一、开源ETL工具
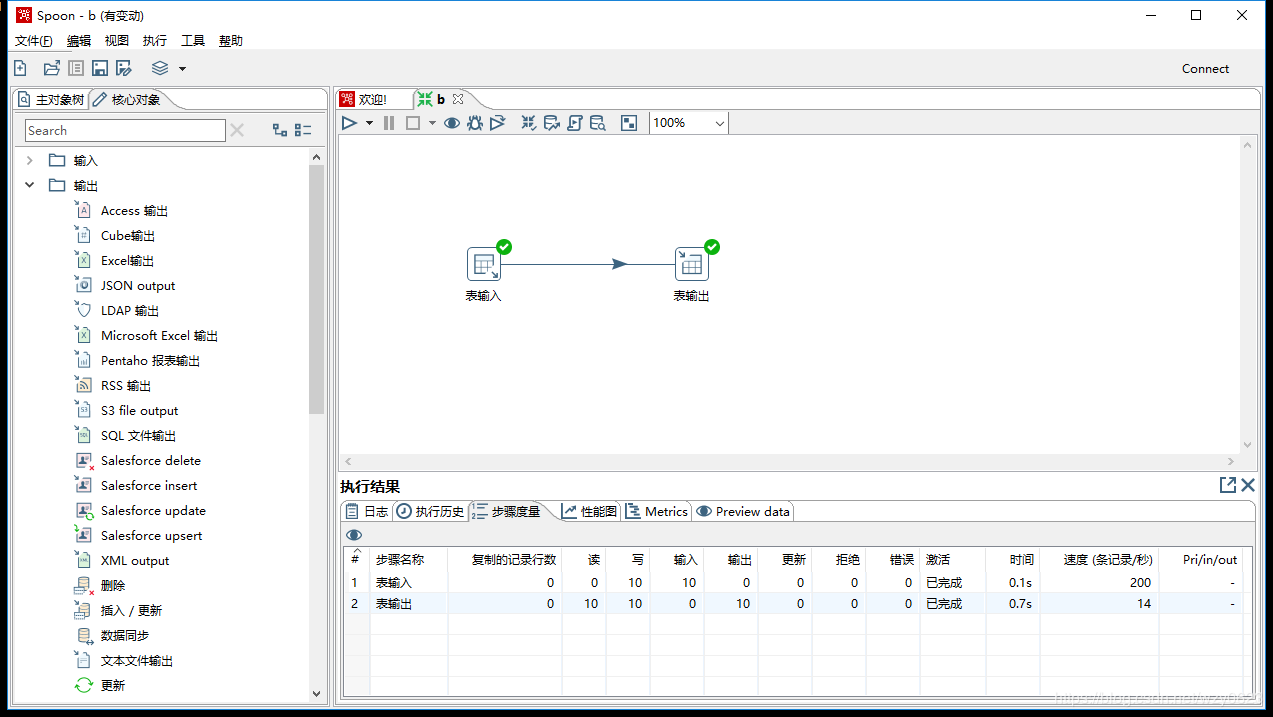
Kettle(Pentaho Data Integration)--Spoon
- 设计及架构:面向数据仓库建模的传统ETL工具。
- 使用方式:C/S客户端模式,开发和生产环境需要独立部署,任务编写、调试、修改都在本地。
- 底层架构:主从结构非高可用,扩展性差,不适用大数据场景。
- 特点:基于Java开发,提供可视化界面(Spoon),支持跨平台部署;插件丰富,适合中小规模数据处理。
- 局限性:处理海量数据时性能不足,调度管理依赖外部系统,缺乏高可用架构。
- 适用场景:预算有限的中小企业、传统数据仓库开发。
kettle源代码工程:https://github.com/pentaho/pentaho-kettle
kettle 通用插件 :kettlePlugins: kettle通用插件,通过json配置文件实现自定义插件的开发。
kettle 大数据插件: https://github.com/pentaho/big-data-plugin
kettle 帮助文档:Pentaho Javadoc
