爱的故事.上集
- 1. Java 基础
- 1.1 常用集合数据结构 Array List Map Set Tree
- 1.1.1 常用集合在JDK中的结构
- 1.1.2 List 底层是数组
- 1.1.3 Map键值对结存储结构
- 1.1.3.1 为什么HashMap的Key、Value都允许为 null
- 1.1.3.2 为什么ConcurrentHashMap的Key、Value都不允许为null
- 1.1.3.3 HashMap 扩容机制
- 1.1.3.4 哈希表的容量为什么推荐2的幂次方
- 1.1.3.5 HashMap 死链问题
- 1.1.4 Set 不允许元素重复
- 1.1.5 Tree 树结构
- 1.1.6 JUC包
- 1.1.6.1 Native API
- 1.1.6.2 CAS的原子性、无锁算法、缓存一致性、ABA问题
- 1.1.6.3 java.util.concurrent.atomic包
- 1.1.6.4 java.util.concurrent.locks包
- 1.1.6.5 java.util.concurrent包重要工具
- 1.2 基础算法:排序算法、二分算法、银行家算法、一致性哈希算法
- 1.2.1 排序算法
- 1.2.2 二分查找算法
- 1.2.3 银行家算法
- 1.2.4 一致性哈希算法
- 1.3 Thread
- 1.4 代理、反射、流操作、Netty
- 1.4.1 代理
- 1.4.2 反射
- 1.4.3 IO 输入输出
- 1.4.3.1 字节流
- 1.4.3.2 字符流
- 1.4.3.3 NIO(New I/O)、BIO
- 1.4.3.4 Serializable 序列化
- 1.4.3.5 Netty
- 1.5 三次握手、四次挥手
- 1.5.1 三次握手
- 1.5.2 四次挥手
- 1.6 JVM 原理
- 1.6.1 内存模型
- 1.6.2 垃圾回收算法
- 1.6.3 垃圾回收器
- 1.6.4 类加载
- 1.6.5 双亲委派模型
- 1.6.6 JVM调优
- 1.7 基础编程规约
- 2. MySQL 数据库、Oracle、Redis、NoSQL、ShardingSphere
- 2.1 MySQL
- 2.1.1 数据库引擎
- 2.1.2 MySQL 数据量瓶颈
- 2.1.3 索引
- 2.1.4 SQL 执行过程
- 2.1.5 Explain 语句执行计划分析
- 2.1.6 索引失效的情况
- 2.1.7 SQL优化
- 2.1.8 MySQL 锁机制
- 2.1.9 悲观锁、乐观锁
- 2.1.10 Binlog
- 2.1.11 主从同步
- 2.1.11.1 一个主库两个从库配置参考
- 2.1.11.2 主从同步延迟
- 2.1.11.3 数据一致性问题
- 2.1.11.4 同步中断及恢复
- 2.1.11.5 性能瓶颈
- 2.1.12 MySQL 高级用法
- 2.1.13 慢 SQL 定位
- 2.2 Oracle
- 2.2.1 架构特性
- 2.3 Redis
- 2.3.1 为什么Redis速度很快
- 2.3.2 基本数据类型 String List Set Zset Hash
- 2.3.3 持久化方式 AOF、RDB
- 2.3.4 缓存穿透、缓存雪崩、缓存击穿
- 2.3.5 布隆过滤器
- 2.3.6 并发一致性问题
- 2.3.7 Redis 删除策略
- 2.3.8 Redis 集群
- 2.3.8.1 配置集群
- 2.3.8.2 Proxy+Replication+Sentinel
- 2.3.8.3 Redis Cluster 集群
- 2.3.9 Redis 分布式锁
- 2.3.10 无阻塞取值 scan、keys
- 2.3.11 Redis 命令
- 2.3.12 Redis 持久化扩容与缓存扩容
- 2.4 ShardingSphere
- 2.4.1 分库分表
- 2.4.2 ShardingSphere
- 2.4.2.1 特性
- 2.4.2.2 具体案例
- 2.4.2.3 其他公司解决方案
- 2.4.2.4 熔断限流
- 2.4.2.5 分片键
- 2.4.2.6 分片算法
- 2.4.2.7 分片策略
- 2.4.2.8 逻辑表、真实表、单表
- 2.4.2.9 负责均衡算法
- 2.4.2.10 数据库兼容性问题
- 2.4.2.11 分布式事务
- 2.4.2.12 读写分离、主从同步
- 3. Spring 框架、SpringBoot、SpringCLoud、Dubbo
- 3.1 Spring
- 3.1.1 事务管理
- 3.1.2 声明式事务失效场景
- 3.1.3 Spring 常用注解
- 3.1.4 SpringMVC 常用注解
- 3.1.5 SpringBoot 常用注解
- 3.1.6 SpringCloud 常用注解
- 3.2 SpringMVC
- 3.3 SpringBoot
- 3.3.1 特征
- 3.3.2 集成中间件
- 3.3.3 SpringBoot 自动装载原理
- 3.4 SpringCloud
- 3.4.1 微服务面临问题
- 3.4.2 SpringCloud 核心组件
- 3.4.3 Ribbon 负载均衡
- 3.4.4 Feign 声明性 rest 客户端
- 3.4.5 Zuul/GateWay 服务网关
- 3.4.6 Hystrix 断路器
- 3.4.7 SpringCloud Config 配置中心
- 3.4.8 SpringCloud Eureka 服务注册发现
- 3.4.9 SpringCloud Bus 消息总线
- 3.4 Dubbo
- 3.4.1 RPC
- 3.4.2 Dubbo
- 4. 持久层框架Mybatis、JFinal、Heibernate
- 4.1 MyBatis
- 4.1.1 原理
- 4.1.2 SQL 注入
- 4.1.3 分库分表历史表清除方案
- 4.1.4 二级缓存
- 4.1.5 一对一、一对多关系 association
- 4.1.6 Mybatis是如何分页
- 4.2 JFinal
- 4.3 Heibernate
- 4.3.1 原理
- 4.3.2 延迟加载 lazy
- 4.3.3 状态转换
- 4.3.4 缓存机制
- 4.3.5 缓存策略
- 4.3.6 一对一、一对多关系
- 4.3.7 检索策略
1. Java 基础
1.1 常用集合数据结构 Array List Map Set Tree
基础规范:任何数据结构的构造或初始化,都应指定大小
1.1.1 常用集合在JDK中的结构
Collection
├List
│├LinkedList 链表集合
│├ArrayList 数组集合
│└Vector 线程安全数组,基于虚拟机并发控制 synchronized
│ └Stack 后进先出堆栈
└Set 不允许重复元素
├HashSet
└TreeSet 排序后的 set 按照升序排列
Map
├Hashtable 线程安全集合,基于虚拟机并发控制 synchronized
├HashMap
└WeakHashMap 对键值弱引用,键值不再被外部引用,允许被 GC 回收
1.1.2 List 底层是数组
ArrayList 底层是数组。
- ArrayList的add()方法
transient Object[] elementData;
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
1.1.3 Map键值对结存储结构
Map的Key/Value为空分析及线程安全性
| 集合类 | Key | Value | Super | 说明 |
|---|---|---|---|---|
| HashMap | 允许为 null | 允许为 null | AbstractMap | 线程不安全 |
| ConcurrentHashMap | 不允许为 null | 不允许为 null | AbstractMap | 线程安全、锁分段技术(JDK8:CAS) |
| Hashtable | 不允许为 null | 不允许为 null | Dictionary | 线程安全、重量级锁synchronized |
| TreeMap | 不允许为 null | 允许为 null | AbstractMap | 线程不安全 |
1.1.3.1 为什么HashMap的Key、Value都允许为 null
- HashMap的基础结构静态内部类Node<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
...
}
- HashMap的put()方法
transient Node<K,V>[] table;
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
...
...
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
(1)灵活性
历史设计原因,允许为null,使得Map结构在实际应用中更加灵活。是有一定的合理性,比如避免了频繁的处理NPE(NullPointerException )异常。
(2)put()方法
put()方法内部求hash没有用Object.hashCode()方法实现。也没有做判空处理,允许键值为空,但仅允许一个键为null,可允许多个value为null,因为键唯一。
1.1.3.2 为什么ConcurrentHashMap的Key、Value都不允许为null
ConcurrentHashMap的Key、Value都不允许为null的二义性问题
- ConcurrentHashMap的基础结构静态内部类Node<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
...
...
}
- ConcurrentHashMap的containsKey()方法
public boolean containsKey(Object key) {
return get(key) != null;
}
(1)当使用containskey(),如果允许键值为空,就会获取到结果为null,但是此时我们不知道值是否真的存在于集合中。
(2)在并发场景下,一个线程读取到真实存在的null,移除元素后,然后另一个线程再去读取,无法判断集合是否是包含该对象。
- ConcurrentHashMap的put()方法
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
...
...
}
put方法内部,当键值为null直接就会抛异常。
(1)值没有在集合中,所以返回的结果就是 null (空);
(2)值就是 null(空),所以返回的结果就是它原本的 null(空) 值
1.1.3.3 HashMap 扩容机制
新的容量通常是当前容量的两倍。
- HashMap的扩容算法resize()方法
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) {
newThr = oldThr << 1; // double threshold
}
} else if (oldThr > 0) {
newCap = oldThr;
} else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
...
...
}
(1)在HashMap中,当存储的键值对数量达到,当前容量(CAPACITY)和加载因子(LOAD_FACTOR)的乘积时,触发扩容。
(2)初始容量默认值为 16。它是 2 的幂次方数,这有助于提高哈希计算效率。
(3)扩容时,新的容量通常是当前容量的两倍。依然是2的幂次方以便能够使用位运算来快速计算索引位置。
1.1.3.4 哈希表的容量为什么推荐2的幂次方
2 的幂次方作为哈希表的容量可以显著提高哈希表操作(如插入、查找和删除)的效率
- 简化索引计算
哈希表中,将键映射到数组中的某个位置通常需要计算该键的哈希码,一般的运用哈希取模运算,对于2的幂次方可以使用位运算来代替取模运算。
// 取模运算
hash % arrayLength
// 位运算
index = hash & (arrayLength - 1);
- 减少哈希冲突
当哈希表的容量是 2 的幂次方时,计算数组索引的方式通常是通过位运算 hash & (capacity - 1)。这种映射方式保留了哈希码的低位信息。如果哈希函数生成的哈希码具有良好的随机性,尤其是低位也足够随机,那么这些哈希值在数组中的分布将会更加均匀。 - 使扩容过程更加简单和高效。
1.1.3.5 HashMap 死链问题
死链出现的原因:扩容方法,当加入的元素超过一个阈值,会引发数组结构的扩容操作。会新创建一个2倍的数组,将原来的元素添加到新的数据里,但是在解析数组绑定的链表的时候,为了提高效率,会从链表头开始循环,从而导致数据被反向绑定到新数组里
// Hash 冲突的解决:开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)、再哈希法、链地址法;此处使用链地址法
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
- HashMap JDK1.7
使用 Hash + 数组 + 链表的结构存储键对元素;旧数组采用头插法维护新元素,新链表元素会逆序排序在并发下链存在环的风险,即死链。 - HashMap JDK1.8
使用 Hash + 数组 + 链表 + 红黑树的结构存储键值对元素;采用尾插法维护新元素
1.1.4 Set 不允许元素重复
HashSet基础结构是HashMap。
<1>根据下面代码块,可以看到,HashSet的元素作为key存放在HashMap中。HashMap的key不重复,所以HashSet不存放重复元素。
<2>允许包含值为null的元素,但最多只能有一个null元素。
- HashSet的put()方法
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
- HashMap的put()方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
1.1.5 Tree 树结构
树包含父节点、左子树、右子树;父节点的数据小于左子树,左子树的数据小于右子树。
- TreeMap的基础结构静态final内部类Entry<K,V>
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
/**
* Make a new cell with given key, value, and parent, and with
* {@code null} child links, and BLACK color.
*/
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
/**
* Returns the key.
*
* @return the key
*/
public K getKey() {
return key;
}
/**
* Returns the value associated with the key.
*
* @return the value associated with the key
*/
public V getValue() {
return value;
}
/**
* Replaces the value currently associated with the key with the given
* value.
*
* @return the value associated with the key before this method was
* called
*/
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
public String toString() {
return key + "=" + value;
}
}
- TreeMap的put()方法
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
- 3、二叉树、红黑树
图和链表都有环,对于链表校验环,即校验后置节点是否在当前节点前置链路出现过即可。
| 类型 | 说明 |
|---|---|
| 二叉树 | 拥有一组节点组合而成具有层次关系的数据结构,没有子节点的称为叶子节点。普通的二叉查找树在极端情况下可退化成链表,此时的增删查效率都会比较低下。 |
| 满二叉树 | 所有父节点都有左子树和右子树,叶子节点且都为最底层树。 |
| 完全二叉树 | 前m个节点数据和满二叉树的前m个节点完全一致,称为完全二叉树 |
| 平衡多路查找树 B Tree | 所有叶子节点到根节点的距离完全一致;该结构用作查询时,能减少查询次数,即索引结构上能减少磁盘 IO 操作的次数 |
| 自平衡的二叉查找树 红黑树 B+ Tree | 相对于平衡查找树拥有更高的性能。红黑树具有良好的效率,它可在 O(logN) 时间内完成查找、增加、删除等操作 |
(1)红黑树根据以下性质维持自平衡
节点是红色或黑色。
根节点是黑色。
所有叶子都是黑色(叶子是NIL节点)。
每个红色节点必须有两个黑色的子节点。
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点(简称黑高)。
(2)红黑树性质顺口溜:一头一脚黑, 黑连红不连。 插入看叔伯, 删除看兄弟
增删查动作下的左旋右旋
3 个一组,左插左旋,右插右旋,中间晋升;
一维列表,分组递归,代表排序,逐级上升;
通过性质发现: 将节点设置为红色在插入时对红黑树造成的影响是小的,而黑色是最大的
将红黑树的节点默认颜色设置为红色,是为尽可能减少在插入新节点对红黑树造成的影响。
(3)一个 m 阶的 B+ 树具有如下几个特征:
有 k 个子树的中间节点包含有 k 个元素(B 树中是 k-1 个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
B+ 树与 B 树最大的不同就是其非叶节点不保存数据,数据都在叶子节点保存,并且叶子节点按照顺序依次相连。
聚簇索引(Clustered Index)中,叶子节点包含完整的记录。而非聚簇索引中,叶子节点仅包含指向完整记录的指针,因此到了叶子节点后还需要做一次磁盘 IO。
1.1.6 JUC包
JUC(java.util.concurrent)提供了丰富的并发编程工具,用于构建高效、线程安全的应用程序。
1.1.6.1 Native API
JUC包基于Native的CAS算法实现并发控制,解决线程安全问题。
具体体现在本地方法 native compareAndSwapInt()。本地方法即 Java 调用非 Java 程序写的方法,本地方法通常为 C 或 C++ 编写。
以下是Native相关API。
- Info相关
主要返回某些低级别的内存信息:addressSize(), pageSize() - Objects相关
主要提供Object和它的域操纵方法:allocateInstance(),objectFieldOffset() - Class相关
主要提供Class和它的静态域操纵方法:staticFieldOffset(),defineClass(),defineAnonymousClass(),ensureClassnitialized() - Arrays相关
数组操纵方法:arrayBaseOffset(),arrayIndexScale() - Synchronization相关
主要提供低级别同步原语(如基于CPU的CAS(Compare-And-Swap)原语):monitorEnter(),tryMonitorEnter(),monitorExit(),compareAndSwapInt(),putOrderedInt() - Memory相关
直接内存访问方法(绕过JVM堆直接操纵本地内存):allocateMemory(),copyMemory(),freeMemory(),getAddress(),getInt(),putInt()
1.1.6.2 CAS的原子性、无锁算法、缓存一致性、ABA问题
- 1、CAS原子性
(1)CAS 操作的原子性来源于硬件层面的支持,即它是由处理器指令集中的特定指令实现的,这些指令在执行时具有不可分割性。
(2)总线锁定机制和缓存一致性协议也帮助确保了多核环境下的数据一致性。
(3)例如:Intel x86 架构:提供了 CMPXCHG 指令。ARM 架构:提供了 LDREX 和 STREX 指令对,来实现 CAS 操作。这些硬件级别的指令被设计成在一个单一、不可中断的操作中完成“比较”和“交换”的过程。即在硬件层保证了CAS操作的原子性。 - 2、CAS无锁算法
CAS 的无锁算法通过利用硬件级别的原子操作,使得多个线程可以在不使用传统锁的情况下安全地更新共享数据。 - 3、CAS缓存一致性
(1)在多核处理器中,每个核心都有自己的缓存层次结构。为了确保不同核心之间的缓存数据一致,处理器实现了缓存一致性协议(例如 MESI 协议)。这些协议确保了当一个核心修改了一个缓存行中的数据时,其他核心能够及时得到通知并更新它们的缓存副本。
(2)对于 CAS 操作而言,缓存一致性协议保证了在任意时刻只有一个核心可以成功执行 CAS 操作,其他尝试同时执行 CAS 的核心将看到最新的数据版本,从而避免了数据竞争。
多核处理器的缓存一致性
MESI 协议通过定义缓存行的四种状态(Modified、Exclusive、Shared、Invalid)以及明确的状态转换规则,有效地解决了多核系统中的缓存一致性问题。
(1)读操作:
如果一个核心尝试读取一个缓存行,它首先检查自己的缓存。如果该缓存行处于 Modified、Exclusive 或 Shared 状态,则直接使用;如果处于 Invalid 状态,则需要从主内存或其他核心的缓存中获取最新数据。
(2)写操作:
如果一个核心尝试写入一个缓存行,它首先检查该缓存行的状态:
如果是 Modified 或 Exclusive,可以直接写入。
如果是 Shared,必须先使所有其他核心持有的该缓存行副本失效,然后独占该缓存行并将其状态转换为 Modified。
如果是 Invalid,必须从主内存或其他核心的缓存中获取最新数据,然后独占该缓存行并将其状态转换为 Modified。
- 4、CAS 的ABA问题
(1)对于共享变量,存在多个线程读取到共享变量的值为A,当线程1执行了修改操作,将A变成B,然后又将B变成A后。此时线程2去执行CAS操作会认为共享变量的值A没发生过变化,导致CAS执行成功。这个场景就是ABA场景,在实际应用上可能存在逻辑错误。
(2)解决方案,使用AtomicStampedReference来记录对象的版本号,通过版本号来解决ABA问题。
模拟ABA问题日志,T1、T2两个线程模拟AtomicInteger操作;T3、T4两个线程模拟AtomicStampedReference操作。通过记录版本号来规避潜在风险。
currentTimeMillis:1733635567834. T1 updated value from 100 to 101. start
currentTimeMillis:1733635567834. Current value: 100
currentTimeMillis:1733635567834. Current value: 101
currentTimeMillis:1733635567834. T1 updated value from 100 to 101. end
currentTimeMillis:1733635567899. T2 performed ABA operation. start
currentTimeMillis:1733635567899. Current value: 101
currentTimeMillis:1733635567899. Current value: 100
currentTimeMillis:1733635567899. T2 performed ABA operation. end
currentTimeMillis:1733635567899. Final value: 100
currentTimeMillis:1733635567901. T3 updated value from 100 to 101. start
currentTimeMillis:1733635567901. Current value: 100, stamp: 0
currentTimeMillis:1733635567901. Current value: 101, stamp: 1
currentTimeMillis:1733635567901. T3 updated value from 100 to 101. end
currentTimeMillis:1733635567961. T4 performed ABA operation. start
currentTimeMillis:1733635567962. Current value: 101, stamp: 1
currentTimeMillis:1733635567962. Current value: 100, stamp: 2
currentTimeMillis:1733635567962. T4 performed ABA operation. end
currentTimeMillis:1733635567962. Final value: 100, stamp: 2
1.1.6.3 java.util.concurrent.atomic包
JUC 包中 atomic 使用底层操作类 sun.misc.Unsafe 基于硬件算法 CAS 实现线程安全;
提供了基于硬件原子指令的原子变量类,包括AtomicBoolean、AtomicInteger、AtomicIntegerArray、AtomicLong、AtomicLongArray、AtomicMarkableReference、AtomicReference、AtomicReferenceArray、AtomicStampedReference等。
1>适用场景
适用于需要高并发性能的场景,尤其是那些频繁进行简单状态更新的操作。通过使用原子变量,可以避免传统锁带来的性能瓶颈和复杂性。
2>AtomicInteger示例代码
此处以AtomicInteger的addAndGet方法为例参考,有个了解即可。
- AtomicInteger的addAndGet()方法
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}
- Unsafe的getAndAddInt()方法
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public native int getIntVolatile(Object var1, long var2);
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
1.1.6.4 java.util.concurrent.locks包
提供了比内置锁(JVM的synchronized )更强大和灵活的锁机制,适合需要复杂锁定逻辑或细粒度控制的场景。它包括了各种类型的锁和条件变量,可以帮助开发者构建高性能的并发应用程序。
包括ReenWriteLock、ReentrantLock、ReentrantReadWriteLock、StampedLock、Condition等。
1>主要接口
- Lock 接口
(1)定义了基本的锁操作,如 lock()、unlock() 等。它不自动释放锁,因此必须确保在 finally 块中调用 unlock()。
(2)ReentrantLock 实现了 Lock 接口,提供了一个可重入的互斥锁。支持公平性和非公平性两种模式。 - ReadWriteLock 接口
(1)定义了读写锁,允许多个读取者同时访问资源,但写入者独占资源。
(2)ReentrantReadWriteLock 实现了 ReadWriteLock 接口,提供了可重入的读写锁。适合读多写少的场景。ReentrantReadWriteLock 在沒有任何读写锁时,才可以取得写入锁。 - Condition 接口
(1)类似于内置的 Object 类中的等待/通知机制,但与特定的 Lock 实例关联。允许更细粒度的线程通信。 - StampedLock 类
(1)StampedLock是比ReentrantReadWriteLock更快的一种锁,支持乐观读、悲观读锁和写锁
(2)StampedLock 对吞吐量有巨大的改进,特别是在读线程越来越多的场景下;
(3)StampedLock有一个复杂的API,对于加锁操作,很容易误用其他方法;
2>示例代码
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Counter {
// 锁的声明和初始化要在方法外部
private final Lock lock = new ReentrantLock();
private int count = 0;
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
return count;
}
}
1、synchronized是在JVM层面上实现的,不但可以通过一些监控工具监控synchronized的锁定,而且在代码执行时出现异常,JVM会自动释放锁定;
2、ReentrantLock、ReentrantReadWriteLock,、StampedLock都是对象层面的锁定,要保证锁定一定会被释放,就必须将unLock()放到finally{}中;
3、当只有少量竞争者的时候,synchronized是一个很好的通用的锁实现;
4、当线程增长能够预估,ReentrantLock是一个很好的通用的锁实现;
1.1.6.5 java.util.concurrent包重要工具
JUC 中的重要工具包括 ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentSkipListMap、CopyOnWriteArrayList、CountDownLatch、CyclicBarrier、Executors、ForkJoinTask、ForkJoinWorkerThread、FutureTask、LinkedBlockingQueue、ThreadPoolExecutor、Semaphore、ArrayBlockingQueue、CompletableFuture、Condition等
1>锁机制
| 类型 | 说明 |
|---|---|
| Synchronized | Java 的内置锁机制,保证同一时间只有一个线程可以访问被 synchronized 修饰的方法或代码块。 |
| ReentrantLock | 显式锁,提供了比 synchronized 更灵活的功能,如可中断锁等待、公平锁等。 |
| Read/Write Lock | 允许多个线程同时读取共享资源,但在写入时确保独占访问。 |
| StampedLock | 结合了读写锁和乐观读锁的优势,适用于高并发读场景。 |
| Condition | 条件变量,与显式锁ReentrantLock绑定使用。通过Lock.newCondition() 方法创建Condition实例。Condition 提供了 signal() 和 signalAll() 方法来唤醒一个或所有等待的线程。提供 await() 方法释放锁,进入等待状态,直到被其他线程唤醒。 |
2>并发集合
| 类型 | 说明 |
|---|---|
| ConcurrentHashMap | 分段锁存储;线程安全的哈希表实现,提供了更高的并发度。 |
| CopyOnWriteArrayList、CopyOnWriteArraySet | 在写操作时复制整个数组,适合读多写少的场景。 |
| ConcurrentSkipListMap、ConcurrentSkipListSet | 基于跳表的数据结构,提供了有序性和线程安全性。 |
3>同步器
| 类型 | 说明 |
|---|---|
| CountDownLatch | 闭锁,一组线程等待其他线程执行完成后再执行。CountDownLatch 初始化时会给定一个计数,然后每次调用 countDown() 计数减1。异步变同步。 |
| CyclicBarrier | 它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point) 也就是阻塞在调用 cyclicBarrier.await() 的地方。和 CountDownLatch 的区别是,计数允许被重置。 |
| Semaphore | 信号量,维护了一个许可集,每次使用时执行 acquire() 从Semaphore 获取许可,如果没有则会阻塞,每次使用完执行 release() 释放许可。Semaphore 对用于对资源的控制,比如数据连接有限,使用 Semaphore 限制访问数据库的线程数。 |
| Exchanger | 用于两个线程间的数据交换,它提供一个同步点,在这个同步点两个线程可以交换彼此的数据。两个线程相互等待处理结果并进行数据传递。 |
4>阻塞队列
| 类型 | 说明 |
|---|---|
| BlockingQueue | 提供了一个线程安全的队列接口,实现了生产者-消费者模式中的缓冲区。 |
| LinkedBlockingQueue、ArrayBlockingQueue | 不同类型的阻塞队列实现,具有不同的容量限制和性能特点。 |
| PriorityBlockingQueue | 基于优先级排序的阻塞队列。 |
| DelayQueue | 只有当元素的延迟期满后才能从中取出。 |
5>异步任务
| 类型 | 说明 |
|---|---|
| CompletableFuture | 代表一个异步计算的结果,提供了组合多个异步任务的能力,如 thenApply、thenCompose 等方法。可以通过 exceptionally 方法处理异步任务中抛出的异常。 |
6>线程池
| 类型 | 说明 |
|---|---|
| Executors 工具类 | 提供创建固定大小、缓存型、定时任务等不同类型的线程池。 |
| ThreadPoolExecutor | 自定义线程池的核心类,允许配置核心线程数、最大线程数、队列类型等参数。 |
| ForkJoinPool | 专为分治算法设计的线程池,支持递归任务的并行执行。 |
| RecursiveTask 和 RecursiveAction | 分别表示有返回值和无返回值的递归任务。 |
1.2 基础算法:排序算法、二分算法、银行家算法、一致性哈希算法
1.2.1 排序算法

