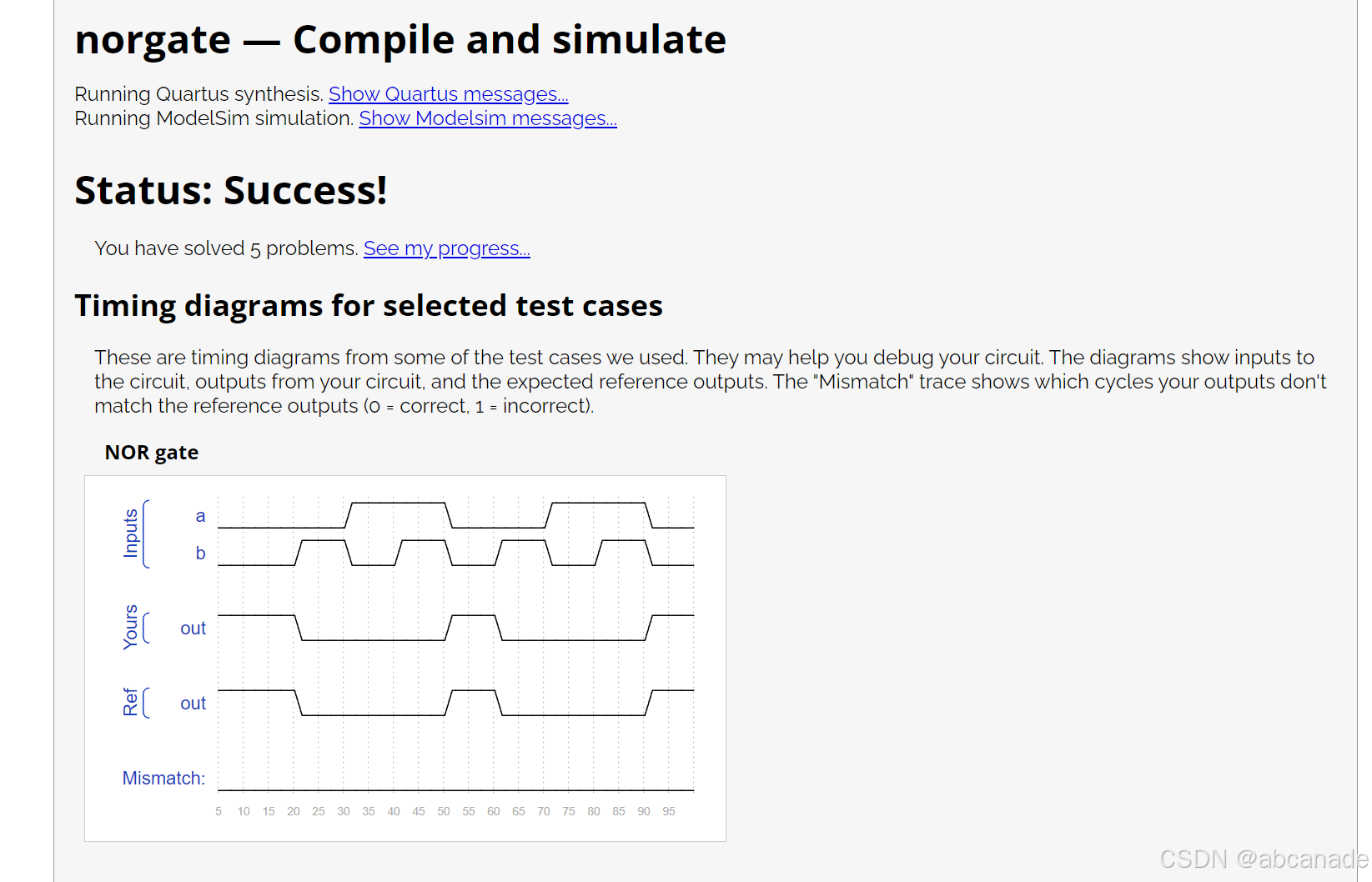
大文件上传源码,支持单个大文件与多个大文件
- Ⅰ 思路
- Ⅱ 具体代码
- 前端--单个大文件
- 前端--多个大文件
- 前端接口
- 后端
Ⅰ 思路
具体思路请参考我之前的文章,这里分享的是上传流程与源码
https://blog.csdn.net/sugerfle/article/details/130829022
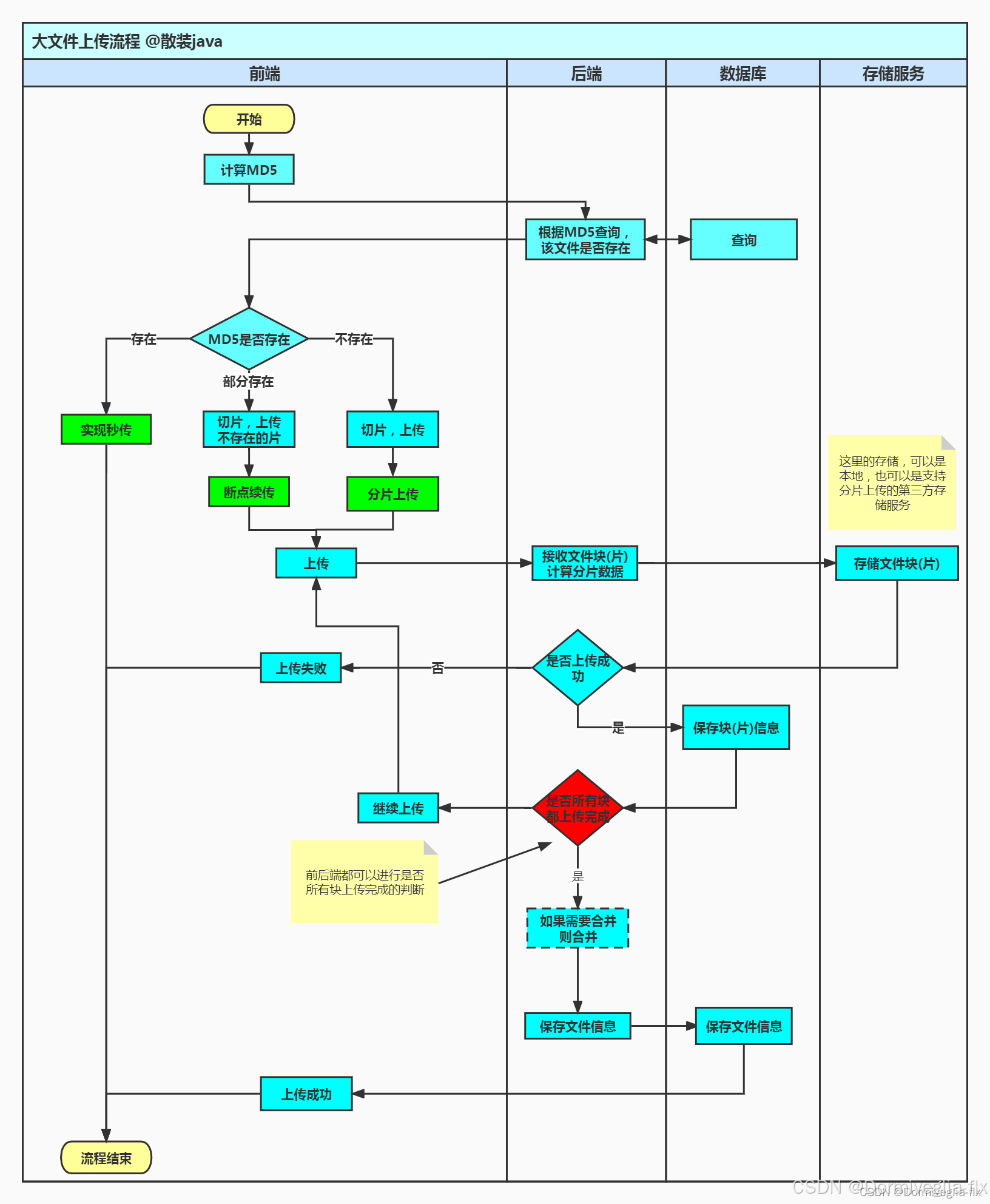
Ⅱ 具体代码
前端–单个大文件
<template>
<el-upload ref="fUploadFile"
multiple
action=""
:show-file-list="false"
:http-request="fhandleFileUpload"
:limit="2"
:on-exceed="fhandleExceed"
:on-success="fhandleSuccess"
:on-change="fhandleChange"
:file-list="fFileList"
>
<el-button class="button" type="primary">上传</el-button>
</el-upload>
</template>
<script>
import SparkMD5 from "spark-md5";
import {fcheckFileExists, fgetUploadedChunks, fMergeChunks, fUploadedChunks} from "@/api/record/recordfile";
export default {
name: "VCUpload",
props:['parentId'],
data(){
return{
fFileList: [], // 文件列表
fFile: null, // 当前文件
fChunkSize: 3 * 1024 * 1024, // 分片大小:3MB
fChunks: [], // 分片数组
fUploadedChunks: [], // 已上传分片索引
fFileType:"",
fFileName:""
}
},
methods:{
fhandleChange(file){
this.file = file.raw;
var fileName = file.name;
var fileArr = fileName.split('.');
this.fFileType=fileArr[fileArr.length-1];
this.fFileName = file.name
console.log("fhandleChange",file.raw)
this.initChunks();
},
fhandleFileUpload(data){
console.log("Flx组件",data)
},
fhandleExceed(){
},
fhandleSuccess(){
this.$refs.fUploadFile.clearFiles();
},
// ========= 分片相关业务方法 =============
// 初始化分片
initChunks() {
if (!this.file) return;
const file = this.file;
this.fChunks = [];
let cur = 0;
while (cur < file.size) {
this.fChunks.push({
index: this.fChunks.length,
file: file.slice(cur, cur + this.fChunkSize),
});
cur += this.fChunkSize;
}
console.log("初始化分片",this.fChunks)
this.calculateMD5(); // 计算文件 MD5
},
// 计算文件 MD5
calculateMD5() {
const spark = new SparkMD5.ArrayBuffer();
const reader = new FileReader();
reader.readAsArrayBuffer(this.file);
reader.onload = (e) => {
spark.append(e.target.result);
const md5 = spark.end();
this.checkFileExists(md5); // 检查文件是否已存在
};
},
// 检查文件是否已存在(秒传逻辑)
checkFileExists(md5) {
console.log("秒传逻辑",md5)
const data = {
fileMd5:md5,
