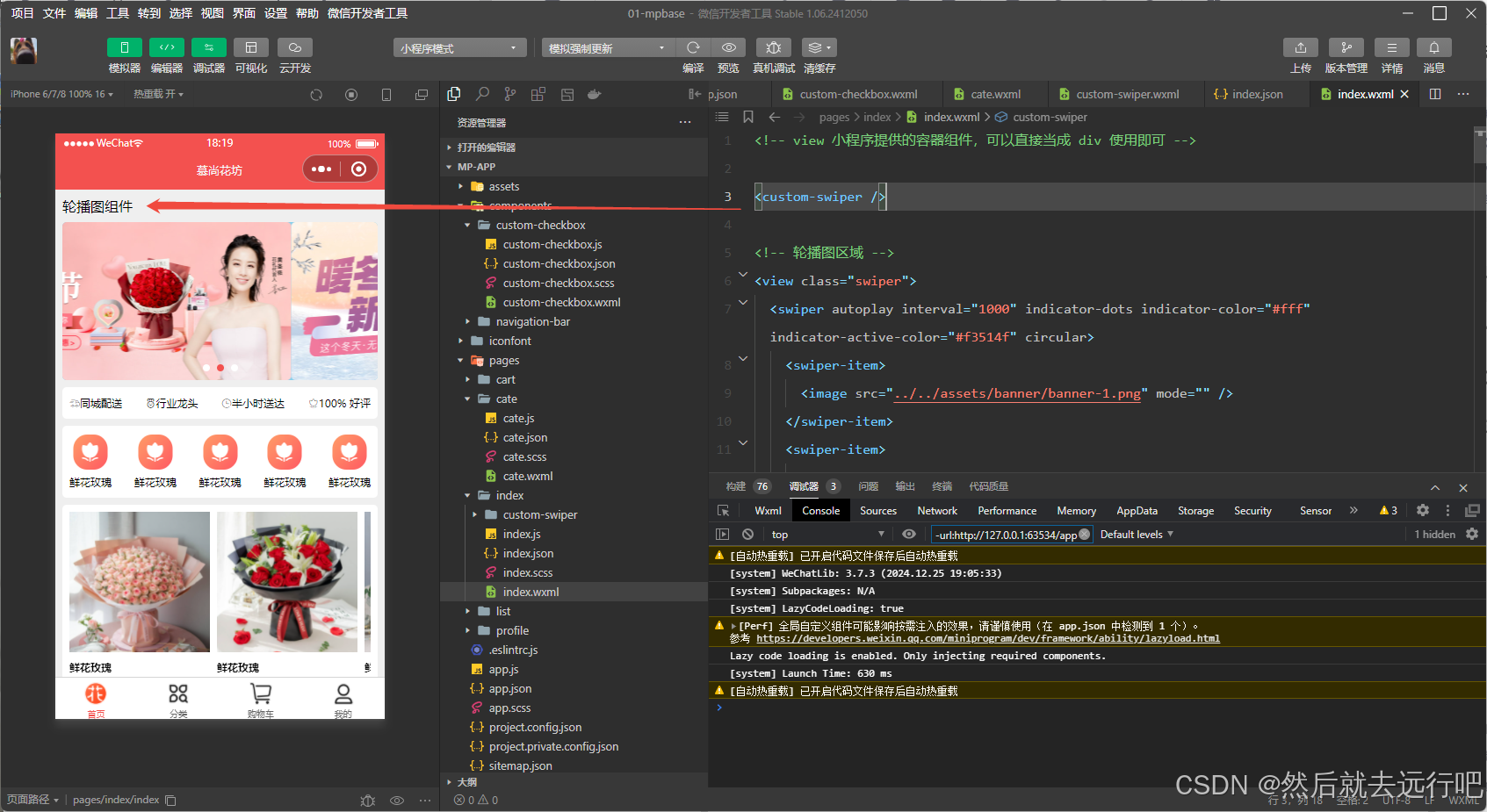
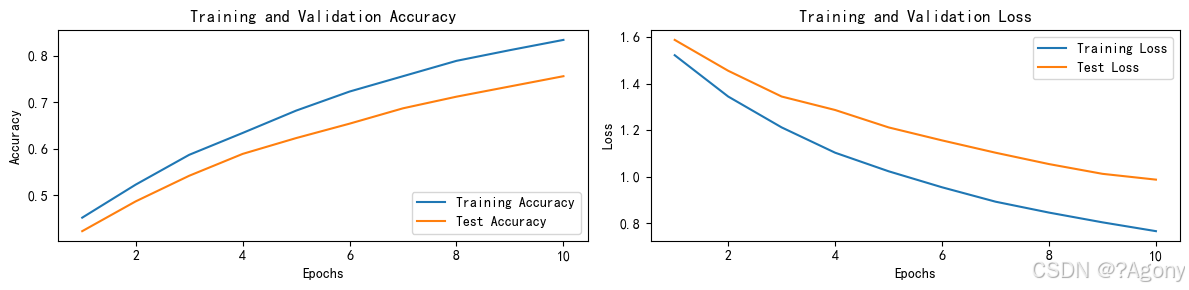
awk 是 Linux/Unix 系统中一个强大的文本处理工具,尤其擅长处理结构化文本数据(如日志、表格数据)。它不仅是命令行工具,还是一种脚本语言,支持变量、条件、循环等编程特性
1. 基本语法
awk [选项] '模式 {动作}' 文件名
-
模式(Pattern):决定何时执行动作(如行号、正则匹配)。
-
动作(Action):对匹配的行执行的操作(如打印、计算)。
2. 核心概念
内置变量
| 变量 | 说明 |
|---|---|
$0 | 当前整行内容 |
$1, $2 | 第1列、第2列(默认以空格分隔) |
NR | 当前行号(从1开始) |
NF | 当前行的列数 |
FS | 输入字段分隔符(默认空格) |
OFS | 输出字段分隔符(默认空格) |
FILENAME | 当前处理的文件名 |
常用选项
-
-F:指定输入字段分隔符(如-F':'以冒号分隔)。 -
-v:定义变量(如-v var=value)。
3. 经典用法示例
提取特定列
# 提取文件的第一列和第三列
awk '{print $1, $3}' a.txt# 输出时用分号分隔列
awk '{print $1 ";" $3}' a.txt

过滤行
# 打印第二列大于50的行
awk '$2 > 50 {print $0}' data.txt# 打印包含 "error" 的行(不区分大小写)
awk '/error/i {print}' log.txt
跳过标题行
# 从第二行开始处理(常用于CSV)
awk 'NR > 1 {print $1, $2}' data.csv
计算列总和
# 计算第一列的总和
awk '{sum += $1} END {print sum}' numbers.txt
BEGIN 和 END 块
-
BEGIN:在处理输入前执行(如初始化变量)。 -
END:在处理完所有行后执行(如输出统计结果)
# 统计文件行数并计算平均值
awk '
BEGIN {sum = 0; count = 0}