- 冒泡排序
/* 冒泡排序 */
void BubbleSort(int arr[], int length)
for (int i = 0; i < length; i++)
for (int j = 0; j < length - i - 1; j++)
if (arr[j] > arr[j + 1]) {
int temp;
temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
}
- 归并排序
public class MergeSort {
// 归并排序
public static int[] mergeSort(int[] arr, int left, int right) {
// 如果 left == right,表示数组只有一个元素,则不用递归排序
if (left < right) {
// 把大的数组分隔成两个数组
int mid = (left + right) / 2;
// 对左半部分进行排序
arr = mergeSort(arr, left, mid);
// 对右半部分进行排序
arr = mergeSort(arr, mid + 1, right);
//进行合并
merge(arr, left, mid, right);
}
return arr;
}
// 合并函数,把两个有序的数组合并起来
// arr[left..mif]表示一个数组,arr[mid+1 .. right]表示一个数组
private static void merge(int[] arr, int left, int mid, int right) {
//先用一个临时数组把他们合并汇总起来
int[] a = new int[right - left + 1];
int i = left;
int j = mid + 1;
int k = 0;
while (i <= mid && j <= right) {
if (arr[i] < arr[j]) {
a[k++] = arr[i++];
} else {
a[k++] = arr[j++];
}
}
while(i <= mid) a[k++] = arr[i++];
while(j <= right) a[k++] = arr[j++];
// 把临时数组复制到原数组
for (i = 0; i < k; i++) {
arr[left++] = a[i];
}
}
}
1.2.2 二分查找算法
二分算法,前提是集合是有序的
1>思想
令L=1, R=8, mid=(L+R)/2=4
(1)比较arr[mid]=6>4,说明要在arr[L]….arr[mid-1]中找,R=mid-1=3
(2)更新mid=(L+R)/2=2,比较arr[mid]=3<4,说明要在arr[mid+1]…arr[R]中找,L=mid+1=3
(3)更新mid=(L+R)/2=3,比较arr[mid]=4,4==key,查找结束!返回结果为3
- 二分查找算法
#include<iostream>
using namespace std;
const int N=1e6;
int n,key,arr[N];
int binarySearch(int arr[],int n,int x)
{
int l = 1;
int r = n;
int ans = -1;
while(l <= r)
{
int m = (l + r) / 2;
if(arr[m] == x)
{
ans = m;
break;
}
if(arr[m] < x)
l = m + 1;
else
r = m - 1;
}
return ans;
}
int main()
{
cin >> n >> key;
for(int i = 1;i <= n;i++)
cin >> arr[i];
int ans = binarySearch(arr,n,key);
cout << ans;
return 0;
}
1.2.3 银行家算法
当一个进程申请使用资源的时候,银行家算法通过先试探分配给该进程资源,然后通过安全性算法判断分配后的系统是否处于安全状态,若不安全则试探分配作废,让该进程继续等待。

1.2.4 一致性哈希算法
哈希算法和一致性哈希算法都是用于将数据映射到特定位置的技术。
1>哈希算法与一致性哈希算法
哈希算法用于哈希表、数据库索引。一致性哈希算法用于Nginx、memcached负载均衡策略、Redis Cluster动态扩容,一致性哈希算法更加适用于分布式场景。
-
1、哈希算法 hash(数据)% N
传统hash算法,对 N 台服务器进行取模运算,对应的打到不同的服务器上,对于这种线性结构,不便于扩展,增加或减少一台服务器,都会影响整个数据。新数据走哈希算法后进入的服务器与扩展前的错误错乱了。需要清除原来所有的数据,重新哈希计算,成本很高。 -
2、一致性哈希算法 hash(数据)% 2^32 相对于哈希算法,支持动态扩容
哈希环:圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到 2^32-1,也就是说0点左侧的第一个点代表 2^32-1。我们把这个由2的32次方个点组成的圆环称为hash环。
负载均衡:服务器和数据(字符)经过md5散列之后,就是一串随机的字符串,根据哈希算法取模,在虚拟的哈希环上依次按模打在不同的节点上,实现负载均衡。此时,扩展服务器,会出现部分数据失效。有更好的扩展性
2>哈希环
一致性哈希就是构建环状结构代替传统哈希线状结构。
整个Hash空间被构建成一个首尾相接的环,使用一致性Hash时需要进行两次映射。
第一次,给每个节点(集群)计算Hash,然后记录它们的Hash值,这就是它们在环上的位置。
第二次,给每个Key计算Hash,然后沿着顺时针的方向找到环上的第一个节点,就是该Key储存对应的集群。
分析一下节点增加和删除时对负载均衡的影响,如下图:
可以看到,当节点被删除时,其余节点在环上的映射不会发生改变,只是原来打在对应节点上的Key现在会转移到顺时针方向的下一个节点上去。增加一个节点也是同样的,最终都只有少部分的Key发生了失效。不过发生节点变动后,整体系统的压力已经不是均衡的了


2>哈希环的偏斜及虚拟节点
真实服务器存在,hash环的偏斜情况,非理想状态下,真实服务器哈希取模后,可能分布在环上相邻的点;导致大量数据还是会分布在某个节点,少量数据分布在其他节点;
通过引入虚拟节点去支持更好的复杂均衡,一个真实服务器可以复制多个虚拟节点;虚拟节点越多,负载均衡分布效果越好。

