一,取证与溯源
镜像文件解压密码:44216bed0e6960fa
1.运维人员误删除了一个重要的word文件,请通过数据恢复手段恢复该文件,文件内容即为答案。
先用R-stuido软件进行数据恢复
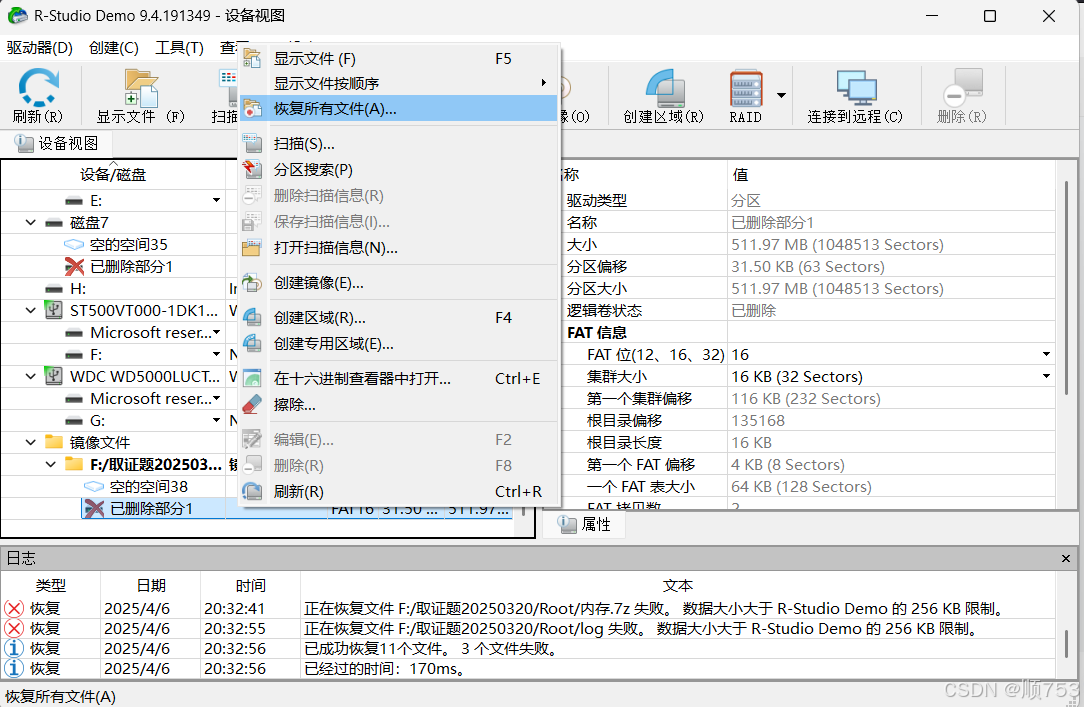
得到
打开重要文件.docx全选发现有一条空白的被选中,

为其加上背景颜色就可以看见

2.服务器网站遭到了黑客攻击,但服务器的web日志文件被存放在了加密驱动器中,请解密获得该日志并将黑客ip作为答案提交。
我直接在使用windows的挂载没有成功,使用FTK-image的镜像挂载成功
得到,和前面的对比可以看见,直接挂载是没有重要文件.docx的
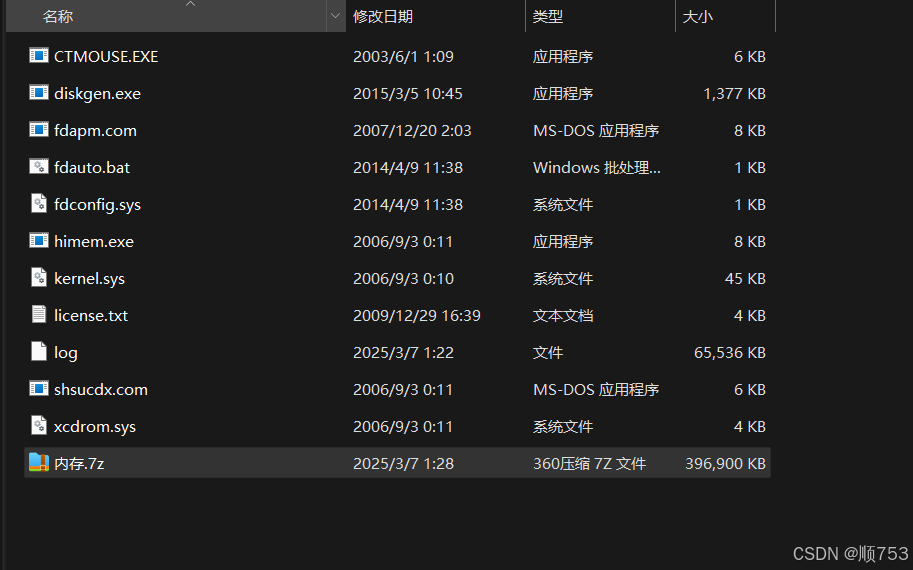
way一: 直接用vol,先看版本信息
vol -f F:\取证题20250320\Root\WIN-IRBP5Q8F25I-20250306-172341.raw windows.info
注:这里更换了vol3,之前的版本提取不出来,不知道为什么
扫描.log文件,开始就得到了access.log文件
vol -f F:\取证题20250320\Root\WIN-IRBP5Q8F25I-20250306-172341.raw windows.filescan | Select-String "log"
将文件导出来,可以看见
vol -f F:\取证题20250320\Root\WIN-IRBP5Q8F25I-20250306-172341.raw windows.dumpfiles --physaddr 0x7c23ba40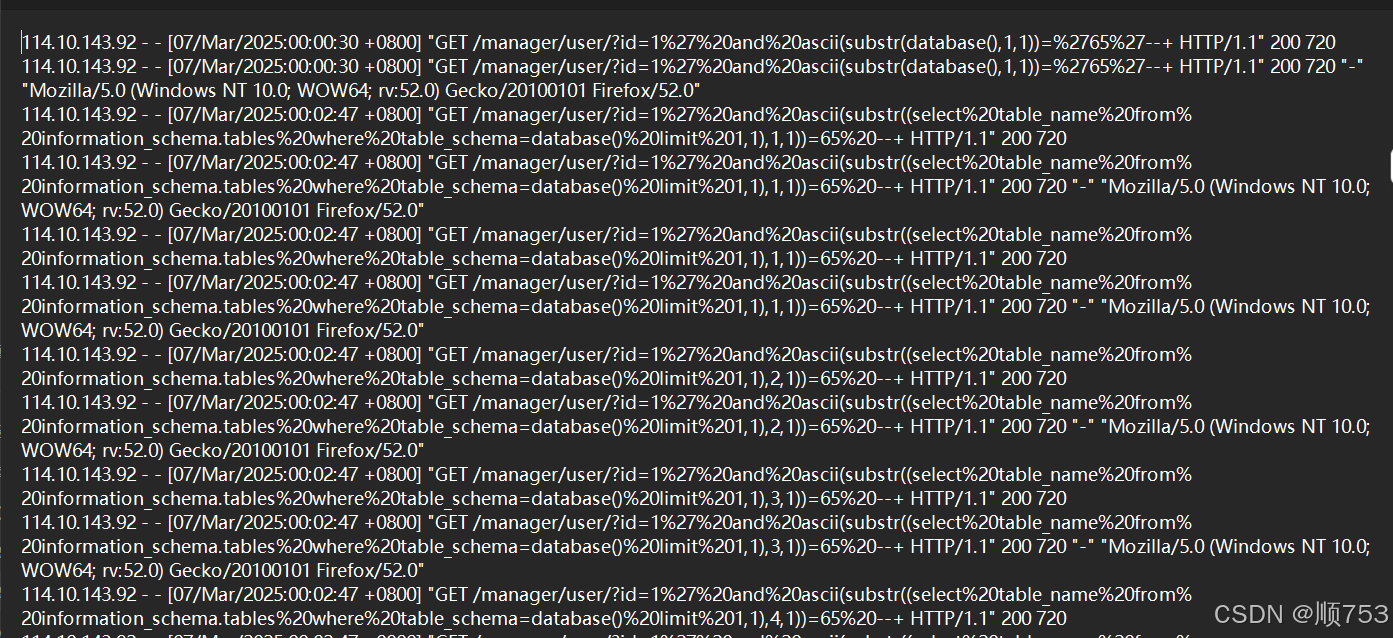
way2:使用R-stuido软件扫描后看text文档,然后查看文档的内容,可以在里面找到ngnix的access.log日志,文件内容可以看出来里面有sql攻击的记录。
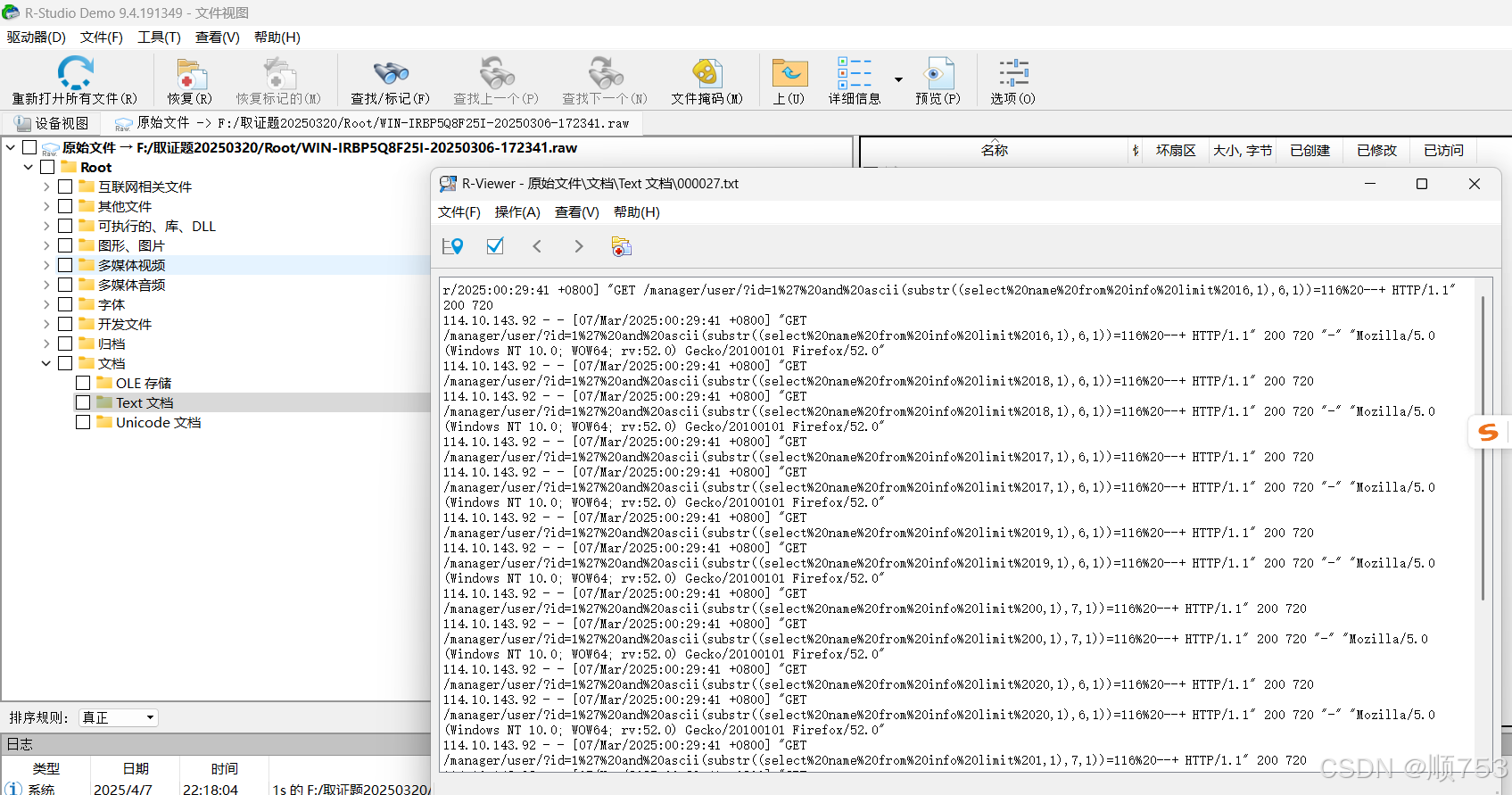