DataX

- 设计及架构:面向数据仓库建模的传统ETL工具。
- 使用方式:DataX是以脚本的方式执行任务的,需要完全吃透源码才可以调用。
- 特点:DataX为阿里巴巴开源的异构数据同步工具。
DataX源代码工程:https://github.com/alibaba/DataX
DataX 使用帮助: https://github.com/alibaba/DataX/blob/master/userGuid.md
DataX 图形工具: https://github.com/WeiYe-Jing/datax-web
Sqoop
- 特点:专注于数据库与Hadoop生态间的批量数据传输;Sqoop支持Hadoop与关系型数据库交互
- 适用场景:大数据平台(如Hive、HDFS)的离线数据迁移。
Sqoop官方网址: Sqoop - --- 已退休,集成到了hadoop中。
Sqoop源代码工程: https://github.com/apache/sqoop
Hadoop Apache Hadoop
二:商业ETL工具
Informatica

- 设计及架构:面向数据仓库建模的传统ETL工具。
- 使用方式:C/S客户端模式,学习成本较高,一般需要受过专业培训的工程师才能使用。
- 特点:企业级数据集成平台,支持复杂数据治理、实时流处理及云原生架构;内置数据质量管理模块,适合高复杂度场景。
- 缺点:成本高,学习门槛较高。
Informatica 官方网址: AI Powered Cloud Data Management | Informatica
FineDataLink
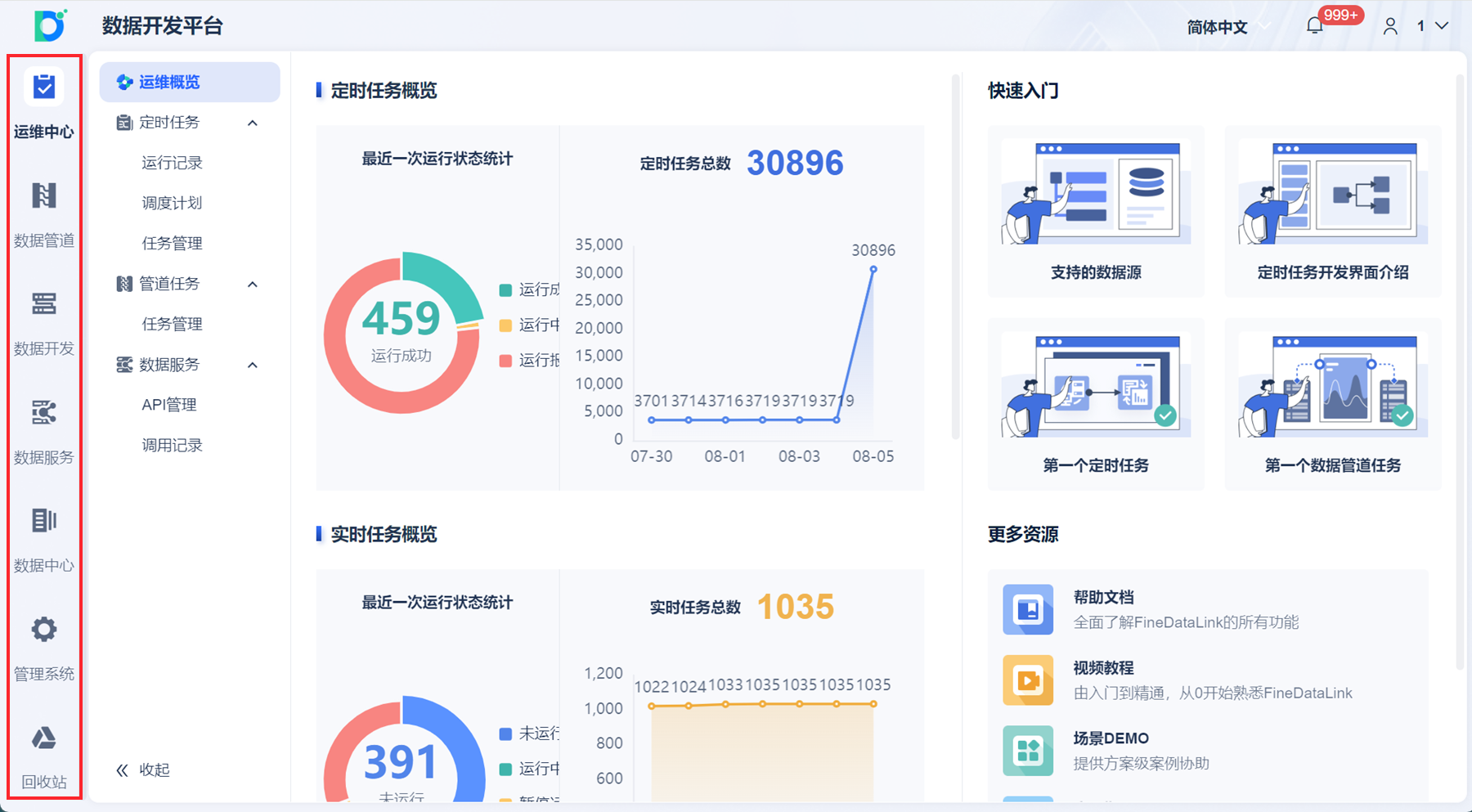
- 特点:低代码操作界面,支持ETL/ELT混合模式;实时增量同步(基于CDC技术)与批量处理结合,与帆软BI工具无缝集成。
- 优势:简化流程设计,适应快速迭代的实时分析需求。
FineDataLink 帮助文档(英文): FineDataLink产品首页- FineDataLink Help Document
FineDataLink 帮助文档(中文):入门指南- FineDataLink帮助文档
DataStage
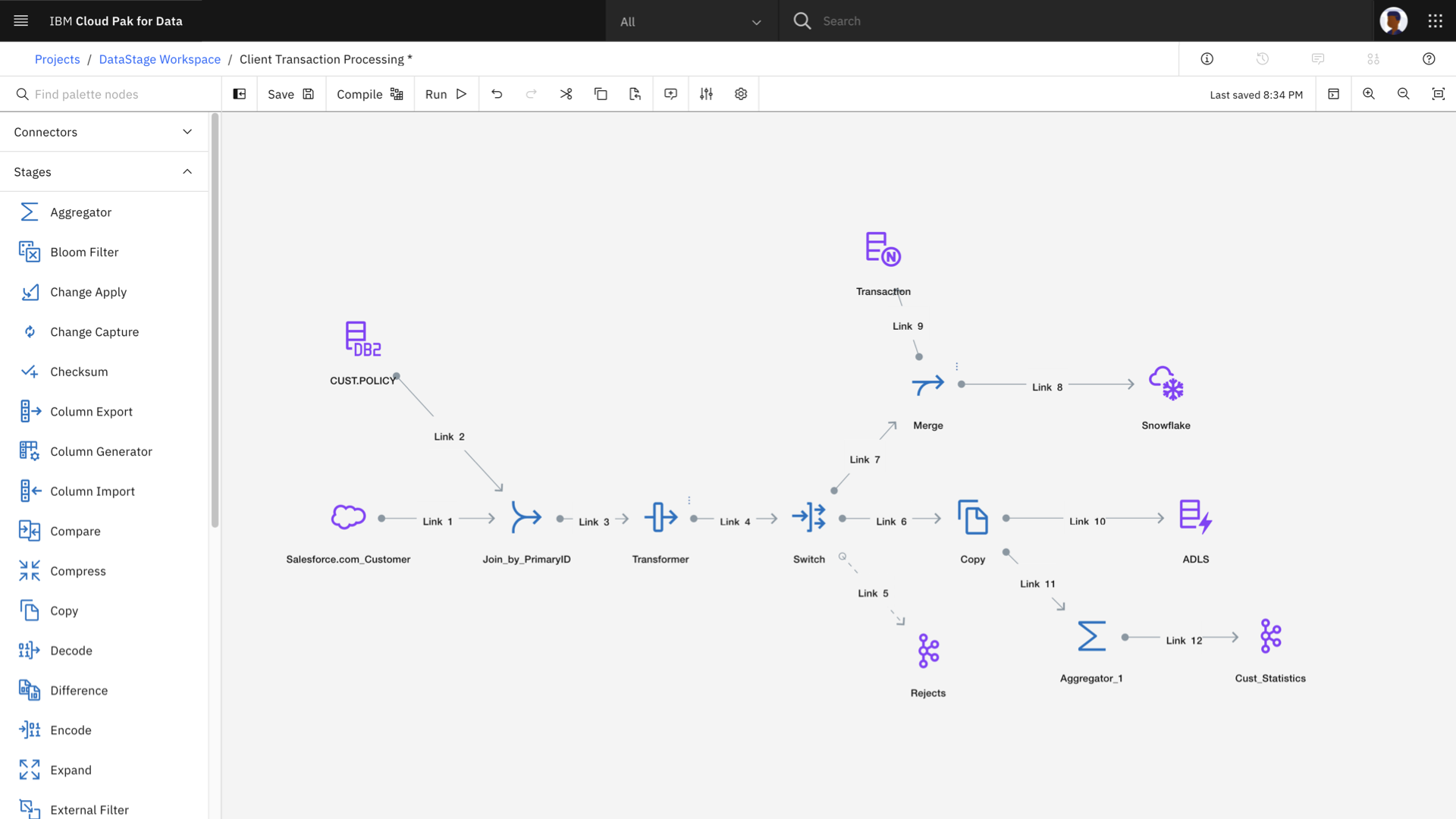
- DataStage支持大规模并行处理,但缺乏图形化开发灵活性。