1.3 Thread
volatile 线程内存可见性,解决一写多读场景的并发问题;
1>线程的状态

2>线程的实现方式
new Thread();
public class Thread implements Runnable {}
3>Callable 和 Runnable 的区别
在一个task里面,Runnable没有返回值,Callable有返回值且支持抛出异常;
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
4>死锁预防
(1)避免嵌套锁
尽量减少锁的嵌套层级,避免死锁的发生。
(2)锁顺序
如果必须嵌套锁,确保所有线程按照相同的顺序获取锁。
(3)超时机制
使用 tryLock 或 lockInterruptibly 方法设置锁的获取超时,防止无限期等待
5>ThreadLocal
它提供了线程局部变量(thread-local variables)。每个线程对其持有的 ThreadLocal 实例都有独立的变量副本,这意味着即使多个线程访问同一个 ThreadLocal 实例,它们看到的变量也是相互隔离的。这在并发编程中特别有用,可以避免使用锁带来的性能开销和复杂性。
- 1、线程隔离管理
ThreadLocal线程隔离的原理是,通过为每个线程维护独立的 ThreadLocalMap 来实现线程隔离。每个 ThreadLocal 实例作为键,存储在线程自己的 ThreadLocalMap 中,从而确保了不同线程之间的数据互不干扰。 - 2、内存泄漏风险
(1)这个变量是针对一个线程内所有操作共享的,所以设置为静态变量,所有此类实例共享此静态变量;
(2)每个线程一个实例T,ThreadLocal 变量共享;必须回收自定义的ThreadLocal 变量,多线程场景下,线程复用,不及时回收存在内存泄漏的风险。 - 3、生命周期绑定到线程
ThreadLocal 变量的生命周期与线程的生命周期绑定。当线程结束时,ThreadLocal 变量也会被回收。
ThreadLocal示例代码
DBConnectionManager 类
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DBConnectionManager {
private static final ThreadLocal<Connection> connectionHolder = ThreadLocal.withInitial(() -> {
try {
return DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "user", "password");
} catch (SQLException e) {
throw new RuntimeException(e);
}
});
public static Connection getConnection() {
return connectionHolder.get();
}
public static void removeConnection() {
Connection conn = connectionHolder.get();
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
connectionHolder.remove(); // 确保清除 ThreadLocal 引用
}
}
}
}
TestDBConnection 测试类
// 测试类
class TestDBConnection {
public static void main(String[] args) {
Runnable task = () -> {
Connection conn = DBConnectionManager.getConnection();
try {
// 执行数据库操作
System.out.println(Thread.currentThread().getName() + " using connection: " + conn);
} finally {
DBConnectionManager.removeConnection(); // 确保清理连接
}
};
Thread t1 = new Thread(task, "Thread-1");
Thread t2 = new Thread(task, "Thread-2");
t1.start();
t2.start();
}
}
1.4 代理、反射、流操作、Netty
1.4.1 代理
java.lang.reflect.* 通过字节码文件 .class 获取实体类的方法及属性。
1>分类
- 静态代理
在编译时创建代理类,并与被代理的对象实现相同的接口。 - 动态代理
在运行时动态生成代理类,通常通过 java.lang.reflect.Proxy 类来实现。
2>原理
动态代理的核心在于使用 java.lang.reflect.InvocationHandler 接口和 Proxy 类。InvocationHandler 定义了如何处理方法调用,而 Proxy 类用于创建代理实例。
3>动态代理方式
| 动态代理 | 优点 | 缺点 |
|---|---|---|
| JDK 动态代理 | 仅支持代理实现了接口的类 | 未实现接口的类不支持 JDK 动态代理 |
| CGlib | 支持代理类文件,原理对指定目标类生成一个子类,覆盖其中的方法实现增强 | 通过继承方式,子类增强,所以不能对 final 类进行代理 |
4>动态代理应用场景
AOP(面向切面编程):如 Spring AOP 使用动态代理来实现横切关注点(如事务管理、日志记录等)。
5>动态代理示例代码
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
// 定义一个接口
interface Service {
void execute();
}
// 实现该接口的服务类
class RealService implements Service {
@Override
public void execute() {
System.out.println("Executing real service.");
}
}
// 创建 InvocationHandler
class ServiceInvocationHandler implements InvocationHandler {
private final Object target;
public ServiceInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 在方法调用前后可以添加额外逻辑
System.out.println("Before method call.");
Object result = method.invoke(target, args);
System.out.println("After method call.");
return result;
}
}
// 使用动态代理
public class DynamicProxyExample {
public static void main(String[] args) {
Service realService = new RealService();
Service proxyInstance = (Service) Proxy.newProxyInstance(
realService.getClass().getClassLoader(),
realService.getClass().getInterfaces(),
new ServiceInvocationHandler(realService)
);
proxyInstance.execute(); // 输出 Before/After 日志
}
}
输出日志
Before method call.
Executing real service.
After method call.
1.4.2 反射
反射机制允许程序在运行期间检查和修改其结构与行为。通过反射,你可以获取类的信息、创建对象、调用方法、访问字段等。
1>功能
- 获取类信息
包括类名、父类、接口、构造函数、方法和字段等。 - 创建对象实例
通过无参或带参数的构造函数创建对象。 - 调用方法
动态地调用任意方法,无论是否是私有方法。 - 访问字段
读取或修改私有字段的值。 - 设置可访问性
绕过 Java 的访问控制修饰符限制。
2>应用场景
- 框架开发
如 Spring 和 Hibernate 使用反射进行依赖注入、ORM 映射等功能。 - 序列化/反序列化
如 Java 的序列化机制依赖于反射来保存和恢复对象状态。 - 测试工具
单元测试框架(如 JUnit)利用反射来发现和执行测试方法。 - 动态配置
根据配置文件动态创建对象或设置属性。
3>示例代码
package pers.niaonao;
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
class ReflectionExample {
private String message;
private ReflectionExample(String message) {
this.message = message;
}
private void printMessage() {
System.out.println("Message: " + message);
}
public static void main(String[] args) throws Exception {
Class<?> clazz = Class.forName("pers.niaonao.ReflectionExample");
// 获取私有构造函数并创建实例
Constructor<?> constructor = clazz.getDeclaredConstructor(String.class);
constructor.setAccessible(true);
Object instance = constructor.newInstance("Hello, Reflection!");
// 获取私有方法并调用
Method method = clazz.getDeclaredMethod("printMessage");
method.setAccessible(true);
method.invoke(instance); // 输出 Message: Hello, Reflection!
}
}
输出结果
Message: Hello, Reflection!
1.4.3 IO 输入输出
Java提供了丰富的类库,来支持不同类型数据的IO操作。包括文件读写、网络通信、字符流和字节流等。
1.4.3.1 字节流
字节流用于处理原始二进制数据,适用于所有类型的文件和网络连接。
| 类型 | 说明 |
|---|---|
| InputStream 和 OutputStream | 抽象基类,定义了基本的读写方法。 |
| FileInputStream 和 FileOutputStream | 用于读写文件。 |
| BufferedInputStream 和 BufferedOutputStream | 提供了缓冲机制,提高读写效率。 |
| DataInputStream 和 DataOutputStream | 支持基本数据类型(如 int, double 等)的读写。 |
| ObjectInputStream 和 ObjectOutputStream | 用于序列化和反序列化对象。 |
示例代码
import java.io.*;
public class ByteStreamExample {
public static void main(String[] args) {
String filePath = "example.txt";
byte[] data = "Hello, World!".getBytes();
// 写入文件
try (FileOutputStream fos = new FileOutputStream(filePath);
BufferedOutputStream bos = new BufferedOutputStream(fos)) {
bos.write(data);
} catch (IOException e) {
e.printStackTrace();
}
// 读取文件
try (FileInputStream fis = new FileInputStream(filePath);
BufferedInputStream bis = new BufferedInputStream(fis)) {
int byteRead;
while ((byteRead = bis.read()) != -1) {
System.out.print((char) byteRead);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
1.4.3.2 字符流
字符流用于处理文本数据,基于 Unicode 字符集,更适合处理文本文件。
| 类型 | 说明 |
|---|---|
| Reader 和 Writer | 抽象基类,定义了基本的读写方法。 |
| FileReader 和 FileWriter | 用于读写字符文件。 |
| BufferedReader 和 BufferedWriter | 提供了缓冲机制,提高读写效率。 |
| InputStreamReader 和 OutputStreamWriter | 用于在字节流和字符流之间进行转换。 |
| PrintWriter | 提供方便的打印方法,适合格式化输出。 |
示例代码
import java.io.*;
public class CharacterStreamExample {
public static void main(String[] args) {
String filePath = "example.txt";
// 写入文件
try (FileWriter fw = new FileWriter(filePath);
BufferedWriter bw = new BufferedWriter(fw);
PrintWriter out = new PrintWriter(bw)) {
out.println("Hello, World!");
} catch (IOException e) {
e.printStackTrace();
}
// 读取文件
try (FileReader fr = new FileReader(filePath);
BufferedReader br = new BufferedReader(fr)) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
1.4.3.3 NIO(New I/O)、BIO
1>NIO
NIO 是 Java 1.4 引入的新一代 IO 库,提供了非阻塞 IO 支持和更高效的缓冲区管理。主要类位于 java.nio 和 java.nio.channels 包中。
Java NIO 同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求就进行处理;

代码示例
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.file.*;
public class NIOExample {
public static void main(String[] args) throws IOException {
Path path = Paths.get("example.txt");
String content = "Hello, NIO!";
// 写入文件
try (FileChannel channel = FileChannel.open(path, StandardOpenOption.CREATE, StandardOpenOption.WRITE)) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put(content.getBytes());
buffer.flip(); // 切换到读模式
channel.write(buffer);
}
// 读取文件
try (FileChannel channel = FileChannel.open(path, StandardOpenOption.READ)) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = channel.read(buffer);
buffer.flip(); // 切换到读模式
System.out.println(new String(buffer.array(), 0, bytesRead));
}
}
}
2>BIO
Java BIO 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时,服务端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销;

3>AIO
Java AIO(NIO.2):异步非阻塞,AIO引入异步通道的概念,采用了Proactor模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用;
Java NIO.2 引入了新的 API 来简化文件系统的操作,提供了更强大的功能和更好的性能。主要包括类Path、Paths、Files。
代码示例
import java.nio.file.*;
public class FileSystemExample {
public static void main(String[] args) {
Path path = Paths.get("example.txt");
// 创建文件
try {
Files.createFile(path);
System.out.println("File created.");
} catch (FileAlreadyExistsException e) {
System.out.println("File already exists.");
} catch (IOException e) {
e.printStackTrace();
}
// 检查文件是否存在
if (Files.exists(path)) {
System.out.println("File exists.");
}
// 删除文件
try {
Files.delete(path);
System.out.println("File deleted.");
} catch (IOException e) {
e.printStackTrace();
}
}
}
BIO方式适用于连接数比较小且固定的架构,这种方式对服务器资源要求比较高,并不局限于应用中,JDK1.4以前的唯一选择,但程序简单易理解;
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂,JDK1.4开始支持。
AIO方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
1.4.3.4 Serializable 序列化
序列化是指将对象转换为字节流以便存储或传输,反序列化则是将字节流还原为对象。主要用于持久化对象状态或通过网络发送对象。
class通过实现 Serializable 接口,即可实现序列化.
import java.io.*;
class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{name='" + name + "', age=" + age + "}";
}
}
public class SerializationExample {
public static void main(String[] args) {
String filePath = "person.ser";
Person person = new Person("Alice", 30);
// 序列化对象
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(filePath))) {
oos.writeObject(person);
} catch (IOException e) {
e.printStackTrace();
}
// 反序列化对象
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(filePath))) {
Person deserializedPerson = (Person) ois.readObject();
System.out.println(deserializedPerson);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
1.4.3.5 Netty
1>简介和特性
Netty 是一个高性能、异步事件驱动的 NIO (异步通讯 non-blocking IO)框架,基于 JAVA NIO 提供的 API 实现。
提供了对 TCP、UDP 和文件传输的支持,作为一个异步 NIO 框架,Netty 的所有 IO 操作都是异步非阻塞的,通过 Future-Listener 机制,用户可以方便的主动获取或者通过通知机制获得 IO 操作结果。
内置多种编解码器,如 HTTP、WebSocket、Protobuf 等,方便开发者快速集成不同协议。
2>核心组件
| 组件 | 说明 |
|---|---|
| Channel | 表示一个网络连接,提供读写操作接口。 |
| EventLoop | 负责管理一组 Channel,处理它们的 I/O 事件(如连接建立、数据读取等)。 |
| ChannelHandler | 定义了如何处理特定类型的事件或消息,是业务逻辑的核心部分。 |
| ChannelPipeline | 每个 Channel 都有一个关联的 ChannelPipeline,它由多个 ChannelHandler 组成,用于处理入站和出站的数据流。 |
| Bootstrap 和 ServerBootstrap | 用于配置客户端和服务器端的启动参数,简化初始化过程。 |
3>应用场景
- 高并发服务器
Netty 的非阻塞特性和高效的线程模型使其非常适合构建高并发的服务端应用。
(1)游戏服务器:实时性强的游戏需要快速响应玩家的操作,Netty 提供了低延迟和高吞吐量的支持。
(2)即时通讯系统:如聊天应用、在线会议平台等,要求稳定的长连接管理和及时的消息传递。 - 微服务通信
Netty 可以作为 RPC(远程过程调用)框架的基础
(1)gRPC:Google 推出的一种高效的 RPC 框架,底层使用 HTTP/2 协议,Netty 是其 Java 实现之一。 - 消息队列
(1)Kafka:虽然 Kafka 自己实现了网络层,但它的设计灵感来源于 Netty,并且 Netty 可以用来构建类似的高性能消息系统。
(2)RabbitMQ 插件:某些 RabbitMQ 插件使用 Netty 来增强其网络性能。 - 物联网
(1)MQTT 协议服务器:MQTT 是一种轻量级的消息传输协议,特别适合资源受限的 IoT 设备。Netty 提供了对 MQTT 的良好支持。
1.5 三次握手、四次挥手
- 1、序号(sequence number)
Seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。 - 2、确认号(acknowledgement number)
Ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,Ack=Seq+1。 - 3、标志位(Flags)
共6个,即URG、ACK、PSH、RST、SYN、FIN等。具体含义如下:
(1)URG:紧急指针(urgent pointer)有效。
(2)ACK:确认序号有效。
(3)PSH:接收方应该尽快将这个报文交给应用层。
(4)RST:重置连接。
(5)SYN:发起一个新连接。
(6)FIN:释放一个连接。
1.5.1 三次握手
建立连接时,客户端发送syn包(seq=j)到服务器,并进入SYN_SENT状态,等待服务器确认;
服务器收到syn包,必须确认客户端的SYN(ack=j+1),同时自己也发送一个SYN包(seq=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手;
1.5.2 四次挥手
Client发送⼀个FIN,⽤来关闭Client到Server的数据传送,Client进⼊FIN_WAIT_1状态;
Server收到FIN后,发送⼀个ACK给Client,确认序号为收到序号+1,Server进⼊CLOSE_WAIT状态;
Server发送⼀个FIN,⽤来关闭Server到Client的数据传送,Server进⼊LAST_ACK状态;
Client收到FIN后,Client进⼊TIME_WAIT状态,接着发送⼀个ACK给Server,确认序号为收到序号+1,Server进⼊CLOSED状态,完成四次挥⼿;
1.6 JVM 原理
(1)生命周期(加载-验证-准备-解析-初始化-使用-卸载)
(2)内存模型(程序计数器、虚拟机栈、本地方法栈、堆、方法区)
(3)JVM类加载机制(双亲委派模型)
(4)垃圾收集机制(标记-清除、标记-整理、复制算法)
(5)类字节码实现机制
(6)JVM调优案例
(7)GC日志详解等
解释与编译共存
Java程序要经过先编译,后解释两个步骤;
由Java编写的程序需要先经过编译步骤,生成字节码(后缀名是.class的文件),这种字节码必须由Java解释器来解释执行。
1.6.1 内存模型
| 堆 | 非堆 | 虚拟机栈 | 本地方法栈 | 程序计数器 | |
|---|---|---|---|---|---|
| 英文名称 | Heap | Non-Heap | JVM Stack | Native Method Stack | Program Counter Register |
| 说明 | 包含新生代与老年代 | 又称永久代或方法区 | 为 Java 方法执行服务 | 为 Native 方法执行服务 | 字节码执行时的行号计数器 |
| 线程安全 | 多线程共享 | 多线程共享 | 线程私有 | 线程私有 | 线程私有 |
| 存储数据 | 对象实例 | 常量、静态变量、已被JVM加载的类 | 栈帧 | 栈帧 | 字节码执行时的行号计数器 |
1.6.2 垃圾回收算法
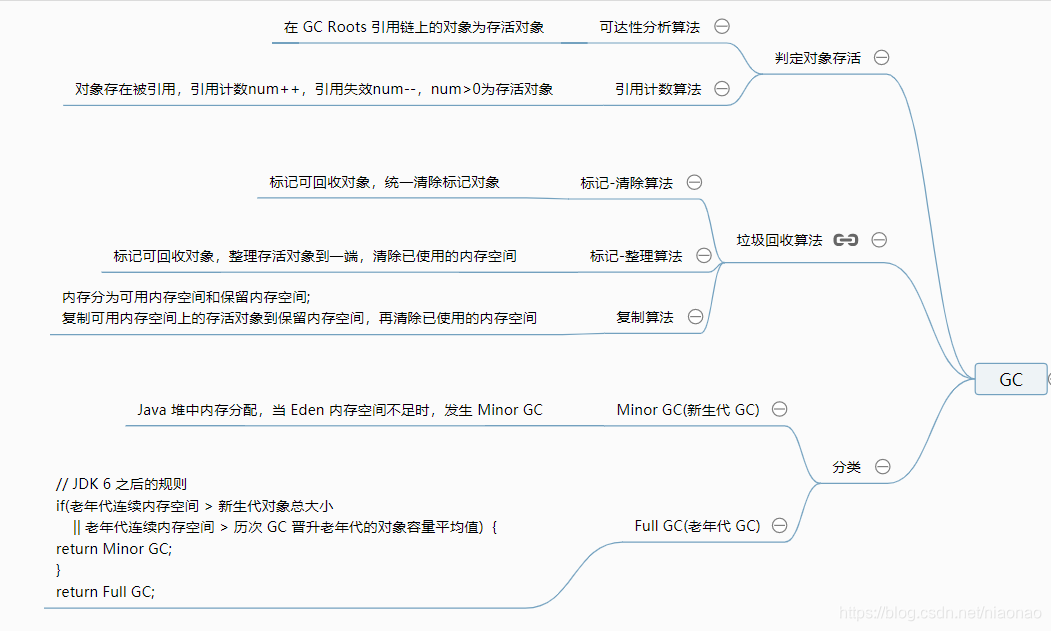
1.6.3 垃圾回收器