3.经分析,黑客在攻击中窃取了一些重要信息,请分析web日志,获取黑客窃取的相关信息,并将黑客窃取的所有身份证号按照其姓名拼音首字母升序排序,并计算其32位小写md5作为答案提交(如zhangsan的身份证是110101199001011234,lisi的身份证是110101198505051234,zhangfei的身份证是110101199203031234,则最终顺序为110101198505051234110101199203031234110101199001011234,计算其32小写md5”9ac198054af03107b2452bee3091b9ef”就是答案)
import re
from collections import defaultdict
import hashlib
from pypinyin import pinyin, Style
# 初始化数据结构 - 改为存储完整记录
records = defaultdict(lambda: {'name': '', 'id_card': ''})
# 优化后的正则表达式,同时匹配name和id_card
pattern = r"ascii\(substr\(\(select%20(name|id_card)%20from%20info%20limit%20(\d+),1\),(\d+),1\)\)=(\d+)"
def extract_payload(line):
"""从日志行中提取攻击载荷部分"""
parts = line.split("\t")
if len(parts) >= 3 and "/manager/user/?id=" in parts[2]:
return parts[2]
return None
# 处理日志文件
with open("sfz.txt") as f:
for line in f:
line = line.strip()
payload = extract_payload(line)
if payload:
match = re.search(pattern, payload)
if match:
field = match.group(1)
index = int(match.group(2))
position = int(match.group(3))
ascii_val = int(match.group(4))
# 拼接字符到对应位置
if position > len(records[index][field]):