DataStage 官方文档:IBM Documentation
Oracle GoldenGate
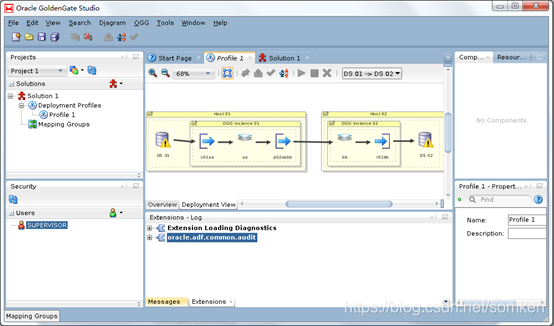
- 设计及架构:主要用于数据备份、容灾。
- 使用方式:没有图形化界面,操作皆为命令行方式,可配置能力差。
- 底层架构:可做集群部署,依赖于外部环境,如Oracle RAC等。
- GoldenGate专注实时数据复制与容灾,命令行操作
Oracle GoldenGate(OGG)是一款用于数据复制、数据整合、数据同步和事务捕获的工具,它支持多种数据库系统之间的数据同步。Oracle GoldenGate Studio是OGG的图形用户界面(GUI)组件,它提供了一个可视化的方式来设计、管理和监控数据复制解决方案
Oracle GoldenGate 下载试用: Download GoldenGate Free | Oracle Singapore
Oracle GoldenGate Studio 官方下载地址: Oracle GoldenGate Downloads
三:云原生与分布式工具