- 串行回收器
Serial、Serial old - 并行回收器
ParNew、Parallel Scavenge、Parallel old、CMS、G1(Garbage First)
如果你想要最小化地使用内存和并行开销,请选Serial GC;
如果你想要最大化应用程序的吞吐量,请选Parallel GC;
如果你想要最小化GC的中断或停顿时间,请选CMs GC。
| 类型 | 说明 |
|---|---|
| Serial | 首先串行适合单核,基本上是在JDK1.3之前的版本会默认使用 Serial,通过复制算法、串行回收和"stop-the-World"机制的方式执行内存回收; |
| ParNew | 目前多核都不推荐串行垃圾回收,推荐并行或并发回收;ParNew 就是 Serial 的多线程版本,也是复制算法、"stop-the-World"机制。 |
| Parallel | 吞吐量优先 |
| CMS | 低延迟 |
| Garbage First | 是一个并行收集器,将堆划分为多个区域 Region,G1 GC有计划地避免在整个Java堆中进行全区域的垃圾收集。针对配备多核CPU及大容量内存的机器,以极高概率满足GC停顿时间的同时,还兼具高吞吐量的性能特征。年轻代GC Young GC、老年代并发标记过程 Concurrent Marking、混合回收 Mixed GC |
| 垃圾回收器 | 内存大小 |
|---|---|
| Serial+SerianlOld | 十M |
| PS+PO | 百M-G |
| PN+CMS | 十G |
| G1 | 百G |
| ZGC | T |
1.6.4 类加载
加载阶段主要是使用类加载器,根据类的全限定名,获取类的二进制字节流;
1>类加载阶段
验证阶段对文本格式、元数据、字节码、符号引用进行验证;
准备阶段在非堆为静态变量分配内存,设置初始值零值;
解析阶段将常量池内的符号引用替换为直接引用;
初始化阶段开始执行字节码,初始化类变量和其他资源,对静态变量进行赋值等。
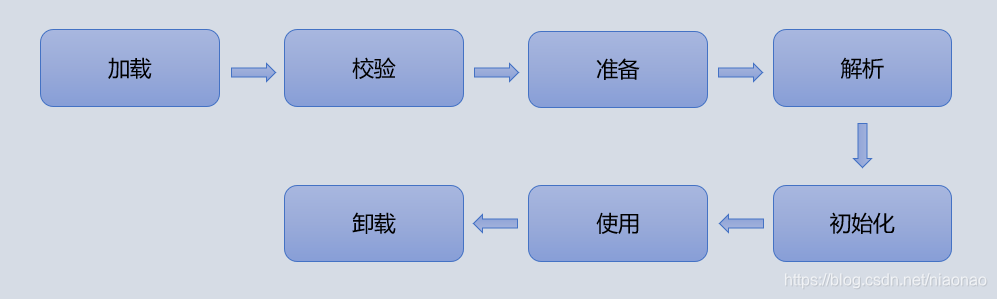
2>类加载器
| 类别 | 程序可直接引用 | 支持加载的类库 |
|---|---|---|
| 启动类加载器 Bootstrap ClassLoader | 否 | JAVA_HOME\lib 目录下的类库和参数 -Xbootclasspath 指定路径中的类库 |
| 扩展类加载器 Extension ClassLoader | 是 | JAVA_HOME\lib\ext 目录下的类库和系统变量 java.ext.dirs 指定路径中的类库 |
| 系统类加载器 Application ClassLoader | 是 | 系统变量 classpath 指定路径中的类库 |
| 自定义类加载器 | 是 |
1.6.5 双亲委派模型
一个类加载器收到类加载的请求,会把请求委派给父-类加载器去完成,如果父-类加载器没有找到所需的类无法完成加载时,子-类加载器开始尝试类加载。

1.6.6 JVM调优
1>JVM参数配置
垃圾回收器配置 -XX:+UseSerialGC
内存配置:垃圾回收频繁时,调整内存大小,新生代老年代占比,老年代年龄大小
调整GC触发时机
调整 JVM本地内存大小 XX:MaxDirectMemorySize
//设置Serial垃圾收集器(新生代)
开启:-XX:+UseSerialGC
//设置PS+PO,新生代使用功能Parallel Scavenge 老年代将会使用Parallel Old收集器
开启 -XX:+UseParallelOldGC
//CMS垃圾收集器(老年代)
开启 -XX:+UseConcMarkSweepGC
//设置G1垃圾收集器
开启 -XX:+UseG1GC
//设置堆初始值
指令1:-Xms2g
指令2:-XX:InitialHeapSize=2048m
//设置堆区最大值
指令1:`-Xmx2g`
指令2: -XX:MaxHeapSize=2048m
//新生代内存配置
指令1:-Xmn512m
指令2:-XX:MaxNewSize=512m
//survivor区和Eden区大小比率
指令:-XX:SurvivorRatio=6 //S区和Eden区占新生代比率为1:6,两个S区2:6
//新生代和老年代的占比
-XX:NewRatio=4 //表示新生代:老年代 = 1:4 即老年代占整个堆的4/5;默认值=2
//进入老年代最小的GC年龄,年轻代对象转换为老年代对象最小年龄值,默认值7
-XX:InitialTenuringThreshol=7
//使用多少比例的老年代后开始CMS收集,默认是68%,如果频繁发生SerialOld卡顿,应该调小
-XX:CMSInitiatingOccupancyFraction
//G1混合垃圾回收周期中要包括的旧区域设置占用率阈值。默认占用率为 65%
-XX:G1MixedGCLiveThresholdPercent=65
// JVM除了堆内存之外还有一块堆外内存,这片内存也叫本地内存,可是这块内存区域不足了并不会主动触发GC,只有在堆内存区域触发的时候顺带会把本地内存回收了,而一旦本地内存分配不足就会直接报OOM异常。
-XX:MaxDirectMemorySize
2>调优案例
常用命令TOP、jmap、jstat -gc、visualVM
- 1、后台导出数据引发的OOM
问题描述:公司的后台系统,偶发性的引发OOM异常,堆内存溢出。
1、因为是偶发性的,所以第一次简单的认为就是堆内存不足导致,所以单方面的加大了堆内存从4G调整到8G。
2、但是问题依然没有解决,只能从堆内存信息下手,通过开启了-XX:+HeapDumpOnOutOfMemoryError参数 获得堆内存的dump文件。
3、VisualVM 对 堆dump文件进行分析,通过VisualVM查看到占用内存最大的对象是String对象,本来想跟踪着String对象找到其引用的地方,但dump文件太大,跟踪进去的时候总是卡死,而String对象占用比较多也比较正常,最开始也没有认定就是这里的问题,于是就从线程信息里面找突破点。
4、通过线程进行分析,先找到了几个正在运行的业务线程,然后逐一跟进业务线程看了下代码,发现有个引起我注意的方法,导出订单信息。
5、因为订单信息导出这个方法可能会有几万的数据量,首先要从数据库里面查询出来订单信息,然后把订单信息生成excel,这个过程会产生大量的String对象。
6、为了验证自己的猜想,于是准备登录后台去测试下,结果在测试的过程中发现到处订单的按钮前端居然没有做点击后按钮置灰交互事件,结果按钮可以一直点,因为导出订单数据本来就非常慢,使用的人员可能发现点击后很久后页面都没反应,结果就一直点,结果就大量的请求进入到后台,堆内存产生了大量的订单对象和EXCEL对象,而且方法执行非常慢,导致这一段时间内这些对象都无法被回收,所以最终导致内存溢出。
7、知道了问题就容易解决了,最终没有调整任何JVM参数,只是在前端的导出订单按钮上加上了置灰状态,等后端响应之后按钮才可以进行点击,然后减少了查询订单信息的非必要字段来减少生成对象的体积,然后问题就解决了。
- 2、单个缓存数据过大导致的系统CPU飚高
1、系统发布后发现CPU一直飚高到600%,发现这个问题后首先要做的是定位到是哪个应用占用CPU高,通过top 找到了对应的一个java应用占用CPU资源600%。
2、如果是应用的CPU飚高,那么基本上可以定位可能是锁资源竞争,或者是频繁GC造成的。
3、所以准备首先从GC的情况排查,如果GC正常的话再从线程的角度排查,首先使用jstat -gc PID 指令打印出GC的信息,结果得到得到的GC 统计信息有明显的异常,应用在运行了才几分钟的情况下GC的时间就占用了482秒,那么问这很明显就是频繁GC导致的CPU飚高。
4、定位到了是GC的问题,那么下一步就是找到频繁GC的原因了,所以可以从两方面定位了,可能是哪个地方频繁创建对象,或者就是有内存泄露导致内存回收不掉。
5、根据这个思路决定把堆内存信息dump下来看一下,使用jmap -dump 指令把堆内存信息dump下来(堆内存空间大的慎用这个指令否则容易导致会影响应用,因为我们的堆内存空间才2G所以也就没考虑这个问题了)。
6、把堆内存信息dump下来后,就使用visualVM进行离线分析了,首先从占用内存最多的对象中查找,结果排名第三看到一个业务VO占用堆内存约10%的空间,很明显这个对象是有问题的。
7、通过业务对象找到了对应的业务代码,通过代码的分析找到了一个可疑之处,这个业务对象是查看新闻资讯信息生成的对象,由于想提升查询的效率,所以把新闻资讯保存到了redis缓存里面,每次调用资讯接口都是从缓存里面获取。
8、把新闻保存到redis缓存里面这个方式是没有问题的,有问题的是新闻的50000多条数据都是保存在一个key里面,这样就导致每次调用查询新闻接口都会从redis里面把50000多条数据都拿出来,再做筛选分页拿出10条返回给前端。50000多条数据也就意味着会产生50000多个对象,每个对象280个字节左右,50000个对象就有13.3M,这就意味着只要查看一次新闻信息就会产生至少13.3M的对象,那么并发请求量只要到10,那么每秒钟都会产生133M的对象,而这种大对象会被直接分配到老年代,这样的话一个2G大小的老年代内存,只需要几秒就会塞满,从而触发GC。
9、知道了问题所在后那么就容易解决了,问题是因为单个缓存过大造成的,那么只需要把缓存减小就行了,这里只需要把缓存以页的粒度进行缓存就行了,每个key缓存10条作为返回给前端1页的数据,这样的话每次查询新闻信息只会从缓存拿出10条数据,就避免了此问题的 产生。
- 3、CPU经常100% 问题定位
问题分析:CPU高一定是某个程序长期占用了CPU资源。
1、所以先需要找出那个进行占用CPU高。
top 列出系统各个进程的资源占用情况。
2、然后根据找到对应进行里哪个线程占用CPU高。
top -Hp 进程ID 列出对应进程里面的线程占用资源情况
3、找到对应线程ID后,再打印出对应线程的堆栈信息
printf “%x\n” PID 把线程ID转换为16进制。
jstack PID 打印出进程的所有线程信息,从打印出来的线程信息中找到上一步转换为16进制的线程ID对应的线程信息。
4、最后根据线程的堆栈信息定位到具体业务方法,从代码逻辑中找到问题所在。
查看是否有线程长时间的watting 或blocked
如果线程长期处于watting状态下, 关注watting on xxxxxx,说明线程在等待这把锁,然后根据锁的地址找到持有锁的线程
- 4、数据分析平台系统频繁 Full GC
平台主要对用户在 App 中行为进行定时分析统计,并支持报表导出,使用 CMS GC 算法。
数据分析师在使用中发现系统页面打开经常卡顿,通过 jstat 命令发现系统每次 Young GC 后大约有 10% 的存活对象进入老年代。
原来是因为 Survivor 区空间设置过小,每次 Young GC 后存活对象在 Survivor 区域放不下,提前进入老年代。
通过调大 Survivor 区,使得 Survivor 区可以容纳 Young GC 后存活对象,对象在 Survivor 区经历多次 Young GC 达到年龄阈值才进入老年代。
调整之后每次 Young GC 后进入老年代的存活对象稳定运行时仅几百 Kb,Full GC 频率大大降低。
- 5、业务对接网关 OOM
网关主要消费 Kafka 数据,进行数据处理计算然后转发到另外的 Kafka 队列,系统运行几个小时候出现 OOM,重启系统几个小时之后又 OOM。
通过 jmap 导出堆内存,在 eclipse MAT 工具分析才找出原因:代码中将某个业务 Kafka 的 topic 数据进行日志异步打印,该业务数据量较大,大量对象堆积在内存中等待被打印,导致 OOM。
1.7 基础编程规约
import * 本质上是无影响的,因为在生成字节码文件时,class 文件还是只会包含引用的包,其他包不导入;不过依然推荐使用import 具体的包,可读性好
foreach 遍历中强制不使用remove方法,不安全
Map、Iterator 迭代器遍历时不推荐遍历k,推荐遍历元素k-v;keySet本质上遍历两次,先遍历元素,后取key组成集合,推荐entrySet();JDK8 推荐使用 Map.forEach;
ThreadLocal 线程池场景下线程共享,要及时回收remove ThreadLocal变量,存在内存泄漏风险
推荐使用 ThreadPoolExecutor 的方式创建线程池,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险;Executors 返回的线程池对象,允许创建大量的线程或处理大量的求,存在资源浪费资源耗尽的风险
推荐构造器注入,避免空指针异常、避免循环依赖;缺点是代码冗余不易读。setter注入方式按需加载,不是初始化阶段把所有对象注入,不支持final;field注入方式不符合javabean规范,存在空指针异常风险,不支持final修饰。
byte、boolean、char、short、int、float、long、double
2. MySQL 数据库、Oracle、Redis、NoSQL、ShardingSphere
2.1 MySQL
(1)数据库引擎(InnDB 支持事务行锁、MyISAM)
(2)SQL执行原理(解析器、优化器、执行器)
(3)索引底层机制
(4)SQL执行计划分析(explain 分析)
(5)Mysql锁机制(悲观锁:行锁、表锁;乐观锁)
(6)Mysql事务隔离(ACID、隔离级别、传播特性)
(7)SQL优化实践(索引失效、大SQL拆分、file_sort)等
2.1.1 数据库引擎
| 数据库引擎 | Innodb | Myisam | Memory | Merge |
|---|---|---|---|---|
| 事务 | 支持 | 不支持 | ||
| 全文索引 | 不支持 | 支持 | ||
| 外键 | 支持 | 不支持 | ||
| 表锁 | 支持 | 支持 | ||
| 行锁 | 支持 | 不支持 | ||
| 事务 | 支持 | 不支持 | ||
| 优点 | 支持行级锁,事务,并发,内存是 Myisam的2.5倍 | 不支持 | 全表锁 | 一组Myisam表的组合 |
2.1.2 MySQL 数据量瓶颈
对于 Mybattis 使用#{}避免 SQL依赖注入,预编译阶段会解析为占位符从而避免 SQL 注入;而 ${} 占位符预编译阶段解析时会将值直接替换,存在 SQL 注入风险。
单表数据瓶颈:单表超出 1000 W推荐分库分表;
分页查询瓶颈:返回总页数或者确定聚簇索引后根据聚簇索引查询,避免查询 offset+n 条数据
推荐count(*)代替count(字段);
推荐查询具体字段代替select *;
-- 连续的ID分页查询
SELECT a.* FROM 表 1 a where a.id > 100000 limit 20
-- 不连续的ID分页查询
SELECT a.* FROM 表 1 a, (select id from 表 1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
-- 根据业务查询具体字段避免查询全部字段
select count(*) from user或select count(1) from user代替select count(name) from user
select id, name from user代替select * from user
-- #{}避免SQL依赖注入
<select id="selectAccumulate" resultType="java.lang.Integer">
SELECT count(1)
FROM user
WHERE user_id = #{userId}
and create_time between #{startTime} and #{endTime}
</select>
2.1.3 索引
1>聚簇索引、非聚簇索引
- 聚簇索引
(1)聚簇索引不是单独的一种索引类型,而是一种数据存储方式。
(2)这种存储方式是依靠B+树来实现的,根据表的主键构造一棵B+树且B+树叶子节点存放的都是索引 和 表行记录时,可称主键索引为聚簇索引。
(3)聚簇索引也可理解为将数据与索引存放在一起,找到了索引也就找到了数据。
(4)聚簇索引中,叶子节点包含完整的记录。而非聚簇索引中,叶子节点仅包含指向完整记录的指针,因此到了叶子节点后还需要做一次磁盘 IO - 非聚簇索引
(1)数据与索引是分开存放的,B+树叶子节点存放的不是数据表行记录,而是主键值或者数据表行记录的物理地址
2>索引使用 B+ 树 的优点
- 更少的磁盘 IO 次数
由于 B+ 树的中间节点不携带完整数据,所以每个节点(磁盘页)可以存放更多元素,使得树的深度更小,更加 “扁平”,从而减少磁盘 IO 次数。 - 性能更稳定
B 树的匹配结束位置既可能在中间节点,也可能在叶子节点,而 B+ 树一定在叶子节点,因此每次查找的时间都是相近的。 - 范围查找更方便
在 B 树中,需要先找到范围的下限,然后通过中序遍历查找到上限,而 B+ 树由于叶子节点是有序链表,所以找到了起点之后只需要顺序遍历到终点即可。
2.1.4 SQL 执行过程
语句的执行阶段 FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT
SQL执行语句前要先连接数据库,通过解析器,优化器,执行器,去查询缓存,但是在一个表上有更新的时候,跟这个表有关的查询缓存会失效;(在mysql8中没有缓存这个逻辑)
SQL接口处理收到的 SQL 语句,解析器将语句转换为数据库语言,优化器对语句优化,执行器根据优化器生成一套执行计划,去调用存储引擎接口完成语句执行计划。


