参考资料:学习R
数据的来源可以由很多。R内置有许多数据集,而在其他的附件包中能找到更多的数据。R能从各式各样的来源中读取,且支持大量的文件格式。
1、内置的数据集
R的基本分发包有一个datasets,里面全是示例数据集。很多其他包也含有数据集。使用data函数可以查看所有我们已成功加载了的包的数据集:

如果需要更完整的列表,包括已安装的所有包的数据,可以使用
data(package=.packages(TRUE))

如果我们想访问任意数据集里的数据,只需调用data函数,传入数据集的名称及其所在的包名(如果此包已经加载,可省略这个packages参数)
data("kidney",package="survival")
2、读取文本文件
有众多的格式和文本文件标准可用于存储数据。用于存储数据的通用格式为分隔符(即CSV或制表符分隔文件)、可扩展标记语言(XML)、JavaScript对象表示法(JSON)和YAML。
将数据存储在文本文件中的主要优点是:它们可被几乎所有的其他数据分析软件读取。
(1)CSV和制表符分隔(Tab-Delimited)文件
矩形(类似电子表格的) 数据通常存储在带有分隔符的文件中, 特别是逗号分隔值(CSV)和制表符分隔值文件。read.table函数将读取这些分隔符文件,并将结果存储在一个数据框中。
RedDeerEndocranialVolume.dlm 是一个以空格符分隔的文件, 它包含了一些使用不同技术
测量得到的马鹿的颅容积数据。数据文件可以在 learningr 包的extdata文件夹中找到。该数据有标题行,所以我们需要给read.table传递参数header=TRUE。因为并不是每次都会进行二次测量,所以不是所有行都是完整的。给read.table传递参数fill=TRUE会使用NA值来代替那些缺失的域。下例中的system.file函数用于定位包中的文件。
install.packages("learningr")
library(learningr)
deer_file<-system.file(
"extdata",
"RedDeerEndocranialVolume.dlm",
package="learningr"
)
deer_data<-read.table(deer_file,header=TRUE,fill=TRUE)
str(deer_data,vec.len=1)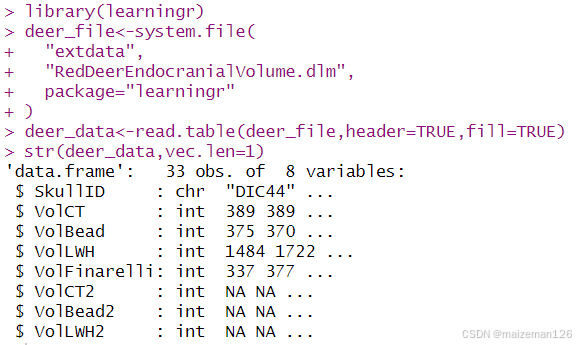
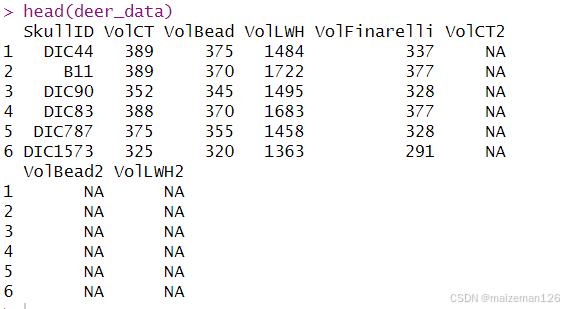
注意, 每个列的类已自动确定, 行和列的名字也已自动分配。 列名( 默认情况下) 必须是有效的变量名(通过使用 make.names), 如果不提供行名那么行将就会按 1、 2、 3 编号,以此类推。
有很多参数可以用来指定如何读取该文件,其中最重要的是sep参数,它决定了使用哪个字符作为字段之间的分隔符。nrow可以指定读取数据的行数,而skip决定跳过文件开始的多少行。更多高级选项包括:覆盖默认的行名、列名和类,指定输入文字的字符编码,以及输入的字符串格式的列如何声明。
有几个read.table的包装函数使用起来比较方便。read.csv分隔符默认设置为逗号,并假设数据有标题行。read.csv2使用逗号作为小数位,并用分号作为分隔符。read.delim和read.delim2将分别使用句号和逗号作为小数位来导入制表符分隔的文件。
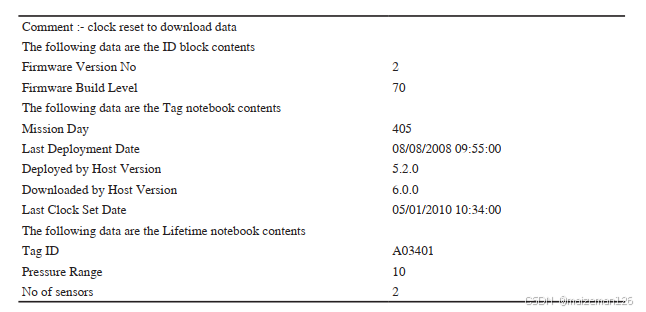
