都是成功的。
new和delete的实现
对于内置类型:
如果申请的是内置类型的空间,new和malloc,delete和free基本类似,不同的地方是:
new/delete申请和释放的是单个元素的空间,new[]和delete[]申请的是连续空间,而且new在申
请空间失败时会抛异常,malloc会返回NULL。区别就在于检查机制。
对于自定义类型:
new的原理
1.调用operator new函数申请空间
2.在申请的空间上执行构造函数,完成对象的构造
delete的原理
1.在空间上执行析构函数,完成对象中资源的清理工作
2.调用operator delete函数释放对象的空间
new T[N]的原理
1.调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对
象空间的申请
2.在申请的空间上执行N次构造函数
delete[]的原理
1.在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
2.调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释
放空间
对于开辟一个空间或者释放一个空间的情况其实是很简单的,只不过在开辟空间的时候会调用其默认构造函数,释放的时候会调用其析构函数。
对于自定义类型,如果是开辟多个空间,其实就是对应使用operator new[]和operator delete[]这两个全局函数。只不过就是多调用了几次的默认构造函数和析构函数罢了,不算复杂,真正到底层实现也是会调用多次的free和malloc。
而对于开辟多个空间和释放多个空间就需要特别注意了。特别是对于new T[]这个操作,如果自定义类中写了析构函数,系统会多分配四个字节的空间放在这个连续空间的头部,记录的是这一串空间的元素个数。这个等下我们在操作方式不批撇的情况下还会细讲。
操作方式不匹配的情况
先说结论:
进入了c++板块后,我们基本上都是使用new和delete进行动态的内存管理的。而且要做到使用匹配。这样子是不会出现问题的。
现在来看操作不匹配的情况下:
我们前面说到:new和delete的底层最终都是会调用malloc和free,我们现在来看一下下面几种情况:
int main() {
int* ptr = new int[5] {1, 2, 3, 4, 5};
free(ptr);
return 0;
}
我们直接使用free对开辟的空间进行释放,请问会报错或者导致内存泄露吗?
我们来看看结果:

很明显,这是没有任何问题的。所以对于内置类型的数据,直接使用free也是可以的。因为delete的底层也就是调用了free,只不过需要有一些检查。
那我们再来看看如果是自定义类型数据呢?

发现好像也挺正常的,但是我们得想到一个问题,如果类中的某个成员变量是指向一块资源的,那就很麻烦了。因为我们调用free只是对开辟的三个B类对象的空间进行释放了,但是其内部还是有资源的话,那么指向的那块资源是无法被释放的。这就导致内存泄漏。
所以一定要注意配套使用,这样子就很难出现问题了。
当然,new和delete也需要注意对应的配套:
即new和delete是配对的,new[]和delete[]是配对的。
我们来看下面一段代码的运行情况:
class B {
public:
B(int a = 0, int b = 0) {
cout << "B" << endl;
_a = a;
_b = b;
}
private:
int _a;
int _b;
};
int main() {
B* p = new B[3]{ {1,2,3},{1,2},{1} };
delete p;
return 0;
}

这是可以正常运行的,是不是说可以不用匹配使用呢?
答案没有那么简单,我们再来看下面这个代码:
class A {
public:
A(int a = 0, int b = 0) {
cout << "A" << endl;
_a = a;
_b = b;
}
~A() {
cout << "~A" << endl;
_a = _b = 0;
}
private:
int _a;
int _b;
};
int main() {
A* p = new A[3]{ {1,2},{1} };
delete p;
return 0;
}
我们来看看运行起来是什么效果:

