目录
一、数据文件
二、模型配置文件 config.py
三、数据加载文件 loader.py
1.导入文件和类的定义
2.初始化
3.数据加载方法
代码运行流程
4.文本编码 / 解码方法
① encode_sentence():
② decode():
代码运行流程
③ padding():
代码运行流程
5.类内魔术方法
6.加载映射关系文件
7.加载词表
8.数据加载器封装
9.数据加载文件测试
10.完整代码
四、模型文件 model.py
1.导入文件
2.将字典配置包装为对象
3.模型初始化
4.前向计算
代码运行流程
5.选择优化器
6.模型文件测试
7.完整代码
五、模型评估文件 evaluate.py
1.类初始化
2.评估模型方法
代码运行流程
3.统计写入
代码运行流程
4.统计结果展示
代码运行流程
5.解码
分组类别规定
代码运行流程
6.完整代码
六、模型训练文件 main.py
代码运行流程
1.导入文件
2.日志文件配置
3.LoRA目标模块配置(包装函数)
4.模型训练主程序
① 创建保存模型的目录
② 加载训练数据
③ 加载模型
④ 标识是否使用GPU
⑤ 加载优化器
⑥ 加载效果测试类
⑦ 训练主流程 ⭐
Ⅰ、Epoch循环控制
Ⅱ、模型设置训练模式
Ⅲ、Batch数据遍历
Ⅳ、梯度清零与设备切换
Ⅴ、前向传播与损失计算
Ⅵ、反向传播与参数更新
Ⅶ、损失记录与日志输出
Ⅷ、Epoch评估与日志
Ⅸ、完整训练代码
七、模型预测文件 predict.py
代码运行流程
1.导入文件
2.初始化
3.加载映射关系表
4.加载字词表
5.文本句子编码
6.解码文本
代码运行流程
7.预测文件
代码运行流程
8.模型效果测试
9.完整代码
Death is not an end, but silence when storie cease.
死亡不是终点,遗忘才是
—— 25.4.5
一、数据文件
通过网盘分享的文件:Ner命名实体识别任务
链接: https://pan.baidu.com/s/1r8cjMyIdQ0oWcNvtIK35Qw?pwd=98u7 提取码: 98u7
--来自百度网盘超级会员v3的分享
二、模型配置文件 config.py
model_path:模型保存路径,训练后的模型权重和文件会存储在该目录下。
schema_path:定义任务中实体类别或标签的配置文件路径(通常是 JSON 文件)
train_data_path:训练数据集的存储路径,通常包含训练文本和对应的标签文件
valid_data_path:验证/测试数据集的存储路径,用于模型性能评估。
vocab_path:词汇表文件路径,包含所有可能的字符或词语列表,用于构建模型的输入编码(如字符级或词级 Embedding)。
max_length:输入文本序列的最大长度。超过此长度的文本会被截断,不足的会用占位符(如 [PAD])填充。
hidden_size:神经网络隐藏层的维度大小(例如 LSTM、Transformer 层的隐藏单元数)。
num_layers:神经网络的层数(如 LSTM 或 Transformer 的堆叠层数)。
epoch:训练的总轮次,即模型遍历整个训练数据集的次数。
batch_size:每次输入模型的样本数量。较大的 batch_size 会占用更多内存,但可能加速训练。
optimizer:优化器类型,用于更新模型参数以最小化损失函数。
learning_rate:学习率,控制参数更新的步长。较小的值收敛更稳定,但速度较慢;较大的值可能不稳定。
use_crf:是否在模型输出层使用 CRF(条件随机场)。CRF 常用于序列标注任务(如 NER)以提升标签序列的合理性。
class_num:分类任务的类别数量。在 NER 任务中,通常为实体类型数 + 1(例如 O 表示非实体)。
bert_path:预训练 BERT 模型的本地路径,用于加载 BERT 的权重和配置
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
Config = {
"model_path": "model_output",
"schema_path": "ner_data/schema.json",
"train_data_path": "ner_data/train",
"valid_data_path": "ner_data/test",
"vocab_path":"chars.txt",
"max_length": 100,
"hidden_size": 256,
"num_layers": 2,
"epoch": 10,
"batch_size": 16,
"optimizer": "adam",
"learning_rate": 1e-3,
"use_crf": False,
"class_num": 9,
"bert_path": r"F:\人工智能NLP/NLP资料\week6 语言模型/bert-base-chinese"
}三、数据加载文件 loader.py
1.导入文件和类的定义
json:用于 JSON 文件的读写。
re:正则表达式库,处理字符串匹配和文本清洗。
os:操作系统接口库,处理文件路径和目录操作。
torch:PyTorch 深度学习框架,提供张量计算、自动求导和模型训练功能。
random:生成 随机数,用于数据随机化。
jieba:中文分词工具,将中文文本分割成词语序列。
numpy:数值计算库,支持高效的数组和矩阵运算。
Dataset:PyTorch 数据集的基类,用于封装自定义数据集。
DataLoader:批量加载数据的工具,支持多进程加速和随机采样。
defaultdict:提供 默认值字典,当键不存在时返回指定类型的默认值。
BertTokenize:HuggingFace Transformers 库中的 BERT 分词器,用于将文本转换为 BERT 模型所需的输入格式。
DataGenerator:自定义数据生成类
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from transformers import BertTokenizer
"""
数据加载
"""
class DataGenerator:2.初始化
data_path:原始数据存储路径(如 ner_data/train),指向包含训练/验证数据的文件或目录。
config:全局配置字典,存放模型超参数、路径和其他运行配置。
self.config:将外部传入的 config 参数保存为类实例的属性,方便在整个类中访问配置内容。
self.path:将传入的 data_path 保存为类实例属性,表示要处理的数据路径。
self.tokenizer:BERT 分词器对象,负责将原始文本转换为 BERT 模型所需的输入格式
self.sentences:存储预处理后的数据集
self.schema:标签到索引的映射字典,通常从 schema.json 文件中加载。
schema_path:指向一个 标签定义文件(通常是 JSON 格式),用于明确任务中的类别或标签体系。
self.load_vocab():从 bert_path 加载 BERT 分词器的自定义实现方法
self.load_schema():解析 schema.json 文件,生成标签与索引的映射字典
self.load():核心数据加载方法,负责以下操作:读取数据、数据处理、保存数据
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.tokenizer = load_vocab(config["bert_path"])
self.sentences = []
self.schema = self.load_schema(config["schema_path"])
self.load()3.数据加载方法
代码运行流程
# `load()` 方法运行流程
├── 1. **初始化数据容器**
│ - `self.data = []`: 创建空列表存储处理后的样本(每个样本为 `[input_ids, labels]` 张量对)
├── 2. **读取原始文件**
│ - `with open(self.path, encoding="utf8") as f`: 打开 `data_path` 指向的数据文件
│ - `segments = f.read().split("\n\n")`: 按空行分段落(每个段落为一个样本)
├── 3. **遍历每个段落(样本)**
│ │
│ ├── 3.1 **初始化当前样本**
│ │ - `sentenece = []`: 存储字符序列(如 `["我", "爱", "NLP"]`)
│ │ - `labels = [8]`: 初始化标签列表,首项为 `8`(可能是 `[CLS]` 标签的预设值)
│ │
│ ├── 3.2 **按行处理段落内容**
│ │ │
│ │ ├── 3.2.1 **跳过空行**
│ │ │ - `if line.strip() == "": continue`
│ │ │
│ │ ├── 3.2.2 **分割字符和标签**
│ │ │ - `char, label = line.split()`: 例如行内容为 `"我 O"` → `char="我", label="O"`
│ │ │
│ │ ├── 3.2.3 **收集字符和标签**
│ │ - `sentenece.append(char)`: 字符加入列表
│ │ - `labels.append(self.schema[label])`: 标签转换为索引(如 `"O"` → `0`)
│ │
│ ├── 3.3 **生成完整句子**
│ │ - `sentence = "".join(sentenece)`: 合并字符为字符串(如 `"我爱NLP"`)
│ │ - `self.sentences.append(sentence)`: 保存原始句子(可能用于调试或展示)
│ │
│ ├── 3.4 **编码句子为 input_ids**
│ │ - `input_ids = self.encode_sentence(sentenece)`: 调用 `encode_sentence` 方法生成 BERT 输入 ID
│ │
│ ├── 3.5 **填充标签序列**
│ │ - `labels = self.padding(labels, -1)`: 调用 `padding` 方法,填充标签到固定长度(用 `-1` 表示填充位)
│ │
│ └── 3.6 **保存为张量对**
│ - `self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])`: 转换为 PyTorch 张量并存入 `self.data`
└── 4. **返回**
- `return`: 方法结束,`self.data` 准备就绪供后续使用self.data:存储预处理后的数据样本,每个样本是一个列表,包含两个 torch.LongTensor 张量
open():打开文件并返回文件对象,用于读取或写入文件内容。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
file | str | 必填 | 文件路径(如 "data.txt")。 |
mode | str | 'r' | 文件模式:'r'(读)、'w'(写)、'a'(追加)、'b'(二进制模式)等。 |
encoding | str | 系统默认 | 文本编码(如 "utf-8")。 |
| 其他参数 | - | - | 如 errors(编解码错误处理)、newline(换行符控制)等。 |
self.path:原始数据存储路径(如 ner_data/train),指向包含训练/验证数据的文件或目录。
f:文件对象,表示已打开的文件句柄,用于读取内容
segments:存储按空行分割后的段落列表,每个段落对应一个样本。
segment:单个段落(即一个样本),包含多行文本,每行格式为字符标签。
文件对象.read():从文件中读取内容,返回字符串或字节对象。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
size | int | None | 读取的字节数(若未指定则读取全部)。 |
字符串.split():按分隔符分割字符串,返回列表。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
sep | str | None | 分隔符(默认为所有空白字符)。 |
maxsplit | int | -1 | 最大分割次数(默认无限制)。 |
sentence:合并当前段落中的所有字符,生成完整的原始句子字符串。
labels:存储标签索引序列,初始值为 [8]([CLS]标签的预留位置)
line:段落中的单行文本,格式为 字符标签(如 "我 O")。
字符串.strip():去除字符串两端的指定字符(默认去除空白符)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
chars | str | None | 要删除的字符集合(默认空白符)。 |
char:单个字符(如 "我"),从每行文本中提取。
label:标签名(如 "O"、"B-PER"),从每行文本中提取。
列表.append():向列表末尾添加元素,无返回值。
| 参数名 | 类型 | 说明 |
|---|---|---|
object | any | 要添加的元素。 |
字符串.join():用指定字符串连接可迭代对象中的元素。
| 参数名 | 类型 | 说明 |
|---|---|---|
iterable | iterable | 要连接的元素(如列表、元组)。 |
self.encode_sentence():自定义编码方法,将字符列表编码为 BERT 的 input_ids。
self.padding():自定义方法,将标签序列填充到固定长度。
torch.LongTensor():创建长整型(64 位)张量,支持从列表、数组等初始化。
| 参数名 | 类型 | 说明 |
|---|---|---|
data | array-like | 初始化数据(如列表、NumPy 数组)。 |
dtype | torch.dtype | 张量数据类型(默认为 torch.int64)。 |
device | torch.device | 张量存储设备(如 "cpu" 或 "cuda")。 |
requires_grad | bool | 是否启用梯度计算(默认为 False)。 |
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
segments = f.read().split("\n\n")
for segment in segments:
sentence = []
labels = [8] # cls_token
for line in segment.split("\n"):
if line.strip() == "":
continue
char, label = line.split()
sentence.append(char)
labels.append(self.schema[label])
sentence = "".join(sentenece)
self.sentences.append(sentence)
input_ids = self.encode_sentence(sentenece)
labels = self.padding(labels, -1)
# print(self.decode(sentence, labels))
# input()
self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])
return4.文本编码 / 解码方法
① encode_sentence():
text:需要编码的原始文本输入(单条文本或列表)。
tokenizer.encode():是 Hugging Face Transformers 库中分词器(如 BertTokenizer)的核心方法,用于将 原始文本 转换为模型可处理的 数值化输入
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
text | str 或 List[str] | 必填 | 要编码的文本(单条文本或列表)。 |
text_pair | str 或 List[str] | None | 第二个文本序列(用于句子对任务,如问答、文本相似度)。 |
add_special_tokens | bool | True | 是否添加模型特定的特殊标记(如 [CLS], [SEP])。 |
padding | str 或 bool | False | 填充策略: - "max_length": 填充到 max_length。- "longest": 填充到批次最长序列。- False/"do_not_pad": 不填充。 |
truncation | str 或 bool | False | 截断策略: - True/"longest_first": 截断到 max_length。- "only_first"/"only_second": 截断第一个或第二个句子。 |
max_length | int | 模型最大长度 | 序列的最大长度(包括特殊标记)。 |
return_tensors | str | None | 返回张量格式: - "pt": PyTorch 张量。- "tf": TensorFlow 张量。- "np": NumPy 数组。 |
return_attention_mask | bool | True | 是否返回 attention_mask(标识有效 token 位置)。 |
| 其他参数 | - | - | 如 return_token_type_ids(是否返回 token 类型 ID)、return_overflowing_tokens 等。 |
def encode_sentence(self, text, padding = True):
return self.tokenizer.encode(text,
padding=padding,
max_length=self.config["max_length"],
truncation=True)② decode():
代码运行流程
# `decode()` 方法运行流程
├── 1. **预处理输入**
│ ├── `sentence = "$" + sentence`
│ │ - 在句子开头添加特殊字符 `$`(可能是为了索引对齐或调试)
│ └── `labels = "".join([str(x) for x in labels[:len(sentence) + 2]])`
│ - 将标签列表转换为字符串(如 `[0,4,4]` → `"044"`)