DataPipeline
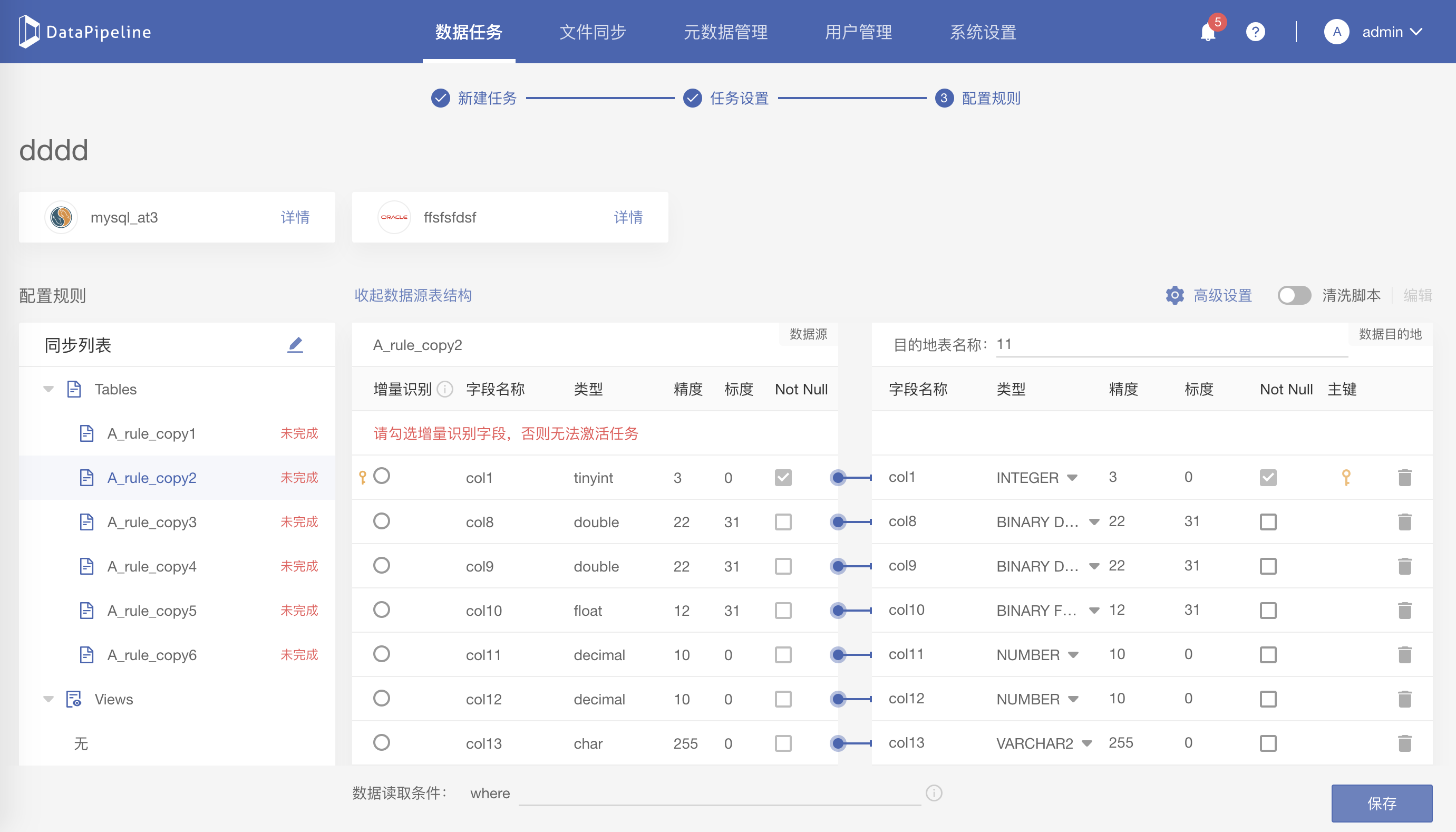
- 设计及架构:专为超大数据量、高度复杂的数据链路设计的灵活、可扩展的数据交换平台。
- 使用方式:全流程图形化界面,Cloud Native架构,所有操作在浏览器内完成,无需额外开发。
- 底层架构:分布式集群高可用架构,自动调节任务在节点间分配,适用于大数据场景
- 特点:浏览器端全流程图形化开发,分布式集群架构自动分配任务;专为超大数据量设计,适合混合云环境。
- 优势:高扩展性,支持复杂数据链路和自动化运维。
DataPipeLine官方网站:DataPipeline数见科技-定义基于DataOps理念的下一代数据基础设施
Talend
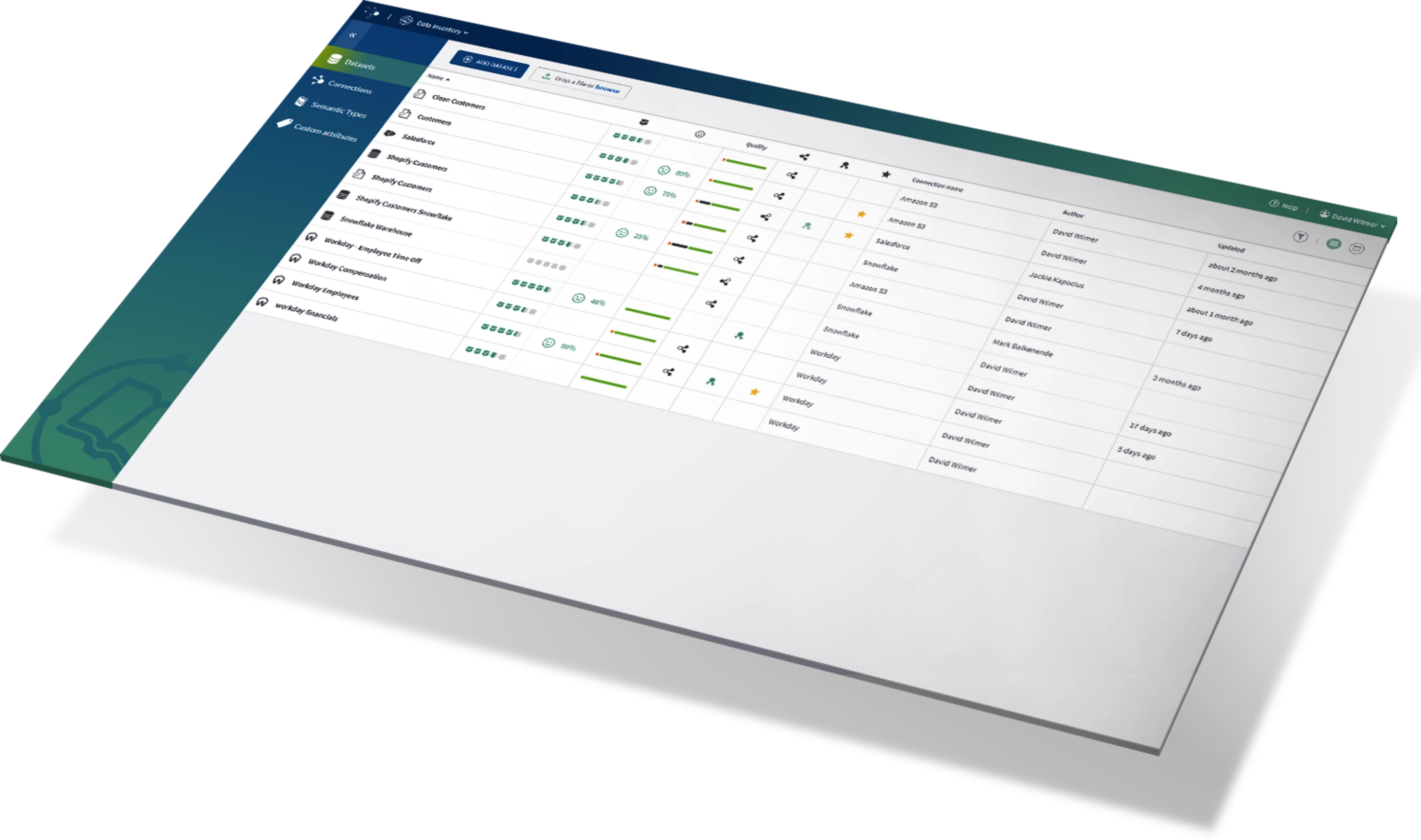
- 设计及架构:面向数据仓库建模的传统ETL工具。
- 使用方式:C/S客户端模式,开发和生产环境需要独立部署
- 特点:开源与商业版本并存,提供数据清洗、机器学习集成功能;支持多云部署,适合中大型企业。
Talend官方网站: https://www.talend.com/
Talend 白皮书: https://www.talend.com/resources/?type=White%20papers%20and%20ebooks
四:选型建议
数据规模与时效性
- 批量处理:Kettle、DataX;
- 实时同步:FineDataLink、Informatica。
企业需求与成本
- 低成本开源:Kettle(Spoon)、Sqoop;
- 企业级功能:Informatica、DataPipeline。
技术生态
- Hadoop集成:Sqoop、DataX;
- BI工具协同:FineDataLink(帆软生态)。
五:发展趋势
ELT模式普及:依赖目标数据库的计算能力(如Snowflake、BigQuery),减少转换阶段资源消耗。
低代码与自动化:工具趋向简化开发流程,提升非技术用户参与度(如FineDataLink、DataPipeline)。




![每日一题洛谷P8649 [蓝桥杯 2017 省 B] k 倍区间c++](https://i-blog.csdnimg.cn/direct/fd17fb358bdf4ce2bac05457902556ba.jpeg)