parentId:this.parentId
}
fcheckFileExists(data).then(resp=>{
console.log("检查文件是否已存在",resp)
if(resp.data.data){
this.$message.success('文件上传成功!');
}else {
this.getUploadedChunks(md5); // 获取已上传分片
}
}).catch(res=>{
this.$message.success('文件检查失败!');
})
},
// 获取已上传分片(断点续传逻辑)
getUploadedChunks(md5) {
const data = {
md5: md5
}
fgetUploadedChunks(data).then(resp=>{
console.log("获取数据库中已经上传分片",resp.data.data)
this.fUploadedChunks = resp.data.data;
// 开始上传
this.startUpload(md5);
})
},
// 开始上传
async startUpload(md5) {
const allChunkLength = this.fChunks.length;
for(let i=0;i<allChunkLength;i++){
console.log("是否需要继续上传",this.fUploadedChunks.includes(this.fChunks[i].index+""))
if (!this.fUploadedChunks.includes(this.fChunks[i].index+"")) {
const formData = new FormData();
let formDataObj = {
chunkIndex:this.fChunks[i].index,
md5:md5
}
let sendData = JSON.stringify(formDataObj)
formData.append('dto',new Blob([sendData],{type:"application/json"}))
formData.append('chunkFile',this.fChunks[i].file)
const result = await this.fetchUploadedChunks(formData);
if(result=="error"){
this.$message.success('文件分片上传失败!');
return
}
console.log("上传分片成功",result)
this.fUploadedChunks.push(this.fChunks[i].index);
// 记录已上传分片
if (this.fUploadedChunks.length === this.fChunks.length) {
// 合并分片
console.log("合并分片")
this.mergeChunks(md5);
}
}
}
},
fetchUploadedChunks(formData){
return new Promise((resolve,reject)=>{
fUploadedChunks(formData).then((resp)=>{
resolve(resp.data.data)
}).catch(err=>{
reject("error")
})
})
},
mergeChunks(md5) {
const data = {
md5: md5,
fileType:this.fFileType,
parentId:this.parentId,
name: this.fFileName,
}
fMergeChunks(data).then(resp=>{
console.log("分片合并成功",resp.data.data)
this.$message.success('文件上传完成!');
this.fFileList = []
})
},
}
}
</script>
<style scoped lang="scss">
</style>
前端–多个大文件
<template>
<div style="display: flex">
<el-upload ref="fUploadFile"
action=""
:auto-upload="false"
:show-file-list="false"
:multiple="true"
:http-request="fhandleFileUpload"
:limit="5"
:on-exceed="fhandleExceed"
:on-success="fhandleSuccess"
:file-list="fFileList"