2.1.5 Explain 语句执行计划分析
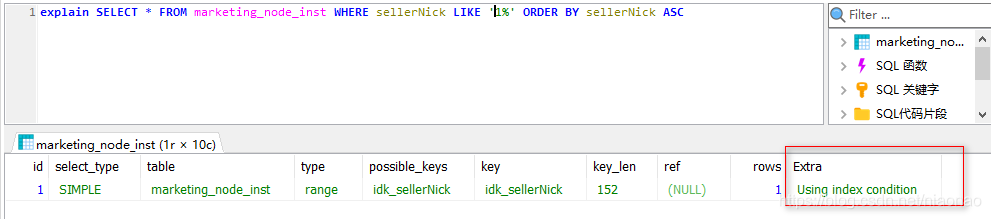
- 1、select_type 项
| 类型 | 说明 |
|---|---|
| SIMPLE | 简单SELECT,不使用UNION或子查询等 |
| PRIMARY | 子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY |
| UNION | UNION中的第二个或后面的SELECT语句 |
| DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,取决于外面的查询 |
| UNION RESULT | UNION的结果,union语句中第二个select开始后面所有select |
| SUBQUERY | 子查询中的第一个SELECT,结果不依赖于外部查询 |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,依赖于外部查询 |
| DERIVED | 派生表的SELECT, FROM子句的子查询 |
| UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外链接的第一行 |
- 2、type 项
全表查询 ALL 性能差,NULL性能最好
| 类型 | 说明 |
|---|---|
| ALL | Full Table Scan, MySQL将遍历全表以找到匹配的行 |
| index | Full Index Scan,index与ALL区别为index类型只遍历索引树 |
| range | 只检索给定范围的行,使用一个索引来选择行 |
| ref | 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 |
| eq_ref | 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件 |
| const、system | 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system |
| NULL | MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。 |
- 3、possible_keys 与 key
possible_keys 包含 key,是 key 的超集;查询可能会使用到的索引项,key是查询使用到的索引项 - 4、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度;不损失精确性的情况下,长度越短越好
(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的) - 5、rows
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 - 6、extra
| 类型 | 说明 |
|---|---|
| Using where | 不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤 |
| Using temporary | 表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by |
| Using filesort | 当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序” |
| Using join buffer | 改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。 |
| Impossible where | 这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。 |
| Select tables optimized away | 这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行 |
| No tables used | Query语句中使用from dual 或不含任何from子句 |
| Not exists | MySQL能够对查询执行 LEFT JOIN 优化,并且在找到与 LEFT JOIN 条件匹配的一行后,不会在上一行组合中检查此表中的更多行。 |
2.1.6 索引失效的情况
- 1、左模糊或全模糊查询时,根据 B+ 树结构可知,无法左模糊查询,索引失效。
- 2、索引列上使用范围查询 >、<、between 时索引失效。
- 3、条件查询存在 or 保留字时索引失效,建议使用 union 代替。
- 4、条件查询存在字段为 varchar 时,查询条件未加引号导致索引失效。
- 5、查询的结果集超过全表的 30% 时索引失效。不建议对枚举类型字段创建索引,比如常见的 status,type 字段。
- 6、查询条件使用函数在索引列上时索引失效。
- 7、字符串条件查询时,应单引号括起来,否则由于隐式转换会导致索引失效。
- 8、对于索引列进行逻辑运算,包括 +、-、* 、/、<>、! 等运算会索引失效,所以 != 在条件查询中会导致索引失效;这种情况下可以创建函数索引来处理。
- 9、对于组合索引,根据最左前缀原则不使用左边的字段,索引失效。
- 10、in、not in、exists、not exists 保留字的使用会索引失效。
- 11、B-tree索引 is null、is not null 不会走索引,位图索引 is null,is not null 都会走。
- 12、当变量采用的是times变量,而表的字段采用的是date变量时,或相反情况时索引失效。
2.1.7 SQL优化
- 1、检查SQL,解释执行优化语句
- 2、优先使用聚簇主键索引;
- 3、建议建立合适的单索引或聚合索引;
- 4、避免索引失效;
- 5、大SQL可以考虑通过业务去实现,不要都通过SQL去处理业务;
2.1.8 MySQL 锁机制
以下演示以 sys_config 表为例
CREATE TABLE `sys_config` (
`config_id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '参数主键',
`config_name` VARCHAR(100) NULL DEFAULT '' COMMENT '参数名称' COLLATE 'utf8_general_ci',
`config_key` VARCHAR(100) NULL DEFAULT '' COMMENT '参数键名' COLLATE 'utf8_general_ci',
`config_value` VARCHAR(500) NULL DEFAULT '' COMMENT '参数键值' COLLATE 'utf8_general_ci',
`config_type` CHAR(1) NULL DEFAULT 'N' COMMENT '系统内置(Y是 N否)' COLLATE 'utf8_general_ci',
`create_time` DATETIME NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME NULL DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR(500) NULL DEFAULT NULL COMMENT '备注' COLLATE 'utf8_general_ci',
PRIMARY KEY (`config_id`) USING BTREE
) COMMENT='参数配置表' COLLATE='utf8_general_ci' ENGINE=InnoDB;
1>表锁:共享(读)锁、排他(写)锁
表的读锁,多个事务可以同时读取,不可写,又称为共享锁
表的写锁,多个事务不可同时写,需阻塞,又称为排他锁
-- 查看表锁情况;解除表锁;对表 sys_config 加读锁,加写锁
SHOW OPEN TABLES
UNLOCK TABLES
LOCK TABLE sys_config READ
LOCK TABLE sys_config WRITE
-- 加了表锁之后,无法执行写操作
UPDATE sys_config SET remark = '备注事务一' WHERE config_id = 1;
/* SQL错误(1099):Table 'sys_config' was locked with a READ lock and can't be updated */
2>行锁,偏写锁,对于存在索引的表支持行锁
对于表 sys_config,不设置表锁时,两个事务同时对主键 config_id = 1 的记录执行更新语句。其中一个事务不提交,另一个事务会进入阻塞。当地一个事务提交后,其他事务才可执行。
使用 for update 可对记录主动加行锁,如果不是索引列则升级为表锁;
UPDATE sys_config SET remark = '备注事务一' WHERE config_id = 1;
/* SQL错误(1205):Lock wait timeout exceeded; try restarting transaction */