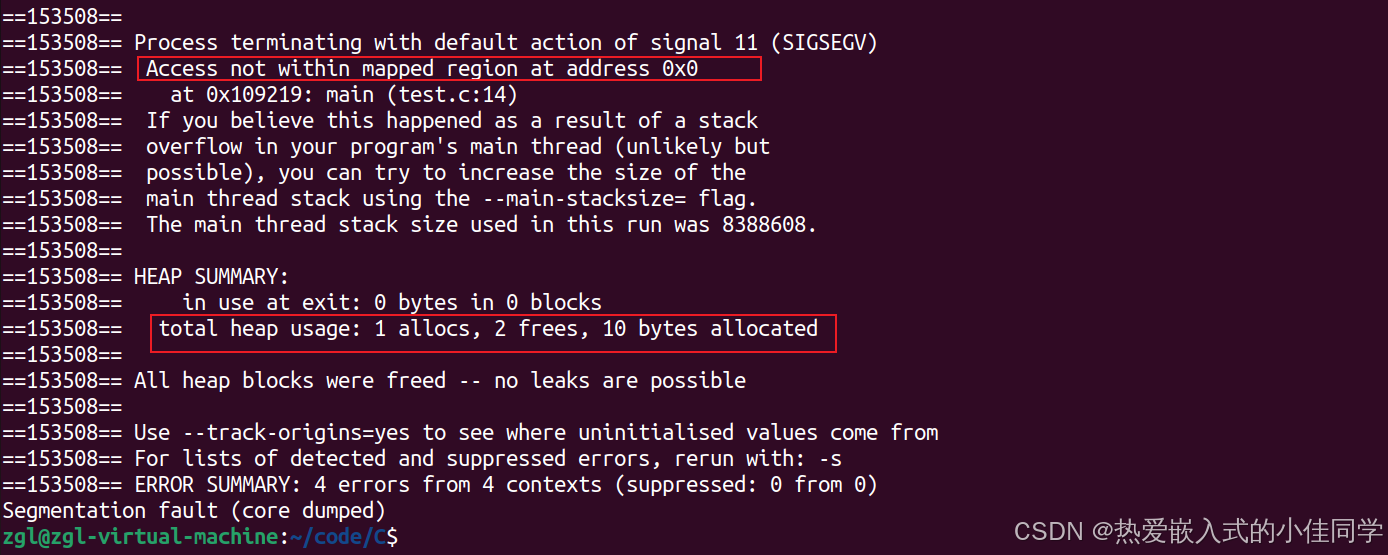
程序竟然崩溃了,这是为什么呢?
这就要说到在上一个点讲到的:
对于自定义类型数据,如果类中写了析构函数,那么在开辟多个空间的时候,系统会多开四个字节在头部存储空间的个数。
我们可以进入监视窗口看看:

x86平台下,系统会多开4个字节。但是我们使用delete的操作的话,如果没有析构函数,那么编译器会优化,直接就不开那么多空间。
注意x64平台下会开8个字节的空间,但是原理和x86平台一样,所以以x86平台下进行举例。

而使用delete即编译器会在第一个元素开始的位置进行释放。delete[]会在所有空间(包括记录数据个数的那个空间)的开始位置开始释放。
然而因为堆区上的内存是不能只释放其中一部分的。所以编译器就会报错了。
所以我们最好的做法就是进行匹配使用,这样子就不会出什么问题了。
定位new
定位new也称为replacement_new,主要还是配合内存池来使用。由于当前还没有相应的知识,所以当前先只做一些了解即可。
内存池是池化技术的一种,即有时候对于某些情况下,某个功能可能需要多次的申请访问内存和释放内存,就需要一直向堆来申请。这是十分麻烦的,效率可能不太高。
所以就专门想出一个办法,从堆中专门划分一块内存空间给某功能进行使用。如果不够了可以再增加。这就有点像一个池子,从中取内存和释放内存。
那这就需要使用operator new这个函数了,对专门的内存池进行开辟内存。
其用法其实和malloc函数是类似的:
int main(){
// p1现在指向的只不过是与A对象相同大小的一段空间,还不能算是一个对象,因为构造函数没有执行
A* p1 = (A*)malloc(sizeof(A));
new(p1)A; // 注意:如果A类的构造函数有参数时,此处需要传参
p1->~A();
free(p1);
A* p2 = (A*)operator new(sizeof(A));
new(p2)A(10);
p2->~A();
operator delete(p2);
return 0;
}
operator new是没有办法像new操作符那样直接调用类的默认构造函数和析构函数的,只是可以专门的对某块位置开辟内存空间。
还需要注意一下使用operator new函数后如何对指向的空间进行初始化。
格式:new(指向空间的指针)类名
如果类中构造函数有参数的话,传参就在后面再加入一个括号输入参数
格式为:new(指向空间的指针)类名(参数1,参数2…)
当然,当前先只做了解即可。本篇文章主要是对内存管理的基本用法和注意点进行讲解。
new/delete和malloc/free的区别
malloc/free和new/delete的共同点是:都是从堆上申请空间,并且需要用户手动释放。不同的地方是:
- malloc和free是函数,new和delete是操作符
- malloc申请的空间不会初始化,new可以初始化
- malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,如果是多个对象,[]中指定对象个数即可
- malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型
- malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需
要捕获异常 - 申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理释放