│ - 截断标签到 `len(sentence) + 2` 的长度(可能存在越界风险)
├── 2. **初始化结果容器**
│ └── `results = defaultdict(list)`
│ - 创建默认值为列表的字典,用于存储提取的实体(如 `{"LOCATION": ["上海"]}`)
├── 3. **正则匹配与实体提取**
│ ├── 3.1 **匹配地点(LOCATION)**
│ │ ├── `for location in re.finditer("(04+)", labels):`
│ │ │ - 正则模式 `04+`: 匹配以 `0` 开头、后跟多个 `4` 的标签序列(如 `"044"`)
│ │ ├── `s, e = location.span()`
│ │ │ - 获取匹配子串的起始 (`s`) 和结束 (`e`) 索引
│ │ └── `results["LOCATION"].append(sentence[s:e])`
│ │ - 根据索引从句子中提取文本(如 `sentence[1:3] → "上海"`)
│ │
│ ├── 3.2 **匹配组织(ORGANIZATION)**
│ │ ├── `for location in re.finditer("(15+)", labels):`
│ │ │ - 正则模式 `15+`: 匹配以 `1` 开头、后跟多个 `5` 的标签序列
│ │ └── 其他操作同步骤 3.1
│ │
│ ├── 3.3 **匹配人物(PERSON)**
│ │ ├── `for location in re.finditer("(26+)", labels):`
│ │ │ - 正则模式 `26+`: 匹配以 `2` 开头、后跟多个 `6` 的标签序列
│ │ └── 其他操作同步骤 3.1
│ │
│ └── 3.4 **匹配时间(TIME)**
│ ├── `for location in re.finditer("(37+)", labels):`
│ │ - 正则模式 `37+`: 匹配以 `3` 开头、后跟多个 `7` 的标签序列
│ └── 其他操作同步骤 3.1
└── 4. **返回结果**
└── `return results`
- 返回实体字典(如 `{"LOCATION": ["上海"], "TIME": ["2023年"]}`)sentence:原始句子字符串,函数中在开头添加了 "$",是为了 调整索引对齐(例如避免标签与字符位置错位)。
labels:标签序列(数值类型),转换为字符串形式以便正则匹配。
字符串.join():将可迭代对象(如列表、元组)中的元素用指定字符串连接,生成新字符串。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | 可迭代对象 | 必填 | 需要连接的元素集合。 |
str():将对象转换为字符串表示。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
object | any | 必填 | 需要转换的对象。 |
results:存储提取的实体结果,结构为 {"LOCATION": ["实体1", ...], "ORGANIZATION": [...]}
defaultdict():创建一个默认值字典,当访问不存在的键时,返回指定类型的默认值。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
default_factory | 类型/函数 | 必填 | 生成默认值的工厂函数(如 list, int)。 |
**kwargs | 关键字参数 | 可选 | 初始化的键值对(如 a=1)。 |
location:正则匹配结果对象,包含匹配到的子串位置信息(通过 .span() 获取)
字符串.span():Python 中 re.Match 对象的方法,用于返回正则表达式匹配的子串在原始字符串中的 起始和结束位置索引。返回值为元组 (start, end),其中:
start:匹配子串的起始索引(包含)。
end:匹配子串的结束索引(不包含)。
re.finditer():在字符串中查找所有匹配正则表达式的子串,返回迭代器(包含所有匹配对象)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pattern | str | 必填 | 正则表达式模式。 |
string | str | 必填 | 要搜索的字符串。 |
flags | int | 0 | 正则匹配标志(如 re.IGNORECASE)。 |
s(start):匹配到的标签子串在 labels 字符串中的 起始索引(包含该位置)
e(end):匹配到的标签子串在 labels 字符串中的 结束索引(不包含该位置)。
列表.append():向列表末尾添加一个元素。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
object | any | 必填 | 要添加到列表的元素。 |
def decode(self, sentence, labels):
sentence = "$" + sentence
labels = "".join([str(x) for x in labels[:len(sentence) + 2]])
results = defaultdict(list)
for location in re.finditer("(04+)", labels):
s, e = location.span()
print("location", s, e)
results["LOCATION"].append(sentence[s:e])
for location in re.finditer("(15+)", labels):
s, e = location.span()
print("org", s, e)
results["ORGANIZATION"].append(sentence[s:e])
for location in re.finditer("(26+)", labels):
s, e = location.span()
print("per", s, e)
results["PERSON"].append(sentence[s:e])
for location in re.finditer("(37+)", labels):
s, e = location.span()
print("time", s, e)
results["TIME"].append(sentence[s:e])
return results③ padding():
代码运行流程
# `padding` 方法运行流程
├── 1. **输入参数**
│ ├── `input_id`: 待处理的原始序列(如 `[token1, token2, ...]`)。
│ └── `pad_token`: 填充符(默认值 `0`,通常对应 `[PAD]`)。
├── 2. **截断序列**
│ ├── **条件判断**: 若 `len(input_id) > max_length`
│ │ └── 截取前 `max_length` 个元素:`input_id = input_id[:max_length]`。
│ └── **否则**(长度 ≤ `max_length`):
│ └── 保留原序列。
├── 3. **填充序列**
│ ├── **计算填充长度**: `pad_length = max_length - len(input_id)`。
│ ├── **条件判断**: 若 `pad_length > 0`
│ │ └── 追加 `pad_length` 个填充符:`input_id += [pad_token] * pad_length`。
│ └── **否则**(`pad_length ≤ 0`):
│ └── 无需填充。
└── 4. **返回结果**
└── 返回统一长度(`max_length`)的序列:`return input_id`。input_id:待处理的原始输入序列(通常是 token ID 列表)
pad_token:填充符的 token ID,用于在序列末尾填充。
config["max_length"]:预定义的序列最大长度,所有输入序列将被统一调整至此长度。
# 补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id, pad_token=0):
input_id = input_id[:self.config["max_length"]]
input_id += [pad_token] * (self.config["max_length"] - len(input_id))
return input_id5.类内魔术方法
__len__():返回数据长度
__getitem()__:根据索引返回元素
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]6.加载映射关系文件
path:任务中实体类别或标签的配置文件路径(通常是 JSON 文件)
f:文件对象
open():打开文件并返回文件对象,用于读写文件内容。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
file | str | 必填 | 文件路径(如 "data/schema.json")。 |
mode | str | "r" | 文件模式(如 "r"、"w"、"a"、"rb" 等)。 |
encoding | str | 系统默认 | 文本编码格式(如 "utf-8")。 |
errors | str | None | 编解码错误处理策略(如 "ignore"、"strict")。 |
newline | str | None | 换行符控制(如 "\n")。 |
json.load():从文件对象中解析 JSON 数据,返回对应的 Python 数据结构(如字典、列表)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
fp | 文件对象 | 必填 | 已打开的文件对象(需以读模式打开)。 |
object_hook | function | None | 自定义函数,用于处理解码后的字典对象(高级用法)。 |
parse_float | function | float | 自定义函数,用于解析 JSON 中的浮点数(如 decimal.Decimal)。 |
parse_int | function | int | 自定义函数,用于解析 JSON 中的整数(如 str 保留原始格式)。 |
encoding | str | "utf-8" | 文件编码(仅 Python 3 之前版本需要显式指定)。 |
def load_schema(self, path):
with open(path, encoding="utf8") as f:
return json.load(f)7.加载词表
vocab_path:词汇表文件路径,包含模型或分词器使用的 所有词汇或子词单元列表,用于将文本转换为数值化的 token ID。
BertTokenizer.from_pretrained():加载分词器配置:根据 vocab_path 自动读取分词器配置(如词汇表、特殊标记、分词规则等)。
| 参数名 | 类型 | 默认值 | 作用 |
|---|---|---|---|
pretrained_model_name_or_path | str 或 os.PathLike | 必填 | 核心参数: - 预训练模型名称(如 "bert-base-chinese")。- 本地目录路径(需包含 vocab.txt 和 tokenizer_config.json)。 |
use_fast | bool | True | 是否使用 快速分词器(Rust 实现,性能更优)。 (若 False,则使用 Python 实现的分词器)。 |
cache_dir | str | None | 指定模型文件的缓存目录(覆盖默认的 ~/.cache/huggingface)。 |
force_download | bool | False | 是否强制重新下载模型文件(即使本地缓存已存在)。 |
local_files_only | bool | False | 是否仅使用本地文件(不联网下载)。 (适用于离线环境或已有缓存文件)。 |
revision | str | "main" | 指定模型版本: - Git 分支名(如 "dev")。- 标签名(如 "v1.0")。- 提交哈希(如 "123abc")。 |
subfolder | str | "" | 若分词器文件存储在模型目录的子文件夹中,需指定子文件夹名。 |
proxies | Dict[str, str] | None | 设置代理服务器(格式:{"http": "http://proxy:port", "https": "https://proxy:port"})。 |
trust_remote_code | bool | False | 是否信任远程代码(当加载自定义分词器时,需设置为 True)。(注意:存在安全风险,需谨慎使用)。 |
mirror | str | None | 指定镜像源地址(如 "https://mirror.example.com")。(用于网络受限环境)。 |
def load_vocab(vocab_path):
return BertTokenizer.from_pretrained(vocab_path)8.数据加载器封装
data_path:数据文件或目录的路径,指向包含训练/验证数据的存储位置。
config:配置字典,包含数据加载、模型训练等参数。
shuffle:是否在每个 epoch 开始时打乱数据顺序。
- 训练阶段:设为
True,避免模型记忆数据顺序,提升泛化能力。 - 验证/测试阶段:设为
False,确保结果可复现。
dg:DataGenerator 类的实例,负责 数据加载与预处理
dl:DataLoader 类的实例,负责 批量数据生成与加载。
DataLoader():将自定义数据集(如 Dataset 或 DataGenerator)封装为 可迭代的批量数据加载器
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
dataset | Dataset | 必填 | 数据集对象(需实现 __len__ 和 __getitem__ 方法)。 |
batch_size | int | 1 | 每个批次的样本数量。 |
shuffle | bool | False | 是否在每个 epoch 开始时打乱数据顺序(推荐训练时设为 True)。 |
num_workers | int | 0 | 数据加载的子进程数(建议设置为 CPU 核心数,如 4)。 |
drop_last | bool | False | 是否丢弃最后一个不完整的批次(当总样本数无法被 batch_size 整除时)。 |
pin_memory | bool | False | 是否将数据复制到 CUDA 固定内存(提升 GPU 传输效率)。 |
collate_fn | Callable | None | 自定义批次处理函数(用于处理不同长度的序列,如填充对齐)。 |
sampler | Sampler | None | 自定义采样策略(覆盖 shuffle 参数)。 |
batch_sampler | Sampler | None | 自定义批次采样策略(覆盖 batch_size 和 drop_last)。 |
timeout | int | 0 | 数据加载的超时时间(秒,0 表示无限等待)。 |
# 用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
9.数据加载文件测试
dg:自定义数据集对象,负责 加载和预处理数据。
dl:数据加载器,将 dg 中的数据集 分批次加载,支持迭代访问。
x:输入特征(如 BERT 的 input_ids 和 attention_mask),形状为 (batch_size, sequence_length)。
y:标签(如序列标注的标签索引),形状与 x 相同或为 (batch_size,)(分类任务)
.shape:PyTorch 张量的属性,返回张量的维度信息。
if __name__ == "__main__":
from config import Config
dg = DataGenerator("ner_data/train", Config)
dl = DataLoader(dg, batch_size=32)
for x, y in dl:
print(x.shape, y.shape)
print(x[1], y[1])
input()10.完整代码
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from transformers import BertTokenizer
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.tokenizer = load_vocab(config["bert_path"])
self.sentences = []
self.schema = self.load_schema(config["schema_path"])
self.load()
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
segments = f.read().split("\n\n")
for segment in segments:
sentenece = []
labels = [8] # cls_token
for line in segment.split("\n"):
if line.strip() == "":
continue
char, label = line.split()
sentenece.append(char)
labels.append(self.schema[label])
sentence = "".join(sentenece)
self.sentences.append(sentence)
input_ids = self.encode_sentence(sentenece)
labels = self.padding(labels, -1)
# print(self.decode(sentence, labels))
# input()
self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])
return
def encode_sentence(self, text, padding=True):
return self.tokenizer.encode(text,