锁定某一行,其对该行的其他事务对其操作会被阻塞,直至锁定行的会话结束commit;
select * from sys_config where config_type = 1 for update;
commit;
2.1.9 悲观锁、乐观锁
- 悲观锁
拿到数据后就上锁,其他事务需等待,否不可写;行锁,表锁都是悲观锁; - 乐观锁
通过版本号的形式,拿到数据时认为不存在并发问题,认为其他事务的修改不会影响数据,在更新数据时通过版本号校验是否被其他事务修改了。
2.1.10 Binlog
配置 log-bin 开启日志文件记录
log-bin=C:\ProgramData\MySQL\BinlogData
# binlog 日志格式
binlog_format=ROW
1> binlog_format日志格式
- 1、STATEMENT
(1)MySQL 记录的是实际执行的 SQL 语句,而不是语句执行后的数据变更。
(2)对于某些非确定性的函数(如 UUID()、NOW() 等),或者依赖于服务器状态的操作,可能会导致主从数据不一致。 - 2、ROW
(1)MySQL 记录的是每一条记录的具体变化(即前后映像),而不是执行的 SQL 语句。
(2)由于直接记录了数据的变化,因此可以确保主从数据的一致性,即使面对非确定性操作也能正确处理 - 3、MIXED
结合了 STATEMENT 和 ROW 的优点,默认使用 STATEMENT 模式,但在遇到可能引起不一致的情况时自动切换到 ROW 模式。
2.1.11 主从同步
MySQL 的主从同步(Master-Slave Replication)是数据库高可用性和读写分离架构中的关键技术。
读写分离提高吞吐量和高可用;主从同步通过binlog日志进行异步复制实现;主从同步延迟解决方案:多主库,增大主库写吞吐量;
sync_binlog在slave端设置为0提升性能,表示MySQL不控制binlog刷新到磁盘;主库sync_binlog=1,每次写入 binlog 时都会调用 fsync() 将日志同步到磁盘,保证数据一致性。
innodb_flush_log_at_trx_commit 设置为1,确保了每个事务提交后数据都能持久化到磁盘,避免数据丢失。
2.1.11.1 一个主库两个从库配置参考
设置主库编号为1,唯一与其他从库编号不重复。编辑配置文件/etc/mysql/my.cnf
server-id=1
log-bin=mysql-bin
binlog-format=row
expire_logs_days=7
创建用于同步的用户
CREATE USER 'replicator'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'replicator'@'%';
FLUSH PRIVILEGES;
编辑从库编号为2,唯一与其他从库及主库编号不重复
server-id=2
# 指定中继日志文件名前缀。
relay-log=mysql-relay-bin
# 允许从库记录自己的更新操作,适用于多级复制
log-slave-updates=1
# 将从库设置为只读模式。
read-only=1
编辑从库编号为3
server-id=3
relay-log=mysql-relay-bin
log-slave-updates=1
read-only=1
配置从库2连接到主库1,执行SQL
-- 此处主库IP为192.168.1.1、同步用户密码replicator、123456
CHANGE MASTER TO
MASTER_HOST='192.168.1.1',
MASTER_USER='replicator',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='recorded_log_file_name',
MASTER_LOG_POS=recorded_log_position;
START SLAVE;
2.1.11.2 主从同步延迟
1>问题表象
从库的数据更新明显滞后于主库,导致查询结果不一致。
2>问题分析
- 1、大量写操作集中在短时间内发生,导致从库来不及处理。
- 2、主库上的大事务锁定了大量数据,使得从库无法及时应用这些更改。
- 3、网络带宽不足或网络不稳定。
- 4、从库的硬件资源(CPU、内存、磁盘 I/O)不足。
3>解决方案
- 1、拆分读写流量
通过读写分离策略减少从库的压力,避免所有读请求都指向同一台从库。 - 2、调整同步模式
考虑使用半同步复制(Semi-Synchronous Replication),在一定程度上保证主从数据的一致性。 - 3、优化 SQL 语句
避免长时间运行的大事务,尽量将批量插入拆分为小批次执行。 - 4、优化网络
确保主从之间的网络连接稳定且带宽足够。 - 5、增强硬件配置
升级从库的硬件资源,如增加 CPU 核心数、内存容量或使用 SSD 硬盘。
2.1.11.3 数据一致性问题
1>问题表象
主库与从库之间的数据不一致,某些记录在主库存在但在从库丢失,或者反之。
2>问题分析
- 1、同步中断后未正确恢复,导致部分 binlog 没有被应用。
- 2、主库上有直接修改从库的操作,破坏了数据一致性。
- 3、使用了非事务型存储引擎(如 MyISAM),在同步过程中出现问题时难以回滚。
3>解决方案
- 1、定期校验数据
使用 pt-table-checksum 和 pt-table-sync 工具定期检查并修复主从之间的数据差异。 - 2、禁用从库上的直接写操作
确保所有数据变更都通过主库进行,避免直接修改从库。 - 3、使用事务型存储引擎
推荐使用 InnoDB 存储引擎,它支持事务和行级锁定,有助于保持数据一致性。 - 4、启用 GTID(全局事务标识符)
使用 GTID 可以简化故障恢复过程,并确保主从之间的一致性。
2.1.11.4 同步中断及恢复
1>问题表象
由于网络故障、服务器重启等原因,主从同步中断,需要手动干预才能恢复。
2>问题分析
- 1、网络连接不稳定或断开。
- 2、主库或从库宕机后未能自动重新建立连接。
3>解决方案
- 1、启用自动重连
确保 MySQL 配置文件中设置了 slave_skip_errors 参数,允许从库自动跳过某些错误继续同步。 - 2、监控和报警系统
设置监控工具(如 Zabbix、Prometheus)来实时监控主从状态,并在出现问题时发送警报。 - 3、编写脚本自动化恢复
开发脚本来自动检测并修复同步中断,例如通过 START SLAVE 命令重启同步线程。
2.1.11.5 性能瓶颈
1>问题表象
从库性能显著低于主库,影响了整体系统的响应速度
2>问题分析
- 1、从库承担了过多的读请求,导致负载过高。
- 2、从库配置不当,如缓存大小、索引等设置不合理。
3>解决方案
- 1、合理分配读流量
通过负载均衡器或应用程序逻辑将读请求分散到多个从库,避免单点过载。 - 2、优化查询和索引
分析慢查询日志,优化 SQL 语句,添加必要的索引以提高查询效率。 - 3、调整 MySQL 参数
根据实际情况调整从库的 MySQL 配置参数,如 innodb_buffer_pool_size、query_cache_size 等。
2.1.12 MySQL 高级用法
-- 查询是否存在表
SELECT * from information_schema.tables WHERE TABLE_SCHEMA = 'niaonao' and TABLE_NAME IN ('position_history20220531','position_history20220530');
drop table if exists position_history20220531, position_history20220530;
-- 备份数据到csv
select * from position_history20220531 into OUTFILE './history20220531.csv' character set gbk fields terminated by ',' enclosed BY '\"';
-- 存在则更新;注意低版本 sharding 不支持 ON DUPLICATE KEY UPDATE
<insert id="batchInsert" >
insert into region_history
(region_id,region_name,map_name,floor,tag_id,user_name,statistics_date,status)
values
<foreach collection="list" item="item" separator="," >
(#{item.regionId},#{item.regionName},#{item.mapName},#{item.floor},#{item.tagId},#{item.userName},#{item.statisticsDate},#{item.status})
</foreach>
ON DUPLICATE KEY UPDATE region_name = values(region_name)
</insert>
2.1.13 慢 SQL 定位
-- 通过开启打印慢查询日志,一般线上不推荐这种方式
-- 开启慢查询、设置慢SQL时间
show variables LIKE '%SLOW%';
set global slow_query_log=on;
show variables LIKE 'long_query_time';
set long_query_time=on;
-- 分析慢SQL日志
pt-query-digest mysql-slow.log
-- 查看 SQL 的执行频率,判断高频插入、高频提交等操作
SHOW GLOBAL STATUS;
-- 查看那些线程在运行,定位低效率的 SQL
-- 查看 MYSQL 正在运行的线程、包括线程状态是否锁表等,info 也包含了具体的 SQL 语句
show PROCESSLIST;
-- 观察大事务、长事务、锁等待等状态
show engine innodb status
-- 查询最近15条SQL,及执行耗时情况
show profiles
-- 查询某条 SQL 耗时细项
show profile for query 2
2.2 Oracle
Oracle相对MySQL除了贵,没有缺点。
2.2.1 架构特性
- 1、Oracle
(1)支持多实例架构,允许在同一硬件上运行多个独立的数据库实例。
(2)提供强大的分区、并行查询、集群等高级特性。
(3)内置对 PL/SQL 的全面支持,是一种强大的过程化编程语言。
(4)数据库对象丰富,如表空间、索引组织表、外部表等。
(5)适用于非常大的数据集和高并发访问场景。
(6)提供了 RAC(Real Application Clusters)等高级集群技术,确保极高的可用性和扩展性 - 2、MySQL
(1)单实例架构为主,但可以通过复制和分片实现高可用性和扩展性。
(2)简单易用,安装配置便捷,性能优化较为直接。
(3)使用 SQL 作为主要的编程接口,也支持存储过程和触发器,但相比 Oracle 的 PL/SQL 功能较弱。
(4)插件式存储引擎架构,最常用的 InnoDB 引擎提供了 ACID 兼容的事务支持和外键约束。
(5)在中小型数据集和中等并发情况下表现出色.
(6)通过主从复制、读写分离、分库分表等方式可以实现良好的扩展性。
2.3 Redis
Key-Value类型的内存数据库。作为缓存提高性能。
(1)基本数据类型(String、Set、ZSet、List、Hash)
(2)持久化方式(AOF、RDB)
(3)缓存更新内存一致性(先更新sql后删除key)
(4)缓存穿透、击穿、雪崩(布隆过滤器,过期时间分散与续期避免同个时刻失效,互斥锁应对并发请求进行阻塞)
(5)缓存降级(自动降级、人工降级)
(6)Redis 集群(Sentinel哨兵、Redis Cluster)
(7)主从复制、主从一致、主从延迟
(8)淘汰策略(不淘汰、过期时间、保留热点数据删除最近最少使用的数据、随机删除)
2.3.1 为什么Redis速度很快
- 1、Redis数据存储在内存中
数据存储在内存,内存操作很快。避免了磁盘IO,磁盘IO比较耗时。 - 2、Redis异步持久化
支持AOF和RDB持久化方式。不是每次命令都会触发持久化。且持久化是异步操作,不影响主线程操作。 - 3、Redis是单线程的
Redis 使用单线程处理客户端请求,通过高效的事件循环(event loop)管理 I/O 操作。避免了线程切换开销和锁竞争。 - 4、非阻塞IO多路复用
Redis 利用操作系统提供的 I/O 多路复用技术,支持处理并发请求且不阻塞。 - 5、Redis的原子性命令
简化了并发控制逻辑 - 6、高效的数据结构
String List Set Zset Hash在内存中支持高效的查找、插入、删除操作 - 7、灵活的淘汰策略
当内存不足时,通过策略配置会淘汰一定的内存数据,保留常用的数据,提高命中率。 - 8、集群模式
集群模式支持水平扩展,提升性能
2.3.2 基本数据类型 String List Set Zset Hash
2.3.3 持久化方式 AOF、RDB
通过配置文件redis.conf配置。AOF和RDB同时开启,都会生效,启动时优先使用 AOF 文件
| 方式 | 原理 | 优缺点 |
|---|---|---|
| RDB | RDB 是通过创建快照的方式实现持久化的。在指定的时间间隔内,Redis 将内存中的数据集快照写入磁盘上的二进制文件(默认名为 dump.rdb)。当 Redis 重启时,它可以加载这个文件来恢复数据。 | 相比 AOF,RDB 在备份和恢复时速度更快。因为它是基于快照的,所以在两次快照之间发生的更改可能会丢失。 |
| AOF | AOF 记录的是服务器接收到的所有写命令,并以文本形式追加到文件末尾。当 Redis 重启时,它会重放这些命令来重建数据集。 | 几乎不会丢失数据,即使在断电等极端情况下也能保证最近一次操作的数据。频繁地将命令追加到文件中会对性能产生一定影响。 |
- 1、RDB方式
# 开启RDB方式,打开save命令即可。关闭RDB方式,注释save命令即可。
# save命令,多长时间内单位秒,存在多少个值变化时触发写入磁盘
save 60 10
# 自定义rdb文件名称
dbfilename dump.rdb
# 自定义rdb文件存储路径
dir D:\Redis\
# RDB 备份文件过程中错误时,停止redis set服务
stop-writes-on-bgsave-error no
- 2、AOF方式
# 开启AOF方式,appendonly yes开启。appendonly no关闭。AOF会记录过程,RDB只会记录结果
appendonly yes
# 自定义AOF文件名称
appendfilename "appendonly.aof"
# AOF同步策略。always 每执行一个命令便保存一次;everysec 每秒保存一次;no,在redis关闭或关闭aof模式时保存一次。
appendfsync everysec
2.3.4 缓存穿透、缓存雪崩、缓存击穿
| 类型 | 说明 | 解决方案 |
|---|---|---|
| 缓存穿透 | 访问的数据在数据库中不存在,在缓存中也不存在,导致每次都会穿透缓存访问数据库 | 布隆过滤器;非法请求参数业务校验避免无意义的请求参数;设置一个值为 null 的热点数据到缓存,并设置过期时间 |
| 缓存击穿 | 热点数据的缓存某个时刻失效,大量的请求直接击穿缓存访问到数据库,数据库压力骤增 | 互斥锁,大量请求只能有一个能拿到锁资源并阻塞,查到数据后放入缓存,后续请求会走缓存;设置合适的缓存过期时间或续期策略 |
| 缓存雪崩 | 大量的热点数据在某段时刻失效,对应的大量请求引起缓存雪崩,都会直接访问数据库,数据库压力骤增 | 热点数据过期时间避免在都在某个时间段;互斥锁(行锁、表锁等);合适的缓存过期时间或续期策略 |
| 缓存降级 | 缓存失效或者服务器挂掉的情况不去访问数据库 | 根据访问超时时间自动降级或可人工配置降级,数据库访问量超出最大阈值人工降级,不去访问缓存和数据库,直接返回默认结果 |
2.3.5 布隆过滤器
布隆过滤器解决了 Hash 碰撞的问题,类似 HashMap 是存在两个元素经过 Hash 取模后存放的位置是相同的位置,这个问题就是 Hash 碰撞问题。
布隆过滤器是基于bitmap和若干个hash算法实现的;在一个存在一定数量的集合中过滤一个对应的元素,判断该元素是否一定不在集合中或者可能在集合中;有一定的错误识别率,可配置误差范围参数,配置误差越小时查询效率越低,误差大查询效率高;
将所有热点数据的 key 存放到布隆过滤器,请求过来时校验布隆过滤器是否存在热点数据的 key,不存在则直接返回,存在再访问缓存,访问数据库。
为什么使用布隆过滤器不使用 HashMap,如果用HashSet或Hashmap存储的话,每一个用户ID都要存成int,占4个字节即32bit。而一个用户在bitmap中只需要1个bit,内存节省了32倍。
我们会把热点数据放入redis,同时面临的问题都是穿过 redis 访问数据库,给数据库带来压力;
2.3.6 并发一致性问题
1>问题
主从库延迟,延迟双删问题
缓存和数据库一致性问题
读写,写一定是写数据库,读可以读缓存;
设置缓存失效时间,保证热数据留下,无用的数据都不放在缓存中,且能有效保证数据一致性。
对于更新缓存和写入数据库是两步操作,存在并发问题;
删除缓存的方案,保证每次都是取数据库,然后放入缓存;
2>缓存并发一致性问题解决方案
先更新数据库,再更新缓存;
先更新缓存,再更新数据库;前两者都存在,数据库与缓存不一致的情况;
先删除缓存,再读取数据库,并发情况下,会读取到更新前的数据;
最优的方案是:**先写数据库,再删除缓存;**因为写数据库有锁,写的时间比读时间长。
为防止第一步成功,第二步失败,可以引入MQ或消息订阅,异步重试操作保证,第二步执行成功。
缓存一致性问题总结:
为了提高性能,引入缓存;
考虑缓存一致性问题,引入更新数据库+更新缓存;更新数据库+删除缓存;
更新数据库+删除缓存在并发下存在一致性问题,推荐使用先更新数据库+后删除缓存;
引入MQ消息不丢失,异步重试操作方式多步骤操作中后续步骤失败。
2.3.7 Redis 删除策略
当内存用完时,会按照删除策略删除热点数据。
redis.conf配置删除策略,设置maxmemory、maxmemory-policy参数控制Redis实例内存限制及删除策略
maxmemory 1gb
maxmemory-policy allkeys-lru
- 1、noeviction 不删除策略, 达到最大内存限制时,继续 set 缓存数据会报错
- 2、allkeys-lru 全部数据删除最少使用策略;优先删除最近最少使用(less recently used ,LRU) 的 key。
- 3、volatile-lru 设置过期时间数据删除最少使用策略;
- 4、allkeys-random 全部数据随机删除策略;
- 5、volatile-random 设置过期时间的数据随机删除策略;
- 6、volatile-ttl 设置过期时间的数据,优先删除剩余时间最短的策略;优先删除剩余时间(time to live,TTL) 短的key。
2.3.8 Redis 集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
集群的缺点是批量删除性能,因为key存放在不同的插槽上。
2.3.8.1 配置集群
1>配置集群
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
2>启动集群
redis-cli --cluster create --cluster-replicas 1 192.168.11.101:6379 192.168.11.101:6380 192.168.11.101:6381 192.168.11.101:6389 192.168.11.101:6390 192.168.11.101:6391
2.3.8.2 Proxy+Replication+Sentinel
1>工作原理
前端使用Twemproxy+KeepAlived做代理,将其后端的多台Redis实例分片进行统一管理与分配
每一个分片节点的Slave都是Master的副本且只读
Sentinel持续不断的监控每个分片节点的Master,当Master出现故障且不可用状态时,Sentinel会通知/启动自动故障转移等动作
Sentinel 可以在发生故障转移动作后触发相应脚本(通过 client-reconfig-script 参数配置 ),脚本获取到最新的Master来修改Twemproxy配置
2>Sentinel 哨兵模式 监控、通知、故障转移
哨兵监控各个节点服务,当主节点宕机,会选一个从节点升为主节点,保证服务的高可用;监控服务状态是否正常运行,监测到服务不可用,会通过API 脚本通知管理员
2.3.8.3 Redis Cluster 集群
1>原理
(1)客户端与Redis节点直连,不需要中间Proxy层,直接连接任意一个Master节点。根据公式HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作。
(2)类似 Hash 环,Redis Cluster采用HashSlot来实现Key值的均匀分布和实例的增删管理。首先默认分配了16384个Slot,每个Slot相当于一致性Hash环上的一个节点。集群的所有实例将均匀地占有这些Slot,而最终当我们Set一个Key时,使用CRC16(Key) % 16384来计算出这个Key属于哪个Slot,并最终映射到对应的实例上去。集群扩展性,要增加一个节点D,RedisCluster的做法是将之前每台机器上的一部分Slot移动到D上,删除某个节点,就是将节点上Solt归还给源节点
2>特性
(1)无需Sentinel哨兵监控,如果Master挂了,Redis Cluster内部自动将Slave切换Master
(2)可以进行水平扩容
(3)支持自动化迁移,当出现某个Slave宕机了,集群自动把多余的Slave迁移到没有Slave的Master 中
3>为什么是16384个槽
(1)集群节点越多,心跳包的消息体携带的数据越多。如果节点超过1000个,会导致网络拥堵。因此 redis 的作者,不建议 redis cluster 节点数量超过 1000 个。16384 个插槽范围比较合适,当集群扩展到1000个节点时,也能确保每个master节点有足够的插槽。
(2)正常的心跳数据包携带节点的完整配置,它能以幂等方式来更新配置。每秒 redis 节点需要发送一定数量的 ping 消息作为心跳包,如果槽位为 65536,这个 ping 消息的消息头太大了,浪费带宽;如果采用 16384 个插槽,占空间 2KB (16384/8);如果采用 65536 个插槽,占空间 8KB (65536/8)。
(3)槽位越小,节点少的情况下,压缩率更高。
2.3.9 Redis 分布式锁
主从复制、主从同步、主从延迟仍然是同步刷新和异步刷新两种方式;一个保证效率一个保证数据一致性;
Redis事务不支持回滚,弃用;推荐分布式事务 SEATA
1>原理
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放;
如果 SETNX 返回1,说明该进程获得锁;返回 0 说明其他线程持有锁资源。
set 命令本身就支持复杂的参数,以支持 nx,ex,px操作。
EX seconds : 将键的过期时间设置为 seconds 秒。 执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
PX milliseconds : 将键的过期时间设置为 milliseconds 毫秒。 执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
NX : 只在键不存在时, 才对键进行设置操作。 执行 SET key value NX 的效果等同于执行 SETNX key value 。
2.3.10 无阻塞取值 scan、keys
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
一般人会说:使用keys指令可以扫出指定模式的key列表。
如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
因为redis的单线程的,keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。·
2.3.11 Redis 命令
# dbsize 返回当前数据库 key 的数量
# info 返回当前 Redis 服务器状态和一些统计信息
# monitor 实时监听并返回Redis服务器接收到的所有请求信息
# shutdown 把数据同步保存到磁盘上,并关闭Redis服务
# config get parameter 获取一个 Redis 配置参数信息
# config set parameter value 设置一个 Redis 配置参数信息
# config resetstat 重置 info 命令的统计信息
# debug segfault 制造一次服务器当机
# flushdb 删除当前数据库中所有 key
# flushall 删除全部数据库中所有 key
2.3.12 Redis 持久化扩容与缓存扩容
如果Redis被当做缓存使用,使用一致性哈希算法实现动态扩容缩容。
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
2.4 ShardingSphere
分库分表解决方案 ShardingSphere
(1)主从库集群(mode.type: Cluster)
(2)主动同步(binlog)
(3)数据分片(逻辑表、真实表)
(4)分布式事务(SEATA)
(5)读写分离(rules.readwrite-splitting)
(6)负责均衡(ROUND_ROBIN、RANDOM、WEIGHT)
(7)数据加密
2.4.1 分库分表
分库分表(Sharding)是一种数据库水平扩展策略,旨在通过将数据分散到多个数据库或表中来解决单个数据库性能瓶颈和容量限制的问题。
1>概念
- 1、分库
将数据分布到多个物理数据库实例上。每个实例负责存储一部分数据,从而减轻单个数据库的压力。 - 2、分表
在同一个数据库内创建多个表来存储不同类型或时间段的数据。例如,按照日期、用户 ID 范围等规则进行划分。
分库分表除了逻辑分片,也可以业务分表;比如按时间分表,某一段时间的数据放入一张表;新数据入新表;按活动类型分表,某一个活动类型的表入一张表,新活动类型入新的表;
2>解决了什么问题
- 1、突破单机磁盘容量限制
(1)随时应用服务时长及业务数据增长,数据量持续增长会导致磁盘空间不足。分库分表允许数据部署在多台机器上,突破单机容量限制 - 2、性能瓶颈
(1)随着业务增长,单一数据库难以承受不断增加的并发访问量。分库分表通过分散负载,使得每台服务器只需处理部分请求,降低了系统的响应时间。
(2)分库分表,允许根据业务类型或业务数据时间等维度分表查询,降低了查询量级,全表扫描对查询性能影响较大。 - 3、动态扩容
(1)当资源容量达到饱和时,可以通过增加数据库实例或表,来扩容
3> 水平分片
分片是一种水平分区模式,将一个表的行为拆分为多张表(分区)的实践。
- 1、水平分片
根据某个字段(分片键)或某种规则将数据分散至多个库或表;按行数据拆分,多张表的行数据不一样; - 2、垂直分片
按业务拆库拆表,专库专用;
(1)根据键值分片
根据键值基于哈希进行分片,进行哈希值计算的是分片键(表的某一列)
(2)根据范围分片
基于给定值的范围进行分片
(3)基于目录分片
需要建立一个使用分片键的查找表,以跟踪那个分片保存哪些数据