NR == 1 {next} # 遇到第一行直接跳到下一行
{sum += $1; count++}
END {print "Average:", sum/count}
' test01.txt 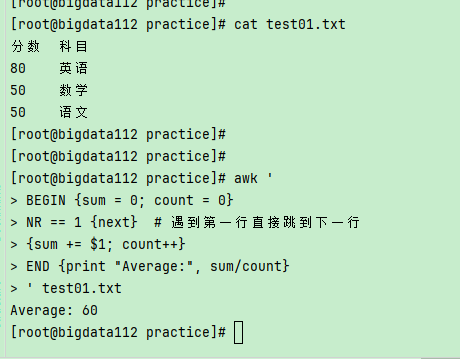
条件语句与循环
# 根据条件处理不同列
awk '{
if ($1 > 100)
print "High:", $0
else
print "Low:", $0
}' values.txt
# 遍历所有列并打印偶数位置的值
awk '{for (i=1; i<=NF; i++) if (i%2==0) print $i}' file.txt自定义分隔符
# 根据条件处理不同列
awk '{
if ($1 > 100)
print "High:", $0
else
print "Low:", $0
}' values.txt
# 遍历所有列并打印偶数位置的值
awk '{for (i=1; i<=NF; i++) if (i%2==0) print $i}' file.txt关联数组(哈希表)
# 统计每列值的出现次数
awk '{count[$1]++} END {for (key in count) print key, count[key]}' data.txt4. 与 cut/sed 的区别
| 工具 | 核心用途 | 优势场景 |
|---|---|---|
cut | 按列切割简单文本 | 快速提取固定列 |
sed | 流编辑(替换、删除、插入) | 基于行的文本替换和过滤 |
awk | 结构化文本处理、计算、统计 | 复杂字段处理、编程逻辑集成 |
5. 学习资源
-
官方文档:GNU Awk User’s Guide
-
在线教程:
awk30分钟入门(链接) -
书籍推荐:《Effective Awk Programming》


![每日一题洛谷P8649 [蓝桥杯 2017 省 B] k 倍区间c++](https://i-blog.csdnimg.cn/direct/fd17fb358bdf4ce2bac05457902556ba.jpeg)