padding="max_length",
max_length=self.config["max_length"],
truncation=True)
def decode(self, sentence, labels):
sentence = "$" + sentence
labels = "".join([str(x) for x in labels[:len(sentence) + 2]])
results = defaultdict(list)
for location in re.finditer("(04+)", labels):
s, e = location.span()
print("location", s, e)
results["LOCATION"].append(sentence[s:e])
for location in re.finditer("(15+)", labels):
s, e = location.span()
print("org", s, e)
results["ORGANIZATION"].append(sentence[s:e])
for location in re.finditer("(26+)", labels):
s, e = location.span()
print("per", s, e)
results["PERSON"].append(sentence[s:e])
for location in re.finditer("(37+)", labels):
s, e = location.span()
print("time", s, e)
results["TIME"].append(sentence[s:e])
return results
# 补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id, pad_token=0):
input_id = input_id[:self.config["max_length"]]
input_id += [pad_token] * (self.config["max_length"] - len(input_id))
return input_id
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
def load_schema(self, path):
with open(path, encoding="utf8") as f:
return json.load(f)
def load_vocab(vocab_path):
return BertTokenizer.from_pretrained(vocab_path)
# 用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
if __name__ == "__main__":
from config import Config
dg = DataGenerator("ner_data/train", Config)
dl = DataLoader(dg, batch_size=32)
for x, y in dl:
print(x.shape, y.shape)
print(x[1], y[1])
input()四、模型文件 model.py
1.导入文件
torch:导入 PyTorch 核心库,提供张量计算、自动求导等深度学习基础功能。
torch.nn:导入 PyTorch 的神经网络模块,包含常用的网络层、损失函数等。
torch.optim:导入优化器,用于更新模型参数以最小化损失函数。
CRF:导入条件随机场(CRF)模块,用于 序列标注任务(如 NER)
BertModel:导入 Hugging Face Transformers 库中的预训练 BERT 模型。
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torchcrf import CRF
from transformers import BertModel2.将字典配置包装为对象
config:字典 (dict) ,存储模型或应用的配置参数(如超参数、路径设置等)
class ConfigWrapper(object):
def __init__(self, config):
self.config = config
def to_dict(self):
return self.config3.模型初始化
nn.Module:PyTorch 所有神经网络的基类,提供参数管理、GPU 迁移等功能。
self.config:字典,模型配置信息
ConfigWrapper():将字典配置包装为对象
max_length:输入序列的最大长度(如 512),用于填充或截断
class_num:分类类别数(如 NER 任务中的实体类型数
self.bert:加载预训练的 BERT 模型,将文本编码为上下文相关的向量表示。
bert_path:预训练 BERT 模型的路径或名称
self.classify:nn.Linear 全连接层,将 BERT 输出的隐藏状态映射到标签空间
BertModel.from_pretrained():加载预训练的 BERT 模型,生成文本的上下文相关向量表示。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pretrained_model_name_or_path | str 或 os.PathLike | 必填 | 预训练模型名称(如 "bert-base-chinese")或本地路径。 |
config | PretrainedConfig | None | 自定义模型配置(若未提供,自动加载默认配置)。 |
output_hidden_states | bool | None | 是否返回所有隐藏层的输出。 |
return_dict | bool | True | 是否以字典形式返回输出(代码中设为 False,返回元组)。 |
self.crf_layer:CRF 条件随机场层。
nn.Linear():定义全连接层,执行线性变换 y = xA^T + b,将输入数据映射到标签空间。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
in_features | int | 必填 | 输入特征维度(如 BERT 隐藏层维度 768)。 |
out_features | int | 必填 | 输出特征维度(即分类类别数 class_num)。 |
bias | bool | True | 是否包含偏置项 b。 |
CRF():条件随机场层,用于优化序列标注任务中的标签转移概率,提升标签序列的合理性。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
num_tags | int | 必填 | 标签类别数(与 class_num 一致)。 |
batch_first | bool | False | 输入张量是否以 (batch_size, seq_len, ...) 格式组织。 |
transitions | Tensor | None | 自定义的初始转移矩阵(若未提供,随机初始化)。 |
self.use_crf:控制模型是否使用 CRF 层。
self.loss:计算模型输出与真实标签之间的损失
torch.nn.CrossEntropyLoss():计算交叉熵损失,用于衡量模型输出与真实标签的差异。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
ignore_index | int | -100 | 忽略的标签索引(代码中设为 -1,对应填充部分)。 |
reduction | str | "mean" | 损失计算方式:"none"、"mean"(默认)、"sum"。 |
class TorchModel(nn.Module):
def __init__(self, config):
super(TorchModel, self).__init__()
self.config = ConfigWrapper(config)
max_length = config["max_length"]
class_num = config["class_num"]
# self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
# self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=num_layers)
self.bert = BertModel.from_pretrained(config["bert_path"], return_dict=False)
self.classify = nn.Linear(self.bert.config.hidden_size, class_num)
self.crf_layer = CRF(class_num, batch_first=True)
self.use_crf = config["use_crf"]
self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) # loss采用交叉熵损失4.前向计算
代码运行流程
# forward() 方法流程
├── 1. **输入处理**
│ ├→ `x`: 输入张量(如 token IDs,形状 `(batch_size, seq_len)`)
│ └→ `target`: 真实标签(可选,形状 `(batch_size, seq_len)` 或 `(batch_size,)`)
├── 2. **BERT 编码**
│ └→ `x, _ = self.bert(x)`
│ - `x`: BERT 输出的最后一层隐藏状态(形状 `(batch_size, seq_len, hidden_size)`)
│ - `_`: 忽略的池化输出(通常用于分类任务)。
├── 3. **分类层映射**
│ └→ `predict = self.classify(x)`
│ - `predict`: 模型输出的 logits(形状 `(batch_size, seq_len, num_tags)`)
├── 4. **分支条件:是否存在真实标签 (target)**
│ │
│ ├── 4.1 **存在真实标签 (训练阶段)**
│ │ │
│ │ ├── 4.1.1 **是否使用 CRF**
│ │ │ ├→ **是**:
│ │ │ │ ├→ `mask = target.gt(-1)`
│ │ │ │ │ - `mask`: 有效标签掩码(形状 `(batch_size, seq_len)`,`True` 表示非填充位置)
│ │ │ │ └→ `return -self.crf_layer(predict, target, mask, reduction="mean")`
│ │ │ │ - 计算 CRF 的负对数似然损失(标量)。
│ │ │ └→ **否**:
│ │ │ └→ `return self.loss(predict.view(-1, num_tags), target.view(-1))`
│ │ │ - 使用交叉熵损失(展平后的 logits 和标签)。
│ │ └── 4.1.2 **结束分支**
│ │
│ └── 4.2 **无真实标签 (预测阶段)**
│ │
│ ├── 4.2.1 **是否使用 CRF**
│ │ ├→ **是**:
│ │ │ └→ `return self.crf_layer.decode(predict)`
│ │ │ - 返回 Viterbi 解码后的标签序列(形状 `(batch_size, seq_len)`)。
│ │ └→ **否**:
│ │ └→ `return predict`
│ │ - 直接返回 logits(形状 `(batch_size, seq_len, num_tags)`)。
│ └── 4.2.2 **结束分支**
└── 5. **返回结果**
├→ **训练模式**: 返回损失值(标量)。
└→ **预测模式**: 返回预测标签或 logits。x:输入张量,表示分词后的 token IDs,形状 (batch_size, sequence_length)
target:真实标签,训练时提供,预测时为 None。
predict:模型输出的 logits,形状由任务类型决定。
self.bert():预训练的 BERT 模型,用于文本编码。
x:BERT 的最后一层隐藏状态,形状为 (batch_size, sequence_length, hidden_size)(如 (32, 128, 768))。
_:忽略的池化输出(通常用于分类任务,此处未使用)。
self.classify():线性层(nn.Linear),将 BERT 输出映射到标签空间。
self.use_crf:控制是否使用 CRF 层优化输出序列。
mask:有效标签掩码(仅 CRF 使用),过滤填充位置。
.gt():比较张量中的元素是否大于给定值,返回布尔类型掩码。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
other | Tensor 或标量 | 是 | 无 | 比较的阈值或相同形状的张量。 |
self.crf_layer():CRF 层,计算负对数似然损失。
self.loss():计算交叉熵损失(非 CRF 模式)。
view():调整张量的形状(类似 reshape),不改变数据内容。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
*shape | 可变参数(整数) | 是 | 无 | 目标形状的维度值(如 2,3)。 |
shape():返回张量的维度形状(元组形式)。
self.crf_layer[CRF()].decode():使用Viterbi维特比算法解码最优标签序列,返回最优标签序列。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
emissions | Tensor | 是 | 无 | 模型的发射分数(logits)。 |
mask | BoolTensor 或 None | 否 | None | 有效位置掩码(None 表示全有效)。 |
# 当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, target=None):
# x = self.embedding(x) #input shape:(batch_size, sen_len)
# x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)
x, _ = self.bert(x)
predict = self.classify(x) # ouput:(batch_size, sen_len, num_tags) -> (batch_size * sen_len, num_tags)
if target is not None:
if self.use_crf:
mask = target.gt(-1)
return - self.crf_layer(predict, target, mask, reduction="mean")
else:
# (number, class_num), (number)
return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))
else:
if self.use_crf:
return self.crf_layer.decode(predict)
else:
return predict5.选择优化器
config:存储模型训练的超参数配置信息
model:PyTorch 模型实例,待训练的神经网络模型,包含所有可训练参数(权重和偏置)。
optimizer:字符串,指定优化器类型,决定如何更新模型参数以最小化损失函数。
learning_rate:浮点数,定义优化器的学习率,控制优化器在参数更新时的步长大小,直接影响模型收敛速度和稳定性。
Adam():自适应学习率优化器,适用于大多数深度学习任务。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
params | iterable | 必填 | 模型的参数集合(通常来自 model.parameters())。 |
lr | float | 1e-3 | 学习率(控制参数更新步长)。 |
betas | Tuple[float, float] | (0.9, 0.999) | 用于计算梯度一阶矩和二阶矩的衰减系数(动量项)。 |
eps | float | 1e-8 | 数值稳定性项,防止除以零。 |
weight_decay | float | 0 | L2 正则化系数(用于防止过拟合)。 |
amsgrad | bool | False | 是否使用 AMSGrad 变体(改进数值稳定性)。 |
SGD():随机梯度下降优化器,需手动调整学习率和动量参数。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
params | iterable | 必填 | 模型的参数集合(通常来自 model.parameters())。 |
lr | float | 必填 | 学习率(控制参数更新步长)。 |
momentum | float | 0 | 动量因子(加速梯度下降过程)。 |
dampening | float | 0 | 动量抑制因子(防止动量过大)。 |
weight_decay | float | 0 | L2 正则化系数(用于防止过拟合)。 |
nesterov | bool | False | 是否使用 Nesterov 动量(改进梯度方向计算)。 |
model.parameters():返回模型的所有可训练参数(torch.nn.Parameter 对象)
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)6.模型文件测试
if __name__ == "__main__":
from config import Config
model = TorchModel(Config)7.完整代码
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torchcrf import CRF
from transformers import BertModel
"""
建立网络模型结构
"""
class ConfigWrapper(object):
def __init__(self, config):