2.4.2 ShardingSphere
Apache ShardingSphere 是一个广泛使用的数据库分片中间件,它不仅支持数据的水平分片(Sharding),还提供了读写分离、分布式事务、数据加密等多种功能。
2.4.2.1 特性
- 1、数据分片(Sharding)
(1)支持基于键值、范围、哈希等策略的数据分片。提供多种内置的分片算法,并允许用户自定义分片规则
(2)根据业务特性,当当网将订单、用户等核心数据表进行了水平拆分。例如,订单表按照 order_id 进行哈希取模,分散到多个数据库实例中;用户表则根据 user_id 范围进行划分。
(3)对于一些非核心但数据量较大的表(如日志、评论),当当网采取了垂直拆分的方式,即将这些表独立出来,放置在专门的数据库中,以减轻主数据库的负担。 - 2、读写分离
(1)支持主从复制架构中的自动读写分离,提高读性能。
(2)当当网构建多台只读从库,用于处理大部分的读请求。ShardingSphere 自动识别并路由查询到合适的从库,从而提高了系统的整体读性能。 - 3、分布式事务
(1)支持 XA、SAGA 和 TCC 等分布式事务协议,确保跨多个分片的一致性
(2)在涉及资金交易等需要强一致性的业务中,当当网采用了 XA 或 TCC 分布式事务协议,确保跨多个分片的操作能够原子性地完成。
(3)对于一些对实时性要求不高的业务(如商品库存更新),当当网则选择了基于消息队列的异步处理方式,实现了最终一致性。 - 4、数据脱敏与加密
(1)内置数据脱敏和加密功能,保护敏感信息的安全。 - 5、SQL 解析与优化
(1)强大的 SQL 解析引擎,能够处理复杂的查询语句并进行优化。 - 6、高可用性和扩展性
(1)借助配置中心(如 Nacos),当当网实现了分片规则的动态调整,可以根据实际业务需求随时增加新的数据库实例或修改现有规则,而无需重启服务。
(2)ShardingSphere 提供了完善的故障检测和自动切换机制,当某个数据库实例出现故障时,系统会自动将流量转移到其他健康的实例上,保障了服务的连续性。
ShardingSphere-JDBC、ShardingSphere-Proxy 均提供标准化的数据水平扩展、分布式事务和分布式治理等功能;
ShardingSphere-JDBC作为增强版 jdbc驱动,完美支持 jdbc 和所有 ORM 框架,适用于 Java 开发的高性能的轻量级;
ShardingSphere-Proxy 作为数据库代理端,更适合运维人员,对分片数据库进行管理和运维的场景;
ShardingSphere-JDBC 支持所有实现JDBC的数据库(MySQL、Oracle、PostgreSQL)、所有的数据库连接池(C3P0、DBCP)、支持所有的 ORM (Object Relational Mapping 对象关系映射)框架(JPA、Hibernate、Mybatis)
2.4.2.2 具体案例
在一次大型促销活动中,当当网成功利用 ShardingSphere 实现了以下成果:
- 1、订单处理能力大幅提升
即使在高峰期,订单创建和查询的速度也保持稳定,用户体验良好。 - 2、库存管理更加高效
通过分布式事务和消息队列相结合的方式,确保了库存数据的一致性和准确性。 - 3、系统稳定性增强
整个活动期间未发生因数据库压力过大而导致的服务中断事件。
2.4.2.3 其他公司解决方案
| 技术 | ShardingSphere | TSharding | Cobar | MyCAT |
|---|---|---|---|---|
| 公司 | 当当 | 蘑菇街 | 阿里巴巴 | Cobar |
2.4.2.4 熔断限流
某个 ShardingSphere 节点超出负载时,停止该节点对数据库的访问;
对超负荷的请求进行限流,保护部分请求得到及时的响应。
2.4.2.5 分片键
用于将数据库(表)水平拆分的数据库字段。根据分片键打散各个数据到各个数据节点(分片);
2.4.2.6 分片算法
用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。
分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
内置分片算法:
- 取模分片算法 MOD
- 哈希取模分片算法 HASH_MOD
- 基于分片容量的范围分片算法 VOLUME_RANGE
- 基于分片边界的范围分片算法 BOUNDARY_RANGE
- 自动时间段分片算法 AUTO_INTERVAL
2.4.2.7 分片策略
分片键+分片算法
2.4.2.8 逻辑表、真实表、单表
数据库中进行分片拆分的表就是逻辑表;不进行分片拆分的表是单表;
对于数据库中逻辑表 t_order 进行分片拆分后真实存在的表 t_order1、t_order2 是真实表
2.4.2.9 负责均衡算法
支持单机和集群模式,集群环境需要通过独立部署的注册中心来存储元数据和协调节点状态。
- WEIGHT 权重算法
- ROUND_ROBIN 轮询算法
- RANDOM 随机算法
2.4.2.10 数据库兼容性问题
shardingsphere5.0.0之前的版本不支持 MySQL 插入或更新语法 ON DUPLICATE KEY UPDATE
不支持 MySQL 本地克隆 CLONE LOCAL DATA DIRECTORY
脱敏字段无法支持计算操作,比如>、<、sum()、avg()等
2.4.2.11 分布式事务
数据库事务满足ACID(原子性、一致性、隔离性、持久性)
1>柔性事务
提倡采用最终一致性放宽对强一致性的要求,以达到事务处理并发度的提升。
ShadingSphehe 集成 SEATA 作为柔性事务的使用方案,SEATA 实现了 SQL 反向操作的自动生成。
| 本地事务 | 两(三)阶段事务 | 柔性事务 | |
|---|---|---|---|
| 业务改造 | 无 | 无 | 实现相关接口 |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性 | 不支持 | 支持 | 业务方保证 |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
| 支持项 | 支持非跨库事务;支持因逻辑异常导致的跨库事务 | 支持嵌套事务;支持分片跨库事务;保证原子操作和数据强一致性;服务宕机事务自动恢复 | 支持分片跨库事务;支持读提交隔离级别;服务宕机自动恢复提交中的事务 |
2.4.2.12 读写分离、主从同步
分库分表中一般有主从库,一主多从;
1>读写分离
根据SQL语义分析,读操作和写操作分别路由至主库和从库;提高了系统的吞吐量和高可用。
2>主从同步
将主库的数据异步的同步到从库的操作。 由于主从同步的异步性,从库与主库的数据会短时间内不一致;通过binlog日志实现主从同步
- 主库:写操作 insert、update、delete
- 从库:读操作 select
spring:
shardingsphere:
# 数据源配置
datasource:
# 规则配置
rules:
readwrite-splitting:
data-sources:
ds0: #主库从库逻辑数据源定义 ds0 为 user_db
write-data-source-name: master
read-data-source-names: slave
load-balancer-name: round-robin
load-balancers:
round-robin: # 负载均衡算法
type: ROUND_ROBIN # 轮询
3>模式配置
mode: # 不配置则默认内存模式
type: Cluster # 运行模式类型。可选配置:Memory、Standalone、Cluster
repository:
type: # 持久化仓库类型
props: # 持久化仓库所需属性
namespace: # 注册中心命名空间
server-lists: # 注册中心连接地址
foo_key: foo_value
bar_key: bar_value
overwrite: # 是否使用本地配置覆盖持久化配置
4>数据源配置
dataSources:
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/ds_1
username: root
password:
ds_2:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/ds_2
username: root
password:
5>数据分片规则
rules:
- !SHARDING
tables: # 数据分片规则配置
<logic-table-name> (+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 分片算法名称
complex: # 用于多分片键的复合分片场景
shardingColumns: # 分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
none: # 不分片
tableStrategy: # 分表策略,同分库策略
keyGenerateStrategy: # 分布式序列策略
column: # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: # 分布式序列算法名称
autoTables: # 自动分片表规则配置
t_order_auto: # 逻辑表名称
actualDataSources (?): # 数据源名称
shardingStrategy: # 切分策略
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 自动分片算法名称
bindingTables (+): # 绑定表规则列表
- <logic_table_name_1, logic_table_name_2, ...>
- <logic_table_name_1, logic_table_name_2, ...>
broadcastTables (+): # 广播表规则列表
- <table-name>
- <table-name>
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
defaultShardingColumn: # 默认分片列名称
# 分片算法配置
shardingAlgorithms:
<sharding-algorithm-name> (+): # 分片算法名称
type: # 分片算法类型
props: # 分片算法属性配置
# ...
# 分布式序列算法配置
keyGenerators:
<key-generate-algorithm-name> (+): # 分布式序列算法名称
type: # 分布式序列算法类型
props: # 分布式序列算法属性配置
# ...
6>读写分离规则
rules:
- !READWRITE_SPLITTING
dataSources:
<data-source-name> (+): # 读写分离逻辑数据源名称
type: # 读写分离类型,比如:Static,Dynamic
props:
auto-aware-data-source-name: # 自动发现数据源名称(与数据库发现配合使用)
write-data-source-name: # 写库数据源名称
read-data-source-names: # 读库数据源名称,多个从数据源用逗号分隔
loadBalancerName: # 负载均衡算法名称
# 负载均衡算法配置
loadBalancers:
<load-balancer-name> (+): # 负载均衡算法名称
type: # 负载均衡算法类型
props: # 负载均衡算法属性配置
# ...
3. Spring 框架、SpringBoot、SpringCLoud、Dubbo
3.1 Spring
(1)spring IOC(容器管理,bean依赖注入控制反转)
(2)spring AOP原理(基于代理面前切面编程,应用于日志打印,全局校验,访问拦截等)
(3)spring 5
(4)springMVC
(5)事务管理(ACID、传播特性、隔离级别)
(6)循环依赖
(7)spring设计模式等(单例、工厂、代理、责任链)

3.1.1 事务管理
1>事务特性
ACID 原子性、一致性、隔离性、持久性
2>隔离级别
读提交、读未提交、重复读、序列化;Spring 事务还有个默认级别,数据库配置什么,Spring就是什么。
3>传播行为
| 类型 | 说明 |
|---|---|
| required | 当前存在事务,则加入事务;不存在则新建事务,加入新的事务 |
| required_new | 无论当前是否存在事务,新建一个事务,加入新的事务 |
| supports | 当前存在事务,则加入事务,不存在则以非事务运行 |
| not_supported | 当前存在事务,则挂起事务,不存在则以非事务运行 |
| mandatory | 当前存在事务,则加入事务,不存在则抛异常 |
| never | 当前存在事务,则抛异常,不存在则以非事务运行 |
| nested | 当前存在事务,则嵌套事务,不存在则新建事务 |
4>Spring 事务
- 1、声明式事务
@Transaction 或 xml 配置 - 2、编程式事务
beginTransaction()、commit()、rollback();
3.1.2 声明式事务失效场景
- 1、@Transactional仅支持public方法
- 2、@Transactional(propagation=Propagation.NEVER) 传播特性设置不支持事务时,抛异常事务失效,以及其他不支持事务的特性Propagation.NOT_SUPPORTED
- 3、抛出的异常被try catch时,无法回滚事务
- 4、事务不支持嵌套;@Transactional,方法嵌套调用失效
// AbstractFallbackTransactionAttributeSource.class
// 声明式事务的方法必须为public方法
@Nullable
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
if (this.allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
...
}
// 抛出的异常被try catch时,无法回滚事务;默认只回滚 RuntimeException 异常,所以建议指定异常以兼容更多场景
@Transactional(rollbackFor=Exception.class)
public void add() throws Exception {
try {
...
} catch (Exception e) {}
}
// 对于方法 test1 test2
// test1 有事务,test2 无事务,事务生效
// test1 有事务,test2 有事务,事务生效
// test1 无事务,test2 有事务,事务不生效
// test1 无事务,test2 无事务,事务不生效
3.1.3 Spring 常用注解
@Component:泛指各种组件
@Controller、@Service、@Repository都可以称为@Component。
@Controller:控制层
@Service:业务层
@Repository:数据访问层
@Value 获取指定名称的配置
@Bean
@Import
注入注解
@Autowired 存在多个实现时,可以配合 @Qualifier 指定名称注入
@Resource 按名称匹配
@Qualifier 强制指定选择
@Primary 默认首选,例如多个数据源配置时,可以指定主配置类
配置注解
@Configuration 声明当前类为配置类;
@Bean 注解在方法上,声明当前方法的返回值为一个bean,替代xml中的方式;
@ComponentScan 扫描可以供 IOC 容器管理的类
切面注解(在java配置类中使用@EnableAspectJAutoProxy注解开启Spring对AspectJ代理的支持)
@Aspect 声明一个切面
@After 在方法执行之后执行(方法上)
@Before 在方法执行之前执行(方法上)
@Around 在方法执行之前与之后执行(方法上)
@PointCut 声明切点
异步注解
@EnableAsync 配置类中通过此注解开启对异步任务的支持;
@Async 在实际执行的bean方法使用该注解来声明其是一个异步任务(方法上或类上所有的方法都将异步,需要@EnableAsync开启异步任务)
定时任务注解
@EnableScheduling 在配置类上使用,开启计划任务的支持(类上)
@Scheduled 标识一个任务,包括cron,fixDelay,fixRate等类型
enable 注解,开启对xx的支持
@EnableAspectAutoProxy:开启对AspectJ自动代理的支持;
@EnableAsync:开启异步方法的支持;
@EnableScheduling:开启计划任务的支持;
@EnableWebMvc:开启web MVC的配置支持;
@EnableConfigurationProperties:开启对@ConfigurationProperties注解配置Bean的支持;
@EnableJpaRepositories:开启对SpringData JPA Repository的支持;
@EnableTransactionManagement:开启注解式事务的支持;
@EnableCaching:开启注解式的缓存支持;
3.1.4 SpringMVC 常用注解
@EnableWebMvc
@Controller
@RequestMapping
@ResponseBody
@RequestBody
@PathVariable
@RestController
@ControllerAdvice 全局数据处理
@ExceptionHandler 用于全局处理控制器里的异常
@ModelAttribute
@Transactional
3.1.5 SpringBoot 常用注解
@SpringBootApplication 启动类,开启自动配置
@EnableAutoConfiguration 根据声明的依赖,自动装载配置 @ImportAutoConfiguration 导入指定配置类
@SpringBootConfiguration 代替 @Configuration
@ImportResource
@Scope 指定 bean 的作用域
@Profile 在那个环境下被激活
@RequestParam
@PostMapping @GetMapping @PutMapping @DeleteMapping
@Service 标记当前类是一个service类,自动装载到 IOC,不需要xml配置bean
@Mapper @MapperScan 不需要 xml 配置就可管理 mapper 映射
@Component @ComponentScan 自动扫描加载 bean 组件到 IOC 容器
@Entity @Table @Column @Setter @Getter标识实体类映射数据表
@Builder 标识当前类可以通过建造者创建对象
@EnableTransactionManagement 启用事务管理,不需要 xml 配置bean
@Slf4j 简单日志门面代替 private final Logger logger = LoggerFactory.getLogger(当前类名.class);
3.1.6 SpringCloud 常用注解
@SpringCloudApplication 包含pringBoot注解、注册服务中心注解、断路器注解 @SpringBootApplication、@EnableDiscovertyClient、@EnableCircuitBreaker
@EnableEurekaServer @EnableDiscoveryClient 服务注册发现
@LoadBalanced 开启负载均衡能力;
@EnableCircuitBreaker 用在启动类上,开启断路器功能;
@HystrixCommand(fallbackMethod=”backMethod”) 用在方法上,fallbackMethod指定断路回调方法;
@EnableConfigServer 用在启动类上,表示这是一个配置中心,开启Config Server;
@EnableZuulProxy 开启zuul路由,用在启动类上;
3.2 SpringMVC
1>SpringMVC 原理
DispatcherServlet 转发 Handler 处理器处理给具体的 Servlet 然后处理请求,返回指定的 ModeAndView
3.3 SpringBoot
3.3.1 特征
- 1、致力于快速开发,避免繁杂的配置,引入自动装配
- 2、直接嵌入 Tomcat、Jetty 或 Undertow
- 3、提供 boot-start 依赖,比如 jdbc,druid,redis,pageHelper,test
- 4、尽可能自动配置 Spring 和 3rd 方库
- 5、提供生产就绪功能,例如指标、健康检查和外部化配置
- 6、自动装配 Spring,无需 XML 配置,提供 yml 风格
3.3.2 集成中间件
springboot 与 redis 数据库集成操作 综合案例 分布式缓存
springboot 与 ElasticSearch 分布式搜索引擎 技术 综合案例
springboot 与 MongoDB nosql 综合案例
springboot 与 MQ(RabbitMQ)集成 综合案例
3.3.3 SpringBoot 自动装载原理
org.springframework.boot.autoconfigure.SpringBootApplication.class
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = {@Filter(type = FilterType.CUSTOM, classes = {TypeExcludeFilter.class}), @Filter(type = FilterType.CUSTOM, classes = {AutoConfigurationExcludeFilter.class})})
public @interface SpringBootApplication {
@AliasFor(annotation = EnableAutoConfiguration.class)
Class<?>[] exclude() default {};
@AliasFor(annotation = EnableAutoConfiguration.class)
String[] excludeName() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackages")
String[] scanBasePackages() default {};
@AliasFor(annotation = ComponentScan.class, attribute = "basePackageClasses")
Class<?>[] scanBasePackageClasses() default {};
}
org.springframework.boot.autoconfigure.EnableAutoConfiguration.class
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
org.springframework.boot.autoconfigure.AutoConfigurationImportSelector.class
public class AutoConfigurationImportSelector implements DeferredImportSelector, BeanClassLoaderAware, ResourceLoaderAware, BeanFactoryAware, EnvironmentAware, Ordered {
...
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!this.isEnabled(annotationMetadata)) {
return NO_IMPORTS;
} else {
AutoConfigurationMetadata autoConfigurationMetadata = AutoConfigurationMetadataLoader.loadMetadata(this.beanClassLoader);
AutoConfigurationImportSelector.AutoConfigurationEntry autoConfigurationEntry = this.getAutoConfigurationEntry(autoConfigurationMetadata, annotationMetadata);
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
}
...
}

org.springframework.boot.autoconfigure.web.servlet.HttpEncodingAutoConfiguration.class
@Configuration
@EnableConfigurationProperties({HttpProperties.class})
@ConditionalOnWebApplication(type = Type.SERVLET)
@ConditionalOnClass({CharacterEncodingFilter.class})
@ConditionalOnProperty(prefix = "spring.http.encoding",value = {"enabled"},matchIfMissing = true)
public class HttpEncodingAutoConfiguration {
private final Encoding properties;
public HttpEncodingAutoConfiguration(HttpProperties properties) {
this.properties = properties.getEncoding();
}
...
}
org.springframework.boot.autoconfigure.http.HttpProperties.class
@ConfigurationProperties(prefix = "spring.http")
public class HttpProperties {
private boolean logRequestDetails;
private final HttpProperties.Encoding encoding = new HttpProperties.Encoding();
public HttpProperties() {
}
...
}
- 1、SpringBoot启动的时候加载主配置类@SpringBootApplication,开启了自动配置功能 @EnableAutoConfiguration
- 2、EnableAutoConfiguration 自动装配注解通过 AutoConfigurationImportSelector 实现给容器自动导入组件;然后将类路径下 META-INF/spring.factories 里面配置的所有AutoConfiguration的值加入到了容器中;(org.springframework.boot.autoconfigure.EnableAutoConfiguration 的属性值即待导入的组件)
- 3、每一个自动配置类进行自动配置功能;
- 4、以HttpEncodingAutoConfiguration(Http编码自动配置)为例解释自动配置原理;一但这个配置类生效,这个配置类就会给容器中添加各种组件,这些组件的属性是从对应的properties类中获取的,这些类里面的每一个属性又是和配置文件绑定的;
(1)@Configuration //表示这是一个配置类,也可以给容器中添加组件
(2)@EnableConfigurationProperties//启动指定类的ConfigurationProperties功能;将配置文件中对应的值和HttpProperties绑定起来;并把HttpProperties加入到ioc容器中
(3)@ConditionalOnWebApplication //Spring底层@Conditional注解:根据不同的条件,如果满足指定的条件,整个配置类里面的配置就会生效; 判断当前应用是否是web应用,如果是,当前配置类生效
(4)@ConditionalOnClass(CharacterEncodingFilter.class) //判断当前项目有没有CharacterEncodingFilter这个类;CharacterEncodingFilter类是SpringMVC中进行乱码解决的过滤器;
(5)@ConditionalOnProperty(prefix = “spring.http.encoding”, value = “enabled”, matchIfMissing=true) //判断配置文件中是否存在 spring.http.encoding.enabled这个配置;如果不存在,判断也是成立的
3.4 SpringCloud
3.4.1 微服务面临问题
- 服务治理
解决小服务之间的管理问题;服务注册与发现 SpringCloud Eureka、SpringCloud Alibaba Nacos - 服务调用
解决小服务之间的通讯问题;Feign是一种声明式、模板化的HTTP客户端。 - 服务网关
解决微服务客户端的访问问题;网关路由管理 Netflix Zuul、SpringCloud GateWay - 服务容错
解决微服务出现问题的解决;负载均衡 Netflix Ribbon,熔断器 Netflix Hystrix - 链路追踪
解决微服务出错的定位问题 SpringCloud Bus