>
<el-button class="button" type="primary">选择文件</el-button>
</el-upload>
<el-button class="button" type="primary" @click.native="fsubmitUpload">上传</el-button>
</div>
</template>
<script>
import SparkMD5 from "spark-md5";
import {fcheckFileExists, fgetUploadedChunks, fMergeChunks, fUploadedChunks} from "@/api/record/recordfile";
export default {
name: "VCUpload",
props:['parentId'],
data(){
return{
fFileList: [], // 文件列表
fChunkSize: 3 * 1024 * 1024, // 分片大小:3MB
}
},
methods:{
// 自定义上传方法
fhandleFileUpload(options){
console.log("自定义上传方法",options)
const { file } = options;
const fileName = file.name;
const fileArr = fileName.split('.');
const fFileType=fileArr[fileArr.length-1];
// 初始化分片
const fChunks = this.initChunks(file);
// 计算文件 MD5 并绑定到文件对象
this.calculateMD5(file).then((md5) => {
file.md5 = md5; // 将 MD5 值绑定到文件对象
// 检查文件是否已存在(秒传逻辑)
this.checkFileExists(md5).then((exists) => {
if (exists) {
this.$message.success(`${file.name} 已存在,无需上传!`);
return;
}
// 获取已上传分片(断点续传逻辑)
this.getUploadedChunks(md5).then(res=>{
const fUploadedChunks = res;
// 开始上传
this.startUpload(md5,fChunks,fUploadedChunks,fileName,fFileType);
});
});
});
},
// 文件超出限制时的回调
fhandleExceed(files, fileList) {
this.$message.warning(`最多只能上传5个文件!`);
},
fsubmitUpload(){
this.$refs.fUploadFile.submit();
},
fhandleSuccess(){
this.$refs.fUploadFile.clearFiles();
},
// ========= 分片相关业务方法 =============
// 初始化分片
initChunks(fArgsfile) {
const file = fArgsfile;
const fChunks = [];
let cur = 0;
while (cur < file.size) {
fChunks.push({
index: fChunks.length+"",
file: file.slice(cur, cur + this.fChunkSize),
});
cur += this.fChunkSize;
}
console.log("初始化分片",fChunks)
return fChunks;
},
// 计算文件 MD5
calculateMD5(fArgsfile) {
// 计算文件 MD5
return new Promise((resolve) => {
const spark = new SparkMD5.ArrayBuffer();
const reader = new FileReader();
reader.readAsArrayBuffer(fArgsfile);
reader.onload = (e) => {
spark.append(e.target.result);
resolve(spark.end());
};
});
},
// 检查文件是否已存在(秒传逻辑)
checkFileExists(md5) {
return new Promise((resolve) => {
const data = {
fileMd5:md5,
parentId:this.parentId
}