self.config = config
def to_dict(self):
return self.config
class TorchModel(nn.Module):
def __init__(self, config):
super(TorchModel, self).__init__()
self.config = ConfigWrapper(config)
max_length = config["max_length"]
class_num = config["class_num"]
# self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
# self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=num_layers)
self.bert = BertModel.from_pretrained(config["bert_path"], return_dict=False)
self.classify = nn.Linear(self.bert.config.hidden_size, class_num)
self.crf_layer = CRF(class_num, batch_first=True)
self.use_crf = config["use_crf"]
self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) # loss采用交叉熵损失
# 当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, target=None):
# x = self.embedding(x) #input shape:(batch_size, sen_len)
# x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)
x, _ = self.bert(x)
predict = self.classify(x) # ouput:(batch_size, sen_len, num_tags) -> (batch_size * sen_len, num_tags)
if target is not None:
if self.use_crf:
mask = target.gt(-1)
return - self.crf_layer(predict, target, mask, reduction="mean")
else:
# (number, class_num), (number)
return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))
else:
if self.use_crf:
return self.crf_layer.decode(predict)
else:
return predict
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)
if __name__ == "__main__":
from config import Config
model = TorchModel(Config)五、模型评估文件 evaluate.py
1.类初始化
config:提供评估所需的路径和超参数。
model:执行预测任务的核心模型。
logger:记录评估过程的关键指标。
self.valid_data:调用 load_data 加载验证集数据,结果存储在 self.valid_data 中
load_data():负责验证集数据的标准化加载与预处理
config:配置信息,用于控制数据加载的细节。
shuffle:是否打乱数据顺序(验证集通常设为 False 以保证结果可复现)。
config["valid_data_path"]:验证集数据文件或目录路径
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)2.评估模型方法
代码运行流程
# `eval()` 方法运行流程
├── 1. **初始化评估状态**
│ ├── `self.logger.info("开始测试第%d轮模型效果:" % epoch)`
│ │ - 记录日志:开始第 `epoch` 轮的模型评估。
│ └── `self.stats_dict = {实体类型: defaultdict(int)}`
│ - 初始化统计字典,记录每个实体类别的 TP/FP/FN(后续由 `write_stats` 填充)。
├── 2. **设置模型为评估模式**
│ └── `self.model.eval()`
│ - 关闭 dropout 和 batch normalization 的随机性。
├── 3. **遍历验证数据批次**
│ │
│ ├── 3.1 **获取当前批次的原始句子**
│ │ └── `sentences = self.valid_data.dataset.sentences[...]`
│ │ - 从数据集中提取当前批次对应的原始文本(用于后续结果分析)。
│ │
│ ├── 3.2 **数据迁移至 GPU(如果可用)**
│ │ └── `batch_data = [d.cuda() for d in batch_data]`
│ │ - 将输入数据移至 GPU 加速计算。
│ │
│ ├── 3.3 **解析输入和标签**
│ │ └── `input_id, labels = batch_data`
│ │ - 分离输入(`input_id`)和真实标签(`labels`)。
│ │
│ ├── 3.4 **禁用梯度计算**
│ │ └── `with torch.no_grad():`
│ │ - 关闭梯度计算,减少内存占用。
│ │
│ ├── 3.5 **模型预测**
│ │ └── `pred_results = self.model(input_id)`
│ │ - 使用模型对输入进行预测(不计算损失,仅前向传播)。
│ │
│ └── 3.6 **统计预测结果**
│ └── `self.write_stats(labels, pred_results, sentences)`
│ - 对比预测结果和真实标签,更新 `stats_dict`(如统计 TP/FP/FN)。
├── 4. **输出评估结果**
│ └── `self.show_stats()`
│ - 计算并打印精确率、召回率、F1 值等指标。
└── 5. **返回**
└── `return`
- 结束评估,可能返回统计结果(代码中未显式返回)。epoch:当前评估的轮次(整数),用于日志记录(如“第5轮模型效果”)
logger.info():记录信息级别的日志,用于输出程序运行状态或调试信息
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的变量参数。 |
**kwargs | dict | {} | 关键字参数(如 exc_info)。 |
self.stats_dict:按实体类别(如 LOCATION)存储统计信息的字典,每个类别对应一个 defaultdict(int),用于统计 TP(True Positive)、FP(False Positive)、FN(False Negative)
defaultdict():创建带有默认值的字典,当访问不存在的键时返回默认值(由工厂函数指定)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
default_factory | Callable | 必填 | 生成默认值的工厂函数(如 int、list)。 |
model.eval():将 PyTorch 模型设置为评估模式(关闭 Dropout 和 Batch Normalization 的随机性)
index:当前批次的索引(整数)
batch_data:当前批次的输入数据和标签,格式由 DataLoader 的 collate_fn 决定(通常为 (input_ids, labels))。
enumerate():遍历可迭代对象(如列表、DataLoader),返回索引和元素的组合。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | Iterable | 必填 | 可迭代对象(如列表、DataLoader)。 |
start | int | 0 | 索引的起始值。 |
self.valid_data:调用 load_data 加载验证集数据,结果存储在 self.valid_data 中
sentences:当前批次对应的原始文本列表(用于调试或结果分析)
torch.cuda.is_available():检查当前系统是否支持 CUDA(即 GPU 加速是否可用)。
cuda():将张量或模型迁移到 GPU 上以加速计算。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
device | int 或 torch.device | None | 目标 GPU 设备号(如 0)。若未指定,使用当前设备。 |
input_id:模型的输入张量,形状为 (batch_size, sequence_length),表示分词后的 token IDs
labels:真实标签张量,形状与 input_id 相同,每个位置为类别索引。
torch.no_grad():上下文管理器,禁用梯度计算以节省内存和计算资源。
pred_results:模型的预测输出
self.wite_stats:自定义方法,对比 labels 和 pred_results,更新 self.stats_dict 中的 TP/FP/FN。
self.show_stats():自定义方法,基于 self.stats_dict 计算并打印评估指标(如精确率、召回率、F1 值)。
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.stats_dict = {"LOCATION": defaultdict(int),
"TIME": defaultdict(int),
"PERSON": defaultdict(int),
"ORGANIZATION": defaultdict(int)}
self.model.eval()
for index, batch_data in enumerate(self.valid_data):
sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_id) #不输入labels,使用模型当前参数进行预测
self.write_stats(labels, pred_results, sentences)
self.show_stats()
return3.统计写入
代码运行流程
# write_stats() 方法运行流程
├── 1. 输入验证
│ └→ `assert len(labels) == len(pred_results) == len(sentences)`
│ - 确保输入数据一致性(样本数相同)
├── 2. 处理预测结果(条件分支)
│ ├── **条件**: `if not self.config["use_crf"]`
│ │ └→ `pred_results = torch.argmax(pred_results, dim=-1)`
│ │ - 将 logits 转换为预测标签索引(非 CRF 模型)
│ └── **否则**(使用 CRF):
│ └→ 直接使用 CRF 解码后的标签序列
├── 3. 遍历每个样本
│ │
│ ├── 3.1 转换预测标签(非 CRF 情况)
│ │ ├── **条件**: `if not self.config["use_crf"]`
│ │ │ └→ `pred_label = pred_label.cpu().detach().tolist()`
│ │ │ - 将 GPU 张量 → CPU 列表(如 `[0, 1, 2]`)
│ │ └→ `true_label = true_label.cpu().detach().tolist()`
│ │ - 真实标签同样转换为列表
│ │
│ ├── 3.2 解码实体
│ │ ├→ `true_entities = self.decode(sentence, true_label)`
│ │ │ - 解码真实标签,得到实体字典(如 `{"LOCATION": [(0, 2)]}`)
│ │ └→ `pred_entities = self.decode(sentence, pred_label)`
│ │ - 解码预测标签,得到预测的实体字典
│ │
│ └── 3.3 统计指标
│ └→ **遍历每个实体类型**:
│ ├→ `self.stats_dict[key]["正确识别"] += ...`
│ ├→ `self.stats_dict[key]["样本实体数"] += ...`
│ └→ `self.stats_dict[key]["识别出实体数"] += ...`
└── 4. 返回
└→ `return`
- 更新后的统计字典将用于计算精确率、召回率labels:真实标签张量,形状为 (batch_size, sequence_length),每个元素为类别索引。
pred_results:模型预测输出(CRF 解码后的标签或 logits)。
未使用 CRF:形状为 (batch_size, sequence_length, class_num) 的 logits。
使用 CRF:形状为 (batch_size, sequence_length) 的预测标签索引。
sentences:原始文本列表(长度为 batch_size),用于实体解码时的上下文参考。
assert:断言条件为真,否则抛出 AssertionError,用于调试时验证程序逻辑。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
condition | 布尔表达式 | 必填 | 断言条件,若为 False 触发异常。 |
message | str | "" | 可选错误消息(如 assert x > 0, "x必须大于0")。 |
config["use_crf"]:配置项,控制是否使用 CRF 层(影响预测结果处理方式)。
torch.argmax():返回张量中最大值所在的索引,用于将模型输出的 logits 转换为预测标签。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input | torch.Tensor | 必填 | 输入张量(如模型输出的 logits)。 |
dim | int | 必填 | 沿指定维度取最大值索引(如 dim=-1 表示最后一个维度)。 |
keepdim | bool | False | 是否保持输出张量的维度(如保持 (batch_size, 1) 而非 (batch_size,))。 |
pred_lable:单个样本的预测标签列表(格式同 true_label)。
true_label:单个样本的真实标签列表(如 [0, 1, 2, 0])
cpu():将张量从 GPU 迁移到 CPU,便于后续处理(如转换为列表)。
detach():从计算图中分离张量,阻断梯度传播,通常用于评估阶段。
tolist():将张量(Tensor)转换为 Python 列表(List),便于序列化或非张量操作。
true_entities:真实实体字典,键为实体类型,值为实体位置列表(如 [(0, 2)])。
self.decode():自定义方法,将标签序列解码为实体字典(输入:文本和标签列表)。
pred_entities:预测实体字典,结构同 true_entities。
self.state_dict:统计字典,按实体类型存储 正确识别、样本实体数、识别出实体数。
ent:代表预测的单个实体,通常以 实体位置范围(起始索引,结束索引) 的形式存在。
def write_stats(self, labels, pred_results, sentences):
assert len(labels) == len(pred_results) == len(sentences)
if not self.config["use_crf"]:
pred_results = torch.argmax(pred_results, dim=-1)
for true_label, pred_label, sentence in zip(labels, pred_results, sentences):
if not self.config["use_crf"]:
pred_label = pred_label.cpu().detach().tolist()
true_label = true_label.cpu().detach().tolist()
true_entities = self.decode(sentence, true_label)
pred_entities = self.decode(sentence, pred_label)
# 正确率 = 识别出的正确实体数 / 识别出的实体数
# 召回率 = 识别出的正确实体数 / 样本的实体数
for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:
self.stats_dict[key]["正确识别"] += len([ent for ent in pred_entities[key] if ent in true_entities[key]])
self.stats_dict[key]["样本实体数"] += len(true_entities[key])
self.stats_dict[key]["识别出实体数"] += len(pred_entities[key])
return4.统计结果展示
代码运行流程
# show_stats() 方法运行流程
├── 1. 初始化 Macro-F1 存储列表
│ └→ F1_scores = []
├── 2. 遍历每个实体类型
│ │
│ ├── 2.1 计算精确率(Precision)
│ │ └→ precision = 正确识别数 / (识别出实体数 + 1e-5)
│ │
│ ├── 2.2 计算召回率(Recall)
│ │ └→ recall = 正确识别数 / (样本实体数 + 1e-5)
│ │
│ ├── 2.3 计算 F1 值
│ │ └→ F1 = 2 * (precision * recall) / (precision + recall + 1e-5)
│ │
│ ├── 2.4 记录日志(实体级别的指标)
│ │ └→ self.logger.info("%s类实体,准确率:%f, 召回率: %f, F1: %f" % ...)