3.4.2 SpringCloud 核心组件
- 1、SpringCloud Netflix
核心组件,可以对多个Netflix OSS开源套件进行整合,包括以下几个组件:
(1)Eureka:服务治理组件,包含服务注册与发现
(2)Hystrix:容错管理组件,实现了熔断器
(3)Ribbon:客户端负载均衡的服务调用组件
(4)Feign:基于Ribbon和Hystrix的声明式服务调用组件
(5)Zuul:网关组件,提供智能路由、访问过滤、频控限制等功能
(6)Archaius:外部化配置组件 - 2、SpringCloud Config
配置中心,支持客户端配置信息刷新、加密/解密配置内容等。 - 3、SpringCloud Bus
事件、消息总线,用于传播集群中的状态变化或事件,以及触发后续的处理 - 4、SpringCloud Security
基于spring security的安全工具包,为我们的应用程序添加安全控制 - 5、SpringCloud Consul
封装了Consul操作,Consul是一个服务发现与配置工具(与Eureka作用类似),与Docker容器可以无缝集成
3.4.3 Ribbon 负载均衡
提供负责均衡、容错、异步和多协议(HTTP,TCP,UDP)支持、缓存、批处理功能
- 1、原理
服务消费者发起请求
LoadBalancerInterceptor拦截器拦截请求
RibbonLoadBanlancerClient根据请求中的uri获取到服务提供者的id
通过DynamicServerListLoadBalancer根据id从eureka服务端拉去服务列表
通过Ribbon负载均衡规则选择某个服务 - 2、负载均衡策略:
RoundRobinRule 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。
AvailabilityFilteringRule 对以下两种服务器进行忽略
WeightedResponseTimeRule 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个权重值会影响服务器的选择。
ZoneAvoidanceRule 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,而后再对Zone内的多个服务做轮询。
BestAvailableRule 忽略那些短路的服务器,并选择并发数较低的服务器。
RandomRule 随机选择一个可用的服务器。
RetryRule 重试机制的选择逻辑 - 3、注解
@LoadBalanced 在RestTemplate的bean上再添加一个@LoadBalanced注解即可。
3.4.4 Feign 声明性 rest 客户端
Feign是一个声明式的Web服务客户端。这使得Web服务客户端的写入更加方便 要使用Feign创建一个界面并对其进行注释。它具有可插拔注释支持,包括Feign注释和JAX-RS注释。Feign还支持可插拔编码器和解码器。Spring Cloud添加了对Spring MVC注释的支持,并在Spring Web中使用默认使用的HttpMessageConverters。Spring Cloud集成Ribbon和Eureka以在使用Feign时提供负载均衡的http客户端。
@EnableFeignClients
@FeignClient
3.4.5 Zuul/GateWay 服务网关
Zuul是Netflix的基于JVM的路由器和服务器端负载均衡器。
API网关可以提供一个单独且统一的API入口用于访问内部一个或多个API。简单来说嘛就是一个统一入口,比如现在的支付宝或者微信的相关api服务一样,都有一个统一的api地址,统一的请求参数,统一的鉴权。
@EnableZuulProxy
@EnableZuulServer
| 服务网关 | Zuul | GateWay |
|---|---|---|
| 实现 | 基于Servlet | |
| 异步 | 不支持 | 支持 |
| 扩展性 | 扩展性低 | 扩展性高,实现了限流、负载均衡 |
身份认证与安全:识别每个资源的验证要求,并拒绝那些与要求不符的请求。
审查与监控:在边缘位置追踪有意义的数据和统计结果,从而带来精确的生产视图。
动态路由:动态地将请求路由到不同的后端集群。
压力测试:逐渐增加指向集群的流量,以了解性能。
负载分配:为每一种负载类型分配对应容量,并启用超出限定值的请求。
静态响应处理:在边缘位置直接建立部分相应,从而避免其转发到内部集群。
3.4.6 Hystrix 断路器
应对服务雪崩
1>熔断器
容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。
在一个分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败,这个就是Hystrix需要做的事情。Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用
2>熔断策略
当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务.
断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况,如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN).
3>熔断降级
Fallback 当请求后端服务异常时,返回默认的响应结果
Cache 对于同样的请求,把缓存直接返回
监控接口状态
3.4.7 SpringCloud Config 配置中心
@EnableConfigServer
3.4.8 SpringCloud Eureka 服务注册发现
当客户端注册Eureka时,它提供有关自身的元数据,例如主机和端口,运行状况指示符URL,主页等。Eureka从属于服务的每个实例接收心跳消息。如果心跳失败超过可配置的时间表,则通常将该实例从注册表中删除
1>高可用
Eureka服务器没有后端存储,但注册表中的服务实例都必须发送心跳以保持其注册更新(因此可以在内存中完成)。客户端还具有eureka注册的内存缓存
3.4.9 SpringCloud Bus 消息总线
Spring Cloud Bus 将分布式系统的节点与轻量级消息代理链接起来。然后可以使用此代理来广播状态更改(例如配置更改)或其他管理指令。一个关键的想法是,总线就像一个分布式执行器,用于横向扩展的 Spring Boot 应用程序。但是,它也可以用作应用程序之间的通信渠道。该项目为 AMQP 代理或 Kafka 提供启动器作为传输
总线事件(的子类RemoteApplicationEvent)可以通过设置来跟踪 spring.cloud.bus.trace.enabled=true。如果这样做,Spring Boot TraceRepository (如果存在)会显示每个发送的事件以及来自每个服务实例的所有确认
3.4 Dubbo
(1)IPC 进程过程调用
(2)LPC 本地过程调用
(3)RPC 远程过程调用,Remote Procedure Call,分布式应用架构
3.4.1 RPC
通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的思想;目标是像调用本地服务一样调用远程服务,具体实现客户端是以调用本地服务的方式调用服务端 API
客户端与服务端建立 TCP 链接,相比于 HTTP 通信协议少去了应用层的东西。
| RPC | HTTP | |
|---|---|---|
| 场景 | 内部服务调用,传输性能高,服务治理方便 | 浏览器接口调用,开放平台接口开放 |
| 协议 | TCP | HTTP |
| 传输效率 | 请求报文小,效率高 | 序列化时耗性能,效率低 |
| 负载均衡 | 支持 | 需要通过 nginx 或 HAProxy 实现 |
| 服务治理 | 支持,自动治理,通知上下游 | 需要实现通知,上下游都知道后再修改 nginx 配置 |
寻址问题:通过服务注册实现,在调用对应的方法也就是自动通过 TCP 链接交互对应的地址。
3.4.2 Dubbo
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
1>组件
- 1、Provider
暴露服务方称之为“服务提供者”。 - 2、Consumer
调用远程服务方称之为“服务消费者”。 - 3、Registry
服务注册与发现的中心目录服务称之为“服务注册中心”。 - 4、Monitor
统计服务的调用次数和调用时间的日志服务称之为“服务监控中心”。
2>主要特性
1.1 服务注册/发现
1.2 健康检查
1.3 多协议支持
1.4 序列化服务
1.5 服务集群
1.6 失败执行策略
1.7 负载均衡策略
1.8 服务治理
1.9 服务监控
1.10 服务运行容器
1.11 直连提供者
1.12 服务代理
1.13 版本/分组管理
1.14 泛化调用
1.15 延迟暴露
1.16 本地存根
1.17 服务降级
1.18 路由规则配置
4. 持久层框架Mybatis、JFinal、Heibernate
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单Java对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
一般的JDBC本身要频繁的创建数据库连接和关闭连接,占用资源;ORM 持久层框架也会引入数据库连接池,对连接进行管理,避免资源浪费。
4.1 MyBatis
(1)MyBatis SQL 防注入(#{})
(2)二级缓存(SqlSession和SqlSessionFactory)
(3)分页原理(内置分页插件接口拦截SQL物理分页)
4.1.1 原理
配置文件加载mapper映射文件,根据id映射具体的mapper具体的实体方法;构造SqlSessionFactory、SqlSession 去执行器执行 MapperStatementt,解析paramType和resultMap封装返回结果
(1)读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了MyBatis 的运行环境等信息,例如数据库连接信息。
(2)加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
(3)构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
(4)创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
(5)Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。6)MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
(7)输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
(8)输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
4.1.2 SQL 注入
对于 Mybattis 使用#{}避免 SQL依赖注入,预编译阶段会解析为占位符从而避免 SQL 注入;而 ${} 占位符预编译阶段解析时会将值直接替换,存在 SQL 注入风险。
#{}是占位符,预编译处理;${}是拼接符,字符串替换,没有预编译处理。
//sqlMap 中如下的 sql 语句
select * from user where name = #{name};
//解析成为预编译语句
select * from user where name = ?;
select * from user where name = '${name}'
//传递的参数为 "ruhua" 时,解析为如下,然后发送数据库服务器进行编译。
select * from user where name = "niaonao";
4.1.3 分库分表历史表清除方案
动态删除分表、历史表CSV备份
<resultMap id="tableNameResult" type="java.lang.String" >
<result column="table_name" property="tableName" jdbcType="VARCHAR" />
</resultMap>
<!-- 查询历史表名称 -->
<select id="findExpireTableNameList" parameterType="list" resultMap="tableNameResult">
SELECT `table_name` from information_schema.tables
WHERE TABLE_SCHEMA = 'niaonao' and TABLE_NAME IN
(<foreach collection="list" item="item" separator=",">
#{item}
</foreach>)
</select>
<!-- 文件导出csv并清除历史表 -->
<select id="historyCsvOutFile" parameterType="list" >
select * from #{tableName} into OUTFILE #{csvDir} character set gbk fields terminated by ',' enclosed BY '\"';
drop table if exists #{tableName};
</select>
service 调用
String dir = csvPath + tableName + ".csv";
File f = new File(dir);
if (f.exists()) {
f.delete();
}
locPositionHistoryMapper.historyCsvOutFile(tableName, dir);
多 SQL 执行方案 allowMultiQueries=true
<!-- url: jdbc:mysql://localhost:3306/niaonao?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8&allowMultiQueries=true
allowMultiQueries 支持多条SQL语句执行通过 ; 分开
-->
<!-- 历史数据文件导出csv,并清除历史记录 -->
<delete id="historyCsvOutFileAndClear" parameterType="String">
select * from loc_warn where warn_time < #{expirationDate} into OUTFILE #{csvDir} character set gbk fields terminated by ',' enclosed BY '\"';
delete from loc_warn where warn_time < #{expirationDate};
</delete>
4.1.4 二级缓存
- 1、一级缓存
一级缓存是SqlSession 级别的缓存,事务提交 Flush、commit 缓存就被清除了;一级缓存存在时,再次查询相同条件,直接返回缓存数据,且存储的是对象,两次结果完全相同; - 2、二级缓存
二级缓存是SqlSessionFactofy 级别的缓存,全局缓存,发送写操作时清除缓存;存储的是数据,通过数据创建新对象返回。
4.1.5 一对一、一对多关系 association
一对多关系用 association 标识
<resultMap type="Stuinfo" id="stuAndMajor">
<id property="sno" column="sno"/>
<result property="sname" column="sname"/>
<association property="major" javaType="Major" select="getMajor" column="majorId"/>
</resultMap>
<select id="getStuAndMajor" resultMap="stuAndMajor" parameterType="String">
select * from stuinfo where sno=#{sno}
</select>
<select id="getMajor" resultType="Major" parameterType="int">
select * from major where id=#{majorId}
</select>
4.1.6 Mybatis是如何分页
1>SQL语句分页
- 1、MySQL示例
<select id="selectUsers" parameterType="map" resultType="User">
SELECT * FROM users
LIMIT #{offset}, #{limit}
</select>
- 2、Oracle示例
<select id="selectUsers" parameterType="map" resultType="User">
SELECT * FROM (
SELECT a.*, ROWNUM rnum FROM (
SELECT * FROM users ORDER BY id
) a WHERE ROWNUM <= #{endRow}
) WHERE rnum > #{startRow}
</select>
2>Mybatis内置分页插件
如 PageHelper 或 Mybatis-Pagehelper
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
- 1、pom.xml
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
</dependency>
- 2、xxx.java
import com.github.pagehelper.PageHelper;
import com.github.pagehelper.PageInfo;
public List<User> selectUsers(int pageNum, int pageSize) {
// 开始分页
PageHelper.startPage(pageNum, pageSize);
// 执行查询
List<User> userList = userMapper.selectUsers();
// 获取分页信息
PageInfo<User> pageInfo = new PageInfo<>(userList);
return userList;
}
4.2 JFinal
JFinal 是一个基于 Java 的轻量级 Web + ORM 框架,由国人创建并维护。它以简洁、高效为设计理念,旨在帮助开发者快速构建高性能的 Web 应用程序。JFinal 的核心思想是“零配置”,即尽可能减少 XML 配置文件的使用,通过注解和约定优于配置的原则简化开发过程。
4.3 Heibernate
4.3.1 原理
- 1、读取并解析配置文件
- 2、读取并解析映射信息,创建SessionFactory
- 3、打开Sesssion
- 4、创建事务Transation
- 5、持久化操作
- 6、提交事务
- 7、关闭Session
- 8、关闭SesstionFactory
4.3.2 延迟加载 lazy
通过设置 lazy 属性支持延迟加载
当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而提高了服务器的性能。
4.3.3 状态转换
瞬时状态、游离状态、持久状态
当对象由瞬时状态(Transient)一save()时,就变成了持久化状态;
当我们在Session里存储对象的时候,实际是在Session的Map里存了一份, 也就是它的缓存里放了一份,然后,又到数据库里存了一份,在缓存里这一份叫持久对象(Persistent)。 Session 一 Close()了,它的缓存也都关闭了,整个Session也就失效了,这个时候,这个对象变成了游离状态(Detached),但数据库中还是存在的。
当游离状态(Detached)update()时,又变为了持久状态(Persistent)。
当持久状态(Persistent)delete()时,又变为了瞬时状态(Transient), 此时,数据库中没有与之对应的记录
4.3.4 缓存机制
- 1、一级缓存
Hibernate一级缓存又称为Session的缓存。由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。第一级缓存是必需的,不允许而且事实上也无法卸除。在第一级缓存中,持久化类的每个实例都具有唯一的OID。 - 2、二级缓存
Hibernate二级缓存又称为SessionFactory的缓存,由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。
4.3.5 缓存策略
| 策略 | 说明 |
|---|---|
| Read-only | 适用于那些频繁读取却不会更新的数据 |
| Read/write | 适用于需要被更新的数据,比read-only更耗费资源 |
| Nonstrict read/write | 不保障两个同时进行的事务会修改同一块数据,这种策略适用于那些经常读取但是极少更新的数据 |
| Transactional | 完全事务化得缓存策略 |
4.3.6 一对一、一对多关系
它们通过配置文件中的many-to-one、one-to-many、many-to-many来实现类之间的关联关系的。
4.3.7 检索策略
立即检索、延迟检索、迫切左外连接检索
| 优点 | 缺点 | |
|---|---|---|
| 立即检索 | 对应用程序完全透明,不管对象处于持久化状态,还是游离状态,应用程序都可以方便的从一个对象导航到与它关联的对象 | select语句太多;可能会加载应用程序不需要访问的对象白白浪费许多内存空间 |
| 延迟检索 | 由应用程序决定需要加载哪些对象,可以避免可执行多余的select语句,以及避免加载应用程序不需要访问的对象。因此能提高检索性能,并且能节省内存空间 | 应用程序如果希望访问游离状态代理类实例,必须保证他在持久化状态时已经被初始化 |
| 迫切左外连接检索 | 对应用程序完全透明,不管对象处于持久化状态,还是游离状态,应用程序都可以方便地冲一个对象导航到与它关联的对象。2使用了外连接,select语句数目少 | 可能会加载应用程序不需要访问的对象,白白浪费许多内存空间;2复杂的数据库表连接也会影响检索性能 |
Power By niaonao, The End