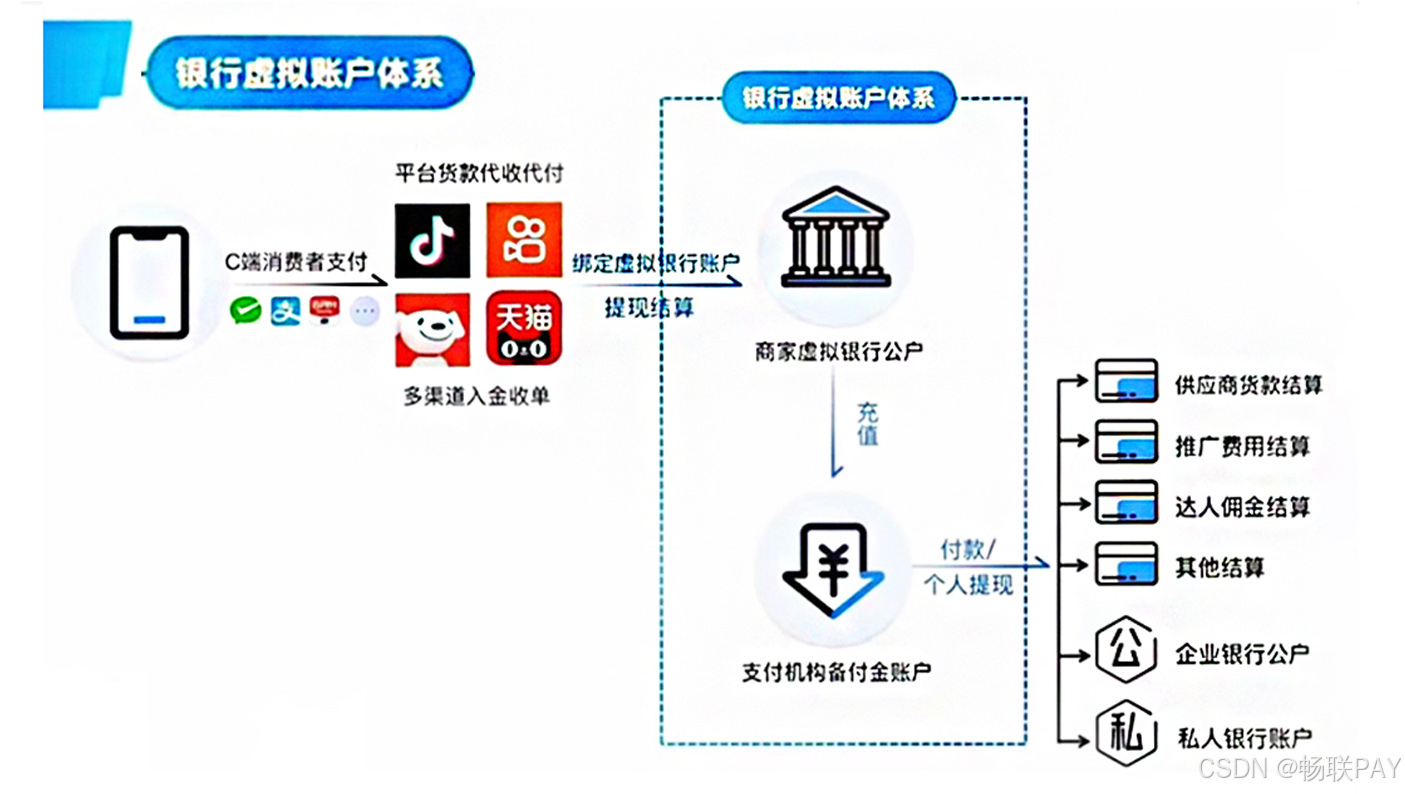
在分布式系统中,生成全局唯一ID是核心需求之一。雪花算法和UUID是两种广泛使用的解决方案。
1. 雪花算法
工作原理
- 分布式ID生成器:由Twitter开源,专为分布式系统设计。
- 组成结构(64位二进制):
- 符号位(1位):固定为0,保证ID为正数。
- 时间戳(41位):当前时间与自定义起始时间(如Twitter的2010-01-01)的毫秒差值,精确到毫秒级,可用约69年。
- 工作节点ID(10位):可配置的机器或进程标识,支持最多1024个节点。
- 序列号(12位):同一毫秒内的自增序号,支持每节点每毫秒生成4096个ID。
- 工作原理:
- 时间戳递增:每次生成ID时获取当前时间戳,若与上次相同,则递增序列号。
- 处理并发:若序列号用尽(达到4096),则等待至下一毫秒再重置序列号。
- 时钟回拨问题:若系统时间回退,可能导致ID冲突。常见解决方案:
- 短暂回拨:等待时间恢复。
- 严重回拨:抛出异常或扩展时间戳位数记录回拨次数。
- 特点:
- 趋势递增:时间戳在高位,生成的ID整体按时间递增,有利于数据库索引优化。
- 依赖时钟:强依赖系统时钟,时钟回拨可能导致ID冲突。
适用场景
- 需要有序ID的场景:
- 数据库主键(如MySQL InnoDB的聚簇索引)。
- 时序数据存储(如日志、监控数据)。
- 分布式系统:
- 微服务架构下的订单ID、支付流水号。
- 需要高吞吐量的ID生成(每秒百万级)。
- 存储敏感场景:
- 要求ID尽可能短(如短链服务、二维码标识)。
2. UUID
- 通用唯一标识符:标准化由RFC 4122定义,无需中心化协调。
- 常见版本:
- UUIDv1:基于时间戳和MAC地址生成,可能暴露隐私信息。
- UUIDv4:完全随机生成(122位随机性),冲突概率极低(约需生成约2.6×10^18个UUID才有1%的冲突概率)。
- UUIDv5/UUIDv3:基于命名空间和哈希算法(如SHA-1或MD5)。
- 组成结构(128位,36字符字符串):