│ │
│ └── 2.5 存储 F1 值
│ └→ F1_scores.append(F1)
├── 3. 计算并记录 Macro-F1
│ └→ self.logger.info("Macro-F1: %f" % np.mean(F1_scores))
├── 4. 计算 Micro-F1
│ │
│ ├── 4.1 汇总全局统计量
│ │ ├→ correct_pred = sum(所有实体的正确识别数)
│ │ ├→ total_pred = sum(所有实体的识别出实体数)
│ │ └→ true_enti = sum(所有实体的样本实体数)
│ │
│ ├── 4.2 计算 Micro-Precision 和 Micro-Recall
│ │ ├→ micro_precision = correct_pred / (total_pred + 1e-5)
│ │ └→ micro_recall = correct_pred / (true_enti + 1e-5)
│ │
│ ├── 4.3 计算 Micro-F1
│ │ └→ micro_f1 = 2 * (micro_precision * micro_recall) / (...)
│ │
│ └── 4.4 记录日志(Micro-F1)
│ └→ self.logger.info("Micro-F1 %f" % micro_f1)
└── 5. 结束
├→ self.logger.info("--------------------")
└→ returnF1_scores:存储每个实体类型的 F1 值,用于计算 Macro-F1。
key:代表当前遍历的实体类别名称,用于逐个处理模型在验证集上需要统计的实体类型。
precision:精确率:正确识别数 / 预测实体总数(TP / (TP + FP))
self.stats_dict:统计字典,存储每个实体类型的 正确识别、样本实体数、识别出实体数。
recall:召回率:正确识别数 / 真实实体总数(TP / (TP + FN))
F1:F1 值:精确率和召回率的调和平均值。
self.logger:日志记录器,用于输出评估结果。
logger.info():记录信息级别的日志,输出程序运行状态或评估结果。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串,如 "准确率:%f" % 0.85)。 |
*args | tuple | () | 格式化字符串的变量参数(如 %f 对应的浮点数)。 |
**kwargs | dict | {} | 关键字参数(如 exc_info=True 记录异常信息)。 |
correct_pred:所有实体类型的 总正确识别数(Micro-F1 的分子)。
sum():计算可迭代对象(如列表、生成器)中所有元素的和。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | Iterable | 必填 | 可迭代对象(如 [1, 2, 3] 或生成器表达式)。 |
start | int/float | 0 | 起始累加值(如 sum([1, 2], start=10) 结果为 13)。 |
total_pred:所有实体类型的 总预测实体数(Micro-Precision 的分母)。
true_enti:所有实体类型的 总真实实体数(Micro-Recall 的分母)。
micro_precision:全局正确识别数 / 全局预测实体数。
micro_recall:全局正确识别数 / 全局真实实体数。
micro_f1:全局精确率和召回率的调和平均值。
def show_stats(self):
F1_scores = []
for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:
# 正确率 = 识别出的正确实体数 / 识别出的实体数
# 召回率 = 识别出的正确实体数 / 样本的实体数
precision = self.stats_dict[key]["正确识别"] / (1e-5 + self.stats_dict[key]["识别出实体数"])
recall = self.stats_dict[key]["正确识别"] / (1e-5 + self.stats_dict[key]["样本实体数"])
F1 = (2 * precision * recall) / (precision + recall + 1e-5)
F1_scores.append(F1)
self.logger.info("%s类实体,准确率:%f, 召回率: %f, F1: %f" % (key, precision, recall, F1))
self.logger.info("Macro-F1: %f" % np.mean(F1_scores))
correct_pred = sum([self.stats_dict[key]["正确识别"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
total_pred = sum([self.stats_dict[key]["识别出实体数"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
true_enti = sum([self.stats_dict[key]["样本实体数"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
micro_precision = correct_pred / (total_pred + 1e-5)
micro_recall = correct_pred / (true_enti + 1e-5)
micro_f1 = (2 * micro_precision * micro_recall) / (micro_precision + micro_recall + 1e-5)
self.logger.info("Micro-F1 %f" % micro_f1)
self.logger.info("--------------------")
return5.解码
分组类别规定
{
"B-LOCATION": 0,
"B-ORGANIZATION": 1,
"B-PERSON": 2,
"B-TIME": 3,
"I-LOCATION": 4,
"I-ORGANIZATION": 5,
"I-PERSON": 6,
"I-TIME": 7,
"O": 8
}代码运行流程
# decode() 方法运行流程
├── 1. 预处理输入
│ ├→ `sentence = "$" + sentence`
│ │ - 在句子开头添加 `$` 符号(可能是为了对齐索引)。
│ └→ `labels = "".join([str(x) for x in labels[:len(sentence)+1]])`
│ - 将标签列表转换为字符串(如 `[0,4,4]` → `"044"`),并截断至 `len(sentence)+1` 长度。
├── 2. 初始化结果字典
│ └→ `results = defaultdict(list)`
├── 3. 正则匹配实体标签序列
│ │
│ ├── 3.1 匹配 LOCATION 实体
│ │ └→ `for location in re.finditer("(04+)", labels):`
│ │ - 正则模式 `04+`:匹配以 `0`(B-LOCATION)开头,后跟多个 `4`(I-LOCATION)的序列。
│ │
│ ├── 3.2 匹配 ORGANIZATION 实体
│ │ └→ `for location in re.finditer("(15+)", labels):`
│ │ - 正则模式 `15+`:匹配以 `1`(B-ORGANIZATION)开头,后跟多个 `5`(I-ORGANIZATION)的序列。
│ │
│ ├── 3.3 匹配 PERSON 实体
│ │ └→ `for location in re.finditer("(26+)", labels):`
│ │ - 正则模式 `26+`:匹配以 `2`(B-PERSON)开头,后跟多个 `6`(I-PERSON)的序列。
│ │
│ └── 3.4 匹配 TIME 实体
│ └→ `for location in re.finditer("(37+)", labels):`
│ - 正则模式 `37+`:匹配以 `3`(B-TIME)开头,后跟多个 `7`(I-TIME)的序列。
├── 4. 提取实体文本
│ └→ 对每个匹配的实体位置 `(s, e)`:
│ - `results[实体类型].append(sentence[s:e])`
│ - 从预处理后的句子中提取子串(如 `sentence[1:3]` 对应原句子的 `0:2`)。
└── 5. 返回结果
└→ `return results`sentence:原始文本句子
labels:标签序列(每个元素为索引值,对应 BIO 标签,如 0 表示 B-LOCATION)。
字符串.join():将可迭代对象(如列表、元组)中的元素用指定字符串连接,生成一个新的字符串。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | Iterable | 必填 | 包含字符串元素的可迭代对象(如列表 ["a", "b", "c"])。 |
str(): 将对象转换为字符串类型。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
object | 任意类型 | 必填 | 需要转换为字符串的对象(如整数、浮点数、列表等)。 |
results:存储实体的字典,键为实体类型,值为实体文本列表。
defaultdict():创建一个默认字典,当访问不存在的键时返回指定类型的默认值(如空列表、0)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
default_factory | Callable | 必填 | 生成默认值的工厂函数(如 int、list、lambda: "N/A")。 |
location:正则匹配结果,包含实体位置信息(span() 方法返回 (s, e))。
s、e:实体在预处理后句子中的起始和结束索引。
re.finditer():在字符串中查找所有匹配正则表达式的子串,返回一个迭代器(包含 re.Match 对象)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pattern | str | 必填 | 正则表达式模式(如 r"\d+")。 |
string | str | 必填 | 要搜索的字符串。 |
flags | int | 0 | 正则表达式标志(如 re.IGNORECASE)。 |
字符串.span():返回正则表达式匹配的子串在原始字符串中的起始和结束位置(元组 (start, end))
列表.append():在列表末尾添加一个元素。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
element | 任意类型 | 必填 | 要添加到列表末尾的元素。 |
'''
{
"B-LOCATION": 0,
"B-ORGANIZATION": 1,
"B-PERSON": 2,
"B-TIME": 3,
"I-LOCATION": 4,
"I-ORGANIZATION": 5,
"I-PERSON": 6,
"I-TIME": 7,
"O": 8
}
'''
def decode(self, sentence, labels):
sentence = "$" + sentence
labels = "".join([str(x) for x in labels[:len(sentence)+1]])
results = defaultdict(list)
for location in re.finditer("(04+)", labels):
s, e = location.span()
results["LOCATION"].append(sentence[s:e])
for location in re.finditer("(15+)", labels):
s, e = location.span()
results["ORGANIZATION"].append(sentence[s:e])
for location in re.finditer("(26+)", labels):
s, e = location.span()
results["PERSON"].append(sentence[s:e])
for location in re.finditer("(37+)", labels):
s, e = location.span()
results["TIME"].append(sentence[s:e])
return results
6.完整代码
# -*- coding: utf-8 -*-
import torch
import re
import numpy as np
from collections import defaultdict
from loader import load_data
"""
模型效果测试
"""
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.stats_dict = {"LOCATION": defaultdict(int),
"TIME": defaultdict(int),
"PERSON": defaultdict(int),
"ORGANIZATION": defaultdict(int)}
self.model.eval()
for index, batch_data in enumerate(self.valid_data):
sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_id) #不输入labels,使用模型当前参数进行预测
self.write_stats(labels, pred_results, sentences)
self.show_stats()
return
def write_stats(self, labels, pred_results, sentences):
assert len(labels) == len(pred_results) == len(sentences)
if not self.config["use_crf"]:
pred_results = torch.argmax(pred_results, dim=-1)
for true_label, pred_label, sentence in zip(labels, pred_results, sentences):
if not self.config["use_crf"]:
pred_label = pred_label.cpu().detach().tolist()
true_label = true_label.cpu().detach().tolist()
true_entities = self.decode(sentence, true_label)
pred_entities = self.decode(sentence, pred_label)
# 正确率 = 识别出的正确实体数 / 识别出的实体数
# 召回率 = 识别出的正确实体数 / 样本的实体数
for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:
self.stats_dict[key]["正确识别"] += len([ent for ent in pred_entities[key] if ent in true_entities[key]])
self.stats_dict[key]["样本实体数"] += len(true_entities[key])
self.stats_dict[key]["识别出实体数"] += len(pred_entities[key])
return
def show_stats(self):
F1_scores = []
for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:
# 正确率 = 识别出的正确实体数 / 识别出的实体数
# 召回率 = 识别出的正确实体数 / 样本的实体数
precision = self.stats_dict[key]["正确识别"] / (1e-5 + self.stats_dict[key]["识别出实体数"])
recall = self.stats_dict[key]["正确识别"] / (1e-5 + self.stats_dict[key]["样本实体数"])
F1 = (2 * precision * recall) / (precision + recall + 1e-5)
F1_scores.append(F1)
self.logger.info("%s类实体,准确率:%f, 召回率: %f, F1: %f" % (key, precision, recall, F1))
self.logger.info("Macro-F1: %f" % np.mean(F1_scores))
correct_pred = sum([self.stats_dict[key]["正确识别"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
total_pred = sum([self.stats_dict[key]["识别出实体数"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
true_enti = sum([self.stats_dict[key]["样本实体数"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
micro_precision = correct_pred / (total_pred + 1e-5)