records[index][field] += ' ' * (position - len(records[index][field]) - 1)
records[index][field] += chr(ascii_val)
else:
# 如果位置已存在,更新字符(防止重复数据覆盖)
if position <= len(records[index][field]):
records[index][field] = records[index][field][:position-1] + chr(ascii_val) + records[index][field][position:]
else:
records[index][field] += chr(ascii_val)
# 过滤有效记录(同时有姓名和18位身份证号)
valid_records = []
for idx, data in records.items():
name = data['name'].strip()
id_card = data['id_card'].strip()
if name and id_card and len(id_card) == 18:
valid_records.append({'name': name, 'id_card': id_card})
# 按姓名拼音首字母排序
def get_pinyin_initial(name):
"""获取姓名拼音首字母"""
try:
initials = pinyin(name, style=Style.FIRST_LETTER)
return ''.join([i[0].lower() for i in initials])
except:
return 'z' # 拼音转换失败时放到最后
valid_records.sort(key=lambda x: get_pinyin_initial(x['name']))
# 构建结果字符串
result_str = ""
for record in valid_records:
result_str += f"{record['id_card']}"
print(result_str)
# 计算MD5
md5_hash = hashlib.md5(result_str.strip().encode('utf-8')).hexdigest()
# 输出结果
print("=== 按姓名拼音排序的结果 ===")
for record in valid_records:
print(f"{record['name']}: {record['id_card']}")
print("\n=== 最终MD5哈希值 ===")
print(md5_hash)
# 将结果保存到文件
with open("sorted_results.txt", "w", encoding='utf-8') as f:
f.write("姓名,身份证号\n")
f.write(result_str)
f.write(f"\nMD5: {md5_hash}")
运行得到结果为
=== 按姓名拼音排序的结果 ===
ChenFang: 500101200012121234
GaoFei: 340104197612121234
GuoYong: 530102199810101234
HeJing: 610112200109091234
HuangLei: 230107196504041234
LiangJun: 120105197411111234
LiNa: 310115198502021234
LinYan: 370202199404041234
LiuTao: 330106197708081234
LuoMin: 450305198303031234
MaChao: 220203198808081234
SongJia: 350203200202021234
SunHao: 130104198707071234
WangWei: 110101199001011234
XieFang: 430104199707071234
XuLi: 320508200005051234
YangXue: 510104199311111234
ZhangQiang: 440305199503031234
ZhaoGang: 420103199912121234
ZhouMin: 210202198609091234
ZhuLin: 410105199206061234
=== 最终MD5哈希值 ===
060b534ffb5c4a487be36cca98165e73