fcheckFileExists(data).then(resp=>{
console.log("检查文件是否已存在",resp)
resolve(resp.data.data)
})
})
},
// 获取已上传分片(断点续传逻辑)
getUploadedChunks(md5) {
return new Promise((resolve) => {
const data = {
md5: md5
}
fgetUploadedChunks(data).then(resp=>{
console.log("获取数据库中已经上传分片",resp.data.data)
resolve(resp.data.data)
})
})
},
// 开始上传
async startUpload(md5,fChunks,fUploadedChunks,fileName,fFileType) {
const allChunkLength = fChunks.length;
for(let i=0;i<allChunkLength;i++){
console.log("是否需要继续上传",fUploadedChunks,fChunks[i].index)
if (!fUploadedChunks.includes(fChunks[i].index)) {
const formData = new FormData();
let formDataObj = {
chunkIndex:fChunks[i].index,
md5:md5
}
let sendData = JSON.stringify(formDataObj)
formData.append('dto',new Blob([sendData],{type:"application/json"}))
formData.append('chunkFile',fChunks[i].file)
const result = await this.fetchUploadedChunks(formData);
if(result=="error"){
this.$message.success('文件分片上传失败!');
return
}
console.log("上传分片成功",result)
fUploadedChunks.push(fChunks[i].index);
// 记录已上传分片
if (fUploadedChunks.length === fChunks.length) {
// 合并分片
this.mergeChunks(md5,fileName,fFileType);
}
}
}
},
fetchUploadedChunks(formData){
return new Promise((resolve,reject)=>{
fUploadedChunks(formData).then((resp)=>{
resolve(resp.data.data)
}).catch(err=>{
reject("error")
})
})
},
mergeChunks(md5,fileName,fFileType) {
const data = {
md5: md5,
fileType:fFileType,
parentId:this.parentId,
name: fileName,
}
fMergeChunks(data).then(resp=>{
console.log("分片合并成功",resp.data.data)
this.$message.success(fileName+'文件上传完成!');
})
},
}
}
</script>
<style scoped lang="scss">
</style>
前端接口
export function fcheckFileExists(obj) {
return request({
url: '/admin/recordfile/check-file',
method: 'post',
data: obj
})
}
export function fgetUploadedChunks(obj) {
return request({
url: '/admin/recordfile/get-uploaded-chunks',
method: 'post',
data: obj
})
}
export function fUploadedChunks(obj) {
return request({
url: '/admin/recordfile/upload-chunk',
method: 'post',
data: obj
})
}
export function fMergeChunks(obj) {
return request({
url: '/admin/recordfile/merge-chunks',