在上图这种情况,我们不能仅调用read.csv就把所有东西都读出来,因为不同的数据块中所含有的字段数量不同,而且每个字段也确实不同。我们需要使用read.csv中的skip和nrow参数指定要读取文件中的哪些位置:
crab_file<-system.file(
"extdata",
"crabtag.csv",
package="learningr"
)
crab_id_block<-read.csv(
crab_file,
header=FALSE,
skip=3,
nrow=2
)
print(crab_id_block)
crab_lifetiem_notebook<-read.csv(
crab_file,
header=FALSE,
skip=8,
nrow=5
)
print(crab_lifetiem_notebook)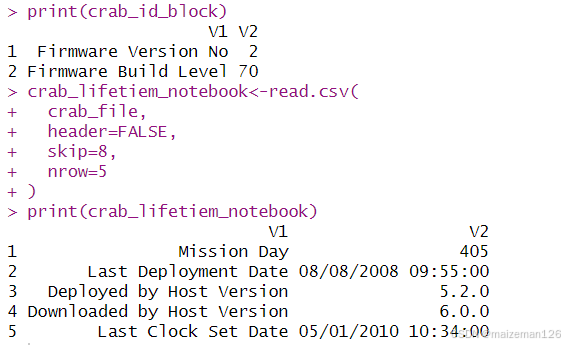
如果我们的数据是从另一种语言中导入的,那么可能需要把na.strings参数传递给read.table。对于SQL导出的数据,则使用na.string="NULL"。对于SAS或Stata导出的数据,则需要使用na.strings="."。从Excel中导出的数据,使用na.string=c("","#N/A","#DIV/0!","#NUM")。
写入文件通常比读取文件要简单,因为我们无需担心读取文件时出现各种问题。很显然,write.table和write.csv分别对应着read.table和read.csv的读操作。这两个函数都需要一个数据框和写入文件的路径作为参数。
write.csv(
crab_id_block,
"Data/Cleaned/id_block_data.csv",
row.names=FALSE,
fileEncoding = "utf8"
)(2)非结构化文本文件
不是所有的文本文件都像都像定界符文件那样有一个定义良好的而结构。如果文件的结构松散,更简单的做法是:先读入文件中的所有文本行,再对其内容进行分析或操作。readLines就提供了这种方法。它接受一个文件路径(或文件连接)和一个可选的最大行数作为参数来读取文件。
text_file<-system.file(
"extdata",
"Shakespeare's The Tempest, from Project Gutenberg pg2235.txt",
package="learningr"
)
the_tempest<-readLines(text_file)
the_tempest[19:20]
help(readLines)writeLines用于执行与readLines相反的操作。它写入文件时需要一个字符向量和文件作为输入参数:
writeLines(
rev(text_file), # rev执行向量的反操作
"name.txt"
)(3)XML和HTML文件
当我们导入一个XML文件时,XML包(需安装并加载)将提供两种选择以存储结果:利用内部节点,或使用R节点。通常,我们应该使用内部节点来存储,因为这样我们能使用XPath来查询节点树。
有几个函数可以用于导入XML数据,如xmlParse:
library(XML)
xml_file<-system.file(
"extdata",
"options.xml",
package="learningr"
)
r_options<-xmlParse(xml_file)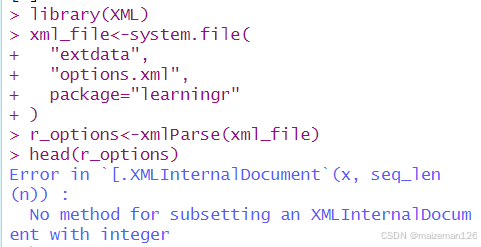
如上图所示,使用内部节点的问题是:str和head等汇总函数不能和它们一起使用。要使用R级的节点,需设置useInternalNodes=FALSE(或使用xmlTreeParse,它会默认设置此项属性)