micro_recall = correct_pred / (true_enti + 1e-5)
micro_f1 = (2 * micro_precision * micro_recall) / (micro_precision + micro_recall + 1e-5)
self.logger.info("Micro-F1 %f" % micro_f1)
self.logger.info("--------------------")
return
'''
{
"B-LOCATION": 0,
"B-ORGANIZATION": 1,
"B-PERSON": 2,
"B-TIME": 3,
"I-LOCATION": 4,
"I-ORGANIZATION": 5,
"I-PERSON": 6,
"I-TIME": 7,
"O": 8
}
'''
def decode(self, sentence, labels):
sentence = "$" + sentence
labels = "".join([str(x) for x in labels[:len(sentence)+1]])
results = defaultdict(list)
for location in re.finditer("(04+)", labels):
s, e = location.span()
results["LOCATION"].append(sentence[s:e])
for location in re.finditer("(15+)", labels):
s, e = location.span()
results["ORGANIZATION"].append(sentence[s:e])
for location in re.finditer("(26+)", labels):
s, e = location.span()
results["PERSON"].append(sentence[s:e])
for location in re.finditer("(37+)", labels):
s, e = location.span()
results["TIME"].append(sentence[s:e])
return results
六、模型训练文件 main.py
代码运行流程
# 主程序运行流程
├── 1. **初始化配置和日志**
│ └→ `logging.basicConfig(...)`:配置日志格式和级别。
├── 2. **定义 PEFT 包装函数**
│ └→ `peft_wrapper(model)`:应用 LoRA 微调配置到模型。
├── 3. **主函数 `main(config)`**
│ │
│ ├── 3.1 **创建模型保存目录**
│ │ └→ `os.mkdir(config["model_path"])`(如果目录不存在)。
│ │
│ ├── 3.2 **加载训练数据**
│ │ └→ `train_data = load_data(...)`:加载预处理后的训练数据。
│ │
│ ├── 3.3 **初始化模型并应用 PEFT**
│ │ ├→ `model = TorchModel(config)`:构建基础模型。
│ │ └→ `model = peft_wrapper(model)`:添加 LoRA 适配器。
│ │
│ ├── 3.4 **迁移模型至 GPU(如果可用)**
│ │ └→ `model = model.cuda()`。
│ │
│ ├── 3.5 **加载优化器**
│ │ └→ `optimizer = choose_optimizer(...)`:根据配置选择优化器(如 Adam)。
│ │
│ ├── 3.6 **初始化评估器**
│ │ └→ `evaluator = Evaluator(...)`:用于验证集性能评估。
│ │
│ ├── 3.7 **训练循环**
│ │ │
│ │ ├── 3.7.1 **遍历每个 epoch**
│ │ │ ├→ `model.train()`:设置模型为训练模式。
│ │ │ ├→ 遍历每个批次数据:
│ │ │ │ ├→ `optimizer.zero_grad()`:清空梯度。
│ │ │ │ ├→ 数据迁移至 GPU(如果可用)。
│ │ │ │ ├→ 前向传播:`loss = model(input_id, labels)`。
│ │ │ │ ├→ 反向传播:`loss.backward()`。
│ │ │ │ └→ 参数更新:`optimizer.step()`。
│ │ │ └→ 记录平均损失。
│ │ │
│ │ └── 3.7.2 **每个 epoch 后的评估**
│ │ └→ `evaluator.eval(epoch)`:在验证集上计算指标。
│ │
│ └── 3.8 **保存最终模型**
│ └→ `torch.save(model.state_dict(), model_path)`。
└── 4. **程序入口**
└→ `if __name__ == "__main__":`:调用 `main(Config)`。1.导入文件
torch:PyTorch 深度学习框架,用于构建、训练和部署神经网络。
os:操作系统交互库,用于文件路径处理和目录操作。
random:生成伪随机数,用于控制随机性。
numpy:科学计算库,支持多维数组和矩阵运算。
logging:日志记录库,用于输出程序运行信息。
get_peft_model:将基础模型包装为 PEFT 模型。
LoraConfig:配置参数高效微调库 LoRA(Low-Rank Adaptation)参数。
TaskType:指定任务类型(如序列标注、分类)。
# -*- coding: utf-8 -*-
import torch
import os
import random
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from peft import get_peft_model, LoraConfig, TaskType2.日志文件配置
logger:全局日志记录器实例,用于输出训练过程中的信息。
logging.basicConfig():配置日志系统的默认行为(如日志级别、格式、输出位置)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
level | int | WARNING | 日志级别(如 logging.INFO)。 |
format | str | 基础格式 | 日志消息格式(如 '%(asctime)s - %(message)s')。 |
filename | str | None | 日志输出文件路径(如不指定则输出到控制台)。 |
filemode | str | 'a' | 文件写入模式('w' 覆盖,'a' 追加)。 |
logging.getLogger():获取或创建一个日志记录器实例(用于模块化日志管理)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
name | str | 必填 | 日志记录器名称(通常为模块名)。 |
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)3.LoRA目标模块配置(包装函数)peft_wrapper ⭐
什么是LoRA
LoRA(Low-Rank Adaptation,低秩适应) 是一种 参数高效微调技术(Parameter-Efficient Fine-Tuning, PEFT),专为大型预训练语言模型(如 BERT、GPT)设计。其核心思想是 通过低秩矩阵分解,仅微调模型的部分参数,从而显著减少训练时的计算量和内存消耗。
LoRA的核心原理
低秩矩阵分解:在模型的权重矩阵旁插入 低秩适配器(Adapter),代替直接微调原始权重。
原始权重矩阵 ![]() ,分解为:
,分解为: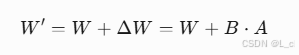
![]() ,仅训练 B 和 A,保持 W 冻结。
,仅训练 B 和 A,保持 W 冻结。
参数高效性:可训练参数量从 d × k 减少到 r × (d + k),例如:若 d=1024,k=1024,r=8,参数从 104 万减少到 16,384(减少 98%)。
"query"、"key":在BERT或其他Transformer架构中,每个Transformer层包含自注意力机制,其中包含三个核心线性变换矩阵:Query (Q)、Key (K)、Value (V)
这些矩阵通过线性层(nn.Linear)实现,通常命名为 attention.self.query、attention.self.key 和 attention.self.value
LoraConfig():定义 LoRA(Low-Rank Adaptation)微调策略的参数配置。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
r | int | 必填 | 低秩矩阵的秩(控制参数量)。 |
lora_alpha | int | 必填 | 缩放因子(控制低秩矩阵的影响强度)。 |
lora_dropout | float | 0.0 | LoRA 层的 Dropout 率。 |
target_modules | List[str] | 必填 | 应用 LoRA 的目标模块(如 Transformer 的 ["query", "key", "value"])。 |
get_peft_model():将基础模型包装为支持参数高效微调(PEFT)的模型(LoRA后的模型)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
model | nn.Module | 必填 | 基础模型实例。 |
peft_config | PeftConfig | 必填 | PEFT 配置对象(如 LoraConfig)。 |
def peft_wrapper(model):
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "value"]
)
return get_peft_model(model, peft_config)4.模型训练主程序
① 创建保存模型的目录
os.path.isdir():检查指定路径是否为目录。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
path | str | 必填 | 待检查的目录路径。 |
os.mkdir():创建新目录。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
path | str | 必填 | 待创建的目录路径。 |
# 创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])② 加载训练数据
train_data:加载并预处理训练数据,生成适用于模型训练的数据加载器。
config:配置字典,提供数据处理的详细参数(如批次大小、最大长度、分词方式等)。
config["train_data_path"]:训练数据文件路径(如 "data/train.txt"),存储原始文本和标签。
load_data():数据加载器封装函数
# 加载训练数据
train_data = load_data(config["train_data_path"], config)③ 加载模型
config:模型配置,包含预训练路径、分类数、是否使用 CRF 等。
model:存储模型实例。
TorchModel():根据配置构建基础神经网络模型。
peft_wrapper():将基础模型转换为参数高效微调(PEFT)版本。
# 加载模型
model = TorchModel(config)
model = peft_wrapper(model)④ 标识是否使用GPU
cuda_flag:GPU 是否可用的标志变量,用于控制模型是否迁移到 GPU 以优化计算性能。
torch.cuda.is_available():检查当前系统是否支持 CUDA(即 GPU 是否可用)。
logging.info():记录信息级别的日志消息。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的变量参数。 |
**kwargs | dict | {} | 关键字参数(如 exc_info)。 |
model.cuda():将模型迁移到 GPU 显存以加速计算。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
device | int 或 torch.device | None | 目标 GPU 设备号(如 0)。 |
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()⑤ 加载优化器
optimizer:优化器,用于更新模型参数以最小化损失函数。
config:存储训练和模型配置的字典
model:待训练的模型实例,包含所有可训练参数。
choose_optimizer():根据 config 选择优化器并初始化
# 加载优化器
optimizer = choose_optimizer(config, model)⑥ 加载效果测试类
evaluator:评估模型性能的类实例
config:全局配置字典,控制优化器、模型结构和训练流程。
model:训练和评估的目标模型,提供参数和计算图。
logger:日志记录器,用于输出评估过程信息(如准确率、F1 值)。
Evaluator():评估模型性能的类,用于验证集或测试集的指标计算(如准确率、F1 值)
# 加载效果测试类
evaluator = Evaluator(config, model, logger)⑦ 训练主流程 ⭐
Ⅰ、Epoch循环控制
epoch:当前训练轮次的序号
config["epoch"]:控制训练的总轮次(即模型遍历完整训练数据集的次数)
range():生成一个整数序列(常用于循环迭代)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
start | int | 0 | 序列起始值。 |
stop | int | 必填 | 序列结束值(不包含)。 |
step | int | 1 | 步长(间隔)。 |
# 训练
for epoch in range(config["epoch"]):
epoch += 1Ⅱ、模型设置训练模式
model.train():设置模型为训练模式(启用 Dropout 和 BatchNorm 的随机性)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
mode | bool | True | 是否设置为训练模式。 |
model.train()Ⅲ、Batch数据遍历
logging.info():记录信息级别的日志消息。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的变量参数。 |
**kwargs | dict | {} | 关键字参数(如 exc_info)。 |
logger:日志记录器,用于输出训练过程中的关键信息。
train_loss:列表,存储当前 epoch 内所有批次的损失值。
index:当前批次在 epoch 中的序号(从 0 开始计数)。
batch_data:单个批次的训练数据,包含输入和标签。
epoch:当前训练轮次的序号
enumerate():遍历可迭代对象并返回索引和元素。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | Iterable | 必填 | 可迭代对象(如列表)。 |
start | int | 0 | 索引的起始值。 |
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):Ⅳ、梯度清零与设备切换
optimizer.zero_grad():清空模型参数的梯度缓存。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
set_to_none | bool | False | 是否将梯度设为 None(节省内存)。 |
optimizer:优化器,用于更新模型参数以最小化损失函数。
cuda_flag:指示 GPU 是否可用(True 表示可用)。
batch_data:单个批次的训练数据,包含输入和标签。
cuda():将模型迁移到 GPU 显存以加速计算。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
device | int 或 torch.device | None | 目标 GPU 设备号(如 0)。 |
input_id:输入文本的 token ID 序列(经过编码处理)。
lables:与输入对应的真实标签(监督信号)。
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况
Ⅴ、前向传播与损失计算
loss:模型根据输入 input_id 和真实标签 labels 计算出的标量值,反映了模型预测结果与真实标签之间的差距。
input_id:输入文本的 token ID 序列(经过编码处理)。
lables:与输入对应的真实标签(监督信号)。
loss = model(input_id, labels)Ⅵ、反向传播与参数更新
loss:模型根据输入 input_id 和真实标签 labels 计算出的标量值,反映了模型预测结果与真实标签之间的差距。
optimizer:优化器,用于更新模型参数以最小化损失函数。
loss.backward():反向传播计算梯度。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
retain_graph | bool | False | 是否保留计算图(用于多次反向传播)。 |
optimizer.step():根据梯度更新模型参数。
loss.backward()
optimizer.step()Ⅶ、损失记录与日志输出