- 示例:123e4567-e89b-12d3-a456-426614174000
- 工作原理:
- UUIDv1:结合时间戳、节点MAC和随机数,确保时空唯一性。
- UUIDv4:依赖强随机数生成器(如加密算法),重复概率极低(约10^37分之一)。
- 优点:
- 去中心化:无需节点协调,节点生成简单。
- 高唯一性:128位空间,重复概率极低。
- 缺点:
- 无序性:随机生成的ID导致数据库索引分裂,影响写入性能。
- 存储成本高:128位(16字节)是Snowflake的两倍。
- 信息泄露风险:可能暴露MAC地址和生成时间。
适用场景
- 去中心化生成:
- 客户端生成的临时标识(如文件上传令牌、浏览器Cookie)。
- 无需服务端协调的多节点系统。
- 隐私要求低:
- 内部系统日志追踪(使用UUIDv4)。
- 非敏感资源的唯一标识(如图片存储key)。
- 兼容性低:
- 跨语言、跨平台系统(UUID是通用标准)。
3. 雪花算法 VS UUID
| 特性 | 雪花算法 | UUID |
|---|---|---|
| 长度 | 64位(短,存储高效) | 128位(长,占用更多空间) |
| 有序性 | 时间戳有序,适合范围查询 | 完全无序,索引效率低 |
| 生成方式 | 依赖时钟和节点配置 | 本地生成,无需协调 |
| 冲突概率 | 理论上无冲突(时钟正常时) | 极低,但非绝对为零 |
| 隐私风险 | 无 | UUIDv1可能暴露MAC地址和时间信息 |
| 时钟依赖 | 严重依赖时钟,回拨会导致问题 | 无依赖(除UUIDv1) |
| 适用场景 | 高并发分布式系统(如订单、日志) | 无需协调的临时标识(如会话ID) |
3.1 如何选择
- 选择雪花算法:
- 需要有序ID以优化数据库性能。
- 对存储和传输效率敏感(如海量数据场景)。
- 能接受节点ID管理和时钟回拨处理成本。
- 选择UUID:
- 无需有效性,追求简单实现和去中心化。
- 接受存储开销,且不依赖高并发索引(如文件ID、临时令牌)。
- 优先使用UUIDv4以避免MAC泄露风险。