xmlParse(xml_file,useInternalNodes = FALSE)
xmlTreeParse(xml_file)
XPath是一种用于查询XML文档的语言,它能基于某些过滤规则寻找相应的节点。下例中,我们将在文档//中寻找命名为variable的节点,此节点[]的name属性@包含contains了warn字符串。
library(XML)
xml_file<-system.file(
"extdata",
"options.xml",
package="learningr"
)
r_options<-xmlParse(xml_file)
xpathSApply(r_options,"//variable[contains(@name,'warn')]")

这种查询在提取网页数据中非常有用。htmlParse和htmlTreeParse是用于HTML页面导入的函数。
(4)JSON和YAML文件
XML 的主要问题是它太冗长了,且你需要显式地指定数据的类型(它在默认情况下不能区分字符串和数字),这就使得它更冗长了。如果文件大小很重要(例如,当你要在网络上传输大量数据集时),信息过于冗余就成了问题。于是,有人发明了YAML和它的子集JSON来解决这些问题。它们特别适合于通过网络传输大量数据集,尤其是数字数据和数组。JSON是Web应用程序彼此之间传递数据的事实标准。
有两个包可用于处理JSON数据:RJSONIO和rjson。在读入不正确的JSON时,RJSONIO一般比rjson更宽容。在这两个包中读取和写入JSON数据的函数名基本相同,所以很容易在它们之间
换。在下例中,双冒号 :: 用于把相同名字的函数从不同的包中分别出来(如果只加载两个包中的一个, 就不需要双冒号)。
install.packages(c("RJSONIO","rjson"))
library(RJSONIO)
library(rjson)
jamaican_city_file<-system.file(
"extdata",
"Jamaican Cities.json",
package="learningr"
)
jamaican_ctiy_RJSONIO<-rjson::fromJSON(jamaican_city_file)
print(jamaican_ctiy_RJSONIO)JSON的规范不允许无穷值或 NaN 值,而且它对缺失数的定义比较模糊。这两个包处理这些值的方式有所不同:RJSONIO 把 NaN 和 NA 映射为 JSON 的 null,但保留正负无穷;而 rjson 会把所有这些值都转换为字符串。
special_numbers<-c(NaN,NA,Inf,-Inf)
RJSONIO::toJSON(special_numbers)
rjson::toJSON(special_numbers)
因为这两种方法都用于处理备受限制的JSON规范,所以如果你发现需要大量地处理这些特殊数字类型(或想在你的数据对象中加些评论),那么最好还是使用YAML。在yaml包中有两个函数能导入YAML数据:yaml.load接受一个YAML的字符串,并将其转换为一个R对象;yaml.load_file 也一样,不过它把输入的字符串作为包含 YAML 文件的路径处理。这里不再展示。

![每日一题洛谷P8649 [蓝桥杯 2017 省 B] k 倍区间c++](https://i-blog.csdnimg.cn/direct/fd17fb358bdf4ce2bac05457902556ba.jpeg)