method: 'post',
data: obj
})
}
后端
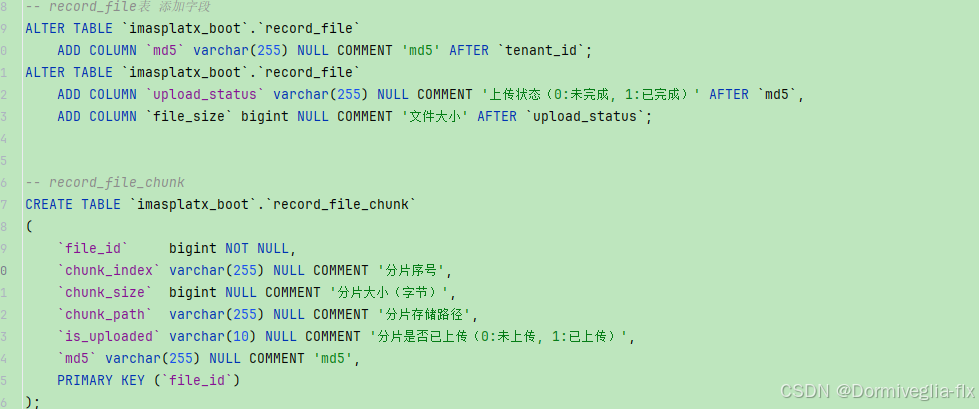
//============= 分片上传 ================
@PostMapping("/check-file")
public R<Boolean> checkFileExists(@RequestBody Map<String, String> request) {
String fileMd5 = request.get("fileMd5");
String parentId = request.get("parentId");
QueryWrapper<RecordFile> q = new QueryWrapper<>();
q.eq("md5",fileMd5);
RecordFile recordFile = recordFileService.getOne(q);
if (recordFile != null && Objects.equals(recordFile.getUploadStatus(), "1")) {
// 文件已存在且已完成上传
if(Long.parseLong(parentId)!=recordFile.getParentId()){
RecordFile recordFile1 = new RecordFile();
recordFile1.setName(recordFile.getName());
recordFile1.setParentId(Long.parseLong(parentId));
recordFile1.setPath(recordFile.getPath());
recordFile1.setType("file");
recordFile1.setFileType("upload");
recordFile1.setUploadStatus("1");
recordFileService.save(recordFile1);
}
return R.ok(Boolean.TRUE);
}
// 如果文件不存在,则创建新的文件记录,并设置初始状态为未完成
if (recordFile == null) {
recordFile = new RecordFile();
recordFile.setMd5(fileMd5);
recordFile.setUploadStatus("0"); // 设置初始状态为未完成
recordFileService.save(recordFile);
}
// 文件不存在或未完成上传
return R.ok(Boolean.FALSE);
}
@PostMapping("/get-uploaded-chunks")
public R<List<String>> getUploadedChunks(@RequestBody Map<String, String> request) {
String md5 = request.get("md5");
QueryWrapper<RecordFileChunk> q = new QueryWrapper<>();
q.eq("md5",md5);
List<RecordFileChunk> chunks = recordFileChunkService.list(q);
List<String> uploadedChunkIndexes = chunks.stream()
.filter(chunk -> Objects.equals(chunk.getIsUploaded(), "1"))
.map(RecordFileChunk::getChunkIndex)
.collect(Collectors.toList());
return R.ok(uploadedChunkIndexes);
}
@PostMapping("/upload-chunk")
public R uploadChunk(@RequestPart("dto") RecordFileChunk recordFileChunk, @RequestPart(name = "chunkFile")MultipartFile file) {
if(file!=null){
R r = sysFileService.uploadFile222(file);
RecordFileChunk myRecordFileChunk = new RecordFileChunk();
myRecordFileChunk.setChunkPath((((Map<String, String>)r.getData()).get("url")));