train_loss:列表,存储当前轮次所有批次的损失值
loss:前向传播计算损失
index:当前批次在 epoch 中的序号(从 0 开始计数)。
train_data:训练数据加载器,按批次(batch)提供训练数据,支持高效的数据加载和预处理。
列表.append():在列表末尾添加元素。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
element | 任意类型 | 必填 | 要添加的元素。 |
item():将张量中的单个值转换为 Python 标量(如 float 或 int)。
logger.info():记录信息级别的日志消息。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的变量参数。 |
**kwargs | dict | {} | 关键字参数(如 exc_info)。 |
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)Ⅷ、Epoch评估与日志
logger.info():记录信息级别的日志消息。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的变量参数。 |
**kwargs | dict | {} | 关键字参数(如 exc_info)。 |
np.mean():计算数组或列表的平均值。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
array | array_like | 必填 | 输入数组或列表。 |
axis | int 或 None | None | 计算均值的维度(如 0) |
logger:日志记录器,用于将训练过程中的关键信息输出到控制台或日志文件。
train_loss:列表,存储当前 epoch 内所有批次的损失值。
evaluator:评估器实例,在验证集上评估模型的性能(如准确率、召回率、F1 值),并记录结果
epoch:当前训练轮次的序号(从 1 开始计数)。
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)Ⅸ、完整训练代码
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from peft import get_peft_model, LoraConfig, TaskType
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
def peft_wrapper(model):
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "value"]
)
return get_peft_model(model, peft_config)
def main(config):
# 创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
# 加载训练数据
train_data = load_data(config["train_data_path"], config)
# 加载模型
model = TorchModel(config)
model = peft_wrapper(model)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
# 加载优化器
optimizer = choose_optimizer(config, model)
# 加载效果测试类
evaluator = Evaluator(config, model, logger)
# 训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_id, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)
model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
torch.save(model.state_dict(), model_path)
return model, train_data
if __name__ == "__main__":
model, train_data = main(Config)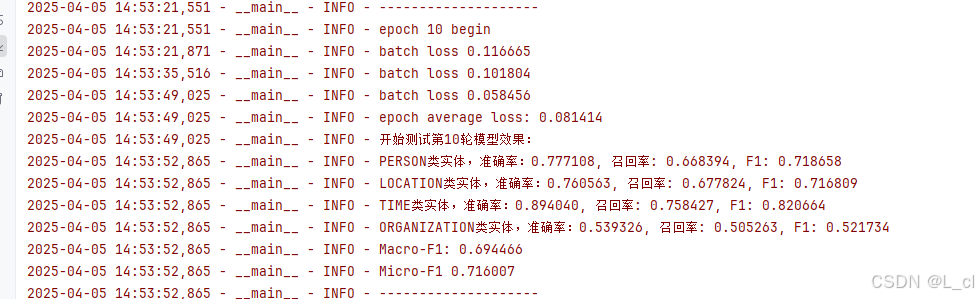
七、模型预测文件 predict.py
代码运行流程
# 代码运行流程树状图
├── 1. **初始化 NER 实例**
│ ├→ 加载配置:`Config`
│ ├→ 加载词汇表:`BertTokenizer.from_pretrained(bert_path)`
│ ├→ 加载实体类别定义:`load_schema(schema_path)`
│ ├→ 构建基础模型:`TorchModel(config)`
│ ├→ 应用 PEFT 微调:`peft_wrapper(model)`
│ ├→ 加载预训练权重:`state_dict.update(torch.load(model_path))`
│ ├→ 权重重新载入:`model.load_state_dict(state_dict)`
│ └→ 设置模型为评估模式:`model.eval()`
├── 2. **输入句子预处理**
│ ├→ 示例输入:`sentence = "(本报约翰内斯堡电)本报记者安洋贺广华..."`
│ └→ 调用 `predict(sentence)` 方法。
├── 3. **句子编码**
│ ├→ 调用 `encode_sentence(sentence)`
│ ├→ 使用 `BertTokenizer` 将文本转换为 ID 序列:
│ │ ├→ `padding="max_length"`(填充至最大长度)
│ │ ├→ `max_length=config["max_length"]`
│ │ └→ `truncation=True`(截断超长部分)
├── 4. **模型推理**
│ ├→ 输入张量转换:`torch.LongTensor([input_ids])`
│ ├→ 模型前向传播:`model(input_ids)`
│ ├→ 输出 logits:`res = model(...)[0]`
│ └→ 取预测标签:`labels = torch.argmax(res, dim=-1)`
├── 5. **标签解码**
│ ├→ 调用 `decode(sentence, labels)`
│ ├→ **预处理**:
│ │ ├→ 句子开头添加 `$`:`sentence = "$" + sentence`
│ │ └→ 标签序列转换为字符串:`labels = "".join(...)`
│ ├→ **正则匹配实体位置**:
│ │ ├→ `LOCATION`:模式 `04+`(B=0, I=4)
│ │ ├→ `ORGANIZATION`:模式 `15+`(B=1, I=5)
│ │ ├→ `PERSON`:模式 `26+`(B=2, I=6)
│ │ └→ `TIME`:模式 `37+`(B=3, I=7)
│ └→ **提取实体文本**:`sentence[s:e]`
├── 6. **输出结果**
│ └→ 示例输出:
│ ```python
│ {
│ "LOCATION": ["约翰内斯堡"],
│ "PERSON": ["安洋", "贺广华"],
│ ...
│ }
│ ```
└── 7. **程序结束**
└→ 返回实体字典并打印。1.导入文件
torch:PyTorch 深度学习框架,提供张量计算、自动微分和 GPU 加速功能。
re:正则表达式,处理字符串的模式匹配和文本清洗。
json:读写 JSON 格式数据。
collections:Python 标准库中的一个模块,提供了许多高效且专用的容器数据类型,是对 Python 内置数据类型(如 list、dict、tuple 等)的补充。
defaultdict:提供带有默认值的字典,避免键不存在时的 KeyError。
transformers (Hugging Face Transformers 库):提供预训练模型(如 BERT、GPT)和 NLP 工具。
BertTokenizer:将文本转换为 BERT 模型所需的输入格式(如 token IDs、attention masks)。
BertModel:加载预训练的 BERT 模型,作为特征提取器或微调的基础。
# -*- coding: utf-8 -*-
import torch
import re
import json
from collections import defaultdict
from config import Config
from model import TorchModel
from transformers import BertTokenizer, BertModel
from main import peft_wrapper
2.初始化
config:全局配置字典,存储所有超参数、路径和模型设置。
model_path:预训练模型权重文件的路径(如 "model/epoch_10.pth")。
self.config:将全局配置字典保存为实例属性,方便类内其他方法访问。
self.tokenizer:BERT 分词器实例,用于将文本转换为模型输入(如 token IDs)。
config["bert_path"]:
self.schema:存储标签或数据结构的定义(如实体类型、分类标签)。
config["schema_path"]:
self.load_vocab():自定义函数,加载分词器(Tokenizer):将文本数据转换为模型可处理的输入格式(如 token IDs、attention masks)。
self.load_schema():自定义函数,加载标签定义(Schema):定义任务的输出结构(如实体类型、分类标签)。
model:初始化基础模型(基于 BERT 的任务特定模型,如分类或序列标注)
TorchModel():自定义模型类
peft_wrapper():应用参数高效微调(PEFT)策略(如 LoRA)到基础模型。
state_dict:字典,键为参数名,值为 torch.Tensor
model.state_dict():返回一个字典(OrderedDict),包含模型的所有可学习参数(权重和偏置)。
- 键(Key):参数名称(如
"bert.encoder.layer.0.attention.query.weight")。 - 值(Value):对应的参数张量(
torch.Tensor)。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
destination | dict | 否 | None | 若提供,参数将存入此字典(否则创建新字典)。 |
prefix | str | 否 | "" | 在所有键名前添加前缀(例如 prefix="module." 用于多 GPU 模型)。 |
keep_vars | bool | 否 | False | 保留 torch.Tensor 的计算图信息(用于继续训练,通常不需设置)。 |
state_dict.update():将预训练权重合并到当前模型的参数中。
torch.load():加载由 torch.save() 保存的对象(如模型参数、优化器状态、张量等)。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
f | str 或 IO 对象 | 是 | - | 文件路径或文件句柄(如打开的文件对象)。 |
map_location | str 或 dict | 否 | None | 指定加载设备(如 "cpu" 或 "cuda:0"),或映射规则(如 {"cuda:0": "cpu"})。 |
pickle_module | module | 否 | pickle | 指定反序列化模块(通常不需修改)。 |
weights_only | bool | 否 | False | 若为 True,仅加载张量(禁止加载可能含有恶意代码的 pickle 对象)。 |
**kwargs | - | 否 | - | 传递给 pickle_module.load() 的额外参数。 |
model.load_state_dict():将合并后的参数加载回模型,完成权重初始化
model.eval():将模型设置为评估模式(关闭 Dropout 和 BatchNorm 的随机性)。
def __init__(self, config, model_path):
self.config = config
self.tokenizer = self.load_vocab(config["bert_path"])
self.schema = self.load_schema(config["schema_path"])
model = TorchModel(config)
model = peft_wrapper(model)
state_dict = model.state_dict()
state_dict.update(torch.load(model_path))
model.load_state_dict(state_dict)
model.eval()
self.model = model
print("模型加载完毕!")3.加载映射关系表
path:字符串 (str),表示要加载的 JSON 文件的路径。
f:文件对象 (TextIOWrapper),通过 open() 打开文件后的文件句柄,用于读取文件内容。
open():打开一个文件并返回文件对象,用于读取或写入文件内容。支持文本模式和二进制模式,并允许指定编码、错误处理等。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
file | str | 是 | - | 文件路径(如 "data/schema.json")。 |
mode | str | 否 | 'r' | 打开模式:'r'(读)、'w'(写)、'a'(追加)、'b'(二进制)等。 |
encoding | str | 否 | 系统默认 | 文本编码(如 'utf-8')。 |
errors | str | 否 | 'strict' | 编码错误处理方式(如 'ignore' 忽略错误)。 |
newline | str | 否 | None | 控制换行符(仅文本模式)。 |
| 其他参数 | - | - | - | (如 buffering、closefd 等,通常无需指定)。 |
json.load():从文件对象中读取 JSON 数据,并将其解析为 Python 对象(如字典、列表)。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
fp | 文件对象 | 是 | - | 已打开的文件对象(通过 open() 获取)。 |
object_hook | Callable | 否 | None | 自定义 JSON 对象解码函数(如将字典转换为自定义类)。 |
parse_float | Callable | 否 | float | 自定义浮点数解析函数(如使用 decimal.Decimal)。 |
parse_int | Callable | 否 | int | 自定义整数解析函数。 |
| 其他参数 | - | - | - | (如 parse_constant、cls 等,通常无需指定)。 |
def load_schema(self, path):
with open(path, encoding="utf8") as f:
return json.load(f)4.加载字词表
vocab_path:字符串 (str),指定 BERT 分词器的加载路径
BertTokenizer.from_pretrained():加载预训练的 BERT 分词器(Tokenizer),将文本转换为模型可处理的输入格式(如 token IDs、attention masks)。支持从 Hugging Face 模型库或本地路径加载分词器,确保与预训练模型兼容,并自动处理文本的标准化、分词、添加特殊标记(如 [CLS]、[SEP])等操作。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
pretrained_model_name_or_path | str 或 Path | 是 | - | 预训练模型的名称(如 "bert-base-chinese")或本地目录路径。 |
cache_dir | str | 否 | None | 指定模型文件的缓存目录。 |
force_download | bool | 否 | False | 是否强制重新下载模型文件(覆盖缓存)。 |
resume_download | bool | 否 | False | 是否支持断点续传下载。 |
proxies | dict | 否 | None | 设置代理服务器(如 {"http": "http://10.10.1.10:3128"})。 |
local_files_only | bool | 否 | False | 是否仅使用本地文件(不联网下载)。 |
token | str 或 bool | 否 | None | Hugging Face 认证 Token(用于访问私有模型)。 |
revision | str | 否 | "main" | 指定模型版本(如 Git 分支、标签或提交哈希)。 |
use_fast | bool | 否 | True | 是否使用快速分词器(基于 Rust 实现,速度更快)。 |
| 其他参数 | - | - | - | (如 trust_remote_code、mirror 等,通常无需指定)。 |
# 加载字表或词表
def load_vocab(self, vocab_path):
return BertTokenizer.from_pretrained(vocab_path)
5.文本句子编码
text:需要编码的原始文本输入(例如:"你好,世界")。
padding:控制是否对序列进行填充(Padding)以统一长度。
self.tokenizer:BertTokenizer,将文本转换为模型输入格式(token IDs、attention masks 等)。
encode():将文本字符串转换为模型可处理的 Token ID 序列,支持填充(Padding)、截断(Truncation)、添加特殊标记(如 [CLS]、[SEP])等操作。
| 参数名 | 类型 | 必需 | 默认值 | 说明 | 示例值 |
|---|---|---|---|---|---|
text | str 或 List[str] | 是 | - | 要编码的文本(单句或列表)。 | "你好,世界" |
padding | bool 或 str | 否 | False | 填充策略:True/"longest"(填充到最长序列)、"max_length"(填充到指定长度)。 | "max_length" |
max_length | int | 否 | 分词器模型最大长度 | 控制填充或截断后的序列长度(如 512)。 | 128 |
truncation | bool 或 str | 否 | False | 截断策略:True(截断到 max_length)、"only_first"(仅截断首句)。 | True |
add_special_tokens | bool | 否 | True | 是否添加特殊标记(如 BERT 的 [CLS] 和 [SEP])。 | True |
return_tensors | str | 否 | None | 返回张量格式:"pt"(PyTorch)、"tf"(TensorFlow)、"np"(NumPy)。 | "pt" |
return_attention_mask | bool | 否 | True | 是否返回 attention_mask(标识有效 token 位置)。 | True |
| 其他参数 | - | - | - | (如 return_token_type_ids、return_overflowing_tokens 等)。 | - |
def encode_sentence(self, text, padding=True):
return self.tokenizer.encode(text,
padding="max_length",
max_length=self.config["max_length"],
truncation=True)6.解码文本
代码运行流程
decode(sentence, labels)
├─ 预处理阶段
│ ├─ 修改句子:sentence = "$" + sentence
│ └─ 转换标签:labels → 字符串(示例:数值标签[0,4,4,4] → "0444")
│ ├─ 截取长度:labels[:len(sentence)+1]
│ └─ 合并字符:生成连续字符串(如"0444")
├─ 初始化结果字典:results = defaultdict(list)
├─ 正则匹配实体
│ ├─ 匹配 LOCATION
│ │ ├─ 正则模式:r"(04+)" (匹配以0开头后续多个4的标签)
│ │ └─ 对每个匹配项:
│ │ ├─ 获取起止位置:s, e = match.span()
│ │ └─ 提取文本:sentence[s:e] → 存入results["LOCATION"]
│ ├─ 匹配 ORGANIZATION
│ │ ├─ 正则模式:r"(15+)" (匹配以1开头后续多个5的标签)
│ │ └─ 对每个匹配项:
│ │ ├─ 获取起止位置:s, e = match.span()
│ │ └─ 提取文本:sentence[s:e] → 存入results["ORGANIZATION"]
│ ├─ 匹配 PERSON
│ │ ├─ 正则模式:r"(26+)" (匹配以2开头后续多个6的标签)
│ │ └─ 对每个匹配项:
│ │ ├─ 获取起止位置:s, e = match.span()
│ │ └─ 提取文本:sentence[s:e] → 存入results["PERSON"]
│ └─ 匹配 TIME
│ ├─ 正则模式:r"(37+)" (匹配以3开头后续多个7的标签)
│ └─ 对每个匹配项:
│ ├─ 获取起止位置:s, e = match.span()
│ └─ 提取文本:sentence[s:e] → 存入results["TIME"]
└─ 返回结果:return results(包含所有匹配实体的字典)sentence:str 类型,原始输入句子(如 "北京欢迎你")。
labels:数值序列(如 List[int] 或 np.ndarray),模型预测的标签序列,每个元素对应一个字符的实体类型编码。
join():将可迭代对象(如列表、元组)中的元素连接成一个字符串,元素之间用调用该方法的字符串(空字符串)分隔。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
iterable | 可迭代对象 | 是 | 无 | 包含字符串元素的可迭代对象(如列表)。 |
str():将对象转换为字符串形式
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
object | 任意对象 | 是 | 无 | 需转换为字符串的对象。 |
default():创建一个默认字典,当访问不存在的键时,返回由 default_factory 生成的默认值。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
default_factory | 可调用对象 | 是 | 无 | 生成默认值的函数(如 list、int)。 |
results:存储不同实体类型的识别结果,字典的键为实体类型(如 "LOCATION"),值为对应实体的文本列表。
location:通过 re.finditer 获得的匹配对象,表示一个正则表达式匹配的结果,包含匹配的位置和文本信息。
s(start):实体标签在 labels 字符串中的起始索引。
e(end):实体标签在 labels 字符串中的结束索引。
re.finditer():在字符串中查找所有匹配正则表达式的子串,返回一个迭代器,每个元素是匹配对象。
Match.span:返回正则匹配的起始和结束位置(闭区间),格式为 (start, end)。
列表.append():在列表末尾添加一个元素。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
element | 任意类型 | 是 | 无 | 要添加的元素。 |
def decode(self, sentence, labels):
sentence = "$" + sentence
labels = "".join([str(int(x)) for x in labels[:len(sentence) + 1]])
results = defaultdict(list)
for location in re.finditer("(04+)", labels):
s, e = location.span()
results["LOCATION"].append(sentence[s:e])
for location in re.finditer("(15+)", labels):
s, e = location.span()
results["ORGANIZATION"].append(sentence[s:e])
for location in re.finditer("(26+)", labels):
s, e = location.span()
results["PERSON"].append(sentence[s:e])
for location in re.finditer("(37+)", labels):
s, e = location.span()
results["TIME"].append(sentence[s:e])
return results7.预测文件
代码运行流程
predict(sentence)
├─ 输入处理阶段
│ ├─ 调用 self.encode_sentence(sentence) → input_ids
│ │ ├─ 将句子编码为模型输入格式(Token ID序列)
│ │ └─ 输出示例:[101, 123, 456, 789, 102](BERT格式)
│ └─ 转换为张量:torch.LongTensor([input_ids])
│ ├─ 添加批次维度:[input_ids] → shape (1, seq_len)
│ └─ 示例:tensor([[101, 123, 456, 789, 102]])
├─ 模型推理阶段(无梯度计算)
│ ├─ with torch.no_grad():
│ │ ├─ 模型前向传播:self.model(input_tensor) → res
│ │ │ ├─ 输出形状:(batch_size, seq_len, num_labels)
│ │ │ └─ 示例:shape (1, 5, 8)(8个实体类别)
│ │ └─ 提取预测结果:res[0] → shape (seq_len, num_labels)
│ │ └─ 示例:shape (5, 8)
│ └─ 取argmax生成标签:torch.argmax(res, dim=-1) → labels
│ ├─ 对每个token选择最大概率的标签
│ └─ 示例输出:tensor([0,4,4,4,0])(数值标签序列)
├─ 后处理阶段
│ └─ 调用 self.decode(sentence, labels) → results
│ ├─ 将标签序列解码为实体字典
│ └─ 示例输出:
│ {
│ "LOCATION": ["北京"],
│ "ORGANIZATION": [],
│ "PERSON": ["张三"]
│ }
└─ 返回结果:return resultssentence:输入的原始文本句子。
input_ids:通过 self.encode_sentence() 将句子编码后的 Token ID 序列(如 BERT 的 [CLS] + 句子 + [SEP])。
self.encode_sentence():将句子编码为模型输入的 Token ID 序列,包含分词、添加特殊标记、填充/截断等操作。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
text | str | 是 | 无 | 要编码的原始文本。 |
padding | bool | 否 | True | 是否填充到固定长度。 |
torch.no_grad():上下文管理器,禁用梯度计算,减少内存占用并加速推理。
res:模型输出的 每个 Token 的预测概率分布。
labels:对 res 在最后一个维度(dim=-1)取 最大概率对应的索引,即预测的标签序列。
torch.LongTensor():将 Python 列表或 NumPy 数组转换为 PyTorch 长整型张量。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
data | 可迭代对象 | 是 | 无 | 要转换为张量的数据。 |
torch.argmax():在指定维度(dim)上取最大值的索引。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
input | Tensor | 是 | 无 | 输入张量。 |
dim | int | 是 | 无 | 要在哪个维度取最大值。 |
results:字典,用于存储从输入句子中识别出的 不同类别的实体及其对应的文本片段。
字典的 键(Key) 是实体类别(如 "LOCATION"、"ORGANIZATION"),值(Value) 是对应类别下所有实体文本组成的列表。
self.decode(): 将标签序列解码为 实体字典(如 {"LOCATION": ["北京"], "PERSON": ["张三"]})。
| 参数名 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
sentence | str | 是 | 无 | 原始句子。 |
labels | torch.Tensor | 是 | 无 | 预测的标签序列。 |
def predict(self, sentence):
input_ids = self.encode_sentence(sentence)
with torch.no_grad():
res = self.model(torch.LongTensor([input_ids]))[0]
labels = torch.argmax(res, dim=-1)
results = self.decode(sentence, labels)
return results8.模型效果测试
sl:命名实体识别模型实例,用于加载配置和预训练模型,执行实体识别任务。
sentence:输入文本,包含需要识别的实体(如人名、地点、组织等)。
res:命名实体识别结果,按实体类型分类存储识别出的文本片段。
if __name__ == "__main__":
sl = NER(Config, "model_output/epoch_10.pth")
sentence = "(本报约翰内斯堡电)本报记者安洋贺广华留学人员档案库建立本报讯中国质量体系认证机构国家认可委员会日前正式签署了国际上第一个质量认证的多边互认协议,表明中国质量体系认证达到了国际水平。"
res = sl.predict(sentence)
print(res)9.完整代码
# -*- coding: utf-8 -*-
import torch
import re
import json
from collections import defaultdict
from config import Config
from model import TorchModel
from transformers import BertTokenizer, BertModel
from main import peft_wrapper
"""
模型效果测试
"""
class NER:
def __init__(self, config, model_path):
self.config = config
self.tokenizer = self.load_vocab(config["bert_path"])
self.schema = self.load_schema(config["schema_path"])
model = TorchModel(config)
model = peft_wrapper(model)
state_dict = model.state_dict()
state_dict.update(torch.load(model_path))
model.load_state_dict(state_dict)
model.eval()
self.model = model
print("模型加载完毕!")
def load_schema(self, path):
with open(path, encoding="utf8") as f:
return json.load(f)
# 加载字表或词表
def load_vocab(self, vocab_path):
return BertTokenizer.from_pretrained(vocab_path)
def encode_sentence(self, text, padding=True):
return self.tokenizer.encode(text,
padding="max_length",
max_length=self.config["max_length"],
truncation=True)
def decode(self, sentence, labels):
sentence = "$" + sentence
labels = "".join([str(int(x)) for x in labels[:len(sentence) + 1]])
results = defaultdict(list)
for location in re.finditer("(04+)", labels):
s, e = location.span()
results["LOCATION"].append(sentence[s:e])
for location in re.finditer("(15+)", labels):
s, e = location.span()
results["ORGANIZATION"].append(sentence[s:e])
for location in re.finditer("(26+)", labels):
s, e = location.span()
results["PERSON"].append(sentence[s:e])
for location in re.finditer("(37+)", labels):
s, e = location.span()
results["TIME"].append(sentence[s:e])
return results
def predict(self, sentence):
input_ids = self.encode_sentence(sentence)
with torch.no_grad():
res = self.model(torch.LongTensor([input_ids]))[0]
labels = torch.argmax(res, dim=-1)
results = self.decode(sentence, labels)
return results
if __name__ == "__main__":
sl = NER(Config, "model_output/epoch_10.pth")
sentence = "(本报约翰内斯堡电)本报记者安洋贺广华留学人员档案库建立本报讯中国质量体系认证机构国家认可委员会日前正式签署了国际上第一个质量认证的多边互认协议,表明中国质量体系认证达到了国际水平。"
res = sl.predict(sentence)
print(res)