myRecordFileChunk.setChunkSize(file.getSize());
myRecordFileChunk.setChunkIndex(recordFileChunk.getChunkIndex());
myRecordFileChunk.setMd5(recordFileChunk.getMd5());
myRecordFileChunk.setIsUploaded("1");
R.ok(recordFileChunkService.save(myRecordFileChunk));
return R.ok(Boolean.TRUE);
}else {
return R.ok(Boolean.FALSE);
}
}
@PostMapping("/merge-chunks")
public R mergeChunk(@RequestBody Map<String, String> request) {
String md5 = request.get("md5");
String fileType = request.get("fileType");
String parentId = request.get("parentId");
String myName = request.get("name");
QueryWrapper<RecordFileChunk> q = new QueryWrapper<>();
q.eq("md5",md5);
List<RecordFileChunk> chunks = recordFileChunkService.list(q);
List<RecordFileChunk> sortchunks = chunks.stream()
.sorted(Comparator.comparingInt(o -> Integer.parseInt(o.getChunkIndex())))
.collect(Collectors.toList());
String fileName = IdUtil.simpleUUID() + StrUtil.DOT + fileType;
String filePath = String.format("/admin/sys-file/%s/%s", properties.getBucketName(), fileName);
String var10000 = this.properties.getLocal().getBasePath();
String dir = var10000 + FileUtil.FILE_SEPARATOR + properties.getBucketName();
String MyUrl = dir + FileUtil.FILE_SEPARATOR + fileName;
try (FileOutputStream fos = new FileOutputStream(MyUrl)) {
// 遍历每个分片路径
for (RecordFileChunk chunkPath : sortchunks) {
try (FileInputStream fis = new FileInputStream(chunkPath.getChunkPath())) {
// 缓冲区大小
byte[] buffer = new byte[1024];
int length;
while ((length = fis.read(buffer)) > 0) {
// 将分片内容写入目标文件
fos.write(buffer, 0, length);
}
}
}
System.out.println("文件合并完成!");
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException("文件合并失败!", e);
}
QueryWrapper<RecordFile> q22 = new QueryWrapper<>();
q22.eq("md5",md5);
RecordFile fileInfo = recordFileService.getOne(q22);
if (fileInfo != null) {
fileInfo.setUploadStatus("1"); // 更新文件状态为已完成
fileInfo.setPath(filePath);
fileInfo.setType("file");
fileInfo.setFileType("upload");
fileInfo.setParentId(Long.valueOf(parentId));
fileInfo.setName(myName);
recordFileService.saveOrUpdate(fileInfo);
}
return R.ok();
}